선택 트리
1) 개념
선택 트리는 정렬된 여러 데이터 리스트를 효과적으로 병합하는 데 사용되는 트리 구조이다. 이는 합병 정렬 과정에서 중요한 역할을 한다. 예를 들어, 8개의 정렬된 리스트가 있을 때, 이들 중 가장 작은 값을 빠르게 찾아내어 새로운 리스트를 생성하는 과정을 단순화한다. 선택 트리는 이러한 비교 과정의 횟수를 줄이는 데 크게 기여한다.
이 트리는 주로 승자 트리와 패자 트리의 두 가지 형태로 구성된다. 승자 트리는 더 작은 값을 가진 노드가 승자가 되어 상위 노드로 올라가는 완전 이진 트리 구조이다. 이는 각 노드가 두 자식 노드 중 작은 값을 선택하여 상위 노드로 올라가는 토너먼트와 유사한 방식으로 작동한다. 반면, 패자 트리는 루트 노드 위에 최상위 0번 노드를 두어 최종 승자를 저장한다. 이 트리는 패자를 부모 노드에 저장하고 승자는 부모의 부모 노드로 올라가게 된다. 이러한 방식은 비교 과정에서 발생할 수 있는 오버헤드를 줄이는 데 효과적이다.
선택 트리의 이러한 구성 방식은 데이터 처리의 효율성을 크게 향상시키며, 복잡한 데이터 처리 과정을 단순화하는 데 중요한 역할을 한다.
2) 승자 트리
승자 트리는 각 노드가 두 자식 노드의 작은 값인 완전 이진트리다. 정렬된 데이터 리스트를 이용해 승자 트리를 구축하는 과정은 토너먼트 경기와 유사하다. 각 내부 노드는 두 자식 노드 중 작은 값을 선택하여 부모 노드의 값으로 한다. 루트 노드는 가장 작은 값을 가지며, 이를 리스트에서 삭제한 후 승자 트리를 재구성한다. 이 과정을 반복하여 여러 리스트를 하나의 순서 리스트로 합병한다.
