이 글에 대해서
자바에서 동시성 문제를 다루는 n가지 방법을 소개합니다. 동시성 이슈가 많이 발생하면서도 중요하기도 한 주식 거래 시스템을 예로 들어, 매수와 매도 상황에서 발생할 수 있는 동시성 문제를 정의하고, 이를 해결하는 다양한 해법들 및 테스트 결과를 소개합니다. 예제로 사용한 소스코드는 다음 링크에서 보실 수 있습니다.
https://github.com/renechoi/study/tree/main/java-concurrency-problem/src
전제
기술적 범위
먼저, 본 글에서 다루는 기술적 범위의 한계는 다음과 같다.
- 서버 인스턴스는 한 대로 가정한다. 분산 환경의 동시성 문제는 더 포괄적인 주제로 분리된 지면을 통해 소개하고자 한다.
- 해결 아이디어에서 데이터베이스를 이용한 해결 방법은 제외한다. 따라서 본 글에서 제시하는 동시성 문제의 대안은 어플리케이션 접근법에 한정된다. 마찬가지로 데이터베이스 주제만으로도 방대한 주제가 될 수 있으며, 접근이 다를 수 있기 때문에 분리했다.
주제의 범위
동시성 이슈를 의도적으로 발생시켜 해결하는 방식을 탐구하는 데 목적이 있다. 이를 위해 간소화된 아키텍처와 어플리케이션 구조, 스타일을 사용하였다.
- Database는 h2 DB와 JPA를 이용하였다.
- 포트폴리오 엔티티에서는 애플 주식만을 담는 것으로 가정하여
애플주식 수량 변수(long aaplStockAmount)를 사용하였다.
문제 상황 정의
동시성 문제란, 여러 사용자가 동시에 하나의 대상에 요청을 할 때, 시스템이 어떤 순서로 이를 처리할지 결정해야 하는 상황을 말한다. 예를 들어, 두 개의 동일한 매수 요청이 동시에 하나의 포트폴리오에 요청된다면, 시스템은 한 번에 한 요청만 성공시켜야 하며, 나머지 요청은 대기하게 만들어야 한다.
현 문제에서 중복 요청에 대한 정의
중복 요청이 무엇이냐에 대한 문제 정의가 필요하다. 문제의 단순화를 위하여 현재 프로젝트에서는 동일한 포트폴리오에 동일한 주식 수량에 대한 입금 요청이 1000ms 미만으로 발생했을 때 중복 요청이 발생했다고 정의한다.
해결하고자 하는 목표
이 문제에서 달성하고자 하는 목표는 다음과 같다.
- 동시 매수 요청의 순차적 처리: 동시에 여러 매수 요청이 발생할 경우, 이를 순차적으로 처리하여 한 번에 하나의 요청만 성공시키고, 나머지는 실패 처리하여야 한다.
동시성 문제가 발생하는 코드
먼저 동시성 방어 로직이 없는 구현과 해당 코드를 통한 문제 상황을 재현해보자.
@RestController
@RequestMapping("/stock-portfolio/normal")
@RequiredArgsConstructor
public class NonProtectedStockTradingController {
private final StockPortfolioRepositoryAdapter portfolioRepository;
@PostMapping("/{id}/buy")
public StockPortfolio buyStock(@PathVariable Long id, @RequestBody BuyOrderRequest request) {
StockPortfolio portfolio = portfolioRepository.findById(id).orElseThrow(EntityNotFoundException::new);
if (portfolio.isRequestDelayBelowMs(1000)) {
throw new IllegalStateException("매수 요청이 너무 자주 발생했습니다. 나중에 다시 시도해 주세요.");
}
portfolio.addStocks(request.getAaplStockAmount());
return portfolioRepository.save(portfolio);
}
@PostMapping("/{id}/sell")
public StockPortfolio sellStock(@PathVariable Long id, @RequestBody SellOrderRequest request) {
Long amount = request.getAaplStockAmount();
StockPortfolio stockPortfolio = portfolioRepository.findById(id).orElseThrow(EntityNotFoundException::new);
if (stockPortfolio.getAaplStockAmount() < amount) {
throw new RuntimeException("매도 가능한 주식이 없습니다.");
}
stockPortfolio.subtractStocks(amount);
return portfolioRepository.save(stockPortfolio);
}
@GetMapping("/{id}")
public StockPortfolio fetchStock(@PathVariable Long id) {
return portfolioRepository.findById(id).orElseThrow(EntityNotFoundException::new);
}
}
# non-protected-stock-trading-api.feature
Feature: 동시성 방어 로직이 없는 경우의 테스트
Scenario: 동시 매수 요청의 순차적 처리 - 제한 준수
Given "normal" API를 호출
Given 초기 주식 수가 10000인 포트폴리오가 주어졌을 때
And 다음 스텝을 위해 1초간 딜레이
And 제한 간격을 준수하여 500을 매수하려고 2회 시도한다
When 포트폴리오를 조회하면
And 포트폴리오에 주식 수는 11000으로 확인되어야 한다
Scenario: 동시 매수 요청의 순차적 처리 - 제한 미준수
Given "normal" API를 호출
Given 초기 주식 수가 10000인 포트폴리오가 주어졌을 때
And 다음 스텝을 위해 1초간 딜레이
And 2개의 스레드가 동시에 500을 매수하려고 시도한다
When 포트폴리오를 조회하면
And 의도한 예외는 발생하지 않는다
And 주식 수는 11000 혹은 10500으로 확인된다
public class StockPortfolioStepDef implements En {
private StockPortfolio stockPortfolio;
private AtomicStockPortfolio atomicStockPortfolio;
private ExtractableResponse<Response> fetchResponse;
private List<ExtractableResponse<Response>> buyOrderResponses;
@Before
public void setup() {
stockPortfolio = null;
fetchResponse = null;
atomicStockPortfolio = null;
buyOrderResponses = new ArrayList<>();
}
@Before
public void setupBackground(Scenario scenario) {
UrlDynamicContext.apiType = scenario.getName();
}
public StockPortfolioStepDef() {
Given("{string} API를 호출", this::setupApiUrl);
Given("초기 주식 수가 {long}인 포트폴리오가 주어졌을 때", this::createPortfolioAndStockAmount);
Given("초기 주식 수가 {long}인 Atomic 포트폴리오가 주어졌을 때", this::createAtomicPortfolioAndStockAmount);
And("다음 스텝을 위해 {int}초간 딜레이", this::delayForNextStep);
And("제한 간격을 준수하여 {long}을 매수하려고 {int}회 시도한다", this::doExecuteValidatedRequestForBuyOrder);
And("{int}개의 스레드가 동시에 {long}을 매수하려고 시도한다", this::doExecuteRequestForBuyOrderRacingMultipleThread);
And("{int}개의 스레드가 동시에 Atomic {long}을 매수하려고 시도한다", this::doExecuteRequestForAtomicBuyOrderRacingMultipleThread);
When("포트폴리오를 조회하면", this::fetchPortfolio);
When("Atomic 포트폴리오를 조회하면", this::fetchAtomicPortfolio);
Then("의도한 예외가 확인된다", this::verifyExpectedException);
Then("포트폴리오에 주식 수는 {long}으로 확인되어야 한다", this::verifyTotalStockAmount);
Then("Atomic 포트폴리오에 주식 수는 {long}으로 확인되어야 한다", this::verifyAtomicTotalStockAmount);
And("의도한 예외는 발생하지 않는다", this::verifyExpectedExceptionNotFound);
And("주식 수는 {long} 혹은 {long}으로 확인된다", this::totalStockAmountFoundWithTwoPossibleAmount);
}
private void setupApiUrl(String apiType) {
UrlDynamicContext.apiType = apiType;
}
private void verifyExpectedException() {
assertTrue(buyOrderResponses.stream().anyMatch(response -> response.statusCode() != 200), "의도한 예외가 확인되지 않았습니다.");
}
private void verifyExpectedExceptionNotFound() {
assertTrue(buyOrderResponses.stream().noneMatch(response -> response.statusCode() != 200), "의도한 예외가 확인되지 않았습니다.");
}
private void doExecuteValidatedRequestForBuyOrder(long amount, int count) {
for (int i = 0; i < count; i++) {
buyStock(stockPortfolio.getId(), BuyOrderRequest.of(amount));
delayForNextStep(1);
}
}
private void createPortfolioAndStockAmount(long amount) {
stockPortfolio = parsePortfolio(createPortfolio());
delayForNextStep(1);
buyStock(stockPortfolio.getId(), BuyOrderRequest.of(amount));
}
private void createAtomicPortfolioAndStockAmount(long amount) {
