이 글에 대해서
회사에서 담당하는 티켓 한 티켓 서비스의 QA(품질 보증) 과정에서 중복 등록 이슈가 보고되었습니다. 사용자가 등록 버튼을 연속으로 빠르게 클릭할 경우 티켓이 중복으로 등록되는 현상입니다. 본 글은 이 문제를 접하며 문제를 정의하고 해결하는 과정을 기록하고 사내에 공유한 글을 재편집한 글입니다. 여러 가지 고민과 결론, 그리고 서버 개발을 하며 만나는 멱등성과 동시성에 있어서 추가로 생각해볼 거리들을 다뤘습니다. 업무의 특성상 구체적인 용어나 코드는 컨셉으로 대체하였습니다.
요약
티켓 서비스의 QA 과정 중 발견된 중복 등록 이슈에 대해 다룹니다. 사용자가 등록 버튼을 연속으로 빠르게 클릭할 때 발생하는 중복 등록 현상에 대한 해결 방안 모색 과정을 기술합니다. 어플리케이션 수준의 검증과 한계를 먼저 다루고 실질적인 해결책으로 데이터베이스 수준의 제약 조건 설정과 분산 환경의 최종 일관성 관점에서의 접근을 제시합니다.
문제 상황
티켓 서비스의 QA 과정에서 중복 등록 이슈가 보고되었습니다. 이 문제는 사용자가 등록 버튼을 연속으로 클릭할 경우, 현장정기권이 중복 등록되는 현상입니다. 사용자가 웹 페이지에서 등록 팝업을 열고 필수 값을 설정한 후, 등록 버튼을 클릭 할 때 세 번 이상 연속해서 클릭하면 티켓이 중복으로 등록됩니다. 즉, 동일한 티켓이 여러 번 등록되고 노출되는 상황입니다.
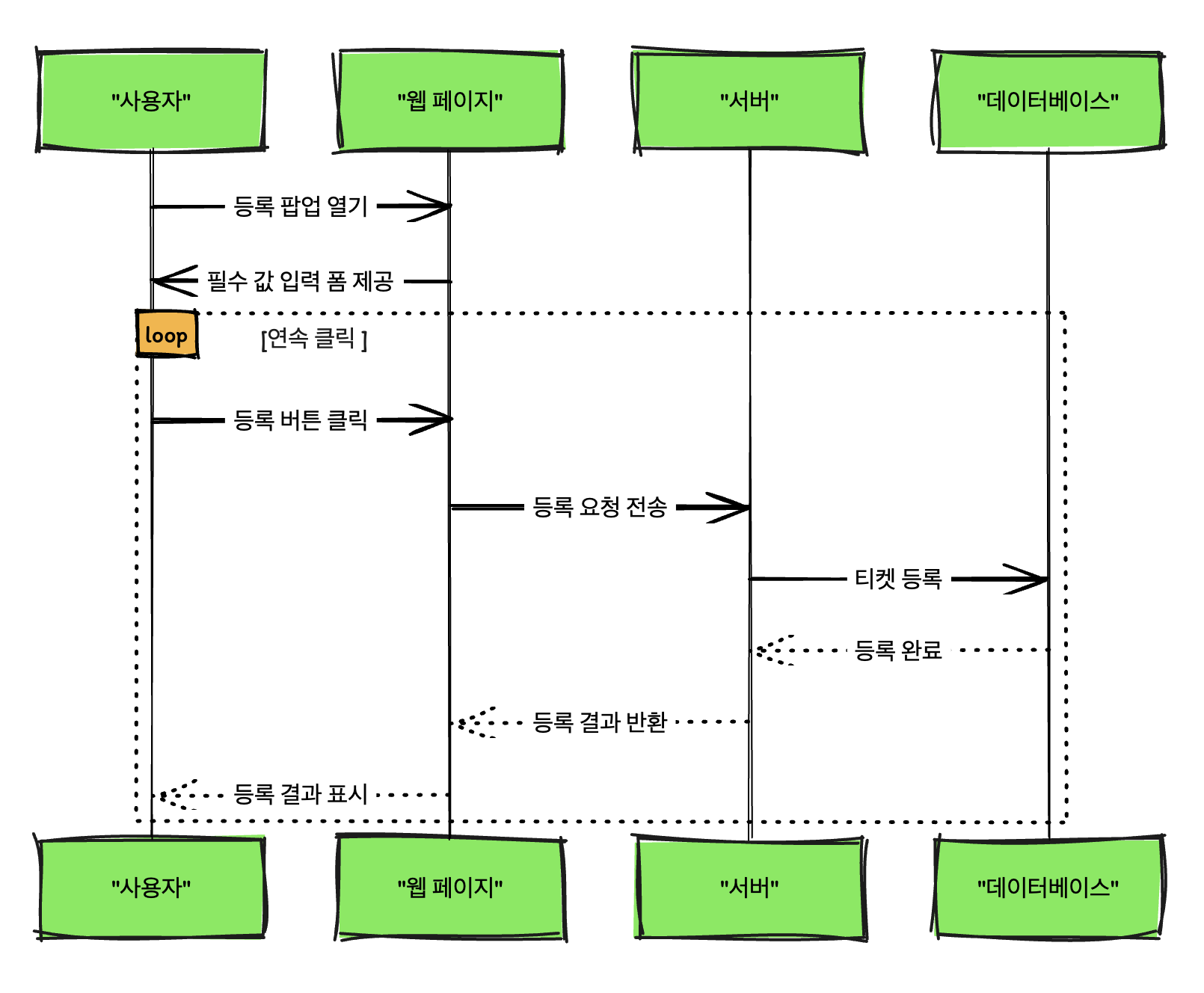
검증을 안하나 ?
검증을 한다 ! 😭
현재의 구조 및 플로우
먼저 현재 플로우는 다음과 같습니다.
