개요
도메인 서비스를 개발하면서 id 채번 방식을 고민한 적이 있었다. 개인 프로젝트를 할 땐 auto generation 옵션으로 순번으로 생성되는 것을 너무 당연하게 생각했었다. 회사에서 다양한 케이스들을 접하면서 도메인 서비스에서 자동 채번으로 데이터가 쌓이기 시작할 때 다양한 문제가 생길 수 있다는 걸 알게 됐다. pk 생성 규칙을 정하기까지 다양한 옵션들을 탐구해보면서 고민했던 과정을 기록해보았다.
@GeneratedValue 부터 멱등성 보장 규칙에 이르기까지 한 마디로 삽질의 기록이다. 하지만 해당 프로젝트를 하면서 정말 혼자했더라면 생각해보지도 못했을 것들을 많이 접하게 돼서 여러 배움 중에서도 인상 깊은 배움이었다.
- 용어나 예시 코드는 실제가 아닌 컨셉 용어, 컨셉 코드로 대체하였습니다.
목차
- 고려한 점
- 초기 구현
- 변경 1
- 변경 2
- 회고 및 후속 대책
1. 고려한 점
초기 PK를 생성해야 하는 일에서도 고민을 하지 않았던 것은 아니다. 나름대로 'PK는 어떠해야 한다'는 것을 다음과 같이 생각했었다. 아래는 PK라면 으레 가져야할 당연한 속성들이다.
PK의 기본 특성
Uniqueness:PK는 유일성이 있어야 한다.Stability:PK는 변경되면 안 된다.Irreducibility: 복합키를 사용하지 않는 이유는 복합키 중 하나가 변경될 경우PK유일성이 깨질 수 있기 때문이다.Simplicity:PK는 간단하고 이해하기 쉬워야 한다.
고민의 필요성
- 초기 방식으로는 해당
엔티티의 특성상 큰 비즈니스 연관 고리(어떤 지점이나 회원 등)가 없다고 판단하였고, 최대 생성 개수가 1,000개 이내로 예상되는 것을 고려해 자동 생성된 Long 타입의 PK를 사용하기로 결정했다. - 해당
엔티티의 사용제한성, 비연관성을 고려하더라도 Pk는 자연 숫자보다는 유의미한 네이밍이 좋다는 걸 놓쳤다. 어떤 의미에서든 해당 Key값을 통해 정보를 인지하고 공유할 수 있기 때문이다. - 예컨대, 여러 도메인에서 다양한 정보를 조회할 때 어떤 도메인의 PK는 "DC-PR-A11239419-19292"인 반면 어떤 PK는 "123491"라면 어떤 것이 유용할까? 당연히 전자다. 전자의 PK에서는 "DC -> Discount", "PR -> price"라는 정보가 유추 가능하기 때문이다. 후자의 경우에서는 어떤 의미도 추출해내기 어렵고 비즈니스 활용도에 있어서 아무런 가치가 없는 pk가 된다.
- 한편, 자연키를 포함한
PK구현에서는 (당연히) 충돌이 발생하지 않도록 유니크함을 보장하는 로직이 필요하다.
2. 초기 구현
초기 방식에서는 JPA의 @GeneratedValue 애노테이션을 사용하여 DB에서 자동으로 증가하는 Long 타입의 PK를 사용했다. 해당 방법을 선택한 이유는 해당 도메인의 비즈니스 특성상 생성 최대 개수가 수 천개 이내로 제한될 것으로 보았고, 그 엔티티의 역할을 고려할 때 비즈니스 연관성을 고려한 PK 채번 이유가 없다고 보았기 때문이다.
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long globalTemplateId;
위에서 언급한 것처럼 너무 나이브한 생각이다.