atomicStockPortfolio = parseAtomicPortfolio(createAtomicPortfolio());
delayForNextStep(1);
buyStock(atomicStockPortfolio.getId(), BuyOrderRequest.of(amount));
}
private void delayForNextStep(int delay) {
try {
Thread.sleep(delay * 1000L);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
private void doExecuteRequestForBuyOrderRacingMultipleThread(int threads, long amount) {
ExecutorService executorService = Executors.newFixedThreadPool(threads);
List<Future<ExtractableResponse<Response>>> futures = new ArrayList<>();
for (int i = 0; i < threads; i++) {
Future<ExtractableResponse<Response>> future = executorService.submit(() -> buyStock(stockPortfolio.getId(), BuyOrderRequest.of(amount)));
futures.add(future);
}
executorService.shutdown();
try {
if (!executorService.awaitTermination(1, TimeUnit.MINUTES)) {
throw new IllegalStateException("모든 매수 작업이 완료되지 않았습니다.");
}
for (Future<ExtractableResponse<Response>> future : futures) {
buyOrderResponses.add(future.get());
}
} catch (InterruptedException | ExecutionException e) {
Thread.currentThread().interrupt();
throw new RuntimeException("매수 작업을 기다리는 동안 인터럽트 발생", e);
}
}
private void doExecuteRequestForAtomicBuyOrderRacingMultipleThread(int threads, long amount) {
ExecutorService executorService = Executors.newFixedThreadPool(threads);
List<Future<ExtractableResponse<Response>>> futures = new ArrayList<>();
for (int i = 0; i < threads; i++) {
Future<ExtractableResponse<Response>> future = executorService.submit(() -> buyStock(atomicStockPortfolio.getId(), BuyOrderRequest.of(amount)));
futures.add(future);
}
executorService.shutdown();
try {
if (!executorService.awaitTermination(1, TimeUnit.MINUTES)) {
throw new IllegalStateException("모든 매수 작업이 완료되지 않았습니다.");
}
for (Future<ExtractableResponse<Response>> future : futures) {
buyOrderResponses.add(future.get());
}
} catch (InterruptedException | ExecutionException e) {
Thread.currentThread().interrupt();
throw new RuntimeException("매수 작업을 기다리는 동안 인터럽트 발생", e);
}
}
private void fetchPortfolio() {
fetchResponse = fetchAmount(stockPortfolio.getId());
stockPortfolio = parsePortfolio(fetchResponse);
}
private void fetchAtomicPortfolio() {
fetchResponse = fetchAmount(atomicStockPortfolio.getId());
atomicStockPortfolio = parseAtomicPortfolio(fetchResponse);
}
private void verifyTotalStockAmount(long expectedAmount) {
assertEquals(expectedAmount, stockPortfolio.getAaplStockAmount(), "기대한 주식이 일치하지 않습니다");
}
private void totalStockAmountFoundWithTwoPossibleAmount(long expectedAmount1, long expectedAmount2) {
long aaplStockAmount = stockPortfolio.getAaplStockAmount();
boolean isAmountCorrect = aaplStockAmount == expectedAmount1 || aaplStockAmount == expectedAmount2;
assertTrue(isAmountCorrect, "주식이 예상한 " + expectedAmount1 + " 혹은 " + expectedAmount2 + "와 일치하지 않습니다. 실제 주식: " + aaplStockAmount);
}
private void verifyAtomicTotalStockAmount(long expectedAmount) {
assertEquals(expectedAmount, atomicStockPortfolio.getAaplStockAmount(), "기대한 주식이 일치하지 않습니다");
}
}결과 분석
"동시 매수 요청의 순차적 처리 - 제한 미준수" 시나리오는 동시에 여러 매수 요청이 처리될 때, 시스템이 이를 올바르게 처리하지 못하고, 잔고가 예상치 못한 방식으로 증가하는 상황을 재현한다. 일반적인 동시성 문제의 예시로, 여러 스레드(또는 요청)가 같은 리소스에 접근하여 변경을 시도할 때, 각각의 변경이 겹치게 되어 예측 불가능한 결과를 초래하는 상황을 보여준다.
레이싱 컨디션의 발생
이 문제를 실제로 재현하기 위한 코드로 테스트 코드의 doExecuteRequestForBuyOrderRacingMultipleThread 메서드가 동시성 문제를 발생시키는 핵심적인 부분이다. 이 메서드는 여러 스레드를 생성하여, 동일한 주식 포트폴리오에 대해 동시에 매수 요청을 보내도록 설계되었다.
즉, 테스트 코드를 통해 실제 프로덕션 환경에서 발생할 수 있는 레이싱 컨디션을 재현한다. 여기서 의도한 바는 동시에 실행되는 스레드들 사이에서 어떠한 동기화 메커니즘도 적용되지 않았기 때문에, 각각의 요청이 서로의 작업 결과를 알지 못하고 독립적으로 실행되어 최종적으로 데이터 무결성에 문제를 초래하는 것 이다.
프로덕션 코드에서의 문제
프로덕션 코드에 적용된 로직에서는, 각 요청이 처리되는 과정에서 동일한 포트폴리오 객체에 대한 동기화가 이루어지지 않는다. 결과적으로, '동시 매수 요청의 순차적 처리 - 제한 미준수' 시나리오에서 볼 수 있듯이, 주식 수량의 최종 결과가 예측 불가능하게 된다.
특히, 동시에 실행된 요청들이 거의 동일한 시점에 처리되었을 때, 한 스레드가 작업을 완료하고 데이터를 저장하는 사이 다른 스레드도 동일한 작업을 수행하기 때문에, 결과적으로 주식 수량이 '11000 혹은 10500'으로 확인되는 현상이 발생한다.
이는 한 스레드의 변경이 다른 스레드에 의해 덮어쓰여지거나, 한 스레드가 변경을 시작하기 전에 이미 다른 스레드에 의해 변경된 상태를 읽어서 발생하는 문제이다.


1. 락 기반 동기화
첫 번째로 가능한 해결 방법은 락이다. Java에서는 synchronized 키워드나 ReentrantLock 같은 메커니즘을 사용하여 특정 코드 블록의 실행을 한 스레드에 의해서만 수행되도록 제한할 수 있다.
1) synchronized 메서드 또는 블록 사용:
Synchronized 키워드를 사용하면, 특정 객체에 대한 락을 획득하고, 해당 락이 해제될 때까지 다른 스레드들이 락을 획득하려고 시도하는 것을 방지한다.
JVM 내부에서, synchronized에 의한 동기화는 메인 메모리와 스레드가 작업하는 로컬 메모리 사이의 일관성을 보장한다. 즉, synchronized 블록에 진입하거나 빠져나올 때, 모든 로컬 캐시(스레드가 보유한 변수의 복사본)가 메인 메모리와 동기화되도록 하여, 모든 스레드가 최신의 데이터를 볼 수 있게 한다.
컴파일러와 CPU는 성능 최적화를 위해 명령어의 실행 순서를 변경할 수 있는데 synchronized 블록의 경계에서는, 이러한 최적화가 변수의 읽기와 쓰기 순서에 영향을 미치지 않도록 제한되기 때문이다.
다시 말해, synchronized 블록 내에서의 모든 작업은 블록을 빠져나올 때까지 메인 메모리에 반영되도록 하여 동기화된 작업이 안전한 메모리 가시성을 갖추도록 한다.
Synchronized 동작 원리
좀 더 상세히 동작 원리를 살펴보자. synchronized 키워드가 적용된 메서드나 코드 블록은 다수의 스레드에 의해 동시에 실행되는 것을 방지함으로써, 공유 자원에 대한 동시 접근을 제어한다.

그림에서처럼 코드 블럭에 가장 완벽한 락을 건다고 볼 수 있다. synchronized 블록에 진입하거나 이를 빠져나갈 때, 핵심은 해당 스레드가 액세스하는 변수들을 메인 메모리와 동기화한다는 것이다. 즉, JVM에 올라온 로컬 캐시(예: L1, L2, L3)에 저장된 변수의 복사본이 메인 메모리와 일치하도록 보장한다. 그럼으로써 모든 스레드가 최신 데이터를 볼 수 있게 되는 것이다. 말하자면, 매번 메인 메모리에 다녀온다는 것이라고도 할 수 있겠다.

2) ReentrantLock 사용:
ReentrantLock은 java.util.concurrent.locks 패키지에 속한 클래스로, synchronized 키워드보다 더 세밀한 동기화 제어를 가능하게 한다. ReentrantLock을 사용하면 락을 명시적으로 획득하고 해제할 수 있으며, tryLock() 메서드를 통해 락 획득 시도가 실패했을 때 즉시 다른 작업을 수행할 수 있도록 할 수 있다.
ReentrantLock의 주요 이점 중 하나는 CPU 캐시와 메인 메모리 간의 동기화를 명시적으로 제어할 수 있다는 것이다. 락을 획득하면 스레드는 메인 메모리에서 최신 데이터를 읽어 들이며, 락을 해제할 때는 변경사항을 메인 메모리에 반영한다. 이를 통해 동시에 실행되는 다른 스레드들이 보는 데이터의 일관성을 보장할 수 있다.