클라이언트요청 -> LB -> 게이트웨이 -> 오케스트레이션 -> 도메인 서비스 - DB
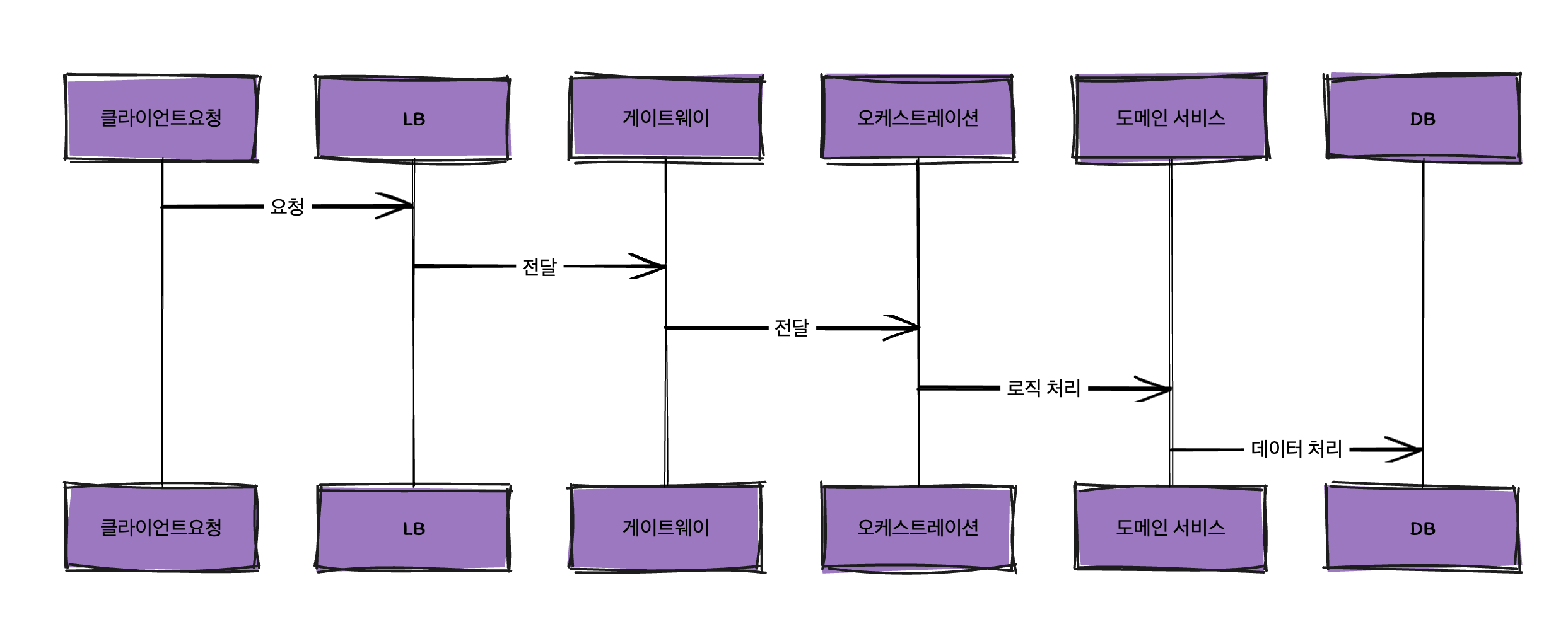
중앙 집중식 오케스트레이션 서비스를 구현한 사가 패턴의 아키텍처를 구성하고 있습니다. 이 MSA 아키텍처에서 도메인 서비스는 응집력을 갖춘 컴포넌트이며 최소화된 기능 단위로 다수 존재하는 서비스입니다. 오케스트레이션은 비즈니스 규칙과 제약에 따라 이들을 조합하거나 호출하여 트랜잭션을 실행하거나 전체적인 비즈니스 프로세스를 달성합니다.
따라서 비즈니스를 관장하는 컴포넌트는 오케스트레이션입니다. 오케스트레이션은 클라이언트의 요청을 받고 비즈니스 규칙과 제약에 따라 검증 로직을 생성하고 도메인 서비스에게 요청합니다. 오케스트레이션과 도메인은 신뢰 기반의 프로세스입니다.
운영상황에서 서버 인스턴스는 4중화되어 있는 상황입니다.
검증을 하는 부분
오케스트레이션에서 티켓 생성 비즈니스를 검증하는 코드는 다음과 같이 구현되어 있습니다.
public void validateDuplicate(TicketRegistrationRequest request) {
// 이미 등록된 티켓 정보를 조회하는 로직
List<RegisteredTicketInfo> existingTickets = ticketResolver.findTickets(new SearchCriteria()
//...
.stream()
.collect(Collectors.toList());
// 중복 검증 로직, 기간이 중복되는지 확인
if (hasOverlappingPeriod(request, existingTickets)) {
throw new DuplicateTicketException("Ticket already exists.");
}
}
이 검증 로직은 이론적으로 중복 등록을 방지하기 위한 기본적인 조치를 제공할 것입니다!
문제는 실제 환경에서는 여러 가지 요인으로 인해 중복 등록 문제가 발생할 수 있고, 실제로 그러하다는 것이죠. 예를 들어, 네트워크 지연이나 클라이언트와 서버 간의 통신 문제로 인해, 오케스트레이션 서비스가 동일한 등록 요청을 여러 번 수신할 수 있습니다. 또한, 서버의 과부하 상태나 데이터베이스의 동시성 처리 미흡으로 인해 중복 검증 로직이 정상적으로 작동하지 않을 수도 있습니다. 특히 서버 인스턴스가 여러 개 운영되는 분산 환경을 고려해야 합니다.
클라이언트 잘못?
그렇다면 클라이언트 쪽에서 접근해보는 것은 어떨까요?
클라이언트 측에서 중복 등록을 방지하기 위한 최소한의 조치는 필요합니다. 예를 들어, 등록 버튼을 누른 후 일정 시간 동안 버튼을 비활성화하는 방법이 있습니다.
원격 API도 클라이언트가 각 요청마다 유일한 ID를 지정하면 멱등성을 구현할 수 있다. 클라이언트가 재시도할 때 실패했던 것과 동일한 요청 ID를 전달하면 된다. 그러면 서버는 이미 해당 요청이 처리된 경우에는 해당 작업을 실행하지 않으면 된다."
- <필독 개발자 온보딩 가이드>
위의 인용구에서 이야기하듯이 클라이언트 측에서 유니크한 ID를 부여하여 요청과 재시도 메커니즘으로 처리된 요청임을 식별하는 절차를 통해서 중복 작업을 방지할 수 있을 것입니다.
이 방식에서는, 클라이언트가 요청을 할 때마다 고유 식별자를 생성하여 요청과 함께 전송합니다. 백엔드는 이 식별자를 확인하여 이미 처리된 요청인지를 판단하고, 이미 처리된 요청이라면 해당 작업을 재실행하지 않고 기존의 결과를 반환합니다. 이 과정은 엔드-투-엔드, 즉 요청이 시작되는 지점부터 처리 완료 지점까지 고유 식별자를 통해 요청의 유일성을 보장합니다. 클라이언트 측에서는 숨겨진 폼 필드를 통해 식별자를 생성할 수 있으며, 서버 측에서는 요청 본문의 해시 값을 사용하여 식별자를 생성할 수 있습니다. 데이터베이스에 식별자를 저장하고, 고유 제약 조건을 적용함으로써, 중복된 요청이 데이터베이스에 반영되지 않도록 합니다.
