목차
- 사전 이해를 위한 구조 설명
- 문제 상황
- 1차 개선: 캐시 도입
- 2차 개선: mesh 방식으로의 전환
- 추가 개선 포인트: ForkJoinPool을 이용한 병렬 처리 & ConnectionPool 조정
- 최종 테스트
- 도대체 왜?! - 답은 늘 쉬운 곳에
- 결론
- 번외편 - 데드락 만들기
본 글에 대해서
주차 도메인 업무를 하면서 정기권 서비스를 개발했습니다. 해당 서비스의 성능을 개선하면서 시도한 방법과 시행착오들을 다룹니다. 실제 코드는 컨셉 코드로 대체하였고 일부 로직은 간소화하거나 대체하였음을 밝힙니다.
사전 이해를 위한 구조 및 테스트 환경 설명
- 스프링 MSA 환경에서 API 오케스트레이션과 사가(도메인)를 구분하는 패턴을 사용한다.
- 엔드포인트는 오케스트레이션에서 받고, 오케스트레이션에서 도메인 서비스를 호출하여 필요한 정보를 조합하여 클라이언트에게 최종 응답한다.
- 엔티티 참조는 직접 참조 방식이 아닌 간접 참조 방식을 사용한다.
- 대상 엔티티의 더미 데이터는 약 5천 건이다. 대용량 데이터셋을 다루는 테스트는 아니므로 데이터 개수는 크게 늘리지 않았다.
- APM은 스카우터, 성능 테스터 도구는 Gatling을 이용했다.
문제 상황
클라이언트 시스템에서 정기권 조회시, paging을 50 사이즈 이상 호출시 500ms 이상의 응답 속도 건이 종종 발생했다. 스카우터 APM을 통해 확인했다.
요청과 응답의 경로를 살펴보면, 클라이언트의 응답을 오케스트레이션에서 받아서 필요한 정보를 정기권에 요청하고, 얻은 정보를 조합하여 응답한다. 예를 들어 정기권을 응답하기 위해서는 메인 엔티티인 정기권 외에, 카테고리, 대차 정보, 주차장 정보를 각각 호출해서 불러온 뒤 조합해야 한다. 이때 다수의 API 호출이 시스템 부하와 지연 시간을 증가시키는 주요 원인으로 추정되었다. 페이지 당 조회가 필요할 경우 단일 페이지 조회에 최대 30회에 달하는 API 호출이 필요했다. 따라서 다수의 호출이 지연을 야기시킬 가능성이 농후했다. 어떻게 개선할 수 있을까?
1차 개선: 캐시 도입
첫 번째 접근은 캐시였다. 사실 캐시는 이와 같은 구조로 설계가 되는 시점부터 염두에 둔 상황이었다. 카테고리 정보나 주차장 정보와 같이 자주 변경되지 않는 데이터가 많았기 때문이다. 당연히 조합하는 과정에서 많은 호출이 발생할 것이 예상되었고, 이에 대한 매번의 호출로 인한 지연은 필연적인 결과이기도 했다. 매 호출마다 DB I/O와 네트워크 I/O를 막무가내로 허용한다면 너무 무책임한 설계일 것이다. 문제는 캐시를 어디에 어떻게 적절하게 구현하느냐였다.
오케스트레이션이 아닌 도메인에 캐시를 건 이유
캐시 구현에서 중요한 점은 무엇일까?
Eviction이다. 즉, 동기화를 통한 정합성을 맞추어주는 작업이다. 현재 구조에서 캐시 로직을 구현하려면 고려해야 하는 변수는, 서버 인스턴스, 도메인, 오케스트레이션, 등 다양했다. 또한 클라이언트의 요청을 받는 오케스트레이션이 단수가 아니라 복수일 수도 있으므로 이 역시도 신경써야 했다.
단순히 현재 문제가 된 오케스트레이션에서의 응답만 고려한다면 현 오케스트레이션에 캐시를 걸어도 될 것이나, 다른 클라이언트 시스템의 요청을 받는 오케스트레이션도 있었기 때문에, 우선 1차 캐시를 도메인 레벨에서 거는 것이 바람직하다고 판단했다. 이것으로 먼저 DB I/O에 대한 개선을 목표로 하는 것이다.
글로벌 캐시가 아닌 로컬 캐시를 사용한 이유
또 하나 고민할 포인트는 로컬 캐시와 글로벌 캐시였다. 글로벌 캐시를 걸면 다음과 같은 플로우가 될 것이다.
- 오케스트레이션에서 클라이언트 응답을 받는다.
- 먼저 글로벌 캐시를 조회하고, 글로벌 캐시에 존재하다면 거기 있는 것을 가져오고
- 없다면 도메인 호출을 통해 가져온다.
관리와 실질적인 성능 개선 차원에서 글로벌 캐시가 가진 다음과 다음과 같은 단점들을 주목했다.
예를 들어 클라이언트 시스템이 페이지마다 정기권 정보를 50회 호출한다면, 이 모든 호출을 글로벌 캐시에서 처리해야 한다. 매 호출마다 네트워크 비용이 발생할 것인데, 글로벌 캐시에서 데이터를 찾지 못하고 미스가 발생할 경우, 오히려 도메인 서비스 호출을 포함한 총 처리 시간이 더 길어지므로 역효과가 날 수 있지 않을까? 즉, 글로벌 캐시의 캐시 미스율을 고려할 때, 네트워크 지연과 더불어 데이터 동기화 문제 등을 고려하면, 성능 향상이 기대만큼 이루어지지 않을 가능성이 크다.
본 서비스의 경우 대부분의 데이터 접근 패턴이 국지적이었다. 즉, 각 오케스트레이션이 처리하는 요청은 해당 도메인 내에서 충분히 예측 가능하고, 대응 가능한 범위 내에 있었다. 이런 상황에서는 로컬 캐시가 훨씬 더 효율적이며, 개별 인스턴스가 자신의 캐시를 독립적으로 관리할 수 있어, 글로벌 캐시의 일관성 문제나 네트워크 지연의 영향을 크게 줄일 수 있다고 판단했다.
이런 점을 고려할 때 로컬 캐시를 이용해 DB I/O를 줄이는 것을 1차 목표로 설정했던 것이다.
또 한가지 포인트는 글로벌 캐시를 사용할 경우 발생할 수 있는 단일 실패 지점(Single Point of Failure, SPOF) 문제였다. 사실 이는 팀내 컨벤션에 따른 것이기도 한데, 글로벌 캐시를 SPOF로서 가급적 지양하고 있었다. 서비스의 성격상 SPOF의 자원을 사용할 만큼 크리티컬하지는 않았어서 쉽게 선택에서 배제할 수도 있었던 것이 사실이다.
어떤 로컬 캐시를 사용할까?
로컬 캐시 적용 시에는 Spring Framework에서 제공하는 Ehcache를 사용하여 구현하기로 결정했다.
Ehcache는 JVM 메모리 내에 캐시를 생성하여 데이터 접근 속도를 향상시키는 경량화된 캐싱 솔루션이다. 스프링 캐시 구현체로서 다른 대안 중 하나로 Caffeine이라는 라이브러리도 있다. Caffein은 소규모에서 중규모의 데이터 세트에서 빠른 조회와 고성능에 초점을 맞출 때 사용하기 좋은 솔루션으로 알려져 있다. Ehcache는 분산 캐싱을 지원하며, 네트워크를 통한 캐시 공유와 동기화가 가능하다는 점에서 MSA 환경에 잘 어울려서 분산 환경에서 사용하기 좋고, 다양한 캐시 전략과 오프힙, 디스크 스토리지 옵션을 제공하여 대규모 데이터 관리에 유리하다고 알려져 있다.
로컬 캐시 적용시의 문제점과 해결 방안
로컬 캐시를 사용하기로 결정했지만, 로컬 캐시 사용에도 난관은 있었다.
서버의 인스턴스가 여러 개일 경우 캐시 데이터 동기화 문제가 생긴다는 것이었다. 이 문제를 해결하기 위해 데이터 변경시 다른 인스턴스를 호출하여 캐시를 클리어해주는 로직을 구현해야 했다.
해결 방안은 다음과 같다.
- 커스텀 eviction을 위한 애노테이션 기반의 프로세스 구성
- 인스턴스가 eviction 호출이 가능하도록 endpoint 구성
- discovery를 이용해 인스턴스 탐색하여 재귀 호출로 evict endpoint 호출하여 캐시 삭제
예를 들어, 특정 데이터가 변경될 때, 해당 데이터와 관련된 캐시를 유효하지 않게 해야 한다. 이를 위해, 서비스의 각 부분에서 발생하는 데이터 변경 이벤트를 감지하고 해당 이벤트에 응답하여 관련 캐시를 삭제하는 커스텀 로직을 구현한다. 변경 사항이 발생하는 메소드에 애노테이션을 추가하여 해당 메소드가 성공적으로 수행될 때 캐시 제거 로직이 자동으로 실행되도록 한다.
실제 search parameter는 다양하게 제공될 수 있고 조합은 다양하기 때문에 캐시를 생성하고 제거하는 로직은 커스텀으로 만들어주어야 한다.
@Aspect
@Component
public class TicketCacheEvictionAspect {
@AfterReturning("evictCache(evictTicketCache)")
public void afterReturning(JoinPoint joinPoint, EvictTicketCache evictTicketCache) {
// 메소드 실행 후 캐시 제거 로직
String valueFromAnnotation = parseValueFromAnnotation(joinPoint, customKey);
String evictTargetValue = isBlank(valueFromAnnotation) ? parseValueFromJoinPoint(joinPoint) : valueFromAnnotation;
evictionStrategies.stream().filter(EvictionStrategy::support).forEach(evictionStrategy -> evictionStrategy.evictTicketCache(evictTargetValue));
}
}
이때 중요한 점은 한 인스턴스에서의 변경이 다른 인스턴스 간에도 동기화되어야 한다는 점이다. 이를 위해 서비스 디스커버리를 활용하여 동적으로 서비스 인스턴스를 찾고, 해당 인스턴스들에게 캐시 제거 요청을 보내도록 한다.
@Service
public class DiscoveryInstanceCallingService {
public void sendCommandToAllInstances(String commandPath) {
List<ServiceInstance> instances = discoveryClient.getInstances("SERVICE_NAME");
instances.forEach(serviceInstance -> {
String url = serviceInstance.getUri().toString() + commandPath;
restTemplate.getForEntity(url, Void.class);
});
}
}
캐시 적용 전과 후 비교 테스트
캐시 동기화 문제를 해결하였으니 이제 캐시가 적용되었을 때 어떻게 변화하는지를 살펴보자. 이를 위해 적용 전과 후를 비교하는 테스트를 구상했다.
🔑 테스트 환경
테스트는 로컬 개발 환경과 클라우드의 데이터베이스 환경을 사용하였다.
🔑 테스트 방법론
Gatling을 사용하여 성능 개선을 위한 캐시 도입 전후의 정기권 서비스 성능을 비교하는 목적으로 설계되었다. 테스트는 TicketSearchSimulation 클래스에 구현된 시나리오를 중심으로 진행되며, createScenarioWithFixedPage() 메서드를 사용하여 고정된 페이지를 대상으로 한 시뮬레이션을 실행한다.
🔑 테스트 시나리오 구성:
- 시작 지연: 모든 시나리오는 초기 10초의 지연 후 시작되며, 테스트에 포함되지 않는 예열 요청을 30초 간 선행한다(시스템 안정화 시간 고려).
🔑 테스트 파라미터:
- 사용자 증가: 1초당 1명의 사용자가 시스템에 접속하여, 총 5명의 사용자가 10초 동안 접속한다.
- 사용자 유지: 5명의 사용자가 40초 동안 시스템에서 활동을 지속한다.
- 사용자 감소: 5명의 사용자가 1명까지 30초 동안 점차 감소한다.
🔑 실제 요청 구성:
- 요청 주소: 정기권 목록 조회 ->
/tickets/api/v1/search - 쿼리 파라미터: 조회는 고정된 주차장 ID(
parkingLotId), 검색 시작일(searchStartAt), 검색 종료일(searchEndAt), 페이지 번호(page), 페이지 크기(size)를 쿼리 파라미터로 포함하여 실행한다. 페이지 번호는 1로 고정하고, 페이지 크기는 10으로 설정한다.
🔑 테스트 파라미터 생성 메서드 및 규칙:
본 테스트는 주차장 구역을 고정하고, 검색 기간을 랜덤 기간으로 설정하여 실행한다.
createFixedParkingLotAndMontPeriodSearchParams() 메서드를 통해 주차장 ID는 고정되며, 검색 기간(시작일과 종료일)은 현재 달의 범위 내에서 랜덤하게 선택된다.
테스트 파라미터는 실제 운영 환경에서의 조회 유스케이스를 모방하여 캐시 히트율을 최적화하기 위한 방식으로 구성하여 변화하지 않는 데이터에 대한 반복된 조회를 최소화하고, 캐시 도입의 효과를 극대화하기 위해 설계되었다.
🔑 예시 로그
12:19:20.834 [ INFO] [XNIO-2 task-6] [ k.c.p.p.c.l.GlobalTraceHandler] - Incoming Request Body: [LPTSearchReq(LPTId=null, TT=null, CN=null, PLId="***", PLZId=null, ST=null, SA=2024-03-23T00:00, EA=2024-03-25T00:00, IE=null, THP=null, CatId=null, Status=null, ID=null, OEF=null, TCEId=null, Notes=null, OTNotes=null, CA=null, CB=null, CIP=null, MA=null, MB=null, MIP=null), Page request [number: 1, size 10, sort: UNSORTED]]
12:20:23.065 [ INFO] [XNIO-2 task-17] [ k.c.p.p.c.l.i.ThreadLocalLogTracer] - [d7a900b8] | |-->SLPTCrudFacade.search(..)
12:20:23.080 [ INFO] [XNIO-2 task-17] [ k.c.p.p.c.l.i.ThreadLocalLogTracer] - [d7a900b8] | |<--SLPTCrudFacade.search(..) time=15ms
13:33:37.619 [ INFO] [scheduling-1] [c.c.s.EhCacheCacheStatisticsActuator] - LPTCache statistics - Hit Count = 15102, Miss Count = 498, Hit Rate = 96.8076923076923전 후 비교
🧼 Before