3. 변경 1
식별자로서의 의미를 강화하기 -> 비즈니스 로직 결합
피드백을 통해 비즈니스 연관성이 적다고 하더라도 더 명확한 의미를 지닌 PK를 사용하는 것이 Auto Generation 보다 낫다고 판단하게 되었다. 도메인을 포함하는 prefix와 고유성을 보장하는 uuid, 시간 해싱을 사용하는 방식으로 문자열 기반의 PK로 변경하였다.
생성 로직
prefix와key의 개념은 그대로 유지하되, 특정 업계나 프로젝트에 특화된 예제를 제거합니다. 대신,prefix는 예를 들어MY_PREFIX와 같이 일반적인 예제로 변경한다.key의 로직에 관한 설명에서는, 현재 시간을 고려하는 것과 MD5 해싱을 사용한다는 점을 유지하지만, 특정 프로젝트나 업계에 특화된 세부사항은 제거한다.
수정된 코드 예시:
/**
* 이 메서드는 주어진 접두사와 자릿수를 사용하여 고유한 ID를 생성합니다.
* UUID의 일부와 현재 시간을 결합하여 MD5 해시를 생성하고,
* 그 해시값을 사용하여 주어진 자릿수에 맞는 고유한 ID를 반환합니다.
*
* @param prefix ID의 앞부분에 붙일 접두사
* @param digitLength 생성할 ID의 총 자릿수 (UUID 포함)
* @return 생성된 고유한 ID
*/
public String generateId(String prefix, int digitLength) {
// 코드 로직
}
// 나머지 메서드들...
@Id
private String uniqueEntityId;
@PrePersist
public void generateId() {
// 코드 로직
}
테스트
다음과 같은 테스트는 총 50만 번의 생성을 통해 본 로직이 생성하는 PK가 유니크함을 증명한다.
@Test
@RepeatedTest(50)
@DisplayName("Md5BasedPkIdGenerator의 ID 유니크함을 테스트 -> 10,000 x 50 번의 반복을 통해 중복이 없음을 증명")
void testUniqueIdGeneration() {
Md5BasedPkIdGenerator generator = Md5BasedPkIdGenerator.getInstance();