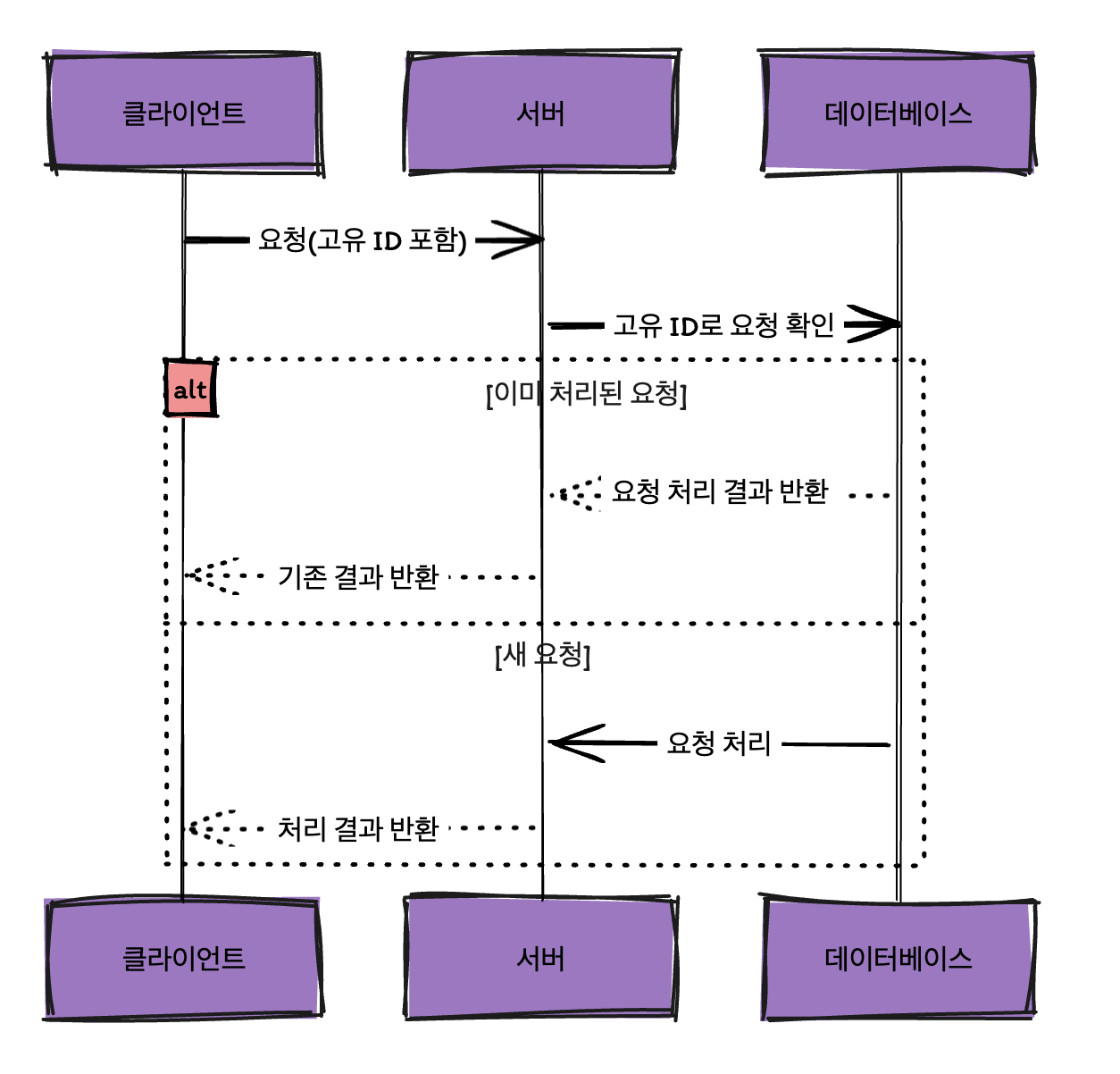
이 방식은 특히 네트워크 불안정 상황에서 도움이 많이 될 것 같습니다.
요금제 서비스를 개발하면서 멱등성 해결을 위해서 사용한 방식이 이 방식입니다. 😇
관련글
MSA 도메인 서비스에서 id 채번 방식 - 멱등성 보장하기
서버 멱등성 혹은 동시성의 문제
그럼에도, 멱등성 문제의 본질적인 책임은 서버가 갖고 있다고 생각합니다.
아무리 클라이언트에서 검증을 해도 본질적인 해결은 서버에서 해주어야 합니다. 멱등성 있는 시스템을 만드는 것이 답입니다. 이런 비유는 어떨까요? 마치 레스토랑에서 서빙 직원이 여러 번 똑같은 주문을 해도 요리사가 이미 만든 요리라면 다시 안 만들면 그만인 것과 마찬가지인 거죠.
멱등성이란
결국 멱등성으로 풀어야 합니다. 멱등성이란, 동일한 작업을 여러 번 수행하더라도 항상 같은 결과를 반환하는 성질을 의미합니다. 멱등하다는 것은 '과자 봉지를 한 번 열면 열린 상태가 되는 것'과 같습니다. 클라이언트 측에서 버튼을 여러 번 눌러도, 서버는 그 요청을 처음 한 번만 인식하고 처리합니다. 이는 마치 봉지를 여러 번 열려고 시도해도 이미 열린 상태이므로 변화가 없는 것과 같습니다. 이렇게 서버에서 한 번의 요청으로만 인식하여 처리함으로써, 중복 등록과 같은 문제를 효과적으로 방지할 수 있습니다.
동시성 문제일까?
이 문제는 동시성(concurrency) 문제의 한 예로도 볼 수 있습니다. 동시성 문제란 여러 프로세스나 스레드가 동시에 같은 데이터에 접근하려 할 때 발생하는 문제를 의미합니다. 본 경우에서는 여러 클라이언트 요청이 서버에 동시에 도달하여 중복된 작업을 수행하게 되는 상황입니다. 마치 여러 고객이 동시에 같은 요리를 주문했을 때, 요리사가 각 주문을 어떻게 처리할지 결정해야 하는 상황과 유사합니다. 서버가 동시에 여러 요청을 받았을 때, 각각의 요청을 독립적으로 처리하지 못하고 중복된 작업을 실행하게 되면 이러한 동시성 문제가 발생합니다.
어플리케이션 접근
1. 락을 이용한 검증 ?
