트리
개요
트리(Tree)란?
- 개념과 특성: 트리는 계층적 구조를 나타내는 자료구조로, 노드(node) 또는 정점(vertex)으로 이루어진다. 데이터 간의 계층 관계와 포함 관계를 나타내는 데 적합하다.
- 비유적 표현: '트리'라는 용어는 거꾸로 세워진 나무를 연상시키며, 이 구조에서는 뿌리(root), 잎(leaf), 서브트리(subtree)와 같이 나무와 관련된 용어들이 사용된다.
- 이진 트리(Binary Tree): 트리의 모든 노드가 최대 두 개의 자식을 갖는 특별한 형태의 트리로, 수학적 이론 정리 및 컴퓨터 구현에 적합하여 자주 사용된다.

이진 트리의 종류
- 가득 찬 이진 트리(Full Binary Tree): 각 레벨의 노드가 최대한 많을 때, 즉 모든 레벨이 노드로 가득 차 있는 상태.
- 완전 이진 트리(Complete Binary Tree): 높이 ( k )인 이진 트리가 레벨 0부터 ( k-2 )까지 모든 레벨이 가득 차 있고, 마지막 레벨 ( k-1 )은 왼쪽부터 차례대로 노드들이 채워져 있는 상태.
예를 들어, '모차르트, 세잔, 아인슈타인, 바흐, 뉴턴, 피카소, 베토벤'과 같은 유명 인물들의 목록을 직업별로 분류하는 경우, 이진 트리를 사용하여 음악가, 화가, 과학자 등으로 효과적으로 분류할 수 있다. 이렇게 분류된 정보는 트리의 계층적 구조를 통해 쉽고 빠르게 접근할 수 있다.

트리 순회(Tree Traversal)
- 개념: 트리의 각 노드를 모두 한 번씩 방문하는 과정.
- 순회 방식: 루트 노드를 방문하는 순서에 따라 전위(preorder), 중위(inorder), 후위(postorder) 순회로 구분.
용어와 논리적 표현 방법
핵심 용어
- 노드(Node) / 정점(Vertex): 트리를 구성하는 기본 단위. 데이터를 저장하며, 다른 노드와의 연결 지점이 됨. 트리의 노드는 부모-자식 관계로 연결.
- 저장된 정보 항목, 에지(edge) 항목으로 구성
- 한 정보 아이템과 이것으로부터 다른 아이템으로 뻗은 가지를 합쳐서 말하는 용어
- 루트 노드(Root Node): 트리의 최상위에 위치하는 노드. 부모가 없는 유일한 노드로, 트리의 출발점. 정점 노드.
- 서브트리(Subtree): 주어진 노드와 그 자손 노드들로 구성된 트리. 특정 노드를 루트로 하는 서브트리는 그 노드의 자식 노드들을 포함.
- 잎 노드(Leaf Node) / 종단 노드(Terminal Node): 자식 노드가 없는 노드. 트리의 가장 바깥쪽에 위치.
- 부모 노드(Parent Node): 특정 노드의 직접적인 상위 노드.
- 자식 노드(Child Node): 특정 노드의 직접적인 하위 노드.
- 형제 노드(Sibling Nodes): 같은 부모 노드를 공유하는 노드들.
- 진입 차수(In-degree)와 진출 차수(Out-degree): 노드로 들어오는 간선의 수를 진입 차수, 노드에서 나가는 간선의 수를 진출 차수라고 함.
- 트리의 경로: 트리에서 루트 노드에서 어떤 노드로 이동하는 데 필요한 간선(에지)들의 연속된 시퀀스.
- 노드의 레벨(Node Level): 루트 노드에서 특정 노드까지의 경로 길이. 여기서는 루트 노드의 레벨을 0으로 정의한다.
- 깊이: 트리의 루트에서 특정 노드까지의 레벨(거리)
- 차수: 어떤 노드의 서브트리의 수
- 노드의 차수: 진출 차수
- 트리의 차수: 트리 내의 각 노드의 차수 가운데 최대 차수
- 신장 트리: 그래프 G의 모든 정점과 간선의 일부(또는 전부)를 포함하는 트리
논리적 표현 방법
트리의 논리적 표현은 구조적인 이해를 돕는다. 노드의 계층적 관계와 상속 구조를 명확히 나타내는 방식으로, 중첩된 집합, 괄호 표현, 들여쓰기 등의 방법을 사용한다. 예를 들어, 중첩된 집합으로 트리를 표현하면 각 노드의 서브트리가 명확히 구분되며, 괄호를 사용하여 노드 간의 관계를 나타낼 수 있다. 이러한 표현은 트리의 계층적 구조를 시각적으로 이해하는 데 유용하다.