> request count 15600 (OK=15600 KO=0 )
> min response time 47 (OK=47 KO=- )
> max response time 3261 (OK=3261 KO=- )
> mean response time 68 (OK=68 KO=- )
> std deviation 99 (OK=99 KO=- )
> response time 50th percentile 56 (OK=56 KO=- )
> response time 75th percentile 62 (OK=62 KO=- )
> response time 95th percentile 85 (OK=85 KO=- )
> response time 99th percentile 249 (OK=249 KO=- )
> mean requests/sec 12.776 (OK=12.776 KO=- )
---- Response Time Distribution ------------------------------------------------
> t < 800 ms 15535 (100%)
> 800 ms <= t < 1200 ms 34 ( 0%)
> t >= 1200 ms 31 ( 0%)
> failed 0 ( 0%)
================================================================================🧼 After

> request count 15600 (OK=15600 KO=0 )
> min response time 14 (OK=14 KO=- )
> max response time 1013 (OK=1013 KO=- )
> mean response time 25 (OK=25 KO=- )
> std deviation 34 (OK=34 KO=- )
> response time 50th percentile 20 (OK=20 KO=- )
> response time 75th percentile 24 (OK=24 KO=- )
> response time 95th percentile 51 (OK=51 KO=- )
> response time 99th percentile 106 (OK=106 KO=- )
> mean requests/sec 12.787 (OK=12.787 KO=- )
---- Response Time Distribution ------------------------------------------------
> t < 800 ms 15596 (100%)
> 800 ms <= t < 1200 ms 4 ( 0%)
> t >= 1200 ms 0 ( 0%)
> failed 0 ( 0%)
================================================================================
🧼 분석
- 응답 시간의 개선:
- 최소 응답 시간: 47ms -> 14ms (70% 개선)
- 최대 응답 시간: 3261ms -> 1013ms (69% 감소)
- 평균 응답 시간: 평균 68ms -> 평균 25ms (63% 개선)
- 표준 편차: 99ms -> 34ms (66% 개선) -> 응답 시간의 변동성이 줄어들어 일관된 성능을 제공함을 의미.
- 응답 시간 분포:
- 캐시 도입 후, 15,000여 건의 요청 중 4건 제외 800ms 미만의 응답 시간을 100%를 달성했다. 이전 대비 데이터 접근 시간이 대폭 줄어들어 전체적인 응답성이 크게 향상되었음을 보여준다.
- 캐시 히트율 분석:
- 캐시 히트율이 약 96.8%로 높은 히트율을 보였는데, 대부분의 요청이 캐시에서 조회되었음을 의미한다. 현 테스트에서 고정된 주차장과 해당 월에 대한 파라미터 기반의 랜덤 기간으로 설정한 것은 실제 유스케이스를 고려한 설정이므로, 실제 운영 환경과 다소 차이는 있겠으나 높은 히트율을 달성할 것으로 기대할 수 있는 부분이다.
응답시간 개선 그러나...
테스트에서 나타난 것처럼 사이즈가 10이나 20인 경우 무난한 응답속도를 보인다. 또한, 캐시 도입 전과 후에 대한 비교만 놓고 보았을 때는 분명히 개선된 결과라고 볼 수 있었다.
문제는 큰 편차와 사이즈가 커졌을 때의 느린 응답시간과, 여전히 큰 사이즈에 대한 너무 느린 응답이었다.
캐시 도입으로 확실히 평균 응답이 약 2배 정도 개선이 된 것은 맞지만 그 수준이 너무 낮았다. 예를 들어, 페이지 요청에서 size가 50인 경우, 실제 스카우터에 찍히는 응답이 250ms ~ 300ms로 확인되었다. 이는, 500ms -> 250ms 수준으로 확실히 2배 가량의 개선이 나타난 점은 유의미한 개선이긴 했다. 하지만 평균적인 응답 시간 역시도 너무 느렸고, 부하가 클 때는 여전히 1-2초 가량의 응답도 있었다. 어딘가 이상했다.
request count 340 (OK=340 KO=0 )
min response time 8 (OK=8 KO=- )
max response time 2674 (OK=2674 KO=- )
mean response time 277 (OK=277 KO=- )
std deviation 393 (OK=393 KO=- )
response time 50th percentile 74 (OK=74 KO=- )
response time 75th percentile 339 (OK=339 KO=- )
response time 95th percentile 1072 (OK=1072 KO=- )
response time 99th percentile 1500 (OK=1500 KO=- )
mean requests/sec 2.222 (OK=2.222 KO=- )
---- Response Time Distribution ------------------------------------------------
t < 800 ms 303 ( 89%)
800 ms <= t < 1200 ms 20 ( 6%)
t >= 1200 ms 17 ( 5%)
failed 0 ( 0%)
2차 개선: mesh 방식으로의 전환
배경
아무래도 API 자체를 끊어서 보내는 요청 자체가 네트워크 비용이 많이 드는 작업이고, 이를 개선해야 문제가 풀릴 것 같았다.
1차 작업은 DB IO를 줄이는 캐싱이었다면 오케스트레이션에서 도메인으로 보내는 api 요청을 줄여 네트워크 io를 줄이는 목적의 2차 개선을 시도했다. 기존에 오케스트레이션에서의 조합 방식을 변경해 도메인에서 조합하여 올리는 방식으로 변경하는 것이다. 이를 도메인 mesh 방식이라고 이름 붙였다.
AS-IS
기존에는 최초 1회 정기권을 불러온 후 page size 당
- 카테고리
- 대차
- parkingLot
을 조회해야 했다. 따라서 1 + pageSize X 3 회, 50회를 예로 들면 1 + 50 X 3 = 151회의 최대 요청이 들었다.
TO-BE
변경에서는 최초 정기권을 불러올 때 정기권에 카테고리와 대차를 포함해서 도메인에서 조합해서 보내므로 무조건 1회 요청이 필요하며, parkingLot에 대해서만 pageSize 만큼 필요하다.
이때 parkingLot 정보는 오케스트레이션에서 DB를 갖고 있으므로 자체 DB의 조회 IO 만큼 필요하며 이는 로컬 캐싱을 통해 해결할 수 있으므로 없는 셈 칠 수 있다.
변경 작업
코드로 보면 다음과 같다.
기존 코드
@Override
public Page<TicketInfo> search(Pageable pageable, TicketSearchRequest searchRequest) {
Page<TicketInfo> ticketInfos = infoResolver.resolveInfosWithThrow(pageable, searchRequest);
ticketInfos.forEach(this::resolveAndSetAdditionalInfo);
return ticketInfos;
}
private void resolveAndSetAdditionalInfo(TicketInfo info) {
ticketAggregator.setCategory(info);
ticketAggregator.setExchangeDetails(info);
ticketAggregator.setZoneInfo(info);
}
@Component
@RequiredArgsConstructor
public class SimpleTicketAggregator implements TicketAggregator {
private final TicketInfoResolver infoResolver;
private final CategoryInfoResolver categoryResolver;
private final ZoneInfoResolver zoneInfoResolver;
@Override
public void setCategory(TicketInfo info) {
CategoryInfo category = categoryResolver.resolveCategoryInfoWithThrow(info.getCategoryId());
info.setCategory(category);
}
@Override
public void setExchangeDetails(TicketInfo info) {
ExchangeDetailsInfo exchangeDetails = infoResolver.resolveActiveExchangeDetail(info.getTicketId(), info.getExchangeDetailsId());
info.setExchangeDetails(exchangeDetails);
}
@Override
public void setZoneInfo(TicketInfo info) {
ZoneInfo zoneInfo = zoneInfoResolver.resolveZoneInfo(info.getZoneId());
info.setZoneInfo(zoneInfo);
}
}변경 코드
@Override
public Page<TicketInfo> searchMesh(Pageable pageable, TicketSearchRequest searchRequest) {
Page<TicketInfo> ticketInfos = ticketInfoResolver.resolveMeshedTicketInfosWithThrow(pageable, searchRequest);
ticketInfos.forEach(ticketAggregator::setParkingLotZoneInfo);
return ticketInfos;
}
@Override
public void setParkingLotZoneInfo(TicketInfo ticketInfo) {
ParkingLotZoneInfo parkingLotZoneInfo = parkingLotInfoResolver.resolveZoneInfo(ticketInfo.getParkingLotZoneId());
ticketInfo.setParkingLotZoneInfo(parkingLotZoneInfo);
}
API를 안전하게 변경하기
해당 시점에 이미 QA가 완료되어 API 변경에 따른 부담이 있었다.
새로운 API와 기존 API가 완전히 동일한지를 검증하는 인수 테스트를 만들었고, 이를 build시에 함께 테스트할 수 있도록 적용했다.
테스트는 두 API에 동일한 파라미터가 주어졌을 때 완전히 동일한 response를 받는지를 검증하므로, 테스트가 실패하지 않는 한, API가 동일함을 보장받을 수 있었다.
Scenario: 정기권 목록조회 mesh 테스트
Given 정기권 기존 목록 조회 API를 호출하고 정상 응답을 받는다
When 정기권 신규 목록 조회 API를 호출하고 정상 응답을 받는다
Then 조회한 결과는 정확히 동일해야 한다
도메인에서의 구현
오케스트레이션에서 이제 mesh 방식으로 api를 가져오도록 변경했으니 조합 책임이 도메인으로 넘어갔다.
JPA의 직접 참조 방식을 사용했다면 별도 구현 없이 단순 조회로도 mesh가 가능했을 것이지만 간접 조회 방식을 썼기 때문에 직접 호출해주어야 했다. 다음과 같이 조합해주었다.
public Page<TicketInfoWithMesh> searchWithMesh(TicketSearchRequest searchRequest, Pageable pageable) {
String originalCarNumber = fetch...
Page<TicketInfoWithMesh> ticketInfoWithMeshes = ticketCrudService.searchWithMesh( ...
ticketInfoWithMeshes.forEach(ticket -> {
ticket.setCategoryInfo(categoryCrudService.search(ticket.getCategoryId())); ticket.setTemporalCarExchangeDetailsInfo(temporalCarExchangeService.fetchById(ticket.getTemporalCarExchangeDetailsId()));
});
return ticketInfoWithMeshes;
}
이제 성능이 어떻게 달라지는지를 살펴보자. 그에 앞서 보다 정확한 테스트를 위해 캐시 히트율을 일관되게 조정해주었다.
캐시 히트율
카테고리 캐시 히트율은 100%, 정기권 캐시 히트율은 15~20% 수준으로 유지하도록 설정했고, 대차에 대해서는 캐시를 적용하지 않았다.
13:40:12.940 [ INFO] [scheduling-1] [ k.c.p.p.c.l.i.ThreadLocalLogTracer] - [294ff79d] | |-->EhCacheStatsActuator.aggStats(..)
13:40:12.940 [ INFO] [scheduling-1] [c.c.s.EhCacheStatsActuator] - catCache stats - Hit Count = 13297, Miss Count = 3, Hit Rate = 99.98
13:40:12.940 [ INFO] [scheduling-1] [ k.c.p.p.c.l.i.ThreadLocalLogTracer] - [91e1d45a] | |-->EhCacheStatsActuator.aggStats(..)
13:40:12.940 [ INFO] [scheduling-1] [c.c.s.EhCacheStatsActuator] - tuCache stats - Hit Count = 0, Miss Count = 0, Hit Rate = 0.00
13:40:12.941 [ INFO] [scheduling-1] [ k.c.p.p.c.l.i.ThreadLocalLogTracer] - [b13a98cb] | |-->EhCacheStatsActuator.aggStats(..)
13:40:12.941 [ INFO] [scheduling-1] [c.c.s.EhCacheStatsActuator] - lptCache stats - Hit Count = 125, Miss Count = 595, Hit Rate = 17.36부하 테스트
이제 Gatling을 이용해서 테스트를 동일하게 돌려보았다.
Gatling 리포트 비교
기존 API
request count 240 (OK=240 KO=0 )
min response time 19 (OK=19 KO=- )
max response time 2277 (OK=2277 KO=- )
mean response time 635 (OK=635 KO=- )
std deviation 803 (OK=803 KO=- )
response time 50th percentile 33 (OK=33 KO=- )
response time 75th percentile 1567 (OK=1567 KO=- )
response time 95th percentile 1883 (OK=1883 KO=- )
response time 99th percentile 2097 (OK=2097 KO=- )
mean requests/sec 2.308 (OK=2.308 KO=- )
---- Response Time Distribution ------------------------------------------------
t < 800 ms 153 ( 64%)
800 ms <= t < 1200 ms 0 ( 0%)
t >= 1200 ms 87 ( 36%)
failed 0 ( 0%)
변경 API(mesh 방식)
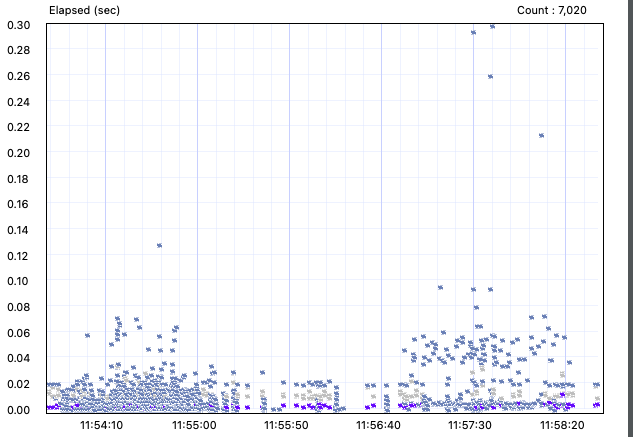
request count 240 (OK=240 KO=0 )
min response time 18 (OK=18 KO=- )
max response time 3564 (OK=3564 KO=- )
mean response time 203 (OK=203 KO=- )
std deviation 300 (OK=300 KO=- )
response time 50th percentile 36 (OK=36 KO=- )
response time 75th percentile 408 (OK=408 KO=- )
response time 95th percentile 480 (OK=480 KO=- )
response time 99th percentile 667 (OK=667 KO=- )
mean requests/sec 2.424 (OK=2.424 KO=- )
---- Response Time Distribution ------------------------------------------------
t < 800 ms 238 ( 99%)
800 ms <= t < 1200 ms 1 ( 0%)
t >= 1200 ms 1 ( 0%)
failed 0 ( 0%)
문제가 무엇일까?
의아한 점은, 분명 응답속도가 평균적으로는 크게 나오지는 않는데, 몇 건씩 튀는 것들이 발생한다는 것이었다.
기존 API로 오케스트레이션에서 성능테스트를 했던 1차에서 800ms 이상의 응답속도가 나왔던 것들의 원인이 이것들과 무관하지 않을 것 같았다.
어째서 이런 현상이 발견하는 것들일까?
처음에 들었던 의심은 DB에 문제가 있나? 네트워크에 문제가 있나? 였다. 문제의 쿼리를 살펴보았다.
mesh API에서 문제의 쿼리
► elapsed = 737 ms
► profileSize=5611
--------------------------------------------------------------------------------
p# # TIME T-GAP CPU CONTENTS
--------------------------------------------------------------------------------
- [000024] 11:57:38.396 1 6 PRE> select ticket_id as ... 중략 ... 37 ms
- [000025] 11:57:39.093 697 0 RESULT-SET-FETCH #5,078 659 ms
... 중략...
- [000199] 11:57:39.130 3 0 parameter: size=50
- [000200] 11:57:39.130 0 0 parameter: parkingLotId=
- [000201] 11:57:39.130 0 0 parameter: page=1
- [000202] 11:57:39.130 0 0 parameter: searchEndAt=2024-04-10T00:00
- [000203] 11:57:39.130 0 0 parameter: searchTarget=startAt
- [000204] 11:57:39.130 0 0 parameter: searchStartAt=2024-03-01T00:00
[******] 11:57:39.130 0 83 end of transaction
------------------------------------------------------------------------------------------
약 5,000건을 조회하는데 659ms가 걸린 것을 볼 수 있다.
문제는 앞전의 실제 db 응답을 보면 37ms가 걸렸다. 사실 여기서 눈치를 챘었어야 했다. 하지만 이때는 이것을 눈치채지 못했었고, 단순하게 조회 응답이 길다고만 생각했었다!
그래서 쿼리에 문제가 있을까 싶어 Explain을 살펴보았다.
EXPLAIN SELECT * FROM ticket WHERE parking_lot_id = '' AND start_at >= '2024-03-01 00:00:00' AND start_at <= '2024-04-10 00:00:00';
결론적으로 답은 아니었지만 덕분에 잘못된 인덱스를 찾을 수 있었다.
인덱스를 보았더니 다음과 같이 중복으로 되어 있었다.
@Index(name = "IDX_TICKET_END", columnList = "endAt DESC"),
@Index(name = "IDX_TICKET_END", columnList = "parkingLotId, startAt")
실행 계획시
INSERT INTO MY_TABLE(id, select_type, `table`, partitions, type, possible_keys, `key`, key_len, ref, rows, filtered, Extra) VALUES (1, 'SIMPLE', 'ticket', null, 'ref', 'IDX_TICKET_LOT,IDX_TICKET_START', 'IDX_TICKET_LOT', '403', 'const', 2596, 49.99, 'Using where');
확인해 보니 중복으로 입력된 인덱스인 IDX_TICKET_END 중 하나는 생성이 안되어 있는 것이 확인된 것이다!
따라서 원래 만들어졌어야 하는 인덱스를 다른 이름으로 생성하여 인덱스 오류를 수정했다.
그리고 다시 충분히 예열한 후 테스트 실행했다.
성능 테스트 - 인덱스 개선 후
기존 API
request count 340 (OK=340 KO=0 )
min response time 18 (OK=18 KO=- )
max response time 2849 (OK=2849 KO=- )
mean response time 659 (OK=659 KO=- )
std deviation 830 (OK=830 KO=- )
response time 50th percentile 34 (OK=34 KO=- )
response time 75th percentile 1608 (OK=1608 KO=- )
response time 95th percentile 1911 (OK=1911 KO=- )
response time 99th percentile 2281 (OK=2281 KO=- )
mean requests/sec 2.742 (OK=2.742 KO=- )
---- Response Time Distribution ------------------------------------------------
t < 800 ms 214 ( 63%)
800 ms <= t < 1200 ms 0 ( 0%)
t >= 1200 ms 126 ( 37%)
failed 0 ( 0%)

변경 API (mesh 방식)
request count 340 (OK=340 KO=0 )
min response time 18 (OK=18 KO=- )
max response time 601 (OK=601 KO=- )
mean response time 175 (OK=175 KO=- )
std deviation 193 (OK=193 KO=- )
response time 50th percentile 33 (OK=33 KO=- )
response time 75th percentile 403 (OK=403 KO=- )
response time 95th percentile 461 (OK=461 KO=- )
response time 99th percentile 528 (OK=528 KO=- )
mean requests/sec 2.857 (OK=2.857 KO=- )
---- Response Time Distribution ------------------------------------------------
t < 800 ms 340 (100%)
800 ms <= t < 1200 ms 0 ( 0%)
t >= 1200 ms 0 ( 0%)
failed 0 ( 0%)