예를 들어, 8개의 정렬된 리스트에서 승자 트리를 구성하는 과정을 살펴보자. 초기 단계에서 리스트의 head에 위치한 값들이 트리의 잎으로 올라간다. 토너먼트의 결과에 따라 승자가 부모 노드로 올라가고, 결과적으로 루트에 가장 작은 값이 위치한다. 루트의 최소값을 리스트에 저장한 후, 그 값을 가진 리스트의 다음 데이터를 승자 트리에 올려보내고 다시 경쟁을 한다. 이 과정을 통해 전체 리스트를 하나로 합병할 수 있다.


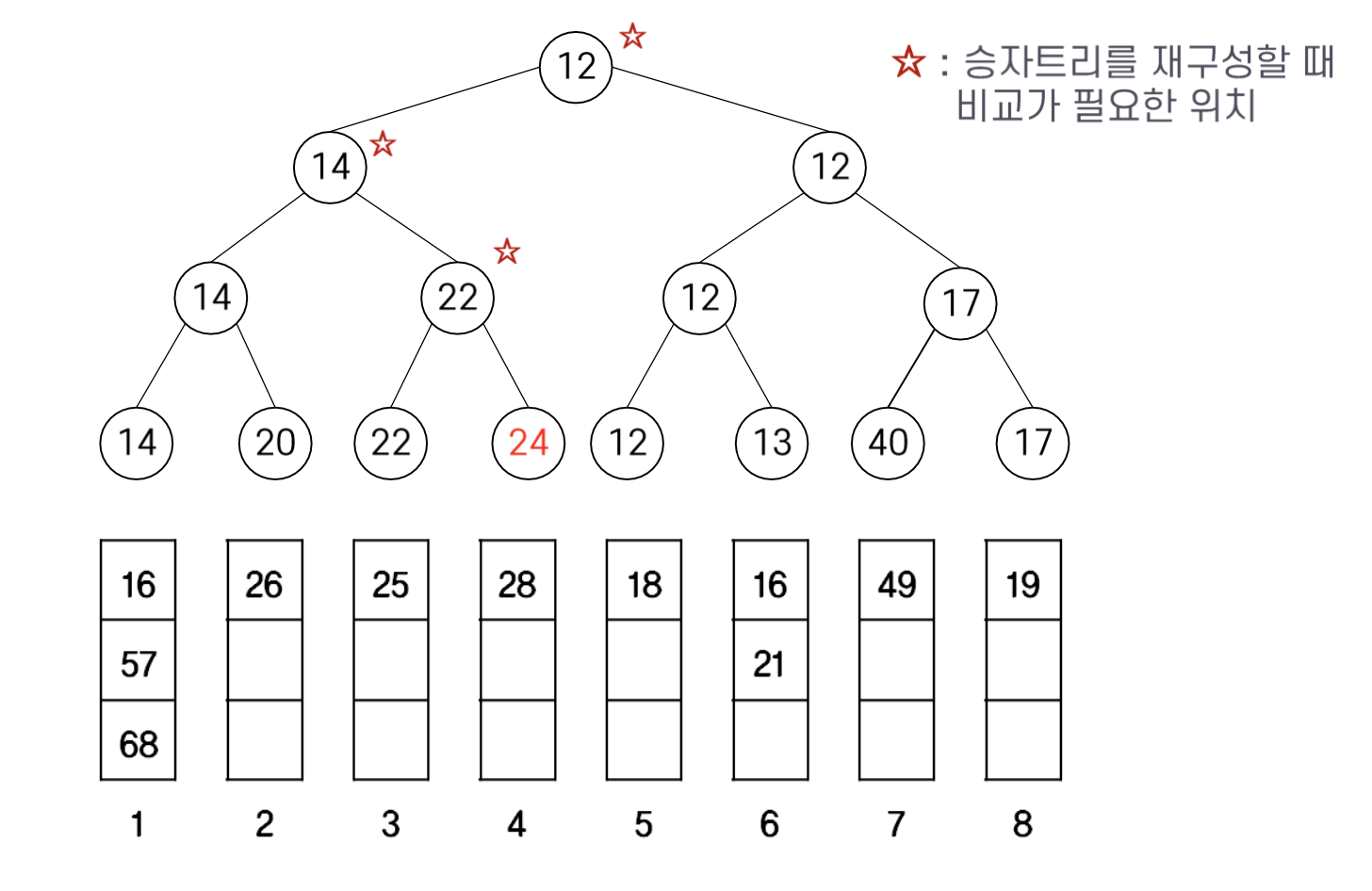
승자 트리 재구성 시 필요한 비교 횟수는 상대적으로 적다. 예를 들어, 8개 리스트의 경우 3회의 비교로 충분하며, 이는 효율성을 크게 증가시킨다. 계산 복잡도는 O(nlogk)로, n개의 데이터를 모두 합병하는 데 필요하다. 승자 트리는 완전 이진트리이기 때문에 배열로 구현이 가능하다. 배열에서 왼쪽 자식 노드의 위치가 i일 때, 오른쪽 자식은 i+1, 부모는 i/2가 되어 구현이 간단하다.
이와 같이 승자 트리는 효율적인 합병 정렬과 데이터 처리에 중요한 역할을 한다.
3) 패자 트리
패자 트리는 승자 트리와 유사하게 각 노드가 두 자식 노드 중 더 작은 값을 갖는 완전 이진 트리이다. 잎 노드들은 각 리스트의 가장 작은 값(리스트의 head가 가리키는 값)을 갖는다. 하지만 승자 트리와 다르게, 패자 트리는 루트 노드 위에 최상위 0번 노드를 갖는다. 이 0번 노드에는 토너먼트에서 이긴 최종 승자가 저장된다. 내부 노드에는 승자가 아닌 패자를 저장하며, 패자는 부모 노드에, 승자는 부모의 부모 노드로 올라가 다시 경쟁한다. 결과적으로 루트 노드에는 마지막 토너먼트의 패자가 저장되고, 최종 승자는 0번 노드에 저장된다.