먼저 생각해볼 수 있는 것은 락(lock)이었습니다. 일반적으로 어플리케이션 수준에서 중복 검증을 처리하기 위해 '락(lock)' 메커니즘을 고려할 수 있죠. 이 방식은 중복 등록을 방지하기 위해 특정 데이터 또는 자원에 대한 접근을 잠그고, 한 번에 하나의 요청만 처리할 수 있게 합니다. 예를 들어, 첫 번째 요청이 처리되는 동안 다른 요청들은 대기 상태에 놓이며, 첫 번째 요청이 완료된 후에만 다음 요청이 처리됩니다. 이는 데이터의 일관성과 무결성을 유지하는 데 효과적일 수 있습니다.
문제는 단일 서버 인스턴스에서의 동시성 문제에 대응할 수 있으나, 현재 운영 환경에서 서버 인스턴스가 4중화되어 있는 상황을 고려할 때, 각각의 서버 인스턴스는 독립적으로 작동하므로, 하나의 인스턴스에서 락을 걸어도 다른 인스턴스들은 그 영향을 받지 않는다는 것입니다. 결과적으로, 하나의 인스턴스에서 요청이 처리되는 동안 다른 인스턴스에서 동일한 요청이 처리될 수 있으므로 중복 등록 문제가 해결되지 않습니다.
2. 요청 유일성 + 분산 캐시를 이용한 요청 관리
또 다른 방법은 각 요청에 대해 유일성을 보장하는 검증 메커니즘을 구현하는 것입니다. 또한 여러 인스턴스간의 인지 공유를 위해 분산 캐시를 사용하는 것입니다. 클라이언트로부터 받은 요청의 고유 식별자를 정의하고, 이를 생성하여 요청별로 분산 캐시에 저장합니다. 동일한 ID 요청이 들어오는 경우 중복인 것으로 판단할 수 있겠지요.
문제는 여러가지가 있는데 첫 번재는 글로벌 캐시 의존성입니다. 글로벌 캐시는 SPOF(Single Point Of Failure)가 되기 쉬운 취약점입니다. 그래서 반드시 필요한 경우가 아니라면 일단은 미뤄두고 보자는 주의입니다. 두 번째는 실질적인 문제는데, 실제 환경에서 고유 식별자를 완벽하게 생성하는 것이 실질적으로 어려울 수 있다는 점입니다. 클라이언트가 생성한 고유 식별자가 사실상 고유하지 않아 중복이 아닌 요청을 중복으로 잘못 판단하는 경우가 발생할 수 있습니다. 이는 뒤의 내용에서 다루는 "중복을 방지하려다 오히려 등록 자체가 안되는 문제"와 일맥상통해서 해당 섹션에서 다루겠습니다.
그 외에도, 네트워크 지연, 캐시 미스, 복잡성 문제로 이 방법보다 나은 방법을 모색하게 되었습니다.
어플리케이션이 아닌 다른 쪽으로 눈을 돌려보자
결국 이 문제는 어플리케이션 수준에서의 접근만으로는 해결이 어렵습니다. 위에서 언급한 방법들은 일정 부분 중복 문제를 줄일 수는 있으나, 복수의 서버 인스턴스가 독립적으로 작동하는 환경에서는 근본적인 해결책이 되지 못합니다. 어플리케이션 수준의 해결책은 각 인스턴스 간의 동기화나 데이터의 일관성 유지에 한계가 있고, 또 트레이드오프를 고려할 때 최적의 안을 찾기 힘들었습니다.
따라서, 이 문제를 체계적으로 해결하기 위해서는 보다 근본적인 접근이 필요합니다. 두 가지로 접근해보았습니다. 첫 번째는 데이터베이스 트랜잭션 관리 측면이고, 분산 시스템의 동기화 메커니즘 관점입니다.
해결 1 - DB 트랜잭션에서 유니크함을 관리하기
데이터베이스 트랜잭션 관리를 통해 중복 등록 문제를 해결하는 방식은 중복 데이터의 생성을 방지하는 데이터베이스 수준의 제약 조건을 설정하는 것입니다. 예를 들어, Ticket 엔티티에 주요 필드를 사용하여 동등성 규칙을 생성하고, 이를 데이터베이스에 적용합니다. 이러한 접근 방식은 데이터베이스가 자체적으로 중복 데이터를 거부하도록 만들어, 원천적으로 데이터가 중복으로 쌓이지 않게 합니다.
주요 필드를 사용한 동등성 규칙 생성
Ticket 엔티티에서 중복 등록을 방지하기 위한 주요 필드는 TicketType, carNumber, ZoneId, startAt, endAt, status, isDeleted 등입니다. 이 필드들을 조합하여 고유한 동등성 규칙을 생성합니다. 즉, 해당 필드들이 모두 같은 객체는 같은 객체로 보는 규칙을 설정합니다.
데이터베이스 차원에서의 중복 방지 - 실제 구현
PK 접근법
주요 필드를 사용하여 중복 방지를 위한 첫 번째 접근법은 기본키(Primary Key, PK)를 활용하는 방식입니다. 이 방법에서는 Ticket 엔티티의 주요 필드를 조합하여 복합 기본키를 형성합니다. 예를 들어, TicketType, carNumber, ZoneId, startAt, endAt 등의 필드를 결합하여 하나의 복합 PK를 구성할 수 있습니다. 이 복합 PK는 각 필드 값의 조합이 유일하도록 보장하여, 동일한 조합의 데이터가 이미 존재하는 경우 데이터베이스가 삽입을 거부하도록 합니다. 이 방식은 중복된 데이터의 삽입을 데이터베이스 레벨에서 자동적으로 방지할 수 있는 장점이 있습니다.
Auto Increment를 분산환경에서 사용할 수 없는 이유도 이와 같은 중복 방지 문제에 있어서 유연하지 못하기 때문입니다.
그런데 이미 PK 로직이 별도로 존재하는데요. 현재 방식은 주어진 ZoneId와 시간 기반의 접미사(suffix)를 조합하여 고유한 PK를 생성합니다. 이 방식으로 각 Ticket의 고유성을 보장했는데, 접미사에 밀리초로 시간을 부여하고 있어서 여러 필드를 조합한다고 해도 완전한 유니크함을 보장할 수 없었습니다.
즉, PK는 다르면서 필드는 완전히 똑같아 버리는 멱등성 문제의 주범이 되었던 것이죠.
복합키 혹은 대체키 접근법
Spring Data JPA와 MySQL을 사용하여 Ticket 엔티티에 대해 중복을 방지하는 유니크 제약 조건을 복합키로 설정할 수 있습니다.