또한, ReentrantLock은 락을 획득하고 해제하는 과정에서 CPU 캐시의 일관성을 유지하기 위해 필요한 메모리 배리어(memory barrier) 작업을 자동으로 처리한다. 결국 메커니즘은 Synchronized와 동일하게 에서 메인 메모리와 CPU 캐시 사이의 동기화를 보장하는 방식으로, 모든 스레드가 최신의 데이터를 볼 수 있도록 하는 것이고, 다만 차이점은 기능적인 면에서 락 획득 해제 등의 제어, 둥잔 제어, 시간 설정 등의 편의성을 제공하는 점이 차이가 있다고 볼 수 있다.
구현 예시 - synchronized
@RestController
@RequestMapping("/stock-portfolio/synchronized")
@RequiredArgsConstructor
public class SynchronizedStockTradingController {
private final StockPortfolioRepositoryAdapter stockPortfolioRepository;
private final Object lock = new Object();
@PostMapping("/{id}/buy")
public StockPortfolio buyStock(@PathVariable Long id, @RequestBody BuyOrderRequest request) {
synchronized (lock) {
StockPortfolio stockPortfolio = stockPortfolioRepository.findById(id).orElseThrow(EntityNotFoundException::new);
if (stockPortfolio.isRequestDelayBelowMs(1000)) {
throw new IllegalStateException("매수 요청이 너무 자주 발생했습니다. 나중에 다시 시도해 주세요.");
}
stockPortfolio.addStocks(request.getAaplStockAmount());
return stockPortfolioRepository.save(stockPortfolio);
}
}
@PostMapping("/{id}/sell")
public StockPortfolio sellStock(@PathVariable Long id, @RequestBody SellOrderRequest request) {
synchronized (lock) {
Long amount = request.getAaplStockAmount();
StockPortfolio portfolio = stockPortfolioRepository.findById(id).orElseThrow(EntityNotFoundException::new);
if (portfolio.getAaplStockAmount() < amount) {
throw new RuntimeException("매도 가능한 주식이 없습니다.");
}
portfolio.subtractStocks(amount);
return stockPortfolioRepository.save(portfolio);
}
}
@GetMapping("/{id}")
public StockPortfolio fetchStock(@PathVariable Long id) {
synchronized (lock) {
return stockPortfolioRepository.findById(id).orElseThrow(EntityNotFoundException::new);
}
}
}# synchronized-stock-trading-api.feature
Feature: 락 기반 접근의 synchronized 해결 방식 테스트
동시성 문제를 해결하기 위한 synchronized 키워드 사용 방식을 테스트하여,
매수, 매도 및 조회 기능에서의 데이터 일관성과 정확성을 검증합니다.
Scenario: 동시 매수 요청의 순차적 처리
Given "synchronized" API를 호출
Given 초기 주식 수가 10000인 포트폴리오가 주어졌을 때
And 다음 스텝을 위해 1초간 딜레이
And 2개의 스레드가 동시에 500을 매수하려고 시도한다
When 포트폴리오를 조회하면
Then 의도한 예외가 확인된다
Then 포트폴리오에 주식 수는 10500으로 확인되어야 한다구현 예시 - ReentrantLock
@RestController
@RequestMapping("/stock-portfolio/reentrantLock")
@RequiredArgsConstructor
public class ReentrantStockPortfolioController {
private final StockPortfolioRepositoryAdapter portfolioRepository;
private final ReentrantLock lock = new ReentrantLock();
@PostMapping("/{id}/buy")
public StockPortfolio buyStock(@PathVariable Long id, @RequestBody BuyOrderRequest request) {
lock.lock();
try {
StockPortfolio stockPortfolio = portfolioRepository.findById(id)
.orElseThrow(EntityNotFoundException::new);
if (stockPortfolio.isRequestDelayBelowMs(1000)) {
throw new IllegalStateException("매수 요청이 너무 자주 발생했습니다. 나중에 다시 시도해 주세요.");
}
stockPortfolio.addStocks(request.getAaplStockAmount());
return portfolioRepository.save(stockPortfolio);
} finally {
lock.unlock();
}
}
@PostMapping("/{id}/sell")
public StockPortfolio sellStock(@PathVariable Long id, @RequestBody SellOrderRequest request) {
lock.lock();
try {
StockPortfolio stockPortfolio = portfolioRepository.findById(id)
.orElseThrow(EntityNotFoundException::new);
Long amount = request.getAaplStockAmount();
if (stockPortfolio.getAaplStockAmount() < amount) {
throw new RuntimeException("매도 가능한 주식이 없습니다.");
}
stockPortfolio.subtractStocks(amount);
return portfolioRepository.save(stockPortfolio);
} finally {
lock.unlock();
}
}
@GetMapping("/{id}")
public StockPortfolio fetchStock(@PathVariable Long id) {
lock.lock();
try {
return portfolioRepository.findById(id)
.orElseThrow(EntityNotFoundException::new);
} finally {
lock.unlock();
}
}
} Feature: 락 기반 접근의 reentrantLock 해결 방식 테스트
동시성 문제를 해결하기 위한 reentrantLock 키워드 사용 방식을 테스트하여,
매수, 매도 및 조회 기능에서의 데이터 일관성과 정확성을 검증합니다.
Scenario: 동시 매수 요청의 순차적 처리
Given "reentrantLock" API를 호출
Given 초기 주식 수가 10000인 포트폴리오가 주어졌을 때
And 다음 스텝을 위해 1초간 딜레이
And 2개의 스레드가 동시에 500을 매수하려고 시도한다
When 포트폴리오를 조회하면
Then 의도한 예외가 확인된다
Then 포트폴리오에 주식 수는 10500으로 확인되어야 한다결과 분석
락 기반 동기화 방식인 synchronized와 ReentrantLock을 이용해 동시성 문제를 해결하는 접근 방법은 테스트 결과 모두 기대한 대로 작동하여, 데이터의 일관성과 정확성을 보장하는 것으로 확인되었다.
synchronized 방식
synchronized 키워드를 사용한 동기화 방식은 Java 내장 기능으로, 간단한 구현을 통해 코드 블록을 동시에 하나의 스레드만 실행할 수 있게 하는 방법이다. 이 방식은 동시 매수 요청 시나리오에서 요청들이 순차적으로 처리되도록 하여, 주식 수량이 10500으로 정확하게 유지되는 것을 보장한다. 각 요청은 synchronized 블록 내에서 처리되며, 이 블록은 단 하나의 스레드만 접근할 수 있도록 한다. 따라서, 한 번에 하나의 요청만이 수행되며, 데이터의 일관성이 유지된다.
ReentrantLock 방식
ReentrantLock을 사용한 접근 방법은 synchronized보다 더 세밀한 제어가 가능하며, 명시적으로 락을 획득하고 해제하는 기능을 제공한다. 이 방식 역시 동시 매수 요청 시나리오에서 주식 수량의 정확성을 보장하며, 특히 락의 해제를 보장하는 finally 블록을 사용함으로써 락이 항상 적절히 해제되도록 한다. 이를 통해 데드락(deadlock)의 위험 없이, 각 요청이 안전하게 처리된다.
두 방식 모두, 테스트 케이스에서 의도한 예외 상황 없이 정상적으로 동작하는 것을 확인할 수 있었다. 주식 수량은 동시성 문제 없이 예상대로 10500으로 정확하게 유지되었다. 즉, 락을 통한 동기화가 동시에 발생하는 요청들 사이에서 데이터 무결성을 효과적으로 유지할 수 있음을 보여주는 결과이다.


2. 락 프리 접근 1: CAS 알고리즘 (Atomic 클래스 사용)
이번에는 락을 걸지 않고 해결하는 방법으로 Atomic한 접근을 고려해보자. 전통적인 락 기반 동기화 방법 대신, 더 높은 동시성을 달성하고 성능 병목을 줄이기 위한 대안으로 락 프리(lock-free) 프로그래밍 기법이 제안되었다고 한다. 이러한 접근법의 핵심은 공유 자원에 대한 동시 접근을 관리하는 데 있어서, 락의 사용을 최소화하거나 전혀 사용하지 않는 것인데, 그 중에 하나가 CAS(Compare-And-Swap) 알고리즘을 사용하는 것이다.
CAS 알고리즘
CAS 알고리즘이란 무엇일까?
핵심원리는 메모리 위치의 값을 확인(Compare)하고, 예상되는 값이 현재 메모리 위치에 저장된 값과 일치하는 경우에만 새로운 값으로 업데이트(Swap)하는 것이다. 예를 들어보자.
1000원이 있는 계좌에 100원을 입금하려고 한다. 예상되는 값은 당연히 1100원일 것이다. 그 과정을 컴퓨터는 어떻게 CAS 알고리즘으로 알까?
입금 작업을 실행하기 전, CAS 알고리즘은 먼저 계좌의 현재 잔액이 1000원인지 확인한다(Compare). 이 값이 예상과 일치한다면, 잔액을 1100원으로 업데이트(Swap)한다. 만약 이 사이에 다른 스레드가 잔액을 변경했다면, 즉 1000원이라는 예상 값이 현재 값과 일치하지 않는다면, 업데이트는 수행되지 않는다.