각 비교(토너먼트 경쟁)에서 패자는 부모 노드에 남고, 승자는 위로 올라가서 다시 경쟁한다. 승자는 노드의 왼쪽에 표시되어 있으며, 패자 트리는 0번 노드에 최소값을 갖는다. 이 최소값을 제거하고 전체 리스트에 저장한다. 제거된 값이 위치한 리스트의 head에 있던 새 값(예: 24)이 패자 트리에 올려져 새로운 경쟁이 이루어진다.

숲
숲에 대한 개념은 강연과 교재 내용을 통해 자세히 다뤄졌다. 숲이란 여러 개의 분리된 트리, 즉 나무의 모임을 의미한다. 이는 숲이 단 하나의 트리로 구성될 수도 있으며, 심지어 아무것도 없는 상태도 숲으로 간주될 수 있다는 것을 포함한다.
다양한 형태의 숲

숲이란 n(>=0)개 이상의 분리된 트리 집합.
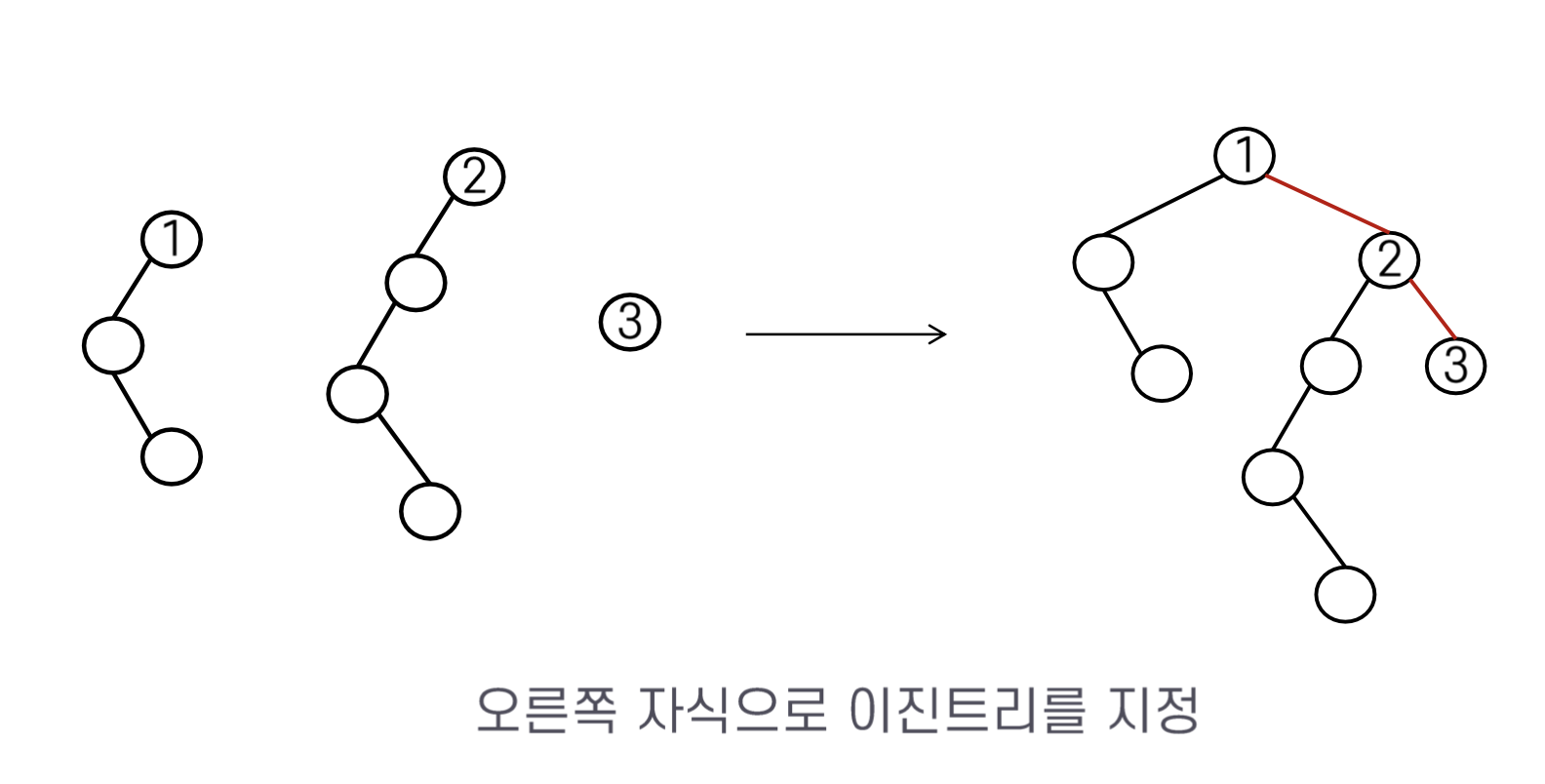
숲을 이진 트리로 변환하는 과정은 간단하면서도 중요한 원리에 기반한다. 각각의 트리(Ti)를 먼저 이진 트리(BTi)로 변환한 다음, 이를 하나의 이진 트리로 결합한다. 이 과정에서 중요한 것은 각 Ti^BT의 루트가 왼쪽 서브트리만을 가지며, 이 루트를 최상위 루트로 하여 왼쪽 자식은 그 왼쪽 서브트리를, 오른쪽 자식은 나머지 트리들의 이진 트리(BT2~n)로 구성하는 것이다.