Spring Data JPA에서는 @Table 애노테이션의 uniqueConstraints 속성을 사용하여 이를 구현할 수 있습니다. 이 경우, Ticket 엔티티에서 중복 등록을 방지하기 위한 주요 필드를 조합하여 복합 키를 형성하고, 이 복합 키가 데이터베이스에 유니크하게 존재하도록 설정해야 합니다.
아래 코드는 Ticket 엔티티에 대한 변경 사항을 보여줍니다. 여기서는 ticketType, carNumber, ZoneId, startAt, endAt 필드를 조합하여 복합 유니크 키를 생성합니다.
@Entity
@Table(name = "ticket", uniqueConstraints = {
@UniqueConstraint(columnNames = {"ticketType", "carNumber", "ZoneId", "isDeleted", "status", "startAt", "endAt"})
})
public class Ticket {
// 기존 필드와 메서드
@Enumerated(EnumType.STRING)
@Column(length = 30, columnDefinition = "VARCHAR(30) COMMENT '티켓 종류'")
private TicketType ticketType;
@NotNull
@Length(min = 4)
@Column(length = 30, columnDefinition = "VARCHAR(30) COMMENT '차량 번호'")
private String carNumber;
@Column(length = 100, columnDefinition = "VARCHAR(100) COMMENT '구역 아이디'")
private String ZoneId;
@Column
private LocalDateTime startAt;
@Column
private LocalDateTime endAt;
// 기타 필드들...
}
이렇게 설정하면, LocalPeriodTicket의 ticketType, carNumber, ZoneId, startAt, endAt 필드 조합이 유니크해집니다. 만약 동일한 조합의 데이터가 이미 데이터베이스에 존재한다면, 새로운 데이터의 추가는 거부될 것입니다.
복합키와 같은 관점에서 비슷한 기능을 하도록 대체키를 직접 생성하고, DB에서 이를 유니크로 걸어서 해결할 수도 있습니다.
// 대체키 생성 메소드
public void generateAlternativeKey() {
// 대체키는 ticketType, carNumber, ZoneId, startAt, endAt의 조합으로 생성
String keySource = ticketType.name() + carNumber + ZoneId + startAt.toString() + endAt.toString();
String generatedKey = DigestUtils.sha256Hex(keySource); // Apache Commons Codec 사용
this.alternativeKey = generatedKey;
}
또 다른 문제
그런데 또 다른 문제가 있습니다 ‼️
이미 등록한 정기권을 삭제하거나 취소한 경우는 어떨까요?
본 시스템에서는 삭제를 별도의 필드를 두고 전부 softDelete로 처리합니다. 'isDeleted' 필드는 티켓이 삭제된 상태인지를 나타냅니다.
취소의 경우는 'status' 필드를 통해 상태 변경에 대한 값을 설정할 수 있습니다. 이 두 필드에 따라, 삭제 혹은 취소된 티켓은 없는 것으로 간주되어야 합니다. 만약 유효 필드를 조합하여 PK를 생성하고 이것만으로 중복 조건을 체크한다면 삭제가 된 경우에는 이제 역으로 등록이 되어야 하는데 등록을 할 수 없다는 예외가 발생하게 될 것입니다. 왜냐하면 PK 생성시점에 isDeleted는 항상 false일 것이고 Status는 Active일 테니까요.
따라서 'isDeleted' 및 'status' 필드의 변화 역시 동적으로 감지할 수 있어야 합니다.
이러한 문제 때문에 복합 필드를 이용하여 고유한 PK를 만드는 방법이나, 별도의 필드를 설정하여 대체키를 생성하는 로직은 현재의 엔티티 모델에서는 사용할 수 없었습니다.
deActivatedAt이라는 별도 필드 도입
문제는 softDelete나 상태가 취소가 되는 경우 이미 인덱스가 생성이 되어서 이제는 역으로 삭제가 안되는 문제가 생깁니다.
예를 들어,
- A 엔티티 생성 -> 삭제
- 동일 조건으로 생성한 B 엔티티 생성 -> 생성 완료 -> 삭제 시도 -> 유니크 제약 조건으로 삭제 안됨
이러한 문제가 발생합니다.
이 문제를 해결 하기 위해서 deActivatedAt를 별도 필드를 도입합니다.
@Column(columnDefinition = "TIMESTAMP NULLABLE COMMENT '티켓이 삭제되거나 취소된 시점'")
private LocalDateTime deActivatedAt; public void softDelete() {
this.isDeleted = true;
this.deActivatedAt = now();
} public void changeStatus(TicketStatusAction action, String statusChangeReason) {
this.status = TicketStatus.transition(this.status, action);
this.statusChangeReason = statusChangeReason;
if (this.status == CANCELLED) {
this.deActivatedAt = now();
}
}
처음 엔티티 등록시 해당 필드는 null로 초기화됩니다.
문제는 MySQL이 고유 인덱스나 제약 조건이 NULL 값을 가진 행들을 충돌로 간주하지 않습니다. 이는 고유 제약 조건의 일부인 열에서 NULL 값을 가진 여러 행이 허용된다는 것을 의미합니다. 그결과 다른 필드가 모두 동일하여도 deActivatedAt의 Null 값 때문에 제약 조건을 통과하게 되고 중복 엔티티가 허용하게 됩니다.

이 문제를 해결하니 또 저 문제가 생기고, 저 문제를 해결하니 또 이문제로 돌아옵니다. 😓
현장정기권의 생명주기를 고려하여 deActivatedAt을 초기화해주는 방식으로 해결했습니다. 티켓의 endAt이 변경되지 않는다는 점, endAt 이후는 만료된다는 점을 고려하여 endAt으로 처음부터 초기화해준 것입니다.
@PrePersist
public void prePersist(Object entity) {
if (entity instanceof Ticket) {
Ticket Ticket = (Ticket) entity;
if (Ticket.getDeActivatedAt() == null) {
Ticket.setDeActivatedAt(Ticket.getEndAt());
}
}
}
SpringDataJpa에서 제공하는 @UniqueConstraint
결론적으로는 @UniqueConstraint를 통해 해결했는데요.
작동 원리에 대해서 좀 더 살펴보고자 합니다.
Spring Data JPA의 @UniqueConstraint 애노테이션은 특정 엔티티에 대한 테이블의 열 조합이 유니크하게 유지되어야 함을 데이터베이스에 지시합니다. 이 애노테이션을 사용하면, 지정된 열의 조합에 대해 중복된 값을 가진 행이 삽입되는 것을 데이터베이스 수준에서 방지할 수 있습니다.