Java 에서는 AtomicLong과 같은 원자적 클래스를 통해 Java에서 구현할 수 있다. AtomicLong 클래스는 내부적으로 CAS 연산을 사용하여 스레드 안전하게 값 변경을 수행한다.
어째서 CAS 알고리즘이 전통적인 락 방식에 비해 성능적인 이점이 있다고 하는 것일까? 다음 그림에서처럼 락을 걸게 되면 Blocked, wasted time이 발생한다.

하지만 Compare and Swap의 경우 공유 자원을 사용할 때 해당 시점에만 스레드를 사용할 수 있어서 효율적이다.

그렇다면 궁금증이 드는 부분은 이것이다. 왜 원자적이라고 하는 것일까? 원자적이라는 말의 뜻은 도대체 무엇일까 ?!
원자적이라는 말의 뜻
원자적이라는 용어는 컴퓨터 과학에서 어떤 연산이 중단될 수 없는, 즉 '분할 불가능한' 단일 작업으로 수행된다는 것을 의미한다. 이 용어는 멀티스레드 환경에서 중요한 개념으로, 원자적 연산은 여러 스레드에 의해 동시에 수행될 때에도 시스템의 일관성을 유지하고 데이터 경쟁 조건을 방지한다.
원자적 연산의 중요성은 멀티스레드 환경에서 공유 자원에 접근할 때 발생할 수 있는 경쟁 조건(race conditions)을 방지하는 데 있다. 예를 들어 보자.i++ 은 안전할까? 단순한 연산 같아보이지만, 이와 같이 간단한 연산조차 멀티스레드 환경에서는 안전하지 않을 수 있다.
'원자적이지 않다면' 말이다. i++ 연산이 '읽기-수정하기-쓰기'의 세 부분으로 구성되어 있으며, 이 과정에서 다른 스레드가 개입하여 값이 예상과 다르게 변경될 수 있기 때문이다.
CAS (Compare-And-Swap)라는 원자적 연산
CAS 연산은 이러한 문제를 해결하기 위해 설계된 원자적 연산의 한 예이다. 위에서 언급한 것처럼 CAS는 크게 다음과 같은 두 부분으로 구성되어 있다.
- 비교(Compare): 목표 메모리 위치의 현재 값을 읽어온다. 이 값이 기대한 값(즉, 연산이 시작되기 전에 읽어온 값)과 동일한지 비교한다. 이 과정에서 현재 값과 기대 값이 일치하지 않는 경우, 즉 다른 스레드에 의해 값이 변경된 경우, 연산은 실패로 종료된다.
- 교환(Swap): 현재 값과 기대 값이 일치하는 경우에만, CAS 연산은 목표 메모리 위치에 새로운 값을 쓴다. 이 단계에서 중요한 점은, 비교 단계와 교환 단계 사이에 다른 어떠한 연산도 개입할 수 없다는 것이다. 즉, 이 두 단계는 분리될 수 없는 하나의 원자적 연산으로 수행된다.
이때 어떻게 연산 중에 발생할 수 있는 모든 경쟁 상태를 방지하는 것일까 하는 궁금증이 생긴다. 이에 대해서는 하드웨어 수준에서의 지원으로서 가능하다고 한다. 메모리 배리어(Memory Barriers)와 같은 메커니즘을 사용하여 명령어의 실행 순서를 강제하고, 캐시 일관성 프로토콜(Cache Coherence Protocols)을 통해 멀티코어 프로세서 시스템에서도 데이터의 일관성을 유지한다.
그렇다면 이제 자바에서 지원하는 Atomic 클래스를 활용하여 본 문제 상황을 해결하는 상황을 살펴보자.
예시: 매수 처리
- 초기 상태: 포트폴리오에 애플 주식의 현재 수량이 10,000 이라고 가정해보자. 이 상태에서 500, 300, 매수 요청이 발생한 상황을 생각해보면 다음과 같다.
- CAS 작업 전 준비:
AtomicLong을 사용하여 주식 수량을 관리한다. 이때, 매수 처리 전,AtomicLong의 현재 값(즉, 현재 주식 수량)을 확인한다. 이 값은 매수 요청을 처리하기 전의 기준점으로 사용된다. - CAS 연산 실행:
- 첫 번째 매수 요청(500주)에 대해,
AtomicLong의compareAndSet메서드를 호출하여 현재 주식 수량이 여전히 기준점인 10,000주인지 확인한다. 만약 동일하다면, 주식 수량을 10,500주로 업데이트한다. - 두 번째 매수 요청(300주)이 거의 동시에 들어온다. 이 요청 역시
compareAndSet을 사용하여 기준점 확인을 시도한다. 그러나 이 시점에서는 첫 번째 매수 요청에 의해 주식 수량이 이미 10,500주로 변경되었기 때문에, 기준점이 더 이상 유효하지 않다. - 따라서, 두 번째 매수 요청은 실패한다. 이후 재시도를 할 것인지 예외를 내릴 것인지는 구현에 따라 달라질 것이다. 만약 재시도를 하는 케이스라면, 새로운 기준점(10,500주)을 바탕으로
compareAndSet연산을 시도하여 주식 수량을 10,800주로 업데이트할 것이다.
- 첫 번째 매수 요청(500주)에 대해,
이 과정을 통해, AtomicLong을 사용한 CAS 연산은 락을 사용하지 않고도 동시성을 보장한다.
이 접근 방식의 핵심은 동시에 발생하는 여러 요청 사이에서 경쟁 조건 없이 공유 자원(이 경우 주식 수량)의 일관성을 유지한다는 점이다.
구현 코드는 다음과 같다.
구현 예시 - Atomic 클래스를 사용한 방식
@RestController
@RequestMapping("/stock-portfolio/atomic-approach")
@RequiredArgsConstructor
public class AtomicApproachBankAccountController {
private final AtomicPortfolioRepositoryAdapter AtomicStockPortfolioRepository;
@PostMapping("/{id}/buy")
public AtomicStockPortfolio buyStock(@PathVariable Long id, @RequestBody DepositRequest request) {
AtomicStockPortfolio atomicStockPortfolio = AtomicStockPortfolioRepository.findById(id).orElseThrow(EntityNotFoundException::new);
if (atomicStockPortfolio.isRequestDelayBelowMs(1000)) {
throw new IllegalStateException("매수 요청이 너무 자주 발생했습니다. 나중에 다시 시도해 주세요.");
}
atomicStockPortfolio.addStocks(request.getAaplStockAmount());
return AtomicStockPortfolioRepository.save(atomicStockPortfolio);
}
@PostMapping("/{id}/sell")
public AtomicStockPortfolio sellStock(@PathVariable Long id, @RequestBody WithdrawRequest request) {
Long amount = request.getAaplStockAmount();
AtomicStockPortfolio atomicStockPortfolio = AtomicStockPortfolioRepository.findById(id).orElseThrow(EntityNotFoundException::new);
if (atomicStockPortfolio.getAaplStockAmount() < amount) {
throw new RuntimeException("매도 가능한 주식이 없습니다.");
}
atomicStockPortfolio.subtractStocks(amount);
return AtomicStockPortfolioRepository.save(atomicStockPortfolio);
}
}# atomic-approach-stock-trading-api.feature
Feature: 락 free 접근의 atomic 해결 방식 테스트
Scenario: 동시 매수 요청의 순차적 처리
Given "atomic-approach" API를 호출
Given 초기 주식 수가 10000인 Atomic 포트폴리오가 주어졌을 때
And 다음 스텝을 위해 1초간 딜레이
And 2개의 스레드가 동시에 Atomic 500을 매수하려고 시도한다
When Atomic 포트폴리오를 조회하면
Then 의도한 예외가 확인된다
Then Atomic 포트폴리오에 주식 수는 10500으로 확인되어야 한다
@Entity
public class AtomicStockPortfolio {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String portfolioId;
private String owner;
/**
* AtomicLong으로 대체하여 원자적 연산을 보장
* AtomicLong 타입의 필드는 객체 생성 시 명시적으로 초기화되어야 합니다.
* 그렇지 않으면 해당 필드는 null 값을 가지게 되어, 해당 필드에 대한 어떤 연산을 시도할 때 NullPointerException이 발생합니다.
* -> 초기값 0으로 설정
*/
@Builder.Default
private volatile AtomicLong aaplStockAmount = new AtomicLong(0);
private LocalDateTime createdAt;
private LocalDateTime modifiedAt;
public void addStocks(long amount) {
this.aaplStockAmount.updateAndGet(current -> current + amount);
this.modifiedAt = LocalDateTime.now();
}
public void subtractStocks(long amount) {
this.aaplStockAmount.updateAndGet(current -> {
if (current < amount) {
throw new RuntimeException("매도 가능한 주식이 없습니다.");
}
return current - amount;
});
this.modifiedAt = LocalDateTime.now();
}
public long getAaplStockAmount() {
return this.aaplStockAmount.get();
}
public boolean isRequestDelayBelowMs(long thresholdMillis) {
return this.getModifiedAt().plusNanos(thresholdMillis * 1_000_000).isAfter(LocalDateTime.now());
}
@PrePersist
private void onCreate() {
createdAt = LocalDateTime.now();
modifiedAt = createdAt;
}
@PreUpdate
private void onUpdate() {
modifiedAt = LocalDateTime.now();
}
}

결과 분석
앗, 그런데, 문제가 발생했다 !