추상 자료형
트리 객체의 정의: 루트 노드를 갖는 유한 리스트
연산 :
- Tree Create() -> 트리를 생성하고 루트 노드를 가리키는 포인터를 반환한다.
- Destroy(Tree) -> 더 이상 사용하지 않는 트리의 기억 장소를 시스템에 반환한다.
- Tree Copy_Tree(Tree) -> 트리를 복사하고 새로 생성한 트리의 루트 노드를 가리키는 포인터를 반환한다.
- Insert(n) -> 트리에 노드 n을 삽입한다.
- Delete() -> 트리에서 노드를 삭제한다. 보통 재구성 단계를 포함한다.
- Search() -> 트리에서 특정 키값을 갖는 노드를 찾는다. 찾으면 true 아니면 false를 반환한다.
- Traverse() -> 트리를 순회하고 방문 순서대로 값을 반화한다.
- Root() -> 루트 노드 값을 반환한다.
- Parent(n) -> 노드 n의 부모(값 혹은 포인터)를 반환. n이 루트이면 오류를 반환
- Children() -> 노드 n의 자식(값 혹은 포인터)를 반환. n이 잎이면 오류를 반환
- IsRoot() -> 노드 n이 루트이면 true 아니면 false 이진 트리 (Binary Tree)
1) 이진 트리 개요
이진 트리는 모든 노드가 최대 두 개의 자식(Left와 Right)을 가질 수 있는 트리 구조이다. 이진 트리의 특징은 각 노드가 오른쪽과 왼쪽 자식 노드를 가질 수 있으며, 특히 계산과 분류, 검색 작업에 효율적이다. 그리고 각 노드는 일정한 규칙에 따라 배치되어, 데이터 검색과 같은 연산을 빠르고 효율적으로 수행할 수 있다. 예시로, '모차르트, 세잔, 아인슈타인, 바흐, 뉴턴, 피카소, 베토벤'과 같은 인물들의 목록을 직업별로 분류할 때, 음악가, 화가, 과학자 등의 카테고리로 효과적으로 분류할 수 있는 것인데, 이렇게 이진 트리의 계층적 구조를 통해 쉽고 빠르게 데이터에 접근할 수 있다.
2) 이진 트리 구현
이진 트리의 구현은 일반적으로 연결 리스트를 사용한다. 각 노드는 데이터 필드와 함께 왼쪽 및 오른쪽 자식 노드를 가리키는 포인터를 포함한다. 연결 리스트를 사용하는 이유는 트리의 동적인 특성을 반영하고, 삽입과 삭제가 빠르며 메모리 낭비를 최소화하기 때문이다. 배열을 사용한 구현은 완전 이진 트리나 가득 찬 이진 트리에서 효율적이지만, 일반적인 경우에는 메모리 낭비가 심할 수 있다. 각 노드의 연결 관계를 통해 트리의 구조를 쉽게 조작하고, 노드의 추가 및 제거를 간단하게 할 수 있다. 예를 들어, 노드 'E'와 'N'은 각각 노드 'Sc'의 왼쪽 및 오른쪽 자식으로, 이러한 방향성은 이진 트리의 핵심적인 부분이다.

이진 트리 연산
1) 이진 트리 순회
이진 트리 순회 (Binary Tree Traversal)
이진 트리 순회는 트리의 모든 노드를 방문하는 과정이며, 이 과정에서 노드를 방문하는 순서에 따라 전위 순회(Preorder), 중위 순회(Inorder), 후위 순회(Postorder)로 나뉜다. 각 순회 방법은 노드의 처리(예: 출력) 순서를 결정한다.
typedef struct node{
struct node *left
char data;
struct node *right;
} node;
void preorder(node* root) {
if (root !=null) {
printf("%c" , root -> data);
preorder(root -> left) ;
preorder(root -> right);
}
}
void inorder(node* root) {
if(root !=null){
inorder(root -> left);
printf("%c", root -> data);
inoder(root ->Right);
}
}
void postorder(node* root){
if(root != null){
postorder(root->left);
postorder(root->Right);
printf("%c" root ->data);
}전위 순회 (Preorder Traversal)
- 원리: 먼저 루트를 방문하고, 그 후 왼쪽 서브트리와 오른쪽 서브트리를 순회한다.