작동 원리
@UniqueConstraint는@Table애노테이션 내에 정의되며, 하나 이상의 열 이름을columnNames속성을 통해 지정합니다.- 이 애노테이션을 포함한 엔티티가 데이터베이스에 매핑될 때, 지정된 열 조합에 대한 유니크 제약 조건이 생성됩니다.
- 이제 해당 엔티티에 대해 데이터베이스에 삽입 또는 갱신 작업을 수행할 때, 지정된 열의 조합이 유니크하지 않으면, 데이터베이스는 이를 거부하고 오류를 발생시킵니다.
@UniqueConstraint 애노테이션의 작동 원리는 데이터베이스 스키마 생성 시점에 중요한 역할을 합니다. 이 애노테이션은 엔티티 클래스에 정의된 필드들의 조합을 기반으로 유니크 제약 조건을 생성하여, 데이터베이스에 적용합니다. 이 과정은 아래의 세부 단계로 구분할 수 있습니다.
- 제약 조건 정의: 데이터베이스에 테이블이 생성될 때,
@UniqueConstraint애노테이션에 의해 정의된 유니크 제약 조건이 데이터베이스 스키마에 반영됩니다. 이 제약 조건은 특정 열들의 조합에 대해 중복된 값을 허용하지 않습니다. - 애노테이션 해석: JPA 구현체(예: Hibernate)는 애노테이션을 해석하여, 해당 필드 조합에 대한 유니크 제약 조건의 메타데이터를 생성합니다.
- DDL 생성: 데이터베이스 스키마 생성 시, 이 메타데이터는 데이터베이스에 적용될 DDL(Data Definition Language) 명령으로 변환됩니다. 이 명령은 특정 테이블에 대한 유니크 제약 조건을 정의합니다.
- 데이터 삽입 또는 갱신 시 검증: 데이터를 삽입하거나 갱신할 때, 데이터베이스는 해당 테이블의 유니크 제약 조건을 검토합니다. 삽입하거나 갱신하려는 행의 특정 열 조합이 이미 테이블에 존재하는지 확인합니다.
- 제약 조건 적용: 데이터베이스는 이 DDL 명령을 실행하여, 실제 테이블에 유니크 제약 조건을 적용합니다. 이렇게 되면, 지정된 필드 조합이 유니크하게 유지되도록 데이터베이스에서 자동적으로 관리됩니다.
- 제약 조건 위반 처리: 만약 삽입하거나 갱신하려는 행이 유니크 제약 조건을 위반한다면, 데이터베이스는
ConstraintViolationException과 같은 오류를 발생시킵니다. 이 오류는 중복된 값이 테이블에 삽입되거나 갱신되지 않도록 보장합니다.
참고자료
https://www.baeldung.com/jpa-unique-constraints
실제 작동 사례
아래와 같은 테스트 코드로 연속된 동일 엔티티 등록을 시도합니다.
/**
* when - 티켓을 연속으로 동일한 건을 요청하면
* then - 유니크 제약에 따라 1건은 성공하고 1건은 실패한다.
*/
@Test
@DisplayName("티켓 등록 - 연속된 등록 제약 조건 ")
void Ticket_equal_enrollment_1(){
// when
TicketEnrollmentRequest enrollmentRequest1 = createAndEnrollDefaultTicket();
TicketEnrollmentRequest enrollmentRequest2 = createAndEnrollDefaultTicket();
// then
fetchTicketWithOk(enrollmentRequest1.getTicketId());
ExtractableResponse<Response> response2 = fetchTicket(enrollmentRequest2.getTicketId());
assertEquals(NO_CONTENT.value(), response2.statusCode());
}
로그를 통해 살펴보겠습니다. 로그에는 Ticket 테이블에 새로운 행을 삽입하려 했으나, Unique index or primary key violation 오류가 발생한 것을 볼 수 있습니다. 이는 삽입하려는 데이터가 ticketType, carNumber, ZoneId, startAt, endAt, isDeleted, status 필드 조합에 대한 유니크 제약 조건을 위반했음을 의미합니다.
14:27:00.139 [ERROR] [XNIO-2 task-1] [o.h.e.jdbc.spi.SqlExceptionHelper] - Unique index or primary key violation: "PUBLIC.UK1N5GDR0L35VMY8UT5S9UCKRV9_INDEX_1 ON PUBLIC.TICKET(TICKET_TYPE, CAR_NUMBER, ZONE_ID, START_AT, END_AT, IS_DELETED, STATUS) VALUES 1"; SQL statement:
insert into ticket ( ... ) values ( ... ) [23505-200]
이 로그는 유니크 제약 조건이 정상적으로 작동하고 있음을 보여주지만, 데이터베이스에서 제약 조건을 어떻게 판단하는지에 대한 내부적인 메커니즘까지는 설명하지 않습니다.
MySQL과 같은 관계형 데이터베이스는 유니크 인덱스를 사용하여 제약 조건을 구현합니다. 이러한 인덱스는 데이터 삽입 또는 갱신 시점에 적용되어 중복되는 데이터의 삽입을 방지합니다. 즉, INSERT 또는 UPDATE 쿼리 실행 시, 데이터베이스는 유니크 인덱스에 정의된 컬럼들의 조합을 검사하여 이미 존재하는지 여부를 판단하고, 중복된 경우 오류를 발생시키는 방식으로 작동합니다.
그런데 왜 유티크 인덱스가 안 보일까?
MySQL에서 유니크 제약 조건이 설정되어 있다면, 일반적으로 관련된 유니크 인덱스가 자동으로 생성되어야 합니다.
SHOW INDEX FROM ticket; 를 했는데 유티크 인덱스가 안 보입니다.
ddl-auto: update인데도 생성되지 않은데요.
한참을 헤맸는데 문제는 기존 database table 내에 컨텐츠가 존재하는데 이미 유니크 조건을 위반하는 레코드가 있을 경우 실패하기 때문이었습니다!
유니크 인덱스 생성 실패: 유니크 인덱스 생성 시 데이터 중복으로 인해 실패할 수 있습니다. 기존 데이터에 이미 유니크 조건을 위반하는 레코드가 있을 경우, 유니크 인덱스 생성이 실패합니다
dev 환경에서 row를 전부 지우고 부팅해보니 생성됩니다.