이와 같이 구현하였을 때 결과적으로 잔고의 수량은 10500으로 원하는 바가 유지되었으나, 예외가 발생하지 않아 요구사항을 충족시키지 못하게 되었다. 왜 그러한지를 살펴보자.
상황 분석
- 동시성 보장:
AtomicLong의updateAndGet메서드를 사용하여 잔액을 업데이트하는addBalance메서드는 원자적 연산을 보장한다. - 예외 처리:
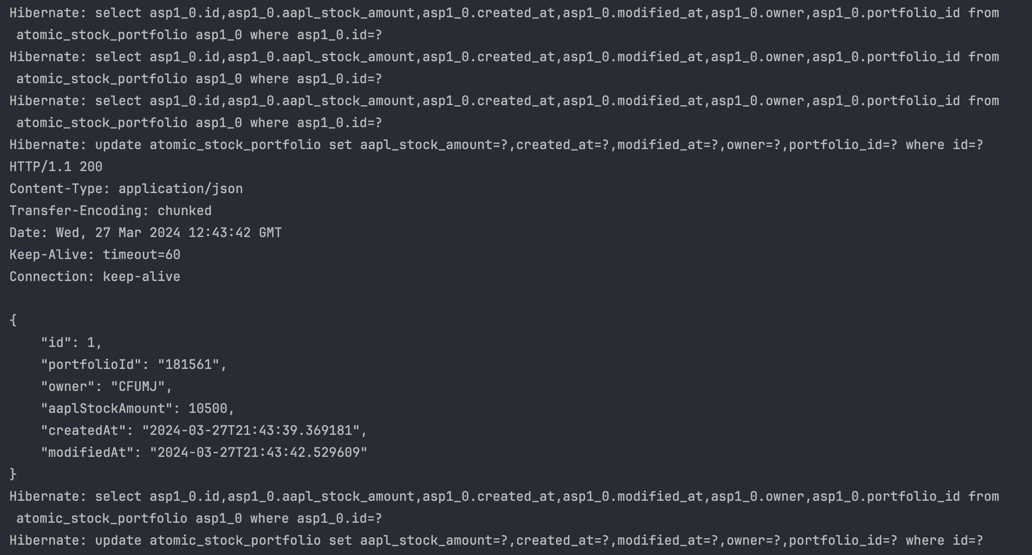
isRequestDelayBelowMs(1000)메서드를 통해 동시 요청을 검사하였으나, 두 요청이 거의 동시에 이루어졌기 때문에 두 요청 모두 이 조건을 통과했다. - 업데이트 쿼리 발생: 로그에 나타난 것처럼,
update쿼리가 두 번 실행되었다. 두 입금 요청이AtomicBankAccount객체의balance필드를 업데이트한 후, 두 번의save호출로 인해 발생한 것이다. 하지만AtomicLong을 사용하여 잔액을 관리함으로써 실제 데이터베이스에 반영된 잔액은 두 요청의 합이 아니라 최종적으로 계산된 잔액이 반영되었다. - 잔액 유지:
AtomicLong의 원자성 보장 덕분에, 두 번째 입금 요청이 첫 번째 요청의 업데이트를 "보게" 되어 잔액이 업데이트 되지 않고 튕기었다.
결론
이 상황은 AtomicLong을 사용하여 동시성 문제를 해결하는 방식의 효과를 잘 보여주긴 한다. 동시에 도착한 여러 요청이 있더라도, AtomicLong의 원자적 연산으로 인해 데이터의 일관성과 정확성을 유지할 수 있다는 것이다.
문제는 의도한 예외가 발생하지 않았다는 것이다. 그렇다면 예외를 발생시키려면 어떻게 해야할까? lock-free 방식으로는 원하는 방식으로 동시성을 관리하기 힘든 것일까?
시간 스탬프나 요청 ID와 같은 추가적인 메커니즘을 사용하여 각 요청을 구별하고 처리 순서를 관리할 수 있다.
예를 들어, 각 입금 요청에 대한 타임스탬프를 기록하고, 해당 타임스탬프를 사용하여 일정 시간 내에 중복된 요청을 식별할 수 있다. 이 방법 역시 자바에서 지원하는 Atomic 클래스인 AtomicReference를 사용하여 최신 타임스탬프를 안전하게 관리하며 CAS 연산을 활용하여 구현할 수 있다.
추가 구현
- AtomicReference 사용: 각 계좌마다 마지막으로 처리된 입금 요청의 타임스탬프를 관리하기 위해
AtomicReference<LocalDateTime>필드를 추가한다. 이 필드는 입금 요청이 처리될 때마다 업데이트된다. - 중복 요청 검사: 입금을 처리하기 전에 현재 요청의 타임스탬프와
AtomicReference에 저장된 마지막 타임스탬프를 비교한다. 만약 현재 요청의 타임스탬프가 마지막 요청으로부터 일정 시간(예: 1000ms) 이내라면, 요청을 중복으로 간주하고 예외를 발생시킨다. - CAS 연산으로 타임스탬프 업데이트: 중복 요청이 아니라면, CAS 연산을 사용하여
AtomicReference에 저장된 타임스탬프를 현재 요청의 타임스탬프로 안전하게 업데이트한다. 이 과정에서 타임스탬프가 이미 변경되었다면 (다른 스레드에 의해), 요청을 재시도하거나 예외를 발생시킬 수 있다.
좀 더 쉽게 설명하기 위해 이런 예를 들어보자. 예를 들어, 계좌 A에 대해 10:00:00에 요청이 들어왔다고 하자. 이 요청을 처리하고 난 후, AtomicReference에 이 시간을 저장한다. 그런 다음, 10:00:01에 다시 같은 계좌에 대한 요청이 들어온 경우, 이전 요청과의 시간 차이가 충분히 작다면 이를 중복 요청으로 간주하고 처리를 거부할 수 있다는 것이다.
이 메커니즘이 곧 조금 있다 살펴볼 레디스 분산락의 메커니즘과 비슷한 원리라고 할 수 있다.
private AtomicReference<LocalDateTime> lastDepositTimestamp = new AtomicReference<>(LocalDateTime.MIN);
public AtomicStockPortfolio buyStock(@PathVariable Long id, @RequestBody BuyOrderRequest request) {
AtomicStockPortfolio atomicStockPortfolio = AtomicStockPortfolioRepository.findById(id).orElseThrow(EntityNotFoundException::new);
LocalDateTime now = LocalDateTime.now();
LocalDateTime lastTimestamp = lastDepositTimestamp.get();
// 중복 요청 검사
if (Duration.between(lastTimestamp, now).toMillis() < 1000) {
throw new IllegalStateException("매수 요청이 너무 자주 발생했습니다. 나중에 다시 시도해 주세요.");
}
// CAS 연산으로 타임스탬프 업데이트
if (!lastDepositTimestamp.compareAndSet(lastTimestamp, now)) {
throw new IllegalStateException("동시 요청 감지. 요청을 처리할 수 없습니다.");
}
// 매수 처리
atomicStockPortfolio.addStocks(request.getAaplStockAmount());
return AtomicStockPortfolioRepository.save(atomicStockPortfolio);
}
이렇게 함으로써 원하는 동시성 방지와 예외 처리까지 구현할 수 있게 되었다.
레디스 분산락
그렇다면 결국 여기서 AtomicReference를 사용한 메커니즘이 발전되면 레디스의 분산락 개념이 되는 것이 아닌가? 하는 생각이 들었다.
AtomicReference은 CPU의 CAS 연산을 활용하여 구현된 내용인 한편, 레디스는 자체 명령어를 통해서 구현된다. 사용환경과 방식은 조금 다를 수 있겠지만 경쟁 상태를 방지하고 원자적 연산을 보장하는 Compare and swap을 구현한다는 측면에서 비슷한 원리의 메커니즘으로 작동한다고 볼 수 있겠다.
분산락이란
분산 시스템에서는 여러 서버 또는 인스턴스가 동일한 자원에 접근하려고 할 때 동시성 문제를 관리해야 한다. 이 때, 단일 시스템 내의 메모리 기반의 동기화 기법만으로는 충분하지 않고, 네트워크를 통해 여러 시스템 간에 동기화를 이루어야 하는데, 이를 위해 분산락이 사용된다.
분산락은 여러 분산 시스템이나 서비스가 공유하는 외부 저장소를 사용할 수 있다. 그 중 하나가 레디스이다. 예를 들어 레디스나 Zookeper를 이용해, 한 시점에 하나의 시스템만 특정 작업을 수행할 수 있도록 제한하는 방식이다. 분산락을 사용함으로써, 여러 시스템이 공유하는 자원에 대한 동시 접근을 안전하게 제어하는 것이 목적이다.