- 절차:
- 루트 노드 방문
- 왼쪽 서브트리 전위 순회
- 오른쪽 서브트리 전위 순회
- 사용 예시: 트리의 복사, 트리 구조의 표현에 사용될 수 있다.
- 자바 코드 구현:
void preorder(Node root) { if (root != null) { System.out.print(root.data + " "); preorder(root.left); preorder(root.right); } }
중위 순회 (Inorder Traversal)
- 원리: 먼저 왼쪽 서브트리를 방문한 후 루트를 방문하고, 마지막으로 오른쪽 서브트리를 순회한다.
- 절차:
- 왼쪽 서브트리 중위 순회
- 루트 노드 방문
- 오른쪽 서브트리 중위 순회
- 사용 예시: 이진 검색 트리에서 정렬된 순서로 노드를 방문할 때 사용된다.
- 자바 코드 구현:
void inorder(Node root) { if (root != null) { inorder(root.left); System.out.print(root.data + " "); inorder(root.right); } }
후위 순회 (Postorder Traversal)
- 원리: 먼저 왼쪽과 오른쪽 서브트리를 모두 방문한 후에 루트를 방문한다.
- 절차:
- 왼쪽 서브트리 후위 순회
- 오른쪽 서브트리 후위 순회
- 루트 노드 방문
- 사용 예시: 트리를 사용하여 수학적 표현식을 계산하거나, 트리의 메모리를 해제할 때 사용된다.
- 자바 코드 구현:
void postorder(Node root) { if (root != null) { postorder(root.left); postorder(root.right); System.out.print(root.data + " "); } }
이진 트리 순회는 각 노드를 한 번씩 방문하며, 순회 방식에 따라 방문 순서가 달라진다. 전위 순회는 루트를 가장 먼저 방문하고, 중위 순회는 루트를 중간에 방문하며, 후위 순회는 루트를 마지막에 방문한다.
class Node {
char data;
Node left, right;
Node(char item) {
data = item;
left = right = null;
}
}2) 이진 트리 생성, 삽입, 삭제
이진 트리 생성
- 이진 트리의 생성은 기본적으로 루트 노드로부터 시작한다.
- 노드는
node구조체로 정의되며, 각 노드는 왼쪽 자식(left), 데이터(data), 오른쪽 자식(right)을 가진다. - 예시: 최초 루트 노드 생성 후, 자식 노드를 추가하여 트리 구조를 확장한다.
이진 트리 노드 삽입
- 이진 트리에 새 노드를 삽입할 때, 부모 노드와의 관계를 고려해야 한다.
- 예시 1: 노드 X의 오른쪽 자식으로 노드 Y를 삽입하는 경우, X의 오른쪽 링크를 Y로 설정한다.
- 예시 2: 노드 Y를 이진 트리에서 삭제하고, Y의 오른쪽 자식인 Z를 X의 오른쪽 자식으로 설정하는 경우, 이때 기존 Y의 위치에 대한 처리가 필요하다.