이번에도 비슷했다. 조금 나아졌다 뿐이지 결과는, 평균값 수준이 비슷하고, 가끔씩 max가 튀는 항목들이 테스트마다 나온다는 점에서 결국 개선 포인트가 없다고 볼 수 있었다. 이상한 점은 XLog 상에 나타난 최고 쿼리 응답시간은 100ms를 넘지 않았다는 점이다.
- [000024] 13:35:51.400 1 7 PRE> select... 중략
['',2024-03-01 00:00:00.,2024-04-08 00:00:00.] 26 ms
- [000025] 13:35:51.508 108 0 RESULT-SET-FETCH #5,078 82 ms
따라서 쿼리와 DB 자체는 문제가 없는 것으로 판단할 수 있었다.
그런데... 오케스트레이션에서 또 다시 부하를 주어 테스트를 해보면 전체 응답에서는 개선이 없고 여전하다…?
평균 응답시간은 양호한데, 몇 개씩 튀는 그놈들이 대체 무엇이냐는 것이었다.
추가 개선 포인트: ForkJoinPool을 이용한 병렬 처리 & ConnectionPool 조정
1. ForkJoinPool 병렬 처리
도메인에서 새롭게 구현한 mesh 조합 코드는 다음과 같았다.
@Override
public Page<TicketInfoWithMesh> searchWithMesh(TicketSearchRequest searchRequest, Pageable pageable) {
// 생략
ticketInfoWithMeshes.forEach(
// 생략
return ticketInfoWithMeshes;
}
여기서 forEach 이하의 작업은 완전히 병렬로 진행되기에 적절한 작업이 아닐까?
parallelStream을 이용한 병렬처리를 고려하게 되었다.
Stream API에서 손쉬운 parallel을 제공해주었기 때문에 반복 전에 parallelStream() 코드만 추가해주면 될 만큼 구현 자체는 간단하다.
public Page<TicketInfoWithMesh> searchWithMeshParallelTest(TicketSearchRequest searchRequest, Pageable pageable) {
String originalCarNumber = fetch...
Page<TicketInfoWithMesh> ticketInfoWithMeshes = ticketCrudService.searchWithMesh( ...
ticketInfoWithMeshes.getContent().parallelStream().forEach(ticket -> {
ticket.setCategoryInfo(categoryCrudService.search(ticket.getCategoryId()));
ticket.setCarExchangeDetailsInfo(CarExchangeService.fetchById(ticket.getCarExchangeDetailsId()));
}
return ticketInfoWithMeshes;
}
작동 원리를 알아보자
ForkJoinPool의 작동원리에 대해서는 분리된 지면을 할애해 정리해두었다.
https://upcurvewave.tistory.com/653
Java 병렬 처리 ForkJoinPool 기본 작동 원리
배경 업무를 하면서 ForkJoinPool을 이용한 병렬 처리를 사용해볼 일이 생겼다. 엄밀히 말하면 Stream API의 parrallelStream()이었다. 본 글은 그에 앞서 간단히 ForkJoinPool의 작동 원리를 공부하면서 정리한
upcurvewave.tistory.com
Thread 조정하기
ForkJoinPool 기반의 병렬 작업을 사용하는 것은 정말 쉽다. 단순히 ForkJoinPool forkJoinPool = new ForkJoinPool(4); 를 만들어주고 작업을 제출만 해주면 된다. 혹은 Stream API를 사용한다면 이조차도 필요 없이 그냥 parallelStream()를 호출해주면 된다. 이때 스레드는 작동하는 CPU의 코어 개수 - 1개로 자동 세팅된다. 다음과 같은 코드로 확인해 볼 수 있다.
Runtime.getRuntime().availableProcessors()); // 코어 개수에 따른 스레드 개수 확인
int currentParallelism = customPool.getParallelism(); // 병렬 처리에 사용되는 실제 스레드 개수 확인
그런데 병렬 구현을 하다가 갑자기 Thread 이야기로 빠졌다. 왜 Thread 설정이 필요한 것일까?
Thread와 Connection Pool의 관계
이유는 현재 필요한 병렬 프로세스가 단순 CPU 연산만 하는 작업이 아니었기 때문이다. 😅
문제 상황을 다시 생각해보자. 병렬 처리를 통해 줄이고 싶었던 응답 시간은 조회 응답이었다. 주 엔티티를 로드하고, 이와 연관된 부가 엔티티들을 간접 참조 방식으로 매핑해야 했던 상황이었다. 카테고리 엔티티와 대차 정보가 그것이었다. 이들을 조합해서 완성된 정기권으로 mesh하여 오케스트레이션으로 보내는 것이 개선된 Mesh 방식의 API인 것이다.
따라서 여기서 Transaction Context가 열린다. 단순 CPU 연산이었다면 훨씬 단순했을 것이고 어쩌면… 그게 더 병렬 사용에 적합했었을 것이다.
병렬 처리가 진행될 때 각 스레드는 독립적인 작업을 수행하면서도, 공유된 리소스인 데이터베이스에 접근해야 한다. 이때, 각 스레드가 데이터베이스 커넥션을 얻기 위해 경쟁하게 되고, 이 과정에서 커넥션 풀의 크기와 관리 방법이 중요한 변수가 된다. 따라서 스레드를 병렬로 적절하게 배정하는 것과 더불어서 커넥션 풀의 수도 적절히 맞추어 최적화된 수치를 찾아야 한다. 예를 들어, 병렬 처리 과정에서 사용하는 ForkJoinPool은 각 스레드에 할당된 작업을 효율적으로 처리하도록 설계되었지만, 동시에 다수의 스레드가 데이터베이스 작업을 요청할 경우 사용 가능한 Connection의 수가 부족해지면 병목 현상이 발생할 수 있다. 이 부분은 뒤에서 실제 예시로 다뤄본다.
현재 상황에서는 다행히 Thread는 분리되지만 Transactional Context가 독립적으로 각각 열리지는 않으며, 따라서 Connection Pool 역시도 공유해서 사용할 수 있었다. 만약 Thread 별로 Connection Pool도 분리해야 했다면 애초에 다른 방식을 고민해야 했을 것 같다.
2. Connection Pool 개수 조정
최적의 Connection Pool 개수는 ?! - Hikari 팀이 제시하는 pool size와 thread 수
따라서 최적의 커넥션 풀 개수를 찾아야 했다.
Hikari Connection Pool의 작동원리는 다음 글에 정리해두었다.
https://upcurvewave.tistory.com/654
Hikari Connection Pool 기본 작동 원리
배경 업무를 하며 ForkJoinPool을 이용해 병렬 처리를 하는 작업 중에 DB IO가 발생하는 작업이 있어 커넥션 풀 사이즈 관리가 필요했다. 성능 최적화와 함께 안정적인 설계를 고민하며 Hikari Connection
upcurvewave.tistory.com
먼저 Hikari team이 제시한 영상을 살펴보자.
https://www.youtube.com/watch?v=_C77sBcAtSQ
영상에 따르면 실제로 많은 시스템에서는 데이터베이스에 과도한 수의 커넥션을 생성하려는 경향이 있는데, 이는 성능 문제의 주요 원인 중 하나라는 것이다. HikariCP의 연구와 실제 적용 사례에 따르면, 커넥션 풀의 크기를 과도하게 크게 설정하는 것은 오히려 성능 저하를 초래할 수 있다.
동영상에서는, 9,600개 스레드가 550밀리초마다 트랜잭션을 실행할 때 2,048개의 커넥션 사용으로 인해 응답 시간이 100밀리초 이상 발생했는데, 커넥션 수를 1,000개로 줄이면 CPU 사용률이 감소했으나 응답 시간 개선은 미미했다. 반면, 커넥션 수를 96개로 대폭 줄였을 때 응답 시간이 크게 감소하고 시스템 성능이 개선되었음을 보였다. 다른 변경 사항 없이 연결 풀 크기만 줄이는 것만으로도 애플리케이션의 응답 시간이 ~100ms에서 ~2ms로 단축되어 50배 이상 향상된 것으로, 적정 수준의 데이터베이스 커넥션 관리가 시스템 성능에 중요함을 강조하는 내용이다.
그렇다면 왜 더 적은 것이 나을까?
Cpu와 스레드 수의 일반적인 관계에 실마리가 있다.
- CPU 코어 수: 실제로 동시에 수행할 수 있는 작업의 수를 결정한다. 각 코어는 한 번에 하나의 작업(스레드)만 처리할 수 있다. 따라서, 코어 수는 동시에 실행할 수 있는 스레드 수의 상한선을 의미한다.
- 스레드 수: 애플리케이션이 동시에 실행하려고 하는 작업의 수이다. 이론적으로 스레드 수는 CPU 코어 수보다 많을 수 있지만, 이는 시스템의 컨텍스트 스위칭(Context Switching) 비용을 증가시키고 성능을 저하시킬 수 있다.
이를 기반으로 적은 커넥션 수가 좋다는 다음과 같은 결론이다.
- 오버헤드 감소: 커넥션 수가 많을수록 관리해야 할 리소스와 오버헤드가 증가한다. 각각의 커넥션은 메모리와 CPU 리소스를 소비하며, 커넥션을 생성하고 유지하는 데에도 비용이 든다. 따라서 커넥션 수를 최소화함으로써 시스템 리소스를 효율적으로 사용할 수 있다.
- 동시성 제어: 현대의 서버는 수십 개의 CPU 코어를 가질 수 있지만, 이는 커넥션 풀의 사이즈가 CPU 코어 수와 직접적으로 비례해야 한다는 것을 의미하지 않는다. 실제로, CPU 코어보다 많은 수의 스레드가 동시에 실행될 경우, 컨텍스트 스위칭으로 인한 오버헤드가 증가하게 된다. Hikari 팀은 실제 CPU 코어 수의 2배 정도를 초과하지 않는 스레드 수가 이상적이라고 제안한다.
- 적절한 리소스 사용: 최적화된 커넥션 풀 사이즈는 모든 요청을 즉시 처리할 수 있도록 충분히 커야 하지만, 동시에 너무 많은 커넥션으로 인해 리소스가 낭비되어서는 안 된다. 적절한 커넥션 풀 사이즈는 시스템의 대기 시간을 최소화하고, 각 커넥션의 활용도를 최대화한다.
가상 상황: 1개 vs 100개
똑같은 쿼리를 날리는 상황을 가정해보자. 이때 CP는 1개일 때와 100개일 때 어느 것이 더 좋은 성능을 보일까?
직관적으로 생각해보아도 1개일 것이다. 그렇다면 의문이 든다.
왜 ?!
단순히, 커넥션을 맺고만 있는 것일 텐데도, 성능이 똑같으면 똑같았지 더 좋을리는 있을까?
Hikari 팀은 클라이언트 입장에서의 관점, 일반적인 CS 관점에서의 입장에 따른 관점이었는데, DB 입장에서 생각해보면 또 다른 근거를 이유로 댈 수 있다. 바로 DB의 메모리 버퍼 때문이다.
데이터베이스의 메모리 버퍼는 디스크 I/O 작업을 최소화하기 위해 최근에 액세스된 데이터를 메모리에 캐싱한다. 이 과정에서, 각 커넥션은 메모리 버퍼 내의 데이터와 메타데이터에 대한 자신만의 뷰(view)를 유지해야 하며, 이는 커넥션이 많아질수록 관리해야 할 메모리 버퍼의 양과 복잡성이 증가한다. 데이터베이스의 메모리 버퍼와 커넥션 관리 메커니즘을 고려할 때, 커넥션 수가 증가하면 여러 부정적인 영향이 따르는 것은 어찌보면 당연하다.
먼저, 각 커넥션은 독립적인 상태 정보를 메모리 버퍼에 유지해야 하므로, 커넥션 수가 많아질수록 데이터베이스 엔진의 버퍼 관리 복잡성과 성능 저하가 발생한다. 또한, 커넥션 수의 증가는 메모리 버퍼 공간의 분산을 초래해 캐시 효율성을 감소시키며, 동일한 데이터에 대한 중복 캐싱과 필요 이상의 데이터 유지로 인해 캐시 미스 확률이 증가한다. 뿐만 아니라 데이터베이스의 동시성 제어 오버헤드를 증가시키며, 락이나 래치 같은 동기화 작업이 빈번해지고 처리 성능에 악영향을 미칠 수 있다.