숲을 이진 트리로 변환하는 과정을 보면, 먼저 각 트리를 이진 트리로 변환한 후, T1^BT의 오른쪽 자식으로 T2^BT를, T2^BT의 루트 오른쪽 자식으로 T3^BT를 배치함으로써 숲을 이진 트리로 성공적으로 변환할 수 있다.
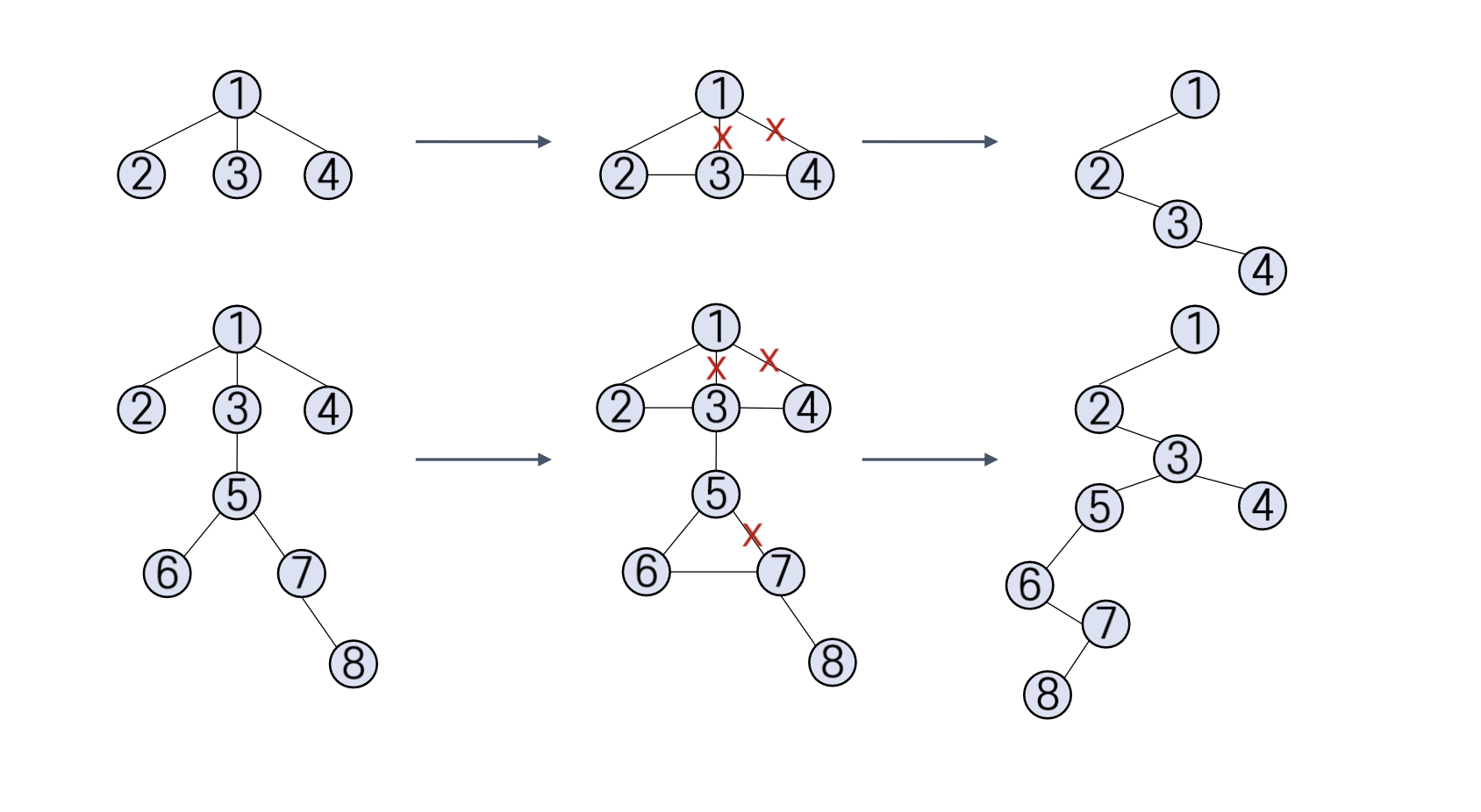
또한, 숲을 순회하는 방법도 이진 트리로 변환하는 과정과 유사하다. 즉, 각 트리를 이진 트리로 변환한 후, rootT1^BT, T1^BT의 왼쪽 서브트리, BT2~n에 대해 전위, 중위, 후위 순회를 수행함으로써 숲을 효율적으로 탐색할 수 있다. 이는 숲을 이진 트리로 변환한 후 숲을 순회하는 전략과 밀접하게 연결되어 있다.
이진 트리 개수
노드 개수가 0인 이진 트리는 몇개나 있을까? 1개이다. 아무것도 없는 그 트리이다. 그럼 노드 개수가 1인 이진트리는 몇개일까? 마찬 가지로 1개이다. 이제 노드가 2인 경우를 생각해보자. 노드가 개수가 2인 이진트리는 다음과 같이 2개이다.

노드 개수가 3인 이진트리는 몇개나 가능할까? 다음과 같이 5가지 가능하다.

어떻게 계산할 수 있을까?