레디스와 같은 분산 캐시 시스템에서 제공하는 분산락 기능은 네트워크 지연, 시스템 장애 등 분산 환경에서 발생할 수 있는 다양한 이슈를 고려하여 설계되었다. 예를 들어, 레디스는 SETNX 명령어와 같은 원자적 연산을 통해 분산락을 구현하고, 락의 유효 시간(TTL)을 설정하여 데드락을 방지하는 등의 기능을 제공한다.
레디스는 어떻게 락을 구현할까?
레디스는 키-값 저장소의 특징을 활용하여 SETNX와 EXPIRE 명령어를 사용한 락을 제공한다.
1. SETNX (Set if not exists)
SETNX는 "Set if Not eXists"의 약자이다(2.6.12 버전부터는 deprecated되고 SET 명령어에 옵션을 주는 식으로 변경). 지정된 키가 존재하지 않을 때만 값을 설정할 수 있는 명령어이다. 이 명령어를 사용하면 해당 키에 대해 SETNX가 1을 반환하면, 해당 작업에 대한 락을 획득한 것이고, 안전하게 작업을 수행할 수 있다는 의미이다. 만약 0을 반환하면, 이미 다른 인스턴스가 락을 획득한 상태이므로, 작업을 수행할 수 없다. 이러한 방식으로 분산 환경에서 동시에 같은 자원에 접근하려는 여러 클라이언트 사이의 경쟁 상황을 해결한다.
2. EXPIRE
EXPIRE 명령어를 사용하여 락에 유효 시간을 설정함으로써, 락이 영원히 유지되지 않도록 한다. 데드락을 방지하는데 있어서 아주 중요한 장치라고 할 수 있다.
여기서 SETNX는 원자적 연산으로 구현된다. 락의 획득 시도가 단일 명령어로 이루어지므로, 다른 프로세스가 동시에 같은 키로 락을 획득할 수 없다. 또한, Redis는 내부적으로 단일 스레드 모델을 사용하여 모든 명령어를 순차적으로 처리한다. 이것 역시 레디스의 특징 중 하나이며, SETNX와 EXPIRE 명령어가 다른 명령어와 섞이지 않고 순차적으로 실행되도록 보장하는 원리라고 할 수 있을 것이다.
이렇게 생각해보면 레디스의 분산락은 정말 간단하다. 그리고 강력하다. 클러스터 모드와 유연한 구조 기반으로 구현할 수 있는 pub/sub 모델 등, 다양한 요구 사항을 처리할 수 있도록 지원한다. 그리고 상당한 고성능을 지원하기까지 한다. 그래서 레디스를 만능 처럼 쓰고 싶은 유혹이 들 때도 있는 것 같다.
그래서... 그렇게 레디스를 사용하다 보면 만나는 문제가 결국 레디스가 SPOF가 된다는 것이다...! 😝
은탄환인 줄 알았던 레디스도 잘못 사용하면 대재앙의 시작이 될 수 있다. 이렇게 만능하게 다재다능하기 때문에 분산환경에서 특히 레디스 의존성이 높아진다면 한 번쯤은 주의를 기울여볼 필요가 있다. "레디스 장애나면?!" 레디스를 이용해 글로벌 캐시나 분산락을 구현했는데 레디스가 장애가 난 것이다. 그래서 덩달아 연결된 내 서비스까지 전파가 된다면? 핵심 요소라면 허용 여부를 고려할 수 있겠지만, 부가 로직과 연결된 레디스 장애 때문에 내 서비스에 장애가 전파된다면 설계에 있어서 재고가 필요한 지점일 수 있다. 이런 점을 고려할 때 레디스를 글로벌 캐시나 분산 락으로 사용할 때 좀 더 조심하게 되는 경향도 생겼다.

3. 락 프리 접근 2: 식별자 메커니즘
이번에는 식별자 메커니즘을 사용해 CAS를 구현하고, 이를 통해 락 프리 방식으로 동시성을 제어하는 방식을 살펴보자.
요청을 식별하고 관리할 수 있는 메커니즘을 사용하는 것이다.
구현 아이디어
- 입금 요청 식별: 각 입금 요청에 대해 유니크한 식별자(예: 요청 시간, 클라이언트에서 생성한 ID 등)를 부여하고, 이를 기반으로 중복 검사를 수행한다.
- 첫 번째 요청만 처리: 요청이 큐에 추가될 때, 해당 계정에 대해 이미 처리 중인 입금 요청이 있는지 확인하고, 있으면 추가 요청을 거부한다. 이를 위해, 각 계정별로 현재 진행 중인 입금 요청의 상태를 관리할 필요가 있다.
핵심 개념
이 접근 방식에서 핵심은 각 작업에 고유 식별자를 부여하고, 이를 통해 데이터의 상태 변경 시도 전후를 비교하여 데이터의 일관성을 보장하는 것이다. 식별자 메커니즘을 통해, 복잡한 동기화 기법 없이도 여러 스레드나 프로세스가 데이터를 안전하게 변경할 수 있다.
- 요청 식별: 각 요청에 고유 식별자를 부여한다. 이 식별자는 요청이 처리될 때까지 요청을 구별하는 데 사용된다.
- 상태 확인: 요청을 처리하기 전에, 현재 데이터 상태와 요청이 예상하는 데이터 상태를 비교한다. 이 과정에서 CAS 연산이 사용된다.
- 조건부 업데이트: 예상되는 값이 실제 값과 일치할 경우에만, 시스템은 요청에 따라 데이터를 업데이트한다.
- 재시도 혹은 예외: 요청이 거부된 경우 적절한 처리를 할 수 있다.
구현 예시
@RestController
@RequestMapping("/stock-portfolio/identifier")
@RequiredArgsConstructor
public class IdentifierStockPortfolioController {
private final StockPortfolioRepositoryAdapter stockPortfolioRepository;
@PostMapping("/{id}/buy")
public StockPortfolio buyStock(@PathVariable Long id, @RequestBody BuyOrderRequest request) {
String identifier = id + ":" + request.getAaplStockAmount();
if (!IdentifierLockManager.tryLock(identifier)) {
throw new IllegalStateException("이미 처리 중인 요청입니다. 나중에 다시 시도해 주세요.");
}
try {
StockPortfolio stockPortfolio = stockPortfolioRepository.findById(id).orElseThrow(EntityNotFoundException::new);
if (stockPortfolio.isRequestDelayBelowMs(1000)) {
throw new IllegalStateException("매수 요청이 너무 자주 발생했습니다. 나중에 다시 시도해 주세요.");
}
stockPortfolio.addStocks(request.getAaplStockAmount());
return stockPortfolioRepository.save(stockPortfolio);
} finally {
IdentifierLockManager.unlock(identifier);
}
}
@PostMapping("/{id}/sell")
public StockPortfolio sellStock(@PathVariable Long id, @RequestBody SellOrderRequest request) {
Long amount = request.getAaplStockAmount();
StockPortfolio stockPortfolio = stockPortfolioRepository.findById(id).orElseThrow(EntityNotFoundException::new);
if (stockPortfolio.getAaplStockAmount() < amount) {
throw new RuntimeException("매도 가능한 주식이 없습니다.");
}
stockPortfolio.subtractStocks(amount);
return stockPortfolioRepository.save(stockPortfolio);
}
@GetMapping("/{id}")
public StockPortfolio fetchStock(@PathVariable Long id) {
return stockPortfolioRepository.findById(id).orElseThrow(EntityNotFoundException::new);
}
}package org.example.javaconcurrencyproblem.client;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.TimeUnit;
/**
* @author : Rene Choi
* @since : 2024/03/21
*/
public class IdentifierLockManager {
private static final ConcurrentHashMap<String, Long> identifierStore = new ConcurrentHashMap<>();
/**
* 기존에 식별자가 없다면 삽입하고 true 반환
* @param identifier
* @return
*/
public static boolean tryLock(String identifier) {
return identifierStore.putIfAbsent(identifier, System.currentTimeMillis()) == null;
}
public static void unlock(String identifier) {
identifierStore.remove(identifier);
}
/**
* 스케줄링을 사용하여 캐시 만료 정책 구현
*/
public static void checkAndCleanExpiredIdentifiers() {
long currentTime = System.currentTimeMillis();
identifierStore.entrySet().removeIf(entry -> currentTime - entry.getValue() > TimeUnit.SECONDS.toMillis(5));
}
}# identifier-stock-trading-api.feature
Feature: lock free 기반 접근의 식별자 해결 방식 테스트
Scenario: 동시 매수 요청의 순차적 처리
Given "identifier" API를 호출
Given 초기 주식 수가 10000인 포트폴리오가 주어졌을 때
And 다음 스텝을 위해 1초간 딜레이
And 2개의 스레드가 동시에 500을 매수하려고 시도한다
When 포트폴리오를 조회하면
Then 의도한 예외가 확인된다
Then 포트폴리오에 주식 수는 10500으로 확인되어야 한다결과 분석
이 접근 방식의 핵심은 각 요청에 고유 식별자를 할당하고, 식별자에 기반한 락을 사용하여 동시 요청을 안전하게 처리하는 것이었다. 마찬가지로 2개의 스레드가 동시에 500주의 주식을 매수하려고 시도한다.