무작정 많은 게 좋은 것이 아님은 이제 확실히 이해되었다!
권장 Pool Size 공식
커넥션 풀 크기 = (CPU 코어 수 * 2) + 유효한 디스크 수
예를 들어, 4개의 CPU 코어와 SSD 기반 스토리지를 사용하는 서버가 있다고 가정해보자. 이 경우, 대부분의 현대적인 데이터베이스 환경에서 디스크 I/O가 큰 병목이 되지 않는다고 가정할 때, 유효한 디스크 수는 큰 영향을 미치지 않을 수 있으므로 단순화를 위해 유효한 디스크 수를 0으로 가정하고(effective_spindle_count=0), 권장되는 커넥션 풀 사이즈는 다음과 같이 계산할 수 있다.
connections = ((4 * 2) + 0) = 8
이는 동시에 최대 8개의 데이터베이스 커넥션이 활성 상태여야 함을 의미한다.
지금의 커넥션은 적절한가?
먼저 하드웨어 사양은 다음과 같았다.
CPU 코어 : 12코어
메모리: 34기가 (70% 사용중)
서비스: 서비스는 약 20대가 운영중인 서버
커넥션 풀 설정은 다음과 같았다.
hikari:
connection-timeout: 9000
idle-timeout: 150000
max-lifetime: 300000
maximum-pool-size: 20
minimum-idle: 15
그러나 일반적인 컴퓨터라고 가정하고, 다른 프로그램이 띄워져있고 이른바 '멀티태스킹' 작업이 진행중이라고 할 때, 프로세스 분배가 OS 작업의 영역이므로, 다른 서비스는 무시하고,
이러한 성능에서 Hikari 팀이 제시하는 기준에 따라 적정한 CP 풀에 대해 다시 계산해 보면 다음과 같다.
권장 커넥션 풀 크기 = (CPU 코어 수 * 2) + 유효한 디스크 수
따라서
권장 커넥션 풀 크기 = (12 * 2) + 0 = 24
이론적으로 24개의 커넥션으로 설정하는 것이 최적일 수 있음을 의미한다. 현재 설정된 maximum-pool-size는 20으로, 권장 사이즈에 약간 못 미치는 수치였다. 하지만 팀내 컨벤션에서 20개 역시도 적지 않은 수치로 여겨졌는데, 실제 운영 환경에서의 인스턴스가 4개이므로 실제 커넥션은 X4가 되는 상황이었고, 다른 서비스들까지 고려했을 때 커넥션 수가 기하급수적으로 증가해 골치였기 때문이다.
따라서 유의해야 할 점은 현재 서버에서는 다른 서비스에서도 풀을 설정한다는 것이다. 각각의 서비스는 DB 자원을 랜덤하게 공유하므로 DB의 부하를 고려해야 한다.
그렇게 따지면 극단적으로 20을 나눈 수치인 2가 맞을까? 그렇게 생각하기엔 또 개별 서비스의 CP 수가 너무 적다.
휴리스틱하게 10~20개가 적당하다는 결론이 나오는 지점 같다.
현재의 테스트에서는 Pool을 2개 이상 사용하는 케이스는 없었으므로 Pool-locking 에 대한 고려는 생략하도록 했다. 우아한 블로그에 2개 Pool을 사용하면서 발생하는 데드락 상황과 이를 방지하기 위해 커스텀으로 설정하는 Pool 개수 공식이 잘 기술되어 있다.
HikariCP Dead lock에서 벗어나기 (이론편) | 우아한형제들 기술블로그
HikariCP Dead lock에서 벗어나기 (이론편) | 우아한형제들 기술블로그
{{item.name}} 안녕하세요! 공통시스템개발팀에서 메세지 플랫폼 개발을 하고 있는 이재훈입니다. 메세지 플랫폼 운영 장애를 바탕으로 HikariCP에서 Dead lock이 발생할 수 있는 case와 Dead lock을 회피할
techblog.woowahan.com
3. 실험
정말 성능이 좋을까?
다음과 같은 테스트로 실제 성능 개선이 있을지 여부를 테스트해보았다.
@SpringBootTest
@ActiveProfiles("test-stgdb")
class SLPTCrudFacadePerfTest {
@Autowired
private SLPTCrudFacade slptCrudFacade;
private LPTSearchRequest searchReq;
private static double totalPerfImprovement = 0;
private static int testCnt = 0;
@BeforeEach
void setup() {
searchReq = defaultSearchReq();
}
/**
* For pages 10, 30, 50, provide each with 5 attempts, totaling 9 page request parameters
* @return
*/
static Stream<PageRequest> pageReqProvider() {
return Stream.of(10, 30, 50)
.flatMap(size -> IntStream.rangeClosed(1, 5)
.mapToObj(attempt -> PageRequest.of(0, size)));
}
@ParameterizedTest(name = "#{index} execution - Evaluating performance difference using page size {arguments} in sequential and parallel processing")
@MethodSource("pageReqProvider")
void testPerfDiff(PageRequest pageable) throws Exception {
jvmWarmup(pageable);
Thread.sleep(2000);
boolean parallelFirst = ThreadLocalRandom.current().nextBoolean();
StringBuilder log = new StringBuilder();
if (parallelFirst) {
log.append("Running parallel version first\\n");
ExecutionResult<Page<LPTInfoWithMesh>> parallelResult = measureExecTime(() -> slptCrudFacade.searchMeshParallelTest(searchReq, pageable));
log.append("Parallel execution duration: ").append(parallelResult.execTime).append("ms. Result size: ").append(parallelResult.result.getContent().size()).append("\\n");
ExecutionResult<Page<LPTInfoWithMesh>> sequentialResult = measureExecTime(() -> slptCrudFacade.searchMesh(searchReq, pageable));
log.append("Sequential execution duration: ").append(sequentialResult.execTime).append("ms. Result size: ").append(sequentialResult.result.getContent().size()).append("\\n");
double perfImpPerc = calcImpPerc(sequentialResult.execTime, parallelResult.execTime);
log.append(String.format("Performance improvement: %.2f%%\\n", perfImpPerc));
totalPerfImprovement += perfImpPerc;
testCnt++;
Thread.sleep(1000);
System.out.println(log);
assertTrue(parallelResult.execTime < sequentialResult.execTime, "Parallel execution should be faster than sequential execution");
} else {
}
}
@AfterAll
static void logTotalImp() {
double avgImp = totalPerfImprovement / testCnt;
System.out.println("---------------------------------------------------");
System.out.println(String.format("Total Performance Improvement across all tests: %.2f%%", avgImp));
System.out.println("---------------------------------------------------");
}
private <T> ExecutionResult<T> measureExecTime(Supplier<T> task) {
long start = System.currentTimeMillis();
T result = task.get();
long end = System.currentTimeMillis() - start;
return new ExecutionResult<>(result, end);
}
private static class ExecutionResult<T> {
final T result;
final long execTime;
ExecutionResult(T result, long execTime) {
this.result = result;
this.execTime = execTime;
}
}
private void jvmWarmup(PageRequest pageable) {
for (int i = 0; i < 5; i++) {
slptCrudFacade.searchMesh(searchReq, pageable);
slptCrudFacade.searchMeshParallelTest(searchReq, pageable);
}
}
private double calcImpPerc(long seqDuration, long parDuration) {
return ((double) (seqDuration - parDuration) / seqDuration) * 100;
}
private static LPTSearchRequest defaultSearchReq() {
return LPTSearchRequest.builder()
.parkingLotId("ID123")
.searchTarget("startAt")
.searchStart(LocalDateTime.of(2024, 3, 1, 0, 0))
.searchEnd(LocalDateTime.of(2024, 4, 30, 0, 0))
.build();
}
}
테스트 셋업은 다음과 같다.
- 가장 많이 조회되는 요청으로
- pageable size를 각각 10, 30, 50 번의 다른 파라미터로 조회 요청
- 정확한 테스트를 위해 캐시는 사용하지 않고, 각 테스트마다 5회씩 jvm 예열을 위한 선 조회 요청 보내기
- 또한 병렬과 순차 요청의 요청 순서에 따라 차이가 날 수도 있으므로 랜덤하게 요청을 보내도록 구현
- 총 15번의 조회 요청
- parrallel이 Sequential 보다 느리게 확인 되는 경우 테스트가 실패하도록 구현
재밌는 결과
결과를 확인해 보니 매 케이스마다 약 1~2회 실패가 발견됐다.
실패가 나는 케이스는 pageable이 10일 때이고 테스트 5회 이상 돌리는 동안 30회 이상에서는 한 번도 실패가 나지 않았다. 즉 page size가 30 이상인 경우 병렬 요청이 훨씬 빠르게 처리된다는 것이었다.