인덱스를 검색해 보니 다음과 같이 나옵니다.
ticket,0,PRIMARY,1,subscription_plan_id,A,0,,,"",BTREE,"","",YES,
ticket,0,UKuniqueIdentifier123,1,vehicle_identifier,A,0,,,YES,BTREE,"","",YES,
ticket,0,UKuniqueIdentifier123,2,plan_type,A,0,,,YES,BTREE,"","",YES,
ticket,0,UKuniqueIdentifier123,3,zone_identifier,A,0,,,YES,BTREE,"","",YES,
ticket,0,UKuniqueIdentifier123,4,is_archived,A,0,,,YES,BTREE,"","",YES,
ticket,0,UKuniqueIdentifier123,5,current_status,A,0,,,YES,BTREE,"","",YES,
ticket,0,UKuniqueIdentifier123,6,activation_date,A,0,,,YES,BTREE,"","",YES,
ticket,0,UKuniqueIdentifier123,7,expiration_date,A,0,,,YES,BTREE,"","",YES,
ticket,0,UKuniqueIdentifier123,8,archive_date,A,0,,,YES,BTREE,"","",YES,
ticket,1,IDX_SUBSCRIPTION_ZONE,1,zone_id,A,0,,,YES,BTREE,"","",YES,
ticket,1,IDX_SUBSCRIPTION_ACTIVATION,1,activation_date,D,0,,,YES,BTREE,"","",YES,
ticket,1,IDX_SUBSCRIPTION_EXPIRATION,1,expiration_date,D,0,,,YES,BTREE,"","",YES,
ticket,1,IDX_SUBSCRIPTION_EXPIRATION,2,zone_id,A,0,,,YES,BTREE,"","",YES,
ticket,1,IDX_SUBSCRIPTION_EXPIRATION,3,activation_date,A,0,,,YES,BTREE,"","",YES,
ticket,1,IDX_SUBSCRIPTION_VEHICLE_IDENTIFIER,1,vehicle_identifier,A,0,,,YES,BTREE,"","",YES,
ticket,1,IDX_SUBSCRIPTION_VEHICLE_IDENTIFIER_LAST_FOUR,1,vehicle_identifier_last_four,A,0,,,YES,BTREE,"","",YES,
따라서 이미 데이터가 존재하는 환경에서 데이터를 지울 수 없는 경우 (stg 환경) 다음과 같이 수동으로 유니크 인덱스를 만들어주어야 합니다.
ALTER TABLE ticket
ADD UNIQUE INDEX idx_unique_ticket (ticketType, carNumber, zoneId, startAt, endAt, isDeleted, status);
잠깐 질문! Distinct로 안 되나 ?
Distinct 연산으로 간단하게 해결할 수 없겠느냐는 질문을 받았는데요 !
A. Distinct 연산은 특정 쿼리 결과에서 중복된 레코드를 제거하는 데 사용됩니다. 그러나 이 경우, 문제의 본질은 데이터 조회 시점에서 중복을 제거하는 것이 아니라, 데이터가 데이터베이스에 저장될 때 중복을 방지하는 것입니다. Distinct를 사용하면 이미 데이터베이스에 저장된 후의 조회 결과에서만 중복을 제거할 수 있으며, 실제 데이터 삽입 과정에서 중복을 방지할 수는 없습니다. 이는 Distinct 연산과는 별개의 접근 방식이 필요함을 의미합니다.
주의할 점
새로운 레코드가 INSERT 되거나 인덱스 칼럼의 값이 변경되는 경우에는 인덱스 쓰기 작업이 필요하다. 그런데 유니크 인덱스의 키 값을 쓸 때는 중복된 값이 있는지 없는지 체크하는 과정이 한 단계 더 필요하다. 그래서 유니크하지 않은 세컨더리 인덱스의 쓰기보다 느리다. 그런데 MySQL에서는 유니크 인덱스에서 중복된 값을 체크할 때는 읽기 잠금을 사용하고, 쓰기를 할 때는 쓰기 잠금을 사용하는데 이 과정에서 데드락이 아주 빈번히 발생한다. 또한 InnoDB 스토리지 엔진에는 인덱스 키의 저장을 버퍼링하기 위해 체인지 버퍼가 사용된다. 그래서 인덱스의 저장이나 변경 작업이 상당히 빨리 처리되지만, 안타깝게도 유니크 인덱스는 반드시 중복 체크를 해야 하므로 작업 자체를 버퍼링하지 못한다. 이 때문에 유니크 인덱스는 일반 세컨더리 인덱스보다 변경 작업이 더 느리게 작동한다.
-<Real MySQL 8.0>
해결 2 - 보상 트랜잭션
DB에서의 정합성 문제에 대해서는, 데이터베이스에 INSERT하는 시점에서 유니크함을 관리하는 방식으로 위에서 설명한 방법으로 해결할 수 있습니다. 그러나 MSA(Microservice Architecture) 분산 환경에서 서비스 간 통신에서 발생하는 정합성 문제—즉, 꼭 데이터베이스 정합성만이 아니라, 전체 시스템의 일관성을 유지하는 문제에 대해서도 고려해야 합니다.
다양한 일관성 모델을 고려해보자
분산 시스템에서 일관성을 관리하는 접근 방법에는 여러 가지가 있으며, 각각의 일관성 모델이 존재합니다. 가장 흔히 논의되는 일관성 모델은 강한 일관성, 약한 일관성, 그리고 최종 일관성입니다.
일관성 모델
- 강한 일관성: 모든 읽기 연산은 가장 최근에 갱신된 결과를 반환한다. 다시 말해서 클라이언트는 절대로 낡은 데이터를 보지 못한다.
- 약한 일관성: 읽기 연산은 가장 최근에 갱신된 결과를 반환하지 못할 수 있다.
- 최종 일관성: 약한 일관성의 한 형태로, 갱신 결과가 결국에는 모든 사본에 반영(즉, 동기화)되는 모델이다.
- <가상 면접 사례로 배우는 대규모 시스템 설계 기초>
이와 같이 일관성 모델에는 강한 일관성(Strong Consistency), 약한 일관성(Weak Consistency), 그리고 최종 일관성(Eventual Consistency)이 있습니다. 각각의 모델은 데이터의 일관성을 유지하는 방법에 대한 다른 접근 방식을 제시합니다. 지금까지 우리가 취한 접근 방식은 강한 일관성을 기반으로 하고 있었습니다. 즉, 쓰기 작업이 완료될 때 정합성이 바로 반영되어야 한다는 가정 하에 작업을 수행했습니다.