- 첫 번째 요청 처리: 첫 번째 요청이 식별자에 따라 락을 성공적으로 획득하고, 주식 매수 작업을 진행한다. 이 작업이 완료되면, 포트폴리오의 주식 수는 10500주로 업데이트된다.
- 두 번째 요청 거부: 두 번째 요청은 동일한 식별자를 가지고 있기 때문에, 이미 진행 중인 작업을 감지하고 예외를 발생시킨다. 이때, 이 로직을 관리하는 클래스는
IdentifierLockManager이다. 해당 클래스에 의해 예외가 발생한다.
식별자 메커니즘을 활용한 락 프리 접근 방식은 고유 식별자를 기반으로 다른 방식과 마찬가지로 경쟁 상태를 방지할 수 있었다. 전통적인 방식의 락 기반 동기화 메커니즘보다 당연히 오버헤드가 적다.
어째서 lock free 라고 할까?
전통적인 락 기반 동기화 방식에서는 데이터를 접근하거나 수정하기 위해 락을 사용하여 해당 영역을 독점적으로 사용한다. 락 방식은 확실한 방식으로 동기화를 제공하므로 동시성 문제를 해결하지만, 오버헤드의 문제를 비롯해, 데드락이나 라이브락 같은 문제의 소지를 갖고 있다. 그런데 어째서 Atomic 클래스를 이용하거나 식별자 메커니즘을 이용하면 Lock-free라고 할 수 있는 걸까?
식별자 기반 접근 방식을 "lock free"라고 분류할 수 있는 이유는, 이 방식이 각 작업에 대해 고유한 식별자를 사용하여 데이터 상태의 변경을 관리하기 때문이다. 즉, 어떤 특정한 메서드나 블럭을 block 하는 방식이 아니라 기본적으로 compare and swap 메커니즘을 기반으로 한다는 것이다.
식별자 기반 접근 방법이 왜 lock-free로 분류될 수 있는지를 이해하기 위해서는, 먼저 lock-based와 lock-free 동기화 메커니즘의 핵심 차이를 이해해야 한다.
lock-based 동기화
Lock-based 동기화에서는 공유 자원에 접근하기 전에 명시적인 락(뮤텍스, 세마포어 등)을 획득해야 하며, 작업이 완료되면 이 락을 해제해야 한다. 이 과정에서 락 획득을 대기하는 동안 스레드는 대기 상태가 된다. 이때 CPU 자원에서 waiting이 발생하여 낭비 상황이 발생하는 것이 핵심이다. 또한, 데드락(Deadlock), 라이브락(Livelock), 락 경쟁(Lock contention)과 같은 복잡한 문제들이 발생할 가능성이 있다.
lock-free 동기화
반면, lock-free 동기화는 락을 사용하지 않고 공유 자원에 대한 접근을 제어한다. 대신 비차단 알고리즘(Non-blocking algorithm)을 사용하여 여러 스레드가 동시에 공유 자원에 접근하더라도 시스템 전체의 진행이 보장되는 방식이다. CAS 같은 원자적 연산을 활용하여, 공유 자원의 상태를 안전하게 변경할 수 있도록 한다.
식별자 기반 접근 방법의 lock-free 특성
식별자 기반 접근 방법에서는 각 작업에 고유한 식별자를 할당하고, 이를 기반으로 데이터의 상태를 비교 및 업데이트하는 CAS 연산을 사용한다. 여기서 중요한 점은, 작업을 처리하는 동안 어떠한 락도 획득하지 않는다는 것이다. 대신, 식별자를 통해 작업이 유일함을 보장하며, 원자적 연산을 통해 데이터 일관성을 유지한다.
따라서 이 방법은 lock-based 접근과는 달리 고성능이면서도 데드락 없이 안정적인 동시성 제어가 가능하다는 점에서 이점이 크다고 생각한다.

4. 순차 처리 접근 방식: 메시지 큐를 모방한 태스크 관리
마지막으로 메시지 큐를 모방한 방식을 살펴보고자 한다. 이를테면 카프카와 같은 메시지 큐이다.
앞서 설명한 CAS 알고리즘과 락 프리 접근 방식에서 한 걸음 더 나아가, 작업들을 순차적으로 처리하며 동시성 문제를 우아하게 해결해보려는 시도이다. 큐의 특성을 이용하면 동시에 발생하는 다수의 요청을 복잡한 동시성 제어 로직 없이 좀 더 효과적으로 처리할 수 있지 않을까?
결론적으로 말하자면 이 방식은 CAS와 식별자 메커니즘을 큐를 이용해 응용한 버전이라고 할 수 있다.
메시지 큐 모방의 기본 개념
메시지 큐는 일반적으로 메시지(데이터)를 순차적으로 저장하고 처리하는 데이터 구조이다. 프로듀서(생산자)는 메시지 큐에 데이터를 추가하고, 컨슈머(소비자)는 이 큐에서 데이터를 순차적으로 꺼내 처리한다. 이 모델은 동시에 발생하는 작업들을 하나의 처리 순서로 정렬하여, 데이터의 일관성과 순서를 보장한다.
매수 처리의 순차적 접근
시스템에서 동시에 발생하는 매수 요청을 처리하기 위해 메시지 큐를 모방한 태스크 관리 시스템을 구현할 수 있다. 각 매수 요청은 메시지 큐에 삽입되며, 시스템은 이 큐에 들어온 순서대로 요청을 처리한다. 다음과 같은 과정으로 진행된다.
- 요청의 큐잉: 각 입금 요청은 도착하는 즉시 메시지 큐에 추가된다. 이 때, 각 요청은 고유 식별자 또는 타임스탬프를 포함하여 중복 처리를 방지한다.
- 순차적 처리: 별도의 처리 스레드(또는 여러 스레드)가 큐에서 요청을 하나씩 꺼내어 처리한다. 이 스레드는 큐의 순서에 따라 입금 작업을 실행하며, 각 작업은 독립적으로 잔액을 업데이트한다.
- 결과 반환: 처리가 완료된 각 요청에 대한 결과(성공 또는 실패)는 해당 요청을 보낸 클라이언트에게 반환된다.
구현 예시
자바에서 제공하는 ConcurrentLinkedQueue와 같은 스레드 안전한 큐를 사용하여 메시지 큐를 구현할 수 있다.ConcurrentLinkedQueue 역시 내부적으로 CAS 알고리즘을 사용하여 요소의 추가와 제거를 관리하기 때문이다. 따라서, 동시성 제어를 위한 복잡한 락이나 동기화 블록 없이도 스레드 간에 안전하게 데이터를 공유할 수 있다.
@RestController
@RequestMapping("/stock-portfolio/queue")
@RequiredArgsConstructor
public class MessageQueueStockPortfolioController {
private final StockPortfolioRepositoryAdapter stockPortfolioRepository;
private final ConcurrentLinkedQueue<BuyOrderTask> buyOrderTasksQueue = new ConcurrentLinkedQueue<>();
private ExecutorService executorService;
@PostConstruct
public void init() {
executorService = Executors.newSingleThreadExecutor();
executorService.submit(this::processBuyOrderTasks);
}
private void processBuyOrderTasks() {
while (!Thread.currentThread().isInterrupted()) {
BuyOrderTask task = buyOrderTasksQueue.poll();
if (task != null) {
try {
performBuyOrder(task);
task.getFutureResult().complete(ok().build()); // 성공 응답 설정
} catch(Exception e){
task.getFutureResult().completeExceptionally(e); // 예외 발생시 실패 응답 설정
}
}
}
}
private void performBuyOrder(BuyOrderTask task) {
StockPortfolio stockPortfolio = stockPortfolioRepository.findById(task.getPortfolioId()).orElseThrow(EntityNotFoundException::new);
if (stockPortfolio.isRequestDelayBelowMs(1000)) {
throw new IllegalStateException("매수 요청이 너무 자주 발생했습니다. 나중에 다시 시도해 주세요.");
}
stockPortfolio.addStocks(task.getAaplStockAmount());
stockPortfolioRepository.save(stockPortfolio);
}
@PostMapping("/{id}/buy")
public CompletableFuture<ResponseEntity<?>> buyStock(@PathVariable Long id, @RequestBody BuyOrderRequest request) {
CompletableFuture<ResponseEntity<?>> futureResult = new CompletableFuture<>();
buyOrderTasksQueue.offer(new BuyOrderTask(id, request.getAaplStockAmount(), now(), futureResult));
return futureResult;
}
@PostMapping("/{id}/sell")
public StockPortfolio sellStock(@PathVariable Long id, @RequestBody SellOrderRequest request) {
Long amount = request.getAaplStockAmount();
StockPortfolio stockPortfolio = stockPortfolioRepository.findById(id).orElseThrow(EntityNotFoundException::new);
if (stockPortfolio.getAaplStockAmount() < amount) {
throw new RuntimeException("매도 가능한 주식이 없습니다.");
}
stockPortfolio.subtractStocks(amount);
return stockPortfolioRepository.save(stockPortfolio);
}
@GetMapping("/{id}")
public StockPortfolio fetchStock(@PathVariable Long id) {
return stockPortfolioRepository.findById(id).orElseThrow(EntityNotFoundException::new);
}
}
public class BuyOrderTask {
private final Long portfolioId;
private final Long aaplStockAmount;
private final LocalDateTime timestamp;
private final CompletableFuture<ResponseEntity<?>> futureResult;
}# message-queue-stock-trading-api.feature
Feature: lock free 기반 비동기 방식의 message queue를 이용한 해결 방식 테스트
Scenario: 동시 매수 요청의 순차적 처리
Given "queue" API를 호출
Given 초기 주식 수가 10000인 포트폴리오가 주어졌을 때
And 다음 스텝을 위해 1초간 딜레이
And 2개의 스레드가 동시에 500을 매수하려고 시도한다
When 포트폴리오를 조회하면
Then 의도한 예외가 확인된다
Then 포트폴리오에 주식 수는 10500으로 확인되어야 한다결과 분석
메시지 큐를 활용하여 동시에 발생하는 여러 요청을 순차적으로 처리할 수 있었다. 이 과정에서 각 요청은 큐에 추가되며, 별도의 처리 스레드가 이를 하나씩 꺼내어 처리한다. 이 방식의 핵심은 동시성 제어를 위한 복잡한 로직 없이도 데이터의 일관성을 유지하며 작업을 처리할 수 있다는 점에 있다.