어떤 트리를 전위 순회한 방문 순선가 1,2,3이고 중위 순회한 방문 순서를 1, 3, 2라 하면 이 두가지 순열로부터 유일하게 이진 트리를 생성할 수 있다. 우선 전위 순회로 첫 번째 방문한 노드가 1이라면 루트라는 뜻이다. 그리고 중위 순회 방문 순서를 보면 1이 가장 먼저 나오므로 3, 2는 노드 1의 오른쪽 서브트리임을 알 수 있다.

그런데 전위 순회 두 번째 방문 노드가 2이고, 중위 순회가 3번 노드가 먼저 방문되므로 노드 3이 노드 2의 왼쪽 서브트리라는 것을 알 수 있다. 따라서 전위 순회한 방문 순서가 1,2,3이고 중위 순회한 방문순서가 1,3,2안 트리는 다음과 같이 (b)임을 알 수 있다.

따라서 다음과 같은 결론이 가능하다.
"어떤 이진 트리에 대한 전위-중위 순회 방문 순서가 주어지면 트리 구조를 유일하게 (한 개) 정할 수 있다."
이 사실로부터 두 번째 결론을 얻는다.
"1부터 N까지 수를 스택에 넣었다가 가능한 모든 방법으로 삭제하여 생성할 수 있는 경우의 수와 n개의 노드를 가진 상이한 이진 트리의 수는 같다."
다음은 Push 와 Pop 연산의 예시이다.


전위 순회 방문 순서가 1,2,3 이고 중위 순회 방문 순서가 1,3,2라고 하자. 1,2,3을 위와 같이 스택에 넣었다 빼면 1,3,2를 얻을 수 있다. push()는 트리 생성 과정으로 껍데기 노드와 왼쪽 서브트리를 나타내고, pop()은 껍데기 노드에 값을 넣고 오른쪽 서브트리로 이동하는 것으로 생각할 수 있다.