int repeat = 10000;
String prefix = "UNIQUE-TEST-";
int digitLength = 16;
Set<String> ids = new HashSet<>();
for (int i = 0; i < repeat; i++) {
String id = generator.generateId(prefix, digitLength);
ids.add(id);
}
assertEquals(repeat, ids.size());
}
4. 변경 2
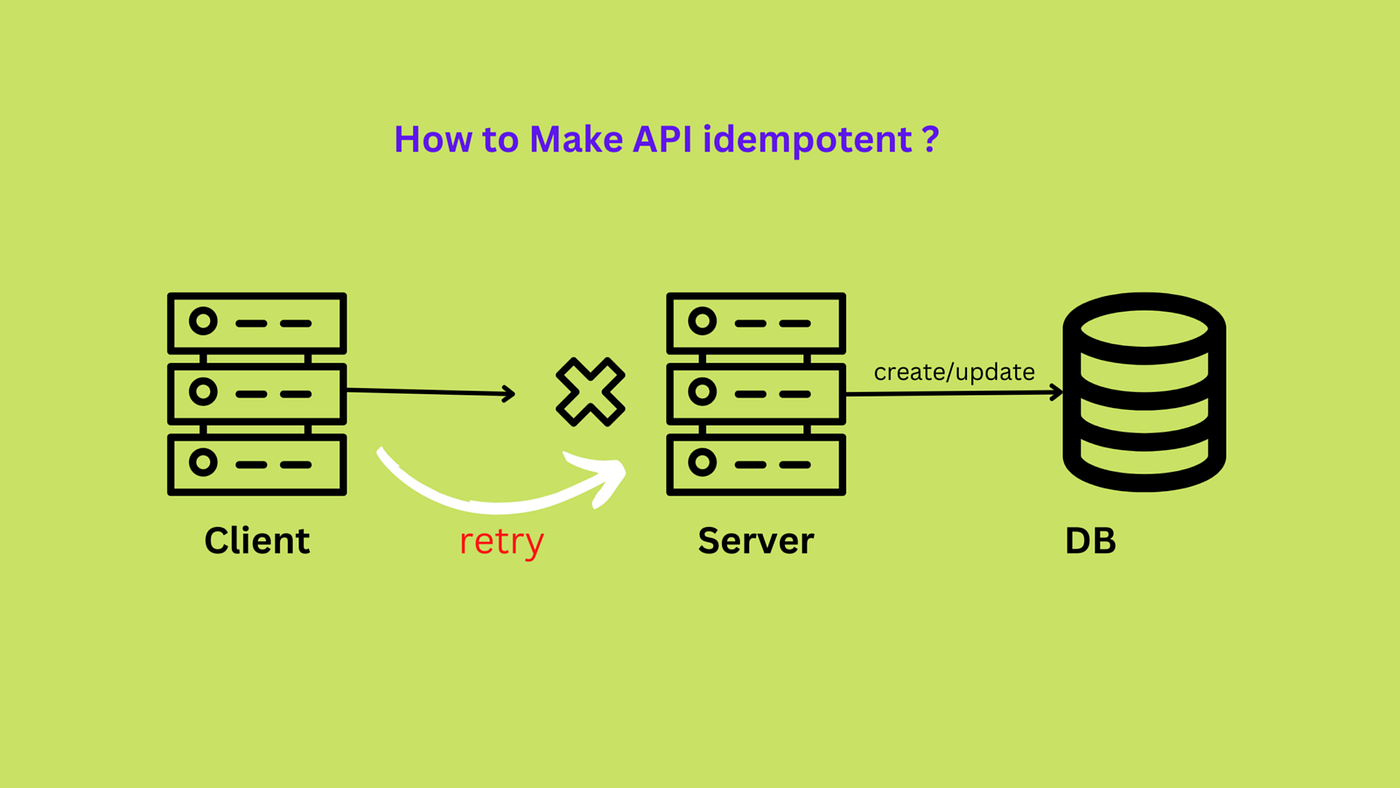
또 하나의 문제가 있었다. 오케스트레이션으로부터 인입되는 요청에 대해 도메인 서비스에서 멱등성을 보장하지 못하면 동일한 요청에 대한 동일한 데이터가 id만 다르게 몇 번이고 쌓일 수 있다는 것이다. 엥... 정말? 왜 그런 일이 생길까? 라고 처음에 생각했는데, 실제 운영 환경에서 그러한 일이 꼭 발생하는 것이 문제였다. '그런 일은 생기지 않아'가 아니라 '생기면 어떻게 할 것이냐'이다. 감당해야 할 비용이 너무 컸고 경험 데이터를 토대로 볼 때 실제로 그러한 일이 생긴다는 것이다.
멱등성의 문제
네트워크 불안정이나 다양한 이유로 인해 클라이언트 요청이 2회 이상 들어올 수 있다. 이러한 상황은 클라이언트의 재시도 로직 혹은 다른 네트워크 문제로 발생할 수 있다. 따라서 멱등성을 보장하지 않으면 동일한 작업이 중복으로 수행될 가능성이 있다.
해결 전략: POST에서 PUT으로
기존의 POST 방식 대신 PUT 방식을 사용하여 클라이언트에서 id를 직접 생성하도록 변경했다.
이러한 내용은 정책적 결정으로써 서버가 동일한 id에 대한 요청을 멱등하게 처리하기 위함이었다.
이와 같은 변화에 따라 기존의 서버에서 생성하는 pk generation 전략을 폐기하고 클라이언트 측에서 생성하는 전략으로 변경하였다.
클라이언트 측에서의 변경
- 적절한 규칙에 따라
id값을 생성한다. - 생성한
id의 고유성을 서버로부터 확인한다. - 고유성이 보장되면 해당
id로create요청을 전송한다.