요청들은 순차적으로 처리되기 때문에, 경쟁 상태(race condition) 없이 각 작업의 처리가 보장된다는 것이 큰 장점이다. 부하 관리에 있어서 처리 스레드의 수를 조정함으로써 요청 처리량을 관리할 수도 있을 것이다. 요청이 도착하자마자 큐에 넣고 관리하기 때문에 모니터링에 있어서도 수월하며 오류 로깅, 재시도 메커니즘 등을 구현하기에도 수월하다.

결론
이렇게 자바에서 동시성 문제를 해결하는 방법을 살펴보았다. 각각은 장단점이 있고, 특정 상황에 따라 다르게 사용할 수 있다고 생각한다.
간단히 정리해보자.
- 락 기반 동기화(
synchronized,ReentrantLock): 가장 기본적이고 직관적인 동기화 방법. 명시적인 락을 사용하여 공유 자원에 대한 동시 접근을 제어. 이 방법은 사용하기 쉽지만, 락 경쟁이나 데드락 등의 문제가 발생할 수 있다. - 락 프리 접근 방식(CAS,
Atomic클래스 사용): 락을 사용하지 않고 동시성 문제를 해결하는 방법. 원자적 연산을 활용하여 락 오버헤드 없이 데이터 일관성을 유지할 수 있는 것이 장점. 보다 나은 성능. 재시도 연산 가능. - 식별자 메커니즘:각 요청에 고유 식별자를 부여하고, 이를 기반으로 요청의 중복을 방지하는 방법. 간단한 동시성 제어가 가능하며, 복잡한 동기화 메커니즘 없이도 데이터의 일관성을 유지할 수 있다.
- 메시지 큐 모방 태스크 관리: 메시지 큐의 원리를 응용하여 요청을 순차적으로 처리하는 방식. 이 방식은 동시에 발생하는 요청을 처리 순서대로 정렬하여 데이터 일관성을 보장. 데이터를 가장 유연하고 효율적으로 관리할 수 있다는 것이 장점이다. 👍🏻
번외: 한가지 더 생각해볼 점... ! 요구 사항을 비틀어 본다면?!
요구 사항을 이렇게 비틀어보면 어떨까?
요구사항에서는 먼저 온 요청이 데이터베이스 쓰이고 두 번째 요청은 막아야 하는 것이었다. 그런데 이제는 두번째 요청을 막아야 하는 것이 아니라, 두번째 요청은 덮어씌워져야 한다. 그런데 어떠한 이유로 첫번째 요청보다 두번째 요청이 더 빠르게 DB에 도착하여 두번째 요청이 먼저 DB에 씌인 것이다. 이러한 경우라면 어떻게 될까? 어떻게 풀어야할까?
결국에는 요청의 순서를 관리하고, 데이터베이스에 반영될 순서를 제어하는 메커니즘이 필요하다.
위에서 제시한 식별자 메커니즘을 활용해보자. 순서 식별자를 부여하고 이를 기반으로 요청을 처리하는 순서를 결정하는 것이다. 여기서의 쟁점은 처리 순서 판단 로직을 어느 컴포넌트에서 맡을 것이냐가 되지 않을까 싶다.
구현 아이디어
- 요청 식별 정보 추가: 각 요청에 대해 서버나 클라이언트 측에서 생성한 시간 스탬프나 순서 식별자를 부여한다. 이 정보는 요청이 생성될 때 결정되며, 이 정보를 기준으로 처리 순서가 결정되어야 한다.
- 처리 순서 판단 로직: 서버에서는 요청을 처리하기 전에 순서 정보를 확인하고, 이를 기반으로 요청을 정렬한다. 예를 들어, 임시 대기 큐를 두고, 이 큐에서 순서에 따라 요청을 꺼낼 수 있다.
- 순서 조정 및 처리: 데이터베이스에 쓰기 작업 전에, 대기 큐에 가장 앞에 있는(즉, 순서가 가장 빠른) 요청만 처리한다. 순서가 가장 빠른 요청이 성공적으로 처리된 후에만, 다음 요청 처리를 진행한다.
동시에 도착하는 시간에 대한 기준을 설정하여 큐가 요청에 대해 판단하는 시점을 정하도록 한다. 예를 들어 1초를 기준으로 한다면, 2개의 요청이 들어오기에 충분한 시간일 것이다.
문제는, 그렇게 정한 기준 시간 바깥에서 순서가 빠른 요청이 도착하는 경우이다. 그렇게 되는 경우에는 어떻게 해야 할까?
데이터베이스 관점에서의 접근이 필요할 것 같다. 요청에 대한 메타데이터 테이블을 두고, 요청 정보를 관리하도록 한다. 이후, 이미 데이터베이스에 쓰인 요청에 대해 후속 요청이 들어왔을 때, 순서 기반으로 데이터를 보정하는 작업을 진행하는 것이다.
- 메타데이터 테이블 정의: 각 요청에 대한 정보를 저장하는 메타데이터 테이블을 데이터베이스에 생성한다. 이 테이블은 요청 식별자, 요청 타임스탬프, 처리 상태(예: 처리 중, 완료 등) 필드를 포함한다.
- 요청 처리 로직 구현: 해당 요청의 메타데이터를 메타데이터 테이블에 먼저 기록한다. 이후 요청 처리 과정에서 이 테이블을 참조하여 이미 처리된 요청에 대한 후속 요청이 들어온 경우 순서 정보를 기반으로 데이터 보정 작업을 진행한다.
- 순서 보정 메커니즘: 이미 처리된 요청보다 순서가 앞선 요청이 나중에 도착한 경우, 해당 요청에 대해 처리 순서를 보정한다. 이를 위해, 요청의 식별자나 타임스탬프를 기준으로 정렬하여 처리 순서를 결정하고, 필요한 경우 데이터베이스에서 이미 적용된 변경 사항을 롤백하거나 수정하여 데이터의 일관성을 유지한다.
- 요청 상태 관리: 처리 과정에서 요청의 상태 정보를 메타데이터 테이블에 업데이트하여, 각 요청의 처리 상태를 명확하게 관리하는 것이다. 이렇게 하면 어떤 요청이 현재 처리 중인지, 처리가 완료되었는지 등의 정보 역시 파악할 수 있다.
조금은 비현실적인 요구사항 같지만 생각해볼 필요가 있어서 함께 생각해보았다.
레퍼런스
- https://redis.io/docs/manual/patterns/distributed-locks/
- https://www.scientecheasy.com/2020/08/synchronized-method-in-java.html/
- https://jenkov.com/tutorials/java-concurrency/compare-and-swap.html
- https://jenkov.com/tutorials/java-concurrency/cache-coherence-in-java-concurrency.html
'이슈와해결' 카테고리의 다른 글
| 대기열 시스템 다양한 설계 방법 탐구 (feat. 레디스와 카프카를 이용한 O(1) 최적화) (2) | 2024.08.10 |
|---|---|
| 백엔드 응답 속도 500ms 줄이고 7배 개선한 썰 (2) | 2024.04.12 |
| 티켓 서비스 백엔드 시스템에서 중복 요청 이슈를 멱등하게 처리하기 (0) | 2024.03.01 |
| 예외 알림 프로세스에서 OOM을 방지하며 중복 처리를 위한 Marking 방식 (WeakHashMap) (1) | 2024.02.18 |
| Gson 베이스 프로젝트에서 LocalDateTime 컨버팅 지옥 탈출하기 (0) | 2024.02.18 |