그런데 재밌는 경우가 있었는데, 병렬이 느릴 때 훨씬 느리게 나타나는 경우가 있었다!
👀 실패 케이스
Running sequential version first
Sequential execution duration: 776ms. Result size: 10
Parallel execution duration: 1613ms. Result size: 10
Performance improvement: -107.86%
Running parallel version first
Parallel execution duration: 1032ms. Result size: 10
Sequential execution duration: 513ms. Result size: 10
Performance improvement: -101.17%
👀 성공 케이스
Running parallel version first
Parallel execution duration: 1027ms. Result size: 30
Sequential execution duration: 1827ms. Result size: 30
Performance improvement: 43.79%
Running sequential version first
Sequential execution duration: 2618ms. Result size: 50
Parallel execution duration: 1469ms. Result size: 50
Performance improvement: 43.89%
Running parallel version first
Parallel execution duration: 1320ms. Result size: 50
Sequential execution duration: 2410ms. Result size: 50
Performance improvement: 45.23%
Running parallel version first
Parallel execution duration: 1341ms. Result size: 50
Sequential execution duration: 2524ms. Result size: 50
Performance improvement: 46.87%
페이지가 30, 50인 경우에는 20% ~ 50% 다양하게 성능 개선이 나타났다.
성능 개선이 나타날 수 있었던 지점
우선 어째서 성능 개선이 가능했는지 분석해보자.
테스트를 그렇게 짰고 구성을 했기 때문도 있지만, 확실히 forkJoinPool의 작동 원리와 parallelStream의 병렬 처리 메커니즘이 작동하는 것을 볼 수 있던 테스트였다. parallelStream은 작업을 여러 서브 태스크로 나누고, 이를 ForkJoinPool의 워커 스레드들이 처리한다. 이 과정에서 작업 훔치기(Work-Stealing) 알고리즘이 중요한 역할을 한다. 작업 훔치기는 유휴 상태의 워커 스레드가 다른 스레드의 작업 큐에서 태스크를 '훔쳐' 실행함으로써, 모든 스레드가 균등하게 일하도록 보장한다. 이를 통해 CPU 자원의 활용도를 극대화하고, 전체적인 처리 시간을 단축시킨다.
본 테스트 케이스에서는 3개의 다른 테이블에 대한 독립적인 DB 호출이 병렬로 이루어졌다. 이러한 병렬 처리는 각각의 DB 호출이 서로 영향을 주지 않고 독립적으로 실행될 수 있기 때문에, 전체적인 응답 시간의 개선을 가져올 수 있었다.
MySQL의 InnoDB 스토리지 엔진의 MVCC(Multi-Version Concurrency Control) 메커니즘은 각 트랜잭션에 데이터의 특정 버전을 보여주어, 동시에 여러 트랜잭션이 읽기 작업을 수행할 수 있게 하는데, REPEATABLE READ격리 수준에서 특히 유용한 현재 테스트 환경에서, 단순 조회 작업 시 다른 트랜잭션의 작업에 의해 블록되지 않도록 했다. 따라서, 병렬 처리를 통해 동시에 여러 DB 조회 요청을 처리할 때, 각 요청이 독립적으로, 그리고 효율적으로 수행될 수 있었다. 다시 말해, 본 테스트에서 병렬 처리가 효과적이었던 이유는, InnoDB의 MVCC와 REPEATABLE READ 격리 수준이 데이터 일관성을 유지하면서도, 동시에 다수의 조회 요청을 처리할 수 있는 환경을 제공되었던 점도 기여했다.
4. 그래서... 병렬 처리, 실 사용 가능할까 ?!
1) 어플리케이션 자원 vs db 자원
MSA 서비스 환경에서 분산 자원에 대한 적절한 분배와 우선순에 대한 고민이 필요하다. 어플리케이션과 DB에 대해서도 마찬가지이다. 각 서비스가 독립된 데이터베이스를 소유하는 구성이 일반적이지만, 서로 다른 스키마를 사용하면서도 동일한 물리적 데이터베이스 인프라스트럭처와 IDC 환경을 공유하는 경우도 존재한다. 이런 상황에서 한 서비스의 가용성 향상은 그 서비스의 데이터베이스 처리량 증가를 의미하며, 이는 곧 다른 서비스들에게 자원 활용의 균형을 잃게 만들 수 있는 '시소 게임'과 같은 상황을 초래할 수 있다. 따라서 어플리케이션에서 병렬로 구성해 놓고 ‘DB에 쉬지 않고 때리는 게 좋기만 할까?’, ‘그럴만한 가치가 있나?!’ 이 질문에 대해 고민해보아야 했다.
2) 유의미한 개선
또 하나는 현재 개선하려는 작업의 수치가 얼마나 유의미한지를 따져볼 필요성이었다. 테스트에서 확인되는 바는 페이징 사이즈가 30이상일 때 20~30% 가량의 응답속도 개선이 있다는 점이었다. 이는 100~200ms대의 평균 수치를 고려할 때, 50ms 안팎의 변화량을 의미하는 수치였다. 이 수치가 실제 기술적인 관점이 아니라 비즈니스적인 차원에서 얼마나 유의미한지도 고민할 필요가 있다고 생각했다. 물론, 공짜로 얻는 개선이면야 고민할 필요가 없을 것이다. 병렬 자원을 사용함으로써 얻을만한 가치일까? 오버엔지니어링은 아닐까?
실제로 사용자 인터페이스(UI) 및 사용자 경험(UX) 관점에서 고객이 체감하는 응답 속도에 대한 불편함은 얼마나 클까? Nielsen Norman Group의 연구에 따르면, 사용자는 웹페이지 로딩에 1초 이상 걸릴 경우 인터랙션에 대한 관심을 잃기 시작하고, 10초가 넘어가면 페이지를 완전히 무시할 가능성이 높아진다고 한다. 이는 즉, 100~200ms의 응답 시간 단축이 사용자가 웹사이트를 더 매끄럽고 즉각적으로 느끼는 데 기여할 수 있음을 의미한다. 특히 고속 인터넷 환경에서는 사용자의 기대치가 더욱 높아지므로, 50ms라는 개선도 사용자 만족도에 큰 영향을 미칠 수 있다.
물론 이는 관점의 차이일 수 있다.
3) 동시성 제어와 관리의 리스크
JVM이 자동으로 관리하며 공용 리소스를 활용한다. 하지만 병렬 처리 작업에 단순 CPU 연산 뿐만이 아니라 데이터베이스 커넥션이 얽혀 있으므로, 커넥션 풀의 설정과 병렬 처리 로직의 설계에 세심한 주의가 필요한 것이 사실이다. 실제 운영 상황에서 관련된 버그로서 문제가 발생했을 때 이를 책임져야 함을 의미하므로 이에 대한 관리의 리스크를 안고감을 의미했다.
마지막으로, 연산 비용은 어떠할까? ForkJoinPool에서 사용하는 스레드 연산의 사용량은 그렇게 크게 나타나지는 않았다.