스택에 Push() 한다는 것은 나보다 먼저 pop()할, 즉 왼쪽 서브 트리가 될 노드들이 있다는 뜻이다. 만일 push()한 후 바로 pop()을 하면 왼쪽 서브트리는 Null이다. 왼쪽으로 갔다가 아무것도 없으니까 가운데인 나를 출력한다는 의미이다. 마찬가지로 pop() 한다는 건 나의 왼쪽 서브트리와 오른쪽 서브트리를 구분하는 위치, 즉 중위 순회에서 가운데 차례가 되기 때문에 노드에 값을 넣고 오른쪽 서브트리로 이동한다.
요약
- 차례로 정렬한 데이터 리스트 k개가 있다고 가정할 때, 그것들을 완전한 순서를 유지하는 하나의 리스트로 만드는 과정을 합병 정렬이라 한다.
- 합병 정렬에 사용하는 특수한 트리가 선택 트리이다.
- 선택 트리에는 승자 트리와 패자 트리 두 종류가 있다.
- 승자 트리는 각 노드가 두 자식 노드의 작은 값을 갖는 완전 이진 트리이다.
- 승자 트리 구축 과정은 작은 값이 승자로 올라가는 토너먼트 경기와 유사하다. 즉 트리의 각 내부 노드는 두 자식 노드 값의 승자를 자신의 값으로 한다.
- 선택 트리를 사용하는 경우 트리의 레벨은 Log(k+1)이므로 선택 트리를 재구성하는 시간은 O(logk)이고, 따라서 n개의 데이터를 모두 합병하는 데 필요한 계산 복잡도는 O(nlogk)이다.
- 패자 트리는 루트 노드 위에 최상위 0번 노드를 갖는다. 이 0번 노드에는 경쟁에서 이긴 최종 승자를 저장한다.
- 패자를 부모 노드에 저장하고 승자는 부모의 부모 노드로 올라가서 다시 경쟁한다. 따라서 루트에는 마지막 토너먼트 패자를 저장하고 최종 승자는 0번 노드에 저장한다.
- 분리된 트리 모임을 숲이라 부르며, 숲은 n(>=0)개 이상의 분리된 트리 집합이다.
- 숲을 이진 트리로 바꾸려면 먼저 각 트리(Ti)를 이진 트리로 바꾼다(Ti^Bt). 이때 Ti^BT의 루트는 왼쪽 서브트리만 갖는다. 다음은 T1^BT의 루트를 최상위 루트로 하고 왼쪽 자식은 그 왼쪽 서브트리(오른쪽 서브트리는 없음), 오른쪽 자식은 나머지들의 이진 트리(BT2~n)가 되도록 한다.
- 어떤 이진 트리에 대한 전위-중위 순회 방문 순서가 주어지면 트리 구조를 유일하게 한 개 정할 수 있다.
- 1부터 n까지 수를 스택에 넣었다가 가능한 모든 방법으로 삭제하여 생성할 수 있는 경우의 수와 n개의 노드를 가진 상이한 이진 트리의 수는 같다.
- 수학자인 카탈랑은 노드 n개인 서로 다른 이진 트리의 개수가 (2n)!/n!(n+1)!과 같음을 증명했다.
참고 자료: 자료구조 (강태원, 정광식 공저, KNOU press 출판)
'CS > 자료구조' 카테고리의 다른 글
| 멀티웨이 탐색 트리 1 - m원 탐색 트리, B 트리, B*트리, B+ 트리 (2) | 2023.11.26 |
|---|---|
| 이진 탐색 트리Bs) - Splay, Avl, BB 트리 (1) | 2023.11.25 |
| 힙 - 개념, 우선순위 큐, 삭제 삽입 연산 (1) | 2023.11.24 |
| 스레드 트리, 개념, 구현, 연산 (순회 삽입 삭제) (0) | 2023.11.24 |
| 트리 용어 및 개념, 이진 트리, 순회 연산, 생성 삭제 조회 연산 - 자바 코드 (0) | 2023.11.24 |