그러나 분산 시스템에서 강한 일관성을 항상 보장하는 것은 많은 자원을 소모하고 시스템의 복잡성을 증가시키며, 때로는 시스템의 성능을 저하시킬 수도 있습니다. 이런 이유로, 최종 일관성 모델이 자주 고려됩니다. 강한 일관성(Strong Consistency)이 모든 읽기 연산이 가장 최근에 갱신된 값을 반드시 반환해야 한다는 엄격한 요구사항을 가지는 반면, 최종 일관성은 시간이 지남에 따라 모든 복제본이 결국 일관된 상태에 도달하게 됩니다. 때문에, 분산 시스템의 성능과 가용성을 향상시키는 데 유리하며, 네트워크 분할이나 지연과 같은 문제에 대해 더 탄력적으로 대응할 수 있게 합니다.
최종 일관성 모델을 고려해봄직한 이유
"얻는 게 있으면 잃는 게 있다"는 트레이드 오프 법칙이 항상 존재합니다.
CAP 정리를 빼놓을 수 없죠. CAP 정리에 따르면 분산 시스템에서 일관성(Consistency), 가용성(Availability), 네트워크 분할 허용(Partition tolerance) 중 두 가지만을 만족할 수 있다고 설명합니다. 이러한 이론적 배경을 바탕으로 최종 일관성(Eventual Consistency) 모델은 분산 시스템에서 실용적이고 현실적인 접근 방법을 제공합니다.
MSA 환경에서 이벤트 기반 아키텍처(EDA), 사가 패턴을 이용한 최종 일관성 보장 방법은 시스템의 복잡성과 네트워크 지연, 서비스 장애 등 다양한 운영 환경의 문제에 유연하게 대응할 수 있게 해 주기 때문에 반드시 전통적인(?) 관점의 "강한 일관성"만을 고집하는 것이 정답은 아닐 수 있다는 생각입니다.
현재 문제를 최종 일관성, 보상 트랜잭션으로 푼다면?
최종 일관성 모델을 적용하여, 시스템 전반의 일관성을 관리하는 방법 중 하나는 "보상 트랜잭션(Compensating Transaction)"을 사용하는 것입니다. 보상 트랜잭션은 이미 완료된 트랜잭션의 효과를 취소하거나 수정하여 시스템의 일관성을 복원하는 방법입니다.
예를 들어, 티켓 서비스에서 중복 등록 문제를 최종 일관성 모델로 해결하기 위해, 처음 티켓 등록 요청이 들어오면 시스템은 해당 요청을 수락하고 처리합니다. 만약 동일한 요청이 다시 수신되어 중복 등록이 감지되면, 시스템은 보상 트랜잭션을 실행하여 이전에 등록된 티켓을 취소하거나 수정합니다.
예시 코드
public Ticket registerTicket(TicketRegistrationRequest request) {
Ticket registeredTicket = ticketService.registerTicket(request);
ticketService.compensateIfDuplicate(registeredTicket);
return registeredTicket;
}@Transactional
public Ticket registerTicket(TicketRegistrationRequest request) {
// 티켓 등록 로직
Ticket ticket = new Ticket(request);
return ticketRepository.save(ticket);
}
public void compensateIfDuplicate(Ticket ticket) {
// 중복 검사 로직
List<Ticket> duplicates = ticketRepository.findDuplicates(ticket);
if (!duplicates.isEmpty()) {
// 보상 트랜잭션 실행
duplicates.forEach(this::deleteTicket);
}
}
이벤트 기반의 비동기 처리
public class TicketEventHandler {
@KafkaListener(topics = "ticket-registration-events", groupId = "ticket-service")
public void onTicketRegistered(TicketRegistrationEvent event) {
// 중복 티켓 검사 로직
boolean isDuplicate = ticketService.checkForDuplicate(event);
if (isDuplicate) {
// 보상 트랜잭션 실행
ticketService.compensateDuplicateRegistration(event);
}
}
}
몇 가지 남은 질문들
클라이언트의 중복 요청을 서버에서 처리하는 문제에 대해 위와 같이 두 가지 해결 방식을 제시해보았습니다. 실제로는 첫 번째 방식인 DB 수준에서 강한 정합성을 유지하는 모델로 해결하였습니다. 간단한 사족을 달면서 글을 마무리하겠습니다.
모든 것은 기회 비용 (그리고 균형)
'모든 것은 기회 비용'이라는 점을 한 번 더 상기했으면 합니다.
데이터베이스 단에서의 처리는 강한 일관성 모델을 기반으로 하며, 이는 시스템의 견고함을 보장합니다. 그러나 견고함이 곧 유연성의 결여를 의미할 수도 있는 것 같습니다. 이러한 결정을 하면서 팀 내에서 나눈 이야기는 '이는 우리가 완성된 플랫폼을 전제로 하는 것이다'라는 인식을 가져야한다는 것이었습니다. 그만큼 데이터베이스의 제약을 통해 시스템이 견고해지는 것은 변경에 취약해지고 어려워진다는 것이기 때문이죠. 이러한 점을 고려할 때, 문제의 본질과 시스템의 요구 사항에 맞는 균형점을 찾는 것이 중요하다고 생각합니다.
프론트에서 1차적인 검증 필요성
한편, 서버 측에서의 검증과 별개로 클라이언트 측에서의 검증 역시 중요합니다. 서버 측에서의 검증과 처리는 필수적이지만, 서버 측 검증은 항상 비쌉니다.
무엇보다도, 중복 등록 문제는 단지 등록 과정에서만 발생하는 것이 아닙니다. 사용자가 인터페이스 상의 다른 버튼들을 연속으로 누를 때도 비슷한 문제가 발생할 수 있습니다. 모든 요청에 대해서 여러 번 중복 요청이 발생한다면, 서버는 동일하게 응답은 하겠고 단순 조회의 경우 문제가 티나지는 않겠지만 불필요한 부하가 지속될 것이고 결론적으로는 사용자 경험과 시스템 전반에 영향을 미치겠죠.
따라서 프론트의 프레임워크 단에서의 일차적인 방어도 역시 필수입니다.
'이슈와해결' 카테고리의 다른 글
| 백엔드 응답 속도 500ms 줄이고 7배 개선한 썰 (2) | 2024.04.12 |
|---|---|
| 자바에서 동시성 문제를 다루는 n가지 방법들(feat. 주식 매수) (6) | 2024.03.28 |
| 예외 알림 프로세스에서 OOM을 방지하며 중복 처리를 위한 Marking 방식 (WeakHashMap) (1) | 2024.02.18 |
| Gson 베이스 프로젝트에서 LocalDateTime 컨버팅 지옥 탈출하기 (0) | 2024.02.18 |
| @RequestBody 컨텐츠 유실 문제 - 컨트롤러에도 디버깅이 찍히지 않으면 어디를 봐야할까? (1) | 2023.12.21 |