그러나 변경이 주는 수치가 크게 유의미한 수치는 아니었다고 판단했고, 우선 적용은 보류하였다.
이제 모든 준비를 마쳤으니 다시 최종 테스트를 해볼 차례가 왔다. 사실 앞전의 도메인만을 테스트했을 때 생각보다 응답속도가 개선이 되는 경우가 몇 차례 있었어서 괜찮게 나올 것으로 기대하고 크게 무리가 없이 넘어갈 것이라고 생각하고 있었다.
최종 테스트
변경 완료 후 다시 재도전
먼저 정확한 비교를 위해 다시 기존 API를 호출했고 역시 드라마틱한 응답을 보여주었다.
기존 API
request count 340 (OK=340 KO=0 )
min response time 8 (OK=8 KO=- )
max response time 3524 (OK=3524 KO=- )
mean response time 431 (OK=431 KO=- )
std deviation 692 (OK=692 KO=- )
response time 50th percentile 27 (OK=27 KO=- )
response time 75th percentile 599 (OK=599 KO=- )
response time 95th percentile 1842 (OK=1842 KO=- )
response time 99th percentile 3114 (OK=3114 KO=- )
mean requests/sec 2.857 (OK=2.857 KO=- )
---- Response Time Distribution ------------------------------------------------
t < 800 ms 281 ( 83%)
800 ms <= t < 1200 ms 20 ( 6%)
t >= 1200 ms 39 ( 11%)
failed 0 ( 0%)
기존 API를 보면 거의 터지기 직전까지 가는 듯 싶었다. 조마조마 할 정도로 Xlog 패턴이 불안하다.
GC count도 상당해지고 TPS도 높아졌다. GC Time이 1초 이상씩 늘어나는 것에 주목해보자.
아래는 2회차 도중 찍힌 그림이다.

fail 안 나는 게 고마울 정도였다.
이제 변경 API로 시뮬레이션을 시작해보자.
변경 API(mesh)
기대되는 바는 도메인에서 20~30ms 평균 응답이 찍히고 오케스트레이션까지 100ms 내에서 찍히는 것이었다.
그런데 ?
잘 가다가....
갑자기...?


역시나 똑같았다 !
특정 값들이 1초대 튀더니, 2초대까지 튀는 모양이 나타났다. 눈에 띈 점은 해당 시점에 GC까지 튀었다는 점이었다. GC Time이 평상시 50ms 수준에서 1500~2000ms까지 약 30배~40배까지 급격히 상승했다.
request count 340 (OK=340 KO=0 )
min response time 7 (OK=7 KO=- )
max response time 2217 (OK=2217 KO=- )
mean response time 191 (OK=191 KO=- )
std deviation 360 (OK=360 KO=- )
response time 50th percentile 29 (OK=29 KO=- )
response time 75th percentile 244 (OK=244 KO=- )
response time 95th percentile 862 (OK=862 KO=- )
response time 99th percentile 2030 (OK=2030 KO=- )
mean requests/sec 2.857 (OK=2.857 KO=- )
---- Response Time Distribution ------------------------------------------------
t < 800 ms 319 ( 94%)
800 ms <= t < 1200 ms 8 ( 2%)
t >= 1200 ms 13 ( 4%)
failed 0 ( 0%)
도대체 왜?! - 답은 늘 쉬운 곳에
Pool의 문제
커넥션 풀이 범인이라고 생각했다. 패턴을 보면 100~200ms의 평균적인 수치를 기록하다가 튀는 시점이 33분 20초 시점부터 1초대가 발생했다. 스카우터의 xlog를 보면 커넥션 풀을 가져오는 래그가 발생하는 것을 볼 수 있다. 쿼리 자체는 느리지 않았지만 그 gap이 문제였는데, 단순 조회였기 때문에 어플리케이션 수준에서 비동기로 따로 로직을 타는 부분도 없었고 별도의 병목으로 지적될만한 부분이 없었기 때문이다.
어떻게 분석할 수 있을까?
조정한 커넥션 풀의 개수는 maximum-pool-size: 20, minimum-idle: 15 였는데, 이것이 부족한 것일까?
부하가 지속되면서 풀이 찼고, 새로운 풀을 맺으려고 요청하는 과정에서 딜레이가 발생한 것일까?
그렇게 생각하면, 1초대, 2초대 이상 발생한 요청에 대해서는 납득하고 넘어갈 수 있었는데, 정말 그러한 것일까? 아무리 생각해도 이상했다.
그럼에도 이러한 의심이 가능성이 높다고 생각한 이유는 실제로 수동으로 조회했을 때, 즉 부하 없이 일반적인 상황에서의 요청은 대다수가 50~100ms에 위치했고 오케스트레이션에서도 100ms 안팎으로 받을 수 있었기 때문이었다.
다른 응답들을 살펴보아도 대체로 실제 조회 응답은 20ms 안팎에서 끊기고, gap 시간으로 100ms 정도의 시간이 소요된 것을 볼 수 있었다.
그렇다면 max pool 사이즈를 2배 늘리고 부하를 조금 줄여본다면 보다 마일드한 환경에서의 성능 지표를 확인할 수 있지 않을까?
먼저 다시 한번 explain을 확인해보자.
정기권 조회의 explain
INSERT INTO MY_TABLE(id, select_type, `table`, partitions, type, possible_keys, `key`, key_len, ref, rows, filtered, Extra) VALUES (1, 'SIMPLE', 'ticket', null, 'ref', 'IDX_TICKET_LOT,IDX_TICKET_START,IDX_TICKET_COMP_PARK_START', 'IDX_TICKET_LOT', '403', 'const', 4029, 49.99, 'Using where; Using filesort');
두 가지 포인트에 주목했다.
분석해야 할 주요 요소는 IDX_TICKET_COMP_PARK_START 인덱스가 제대로 사용되지 않았다는 점과, Using filesort가 사용된다는 점이었다.
📌 IDX_TICKET_COMP_PARK_START 인덱스 사용 문제
- 인덱스 설계 확인: IDX_TICKET_COMP_PARK_START 인덱스는 parkingLotId와 startAt 컬럼을 기준으로 생성되어 있었다. 이는 주차장 ID와 시작 시간을 이용한 조회에 최적화되어 있어야 했다. 해당 쿼리에서는 parkingLotId와 startAt 범위를 기준으로 데이터를 요청하고 있으므로, 이 인덱스가 사용되어야 했다.
- 인덱스 선택 메커니즘: MySQL은 쿼리를 실행할 때 다수의 가능한 인덱스 중에서 하나를 선택한다. possible_keys에서 여러 인덱스가 후보로 나타났으나, 실제로 선택된 키는 IDX_TICKET_LOT이다. 이는 MySQL 옵티마이저가 IDX_TICKET_COMP_PARK_START 인덱스보다 다른 인덱스를 선택한 것으로, 쿼리의 조건이나 데이터 분포에 따라 최적이라고 판단된 인덱스를 선택한다.
→ 즉, 의도한 IDX_TICKET_COMP_PARK_START 가 아닌 IDX_TICKET_LOT 을 탔다. 그런데 그렇다고 해도 현재 발생하는 gap의 시간이 설명이 안된다.
→ 쿼리 패턴이 정확히 의도한 인덱스와 일치했는데도 해당 인덱스를 타지 않은 이유는 데이터의 분포 때문이었을 것이다. 현재 개발 환경에서 생성된 더미 데이터는 3월 데이터들 위주였다. 따라서 더미 데이터가 특정 기간(예: 3월)에 집중되어 있고, 이 데이터가 IDX_TICKET_LOT를 통해 더 효율적으로 액세스될 수 있어서 옵티마이저는 IDX_TICKET_LOT 인덱스를 선호한 것으로 추정되었다.
📌 Using Filesort 분석
Filesort 사용 이유: Using filesort는 MySQL이 결과를 정렬하기 위해 인덱스를 사용할 수 없을 때 발생한다. 이 쿼리에서는 명시적인 ORDER BY 구문이 보이지 않지만, LIMIT와 함께 사용되어 정렬이 필요한 상황이 발생했을 수 있다. 특히, startAt 기준으로 데이터를 필터링하면서 이 필드에 대한 정렬이 내부적으로 수행될 가능성이 있다.
→ Filesort는 추후 개선 포인트가 될 여지는 있었지만 당장의 문제는 아니었다.
→ 어쨌든, 두가지 이유 모두 다 gap의 시간을 설명하지 못했다.
Pool 사이즈 x2, 부하x1/2
기존의 초당 5~10개 요청을 절반으로 줄이고 풀을 10개에서 20개로 늘려보았다. 추론이 맞다면, 이러한 변화로 문제가 잡혀야 마땅할 것이다.
> request count 340 (OK=340 KO=0 )
> min response time 7 (OK=7 KO=- )
> max response time 1200 (OK=1200 KO=- )
> mean response time 136 (OK=136 KO=- )
> std deviation 204 (OK=204 KO=- )
> response time 50th percentile 21 (OK=21 KO=- )
> response time 75th percentile 202 (OK=202 KO=- )
> response time 95th percentile 660 (OK=660 KO=- )
> response time 99th percentile 851 (OK=851 KO=- )
> mean requests/sec 2.222 (OK=2.222 KO=- )
---- Response Time Distribution ------------------------------------------
> t < 800 ms 332 ( 98%)
> 800 ms <= t < 1200 ms 8 ( 2%)
> t >= 1200 ms 0 ( 0%)
> failed 0 ( 0%)
전체적인 응답 속도는 100ms 수준으로 맞췄는데 문제는 여전히 튀는 항목들이 존재한다! 즉, 문제 해결이 여전히 안된다.
실제 xlog를 분석해 보면 db에서의 조회 자체는 20ms 안팎이나 그 외의 시간 소요가 걸린 것을 볼 수 있었다.
대체 어느 부분에서 병목이 발생하는 것일까?
혹시 정말 순차 처리의 문제일까?
parrallel 로 변경해보자.
parrallel 적용
앞에서 논의한 ForkJoinPool을 이용한 병렬 방식으로 Stream API의 parrallelStream()으로 stream을 변경했다.
전반적인 개선은 있었다.