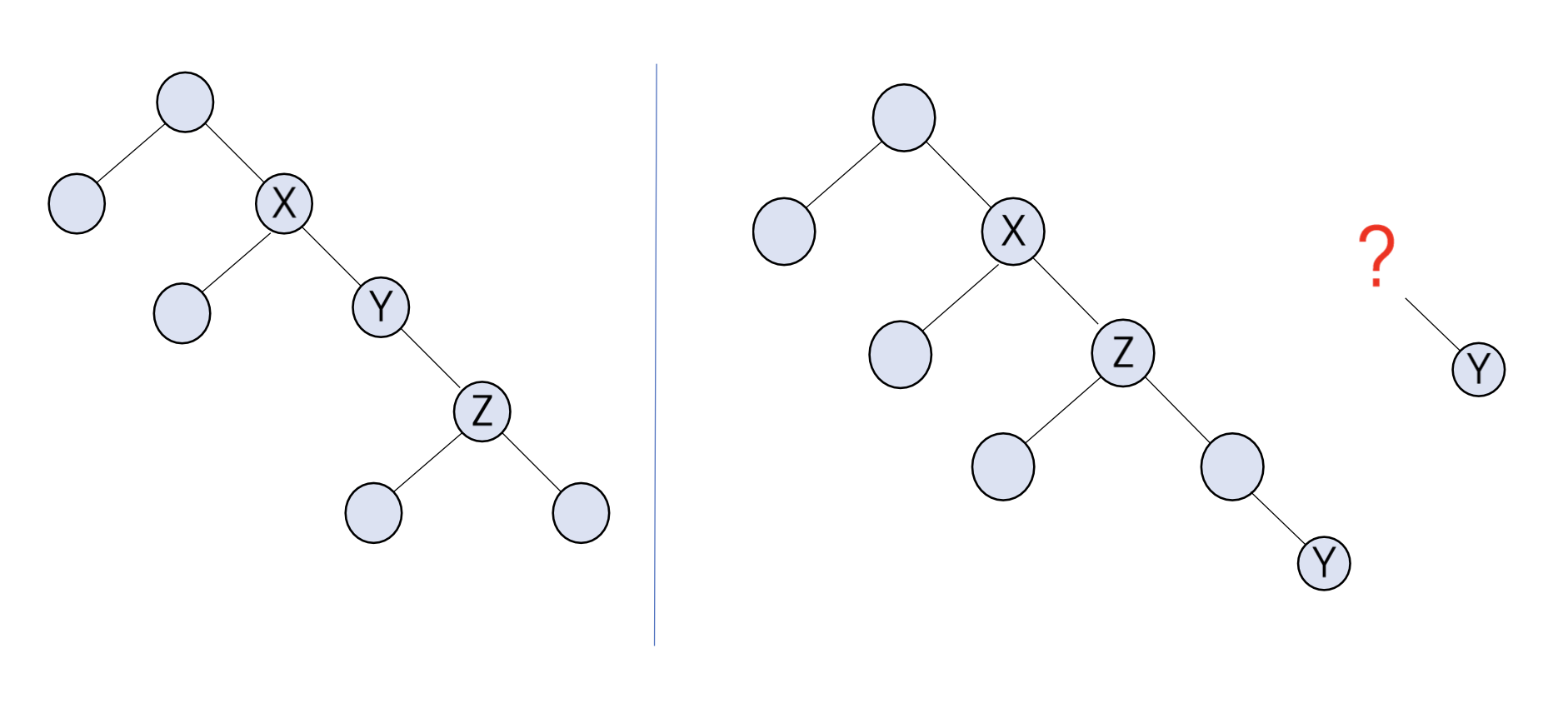
이진 트리 노드 삭제
- 이진 트리에서 노드를 삭제할 때는 해당 노드의 자식 노드 처리가 중요하다.
- 잎 노드(leaf node)를 삭제하는 경우 간단하다. 해당 노드를 null로 지정하고, 메모리를 해제한다.
- 자식 노드가 있는 경우, 삭제 노드의 자식을 어떻게 처리할지 결정해야 한다.
- 예시: 노드 Y 삭제 시, Y의 자식 노드를 Y의 부모 노드의 적절한 위치에 배치한다.
- 서브트리가 하나인 경우, 서브트리의 루트를 삭제한 노드의 위치로 이동한다.
- 양쪽 서브트리가 모두 있는 경우, 한쪽 서브트리를 선택하여 삭제한 노드의 위치로 이동하고, 나머지 서브트리에 대한 처리가 필요하다.