위의 스카우터에 찍힌 지연 Xlog이다. 동일한 증상이었다.
[000025] 12:02:28.140 652 0 RESULT-SET-FETCH #7,566 606 msrequest count 340 (OK=340 KO=0 )
min response time 8 (OK=8 KO=- )
max response time 802 (OK=802 KO=- )
mean response time 84 (OK=84 KO=- )
std deviation 109 (OK=109 KO=- )
response time 50th percentile 17 (OK=17 KO=- )
response time 75th percentile 177 (OK=177 KO=- )
response time 95th percentile 250 (OK=250 KO=- )
response time 99th percentile 361 (OK=361 KO=- )
mean requests/sec 2.237 (OK=2.237 KO=- )
---- Response Time Distribution ------------------------------------------------
t < 800 ms 339 (100%)
800 ms <= t < 1200 ms 1 ( 0%)
t >= 1200 ms 0 ( 0%)
failed 0 ( 0%)
평균응답은 100ms 초반으로 줄어서 20% 의 추가 개선은 분명 주목할만 했다. 이것으로 병렬 처리의 성능 개선은 분명히 있다는 점이 확인된 셈이다.
하지만 특정 응답이 튀는 현상은 여전하다. 여전히 lag 응답이 확인되었고 똑같은 증상으로 db 조회 대비 gap에서의 시간 지연이 확인되었다.
문제 해결의 길이 보이지 않는 것 같았다.
정말 DB나 다른 네트워크의 문제가 없을까?
- 디스크 IO도 다시 확인했다. → 튀는 부분은 있으나 크게 문제는 없었다.

- CPU → 특이 사항 없음
- 네트워크 → 일상적인 수준
현재 상황 다시 요약
정말 무엇 때문인지 이젠 미궁에 빠져버렸다. 뭘까?!
다시 상황을 요약해보았다.
HikariCP 커넥션 풀을 20개로 설정했고, 초당 10개의 동시 요청이 들어오며, TPS가 100~200 수준이며, DB 응답 시간이 평균 20ms에서 100ms 사이인 상황이다.
애플리케이션의 커넥션 풀 사용 상황을 분석해 보자.
적절한가? 불현듯 두가지 질문이 떠올랐다.
- 커넥션 풀이 100%를 치고 있는 것을 어떻게 알 수 있는가?
- 혹시…! Heap memory의 부족에 따른 GC time 딜레이로 인한 어플리케이션 연산 지연은 아닐까?!
logback 설정 변경
logback 설정을 변경하여 클라우드 환경에서도 커넥션 풀의 실시간 스탯이 찍히도록 조정했다.
확인 결과 커넥션 풀의 문제는 아니었다.
부하가 들어와도 차지 않았다!
신기할 정도로 커넥션 풀의 active 수치는 안정적으로 0을 유지했다.

GC 문제일까?
생각해보니 부하가 칠 때 GC Time이 올라가던 게 기억났다.
현재 개발 환경에서 Heap 메모리 설정은 128MB였다. 서비스 간 자원을 나눠 쓰다 보니 이렇게 빠듯한 설정을 유지하고 있었다. 이를 256MB로 올려보았다.

아니… 이게 무슨 일인가 !!!
엄청나게 쾌적해졌다...!!!
튀는 게 하나도 없는 것이다... !!!
메모리 문제로 인해 GC가 과도하게 발생했고 그로 인해 어플리케이션 수준의 딜레이가 발생했던 것이다.
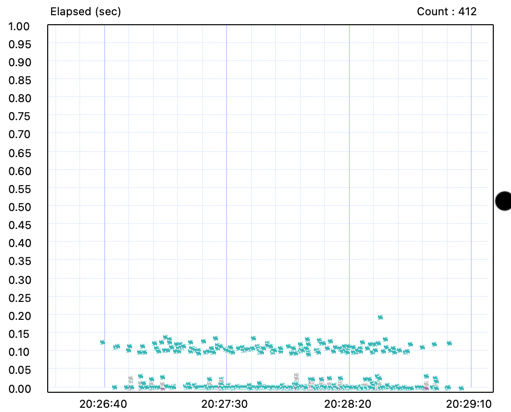
정말 아름답게 찍히는 XLog 그래프…!!
그리고 깔끔하게 떨어지는 GC Time

request count 340 (OK=340 KO=0 )
min response time 9 (OK=9 KO=- )
max response time 259 (OK=259 KO=- )
mean response time 79 (OK=79 KO=- )
std deviation 77 (OK=77 KO=- )
response time 50th percentile 20 (OK=20 KO=- )
response time 75th percentile 163 (OK=163 KO=- )
response time 95th percentile 193 (OK=193 KO=- )
response time 99th percentile 225 (OK=225 KO=- )
mean requests/sec 2.237 (OK=2.237 KO=- )
---- Response Time Distribution ------------------------------------------------
t < 800 ms 340 (100%)
800 ms <= t < 1200 ms 0 ( 0%)
t >= 1200 ms 0 ( 0%)
failed 0 ( 0%)
이렇게 쉽게 풀릴 일이었다고 ?! 단순히 메모리 문제였다니... 너무 쉽게 해결되어 버렸다.
그에 반해... 128MB일때를 다시 살펴보자.
128MB일때