예시: 이진 트리 노드 삽입 및 삭제 코드
// 이진 트리 노드 삽입
node *insert(node *here, node *it) {
if (here == NULL) {
here = it;
return NULL;
} else {
node *victim;
victim = here;
*here = *it;
return victim;
}
}
// 이진 트리 노드 삭제
node *delete(node *root, node *it, char direction) {
node *parent = searchParent(root, it);
if (parent == NULL) {
printf("삭제 불가");
return NULL;
} else {
if (direction == 'l') {
parent->left = NULL;
free(parent->left);
return it;
} else if (direction == 'r') {
parent->right = NULL;
free(parent->right);
return it;
} else {
return NULL;
}
}
}class Node {
int data;
Node left, right;
public Node(int item) {
data = item;
left = right = null;
}
}
class BinaryTree {
Node root;
// 노드 삽입 메소드
void insert(Node node, int data) {
if (node == null) {
node = new Node(data);
} else {
if (data < node.data) { // 삽입할 데이터가 현재 노드 데이터보다 작으면 왼쪽 자식으로 삽입
if (node.left == null) {
node.left = new Node(data);
} else {
insert(node.left, data);
}
} else { // 삽입할 데이터가 현재 노드 데이터보다 크거나 같으면 오른쪽 자식으로 삽입
if (node.right == null) {
node.right = new Node(data);
} else {
insert(node.right, data);
}
}
}
}
// 노드 삭제 메소드
Node deleteNode(Node root, int data) {
if (root == null) return root;
// 삭제할 데이터가 현재 노드보다 작으면 왼쪽 서브트리에서 삭제
if (data < root.data) {
root.left = deleteNode(root.left, data);
}
// 삭제할 데이터가 현재 노드보다 크면 오른쪽 서브트리에서 삭제
else if (data > root.data) {
root.right = deleteNode(root.right, data);
}
// 삭제할 노드를 찾은 경우
else {
// 자식 노드가 하나 또는 없는 경우
if (root.left == null) {
return root.right;
} else if (root.right == null) {
return root.left;
}
// 두 자식 노드가 모두 있는 경우
root.data = minValue(root.right); // 오른쪽 서브트리에서 최소값 찾기
root.right = deleteNode(root.right, root.data); // 오른쪽 서브트리에서 최소값 삭제
}
return root;
}
int minValue(Node root) {
int minv = root.data;
while (root.left != null) {
minv = root.left.data;
root = root.left;
}
return minv;
}
}이진 트리의 노드 삽입과 삭제는 트리의 구조와 데이터의 무결성을 유지하는 데 중요하다. 삽입 시에는 적절한 위치에 노드를 추가하고, 삭제 시에는 자식 노드의 처리 방법을 신중하게 결정해야 한다.
3) 이진 트리 노드 개수 세기
class BinaryTree {
// ...
// 노드 개수 세기
int countNodes(Node node) {
if (node == null) return 0;
return 1 + countNodes(node.left) + countNodes(node.right);
}
// 잎 노드 개수 세기
int countLeafNodes(Node node) {
if (node == null)
return 0;
if (node.left == null && node.right == null)
return 1;
return countLeafNodes(node.left) + countLeafNodes(node.right);
}
}전체 노드 개수 세기
이진 트리의 노드 개수를 세는 과정은 트리의 모든 노드를 순회하며 각 노드를 계산하는 과정이다. 이 과정은 재귀적으로 진행되며, 각 노드에서 자신을 포함해 왼쪽과 오른쪽 서브트리의 노드 개수를 합산한다.
잎 노드 개수 세기
잎 노드 개수를 세는 과정은 트리의 모든 노드를 순회하며 잎 노드인 경우에만 카운트를 증가시킨다.
일반 트리를 이진 트리로 변환
일반 트리를 이진 트리로 변환하는 과정은 각 노드의 자식들을 오른쪽 서브트리로 연결하는 것을 포함한다. 이 과정은 일반 트리의 모든 노드를 이진 트리 형식에 맞게 재배치하는 것을 의미한다. 예를 들어, 일반 트리의 각 노드에 대해 첫 번째 자식은 왼쪽 서브트리로, 나머지 자식들은 오른쪽 서브트리로 연결된다. 이렇게 변환된 트리는 이진 트리의 특성을 가지며, 이진 트리를 사용하는 알고리즘을 적용할 수 있다.
- 일반 트리에 대하여 각 노드의 형제들을 연결
- 각 노드에 대하여 가장 왼쪽 링크만 남겨두고 모두 제거
- 루트 노드는 반드시 왼쪽 자식 노드 하나만 갖도록 함

참고 자료: 자료구조 (강태원, 정광식 공저, KNOU press 출판)
'CS > 자료구조' 카테고리의 다른 글
| 힙 - 개념, 우선순위 큐, 삭제 삽입 연산 (1) | 2023.11.24 |
|---|---|
| 스레드 트리, 개념, 구현, 연산 (순회 삽입 삭제) (0) | 2023.11.24 |
| 깊이 우선 탐색 (Depth-First Search) (0) | 2023.11.24 |
| 연결 리스트의 변형: 원형 연결 리스트, 이중 연결 리스트 (1) | 2023.11.19 |
| 연결 리스트, 리스트의 개념 및 구현, 포인터 변수, 여러 연산들 (1) | 2023.11.19 |