이로써 답은 나왔다. 긴 삽질 끝에 결국 문제는 GC였다. 엄밀히 말하면 메모리의 부족이었다.
어플리케이션의 절대 메모리 부족이 부하 상황에서 응답속도 지연을 야기할 수 있는가?!
YES이다.
결론
APM에서 확인한 지연 현상을 개선하고자 캐시 도입부터 API 변경, 병렬 처리 시도까지 다양한 방법을 시도했고, 여러 가지의 삽질 경험을 다루었다. 결국 문제의 실마리는 GC 로그와 메모리 사용량에서 발견되었고, 힙 메모리 크기를 조정함으로써 문제를 해결할 수 있었다.
단순함에 답이 있다. 역시… 🚀
결론적으로 paging size 50 건 조회 응답에 대해서 평균 응답 기준 550ms → 250ms → 70ms 까지 약 500ms 줄이고 7배 가량 개선에 성공했다.
번외편 - 데드락 만들기
parallelStream() 과 connection Pool을 함께 사용할 때의 문제
parallelStream()은 작업을 병렬로 수행하기 위해 내부적으로 Java의 ForkJoinPool을 사용한다. 병렬 스트림이 동시에 많은 데이터베이스 커넥션을 요청하게 되면, 커넥션 풀의 사용 가능한 리소스가 고갈될 수 있고, 결과적으로 대기 시간이 증가하며 대기 큐가 쌓일 수 있다.
사용 가능한 커넥션 풀의 연결이 모두 사용 중일 때 추가적인 연결 요청이 발생하면, 해당 요청을 처리하는 스레드는 사용 가능한 연결이 생길 때까지 대기 상태에 머무르게 될 것이다. 이로 인해 연결 풀의 모든 연결이 대기 상태에 있는 스레드에 의해 점유되어 있고, 이 스레드들 역시 연결을 기다리며 대기 중이라면 데드락(Deadlock) 상황이 발생할 수 있다.
정말 그럴까?
pool 수치를 낮춰보자
문득 궁금해졌다.
pool stat을 찍어보았을 때 DB 응답 속도에 문제가 없었기 때문에 idle이 15이고 active는 0으로 찍혔다.
또한, hikari 공식 문서에서도 제시하듯이 pool은 적어도 충분하다.
그렇다면 pool을 낮춰보면 어떨까?
기본 값을 5개로 설정하고 max를 10개로 설정해보았다.
앗, 그러니깐 다음과 같은 로깅이 확인되었다. 못보던 로깅이었다.
00:39:47.887 [DEBUG] [ForkJoinPool.commonPool-worker-6] [ com.zaxxer.hikari.pool.HikariPool] - HikariPool-1 - Add connection elided, waiting 1, queue 2
00:39:47.887 [DEBUG] [ForkJoinPool.commonPool-worker-8] [ com.zaxxer.hikari.pool.HikariPool] - HikariPool-1 - Add connection elided, waiting 1, queue 2
00:39:47.887 [DEBUG] [ForkJoinPool.commonPool-worker-15] [ com.zaxxer.hikari.pool.HikariPool] - HikariPool-1 - Add connection elided, waiting 1, queue 2
00:39:47.887 [DEBUG] [ForkJoinPool.commonPool-worker-9] [ com.zaxxer.hikari.pool.HikariPool] - HikariPool-1 - Add connection elided, waiting 1, queue 2
00:39:50.756 [DEBUG] [XNIO-2 task-5] [ com.zaxxer.hikari.pool.HikariPool] - HikariPool-1 - Add connection elided, waiting 2, queue 3
00:40:09.613 [DEBUG] [ForkJoinPool.commonPool-worker-10] [ com.zaxxer.hikari.pool.HikariPool] - HikariPool-1 - Add connection elided, waiting 2, queue 3Add connection elided, waiting N, queue M
무슨 메시지일까?
새로운 데이터베이스 커넥션을 풀에 추가하려는 시도가 생략(elided)되었음을 나타낸다. waiting은 현재 커넥션을 기다리고 있는 스레드의 수, queue는 커넥션 획득을 시도하고 대기 중인 작업의 수를 나타낸다. 즉, 이 상황은 일반적으로 커넥션 풀이 가득 차 있고, 추가 커넥션 생성이 필요하지 않거나 제한에 도달했음을 의미한다.
구현 코드를 보면 다음과 같은 부분이 로그의 원천이다.
@Override
public void addBagItem(final int waiting)
{
final boolean shouldAdd = waiting - addConnectionQueueReadOnlyView.size() >= 0; // Yes, >= is intentional.
if (shouldAdd) {
addConnectionExecutor.submit(poolEntryCreator);
}
else {
logger.debug("{} - Add connection elided, waiting {}, queue {}", poolName, waiting, addConnectionQueueReadOnlyView.size());
}
}
즉, 커넥션 풀의 자원이 최대 한계에 도달하여 추가 커넥션 생성 요청이 일시적으로 무시된 것이다.addBagItem 메서드의 구현을 보면, 현재 대기 중인 스레드의 수(waiting)와 대기 큐(queue)에 있는 작업의 수를 기반으로 새로운 커넥션을 추가할지 여부를 결정한다. waiting - queue size >= 0이라는 조건은 커넥션 요청이 대기 큐에 있는 작업 수보다 많거나 같을 때 새로운 커넥션을 추가하려고 시도한다는 것을 의미한다. 여기서, >= 연산자 사용은 의도적이며, 이는 적어도 한 개의 대기 중인 요청이 있을 때만 새로운 커넥션을 추가하려는 로직을 반영한다.
하지만, 이 조건이 충족되지 않을 경우, 즉 현재 대기 중인 요청 수가 큐의 작업 수보다 적을 경우, else 블록이 실행되며 "Add connection elided, waiting N, queue M" 로그 메시지가 출력된다. 이는 시스템이 현재 커넥션을 더 생성할 필요성을 느끼지 않거나, 커넥션 풀의 설정된 한계치에 도달하여 추가 커넥션 생성을 생략하고 있다는 것을 나타낸다.
그런데 이것은 좀 이상하지 않은가? 분명히 대기가 더 많을 것인데 말이다. 그렇다면 어째서 else 블록이 실행된 것일까?
ForkJoinPool의 부작용 그리고 아주 재밌고 놀랍고 감탄스러운 부분!
이는 ForkJoinPool을 사용하는 병렬 스트림 처리 과정에서 발생할 수 있는 특수한 상황에서 기인한다.
ForkJoinPool의 작업 스레드들은 대기 중인 작업이 있더라도, 현재 실행 중인 작업을 완료할 때까지 추가 작업을 수행하지 않는 특성을 갖는다. 이러한 특성은 병렬 스트림 처리 중 데이터베이스 커넥션 요청 같은 I/O 대기 작업에서 문제가 발생할 수 있다는 것을 시사한다. 아주 재밌는 포인트이다.
커넥션 풀 설정에 따라 사용 가능한 커넥션 수가 제한되어 있을 경우, 모든 커넥션이 사용 중이고 추가 커넥션 생성에 대한 요청이 발생하면, 해당 요청은 대기 큐에 추가된다. 그러나 병렬 스트림을 처리하는 스레드들이 I/O 작업에 대기 상태에 빠져 있을 때, 실제로 실행 가능한 작업(커넥션 요청 포함)이 존재하더라도 이를 처리할 수 있는 스레드가 없게 되는 상황이 발생할 수 있다. 그 결과 waiting 수치가 실제로 queue의 크기보다 작게 계산될 수 있으며, 이로 인해 else 블록의 로그가 기록될 수 있다.

이러한 현상이야말로 병렬 스트림과 커넥션 풀 사용 시 발생할 수 있는 복잡한 상호작용을 보여주는 포인트이다. 병렬 처리 시스템의 설계에서 고도의 동시성과 비동기 I/O 작업의 특성을 고려하지 않으면, 특히 블로킹 작업이 맞물려 있는 경우 심각한 부작용을 초래할 수 있는 사례인 것이다.
한편, 이러한 문제를 HikariCP는 마치 고려했다는 듯이, 커넥션 풀의 크기를 동적으로 조절하는 로직을 구현하고 있었다는 것이 또 놀라운 부분이다.
커넥션 풀의 동적 관리와 리소스 활용의 균형을 유지하려는 HikariCP의 설계 철학을 반영한 부분일 것이다. 커넥션 풀의 크기를 동적으로 조절함으로써, 필요한 시점에만 리소스를 할당하고, 사용하지 않는 커넥션은 재활용하려는 목적이다. addBagItem 메소드의 로깅에서 볼 수 있듯이, 커넥션 풀은 필요에 따라 새로운 커넥션 생성 시도를 생략(elided)할 수 있다. 이러한 설계 덕분에, 커넥션 요청이 폭증하여도 내부적으로 커넥션 생성과 할당을 효율적으로 관리하여 데드락에 이르지 않도록 한다.
결론적으로 이러한 로깅의 발생은 대기 중인 작업이 많아 커넥션 풀의 크기가 충분하지 않을 수 있음을 시사한다. 명확한 데드락으로 이어지지는 않았지만, 분명 커넥션 풀의 과부하와 관련된 병목 현상의 신호이다. 커넥션 요청이 대기열에 쌓이게 되면, 시스템의 처리량이 저하되고 응답 시간이 증가하게 된다. 특히, waiting과 queue의 값이 지속적으로 증가하는 상황이 발견된다면, 이는 시스템이 현재의 부하를 감당하지 못하고 있음을 의미한다.
그래도 데드락을 발생시켜 보고싶다면?
보다 극단적인 상황을 시뮬레이션 해보기로 했다.
- 동시 요청수를 극단적으로 증가(기존 대비 100배 증가 -> 초당 1000회의 요청)
- pool size는 idel1, max1로 조정
- 캐시는 off
데드락 조건 불충분
아쉽게도 단순 조회 요청이므로 커넥션 데드락 조건을 형성하지는 않았다. 그 이유는 무엇 때문일까?
그 이유는 복수의 트랜잭션이나 커넥션 요구 사항이 겹치지 않는 경우, 즉 각 작업이 독립적으로 실행되며 서로 다른 리소스에 대한 점유를 시도하지 않기 때문이다. 이는 데이터베이스의 락킹 메커니즘과 관련이 있다.
데드락은 두 개 이상의 트랜잭션이 서로의 완료를 기다리며 영원히 대기하는 상태를 의미한다. 상호 배제, 점유 및 대기, 비선점, 순환 대기 등의 조건이 모두 충족될 때 발생한다. 본 시나리오에서는 단일 작업에서 하나의 커넥션만을 사용하므로 상호 배제 조건은 충족될 수 있다. 그러나 점유 및 대기 조건, 즉 하나의 작업이 이미 점유한 리소스를 유지한 채로 다른 작업이 점유한 리소스를 추가로 요구하는 상황이 발생하지 않는다. 각 병렬 스트림 작업은 독립적이며, 서로 다른 커넥션을 사용하여 데이터베이스에 접근한다.
더욱이, searchWithMeshParallel 에서 병렬 스트림을 사용하여 데이터 처리를 수행하는 경우에도 각 스레드가 독립적으로 데이터베이스 커넥션을 활용한다. 따라서, 한 스레드의 작업이 다른 스레드의 작업에 의해 차단되거나 대기 상태에 빠질 가능성이 매우 낮다.
따라서, 이러한 환경에서는 데드락이 발생하지 않는다. 다만, 위의 로깅에서 볼 수 있듯이, 커넥션 풀의 크기가 작은 상황에서 부하가 발생하는 경우 커넥션 요청이 대기열에 쌓이며 처리를 위해 대기하는 상황을 유발되고, 리소스 부족으로 인한 처리 지연으로 이어질 것이다.
결과
실제로 특정 시점부터 상당히 느려지는 결과를 볼 수 있었다.
Gatling 테스트는 60초 타임아웃이 default인데, 타임아웃이 나면서 실패 케이스들이 발생했다.
10:07:08.990 [ INFO] [XNIO-2 task-44] [ k.c.p.p.c.l.i.ThreadLocalLogTracer] - [05d6bc21] |<--TicketCrudController.searchWithMesh(..) time=38290msGlobal (OK=121 KO=26 )
정기권 목록조회 - 고정 페이지 (OK=121 KO=26 )
---- Errors --------------------------------------------------------------------
Request timeout to localhost/127.0.0.1:9602 after 60000 ms 23 (88.46%)
이와 같이 Gatling 테스트가 실패하는 상황이 발생했다.
로그에서 보다시피 38289ms의 지연과 같은 긴 지연이 발생했다. 단 하나의 데이터베이스 연결만 사용 가능하기 때문에, 나머지 요청들은 사용 가능한 커넥션이 생길 때까지 대기해야 한다. 이 대기 시간이 누적되어 전체 요청 처리 시간이 길어지게 된 것이다. 연쇄적으로 요청이 밀려서 결국 타임아웃이 나게 되었고 다음과 같이 Could not write JSON: java.io.IOException: Broken pipe; 오류를 발생시켰다.
다소 극단적인 상황이었지만, 확실히 커넥션 풀의 사이즈에 따라 극과 극의 차이가 발생할 수 있는 것을 볼 수 있는 테스트였다.
참고 자료
Forkjoinpool
- https://medium.com/geekculture/pitfalls-of-java-parallel-streams-731fe0c1eb5f
- https://dev-milk.tistory.com/5
Hikari
- https://medium.com/@rajchandak1993/understanding-hikaricps-connection-pooling-behaviour-467c5a1a1506
- https://github.com/brettwooldridge/HikariCP
- https://github.com/brettwooldridge/HikariCP/wiki/About-Pool-Sizing#the-formula
- https://medium.com/@guptadiksha88/hikari-cp-efficient-database-connection-pooling-d458c0bdf7df
- https://techblog.woowahan.com/2664
- https://techblog.woowahan.com/2663
Gatling
기타
'이슈와해결' 카테고리의 다른 글
| 대기열 기반 예약 시스템에서 MSA와 EDA를 이용해 느슨한 결합 추구하기 (0) | 2024.08.11 |
|---|---|
| 대기열 시스템 다양한 설계 방법 탐구 (feat. 레디스와 카프카를 이용한 O(1) 최적화) (2) | 2024.08.10 |
| 자바에서 동시성 문제를 다루는 n가지 방법들(feat. 주식 매수) (6) | 2024.03.28 |
| 티켓 서비스 백엔드 시스템에서 중복 요청 이슈를 멱등하게 처리하기 (0) | 2024.03.01 |
| 예외 알림 프로세스에서 OOM을 방지하며 중복 처리를 위한 Marking 방식 (WeakHashMap) (1) | 2024.02.18 |