서버 측에서의 변경
@PutMapping("/resource")
@Operation(summary = "리소스 생성")
public ResponseEntity<Void> createResource(@Valid @RequestBody ResourceRequest request){
service.saveResource(request);
return ResponseEntity.ok().build();
}
생성에 있어서 POST가 아니라 PUT이라니 !
그리고 그 책임을 클라이언트에게 전가한다?
멱등성을 보장하기 위해 Http 규약을 깨는 것을 생각해 보지 못했었기 때문에 이러한 접근을 처음 접할 땐 당황스러웠던 것 같다.
그래서 이런 저런 고민도 해보고 다음과 같은 안도 제시해보았다.


그렇지만 어떤 방식을 써보아도 결국 본질적인 멱등함을 보장하지 않으면 문제는 같았고 결국 최선의 방식으로 위에서 결정한 방식으로 선택했다.
5. 회고 및 후속 대책
본 전략 결정에 대해서는 다음의 내용들을 고려해야 했다.
- 불변 필드들이 없을 때 고유한
PK를 어떻게 생성할 것인가? POSTvs.PUTPK채번 역할은 서버 고유의 역할이 아닌가?- 향후 문제 발생시 책임은 어느쪽에서?
첫 번째 주제로, 해당 프로젝트에서는 새로운 유형의 데이터 템플릿을 도입하는 케이스였는데, 이 템플릿은 기존의 고정된 구조와 달리, 유연하고 다양한 필드가 제공되었다. 예전의 템플릿에서는 특정 필드들이 고정값으로 설정되어 있어, 이 값을 기준으로 데이터를 식별할 수 있었다. 그러나 새로운 템플릿에서는 이러한 고정값이 없기 때문에, 데이터의 고유 식별자를 생성하는 데에 있어 새로운 접근 방식이 필요했다.
만약, 불편 필드를 찾을 수 있었다면 서버에서 생성하면서 해당 값을 기준으로 멱등성을 보장하는 로직을 구현할 수 있었을 것이다. 결과적으로 이 부분 때문에 id 생성을 클라이언트 쪽에서 하는 것으로 결정한다.
두번째 이슈로, create 로직에 PUT을 적용하면 다음과 같은 장단점이 있다고 분석했다.
장점
- 멱등성: 동일한 리소스에 대한 동일한 PUT 요청은 항상 동일한 결과를 반환하기 때문에, 멱등성이 필요한 경우 유용하다.
- 단순성: 리소스의 생성과 수정 로직을 하나의 엔드포인트에서 처리할 수 있으므로 API 설계가 단순해진다.
단점
- 의미론적 부정확성: PUT이 리소스를 "대체"하는 의미로 설계되었다는 점을 고려할 때, 새로운 리소스를 생성하는 데 PUT을 사용하는 것은 HTTP 메서드의 의미론적 정확성을 해칠 수 있다.
- 복잡성: PUT 요청을 통해 리소스를 생성할 때는 클라이언트가 리소스의 식별자를 미리 알고 있어야 한다. 이것은 클라이언트와 서버 간에 추가적인 약속을 필요로 한다.
결론적으로 PUT을 사용하여 리소스를 생성하는 것은 멱등성을 보장해야 하는 환경에서 유용할 것이고, 따라서 MSA 기반의 분산 아키텍처 환경을 고려할 때 충분히 필요한 전략일 수 있다는 생각이 들었다.
셋째로, PK 채번 역할은 서버 고유의 역할이 아닌가? 라는 문제에 대해서는 관점에 따라 다를 수 있다. 아이디 생성 포맷의 문제를 리소스의 규칙이라는 광의에서 접근한다면, 반드시 생성자와 관리자가 같을 필요가 없을 수도 있겠다. id 생성이 복잡한 비즈니스 로직을 필요로 한다면, 이는 서버 측에서 관리되어야 할 것이나, 단순히 고유한 값이어야 하는 것이라면, 이를 클라이언트에서 생성하는 것이 시스템의 복잡성을 줄이고 멱등성을 보장하는 구현으로써 영속 계층의 안정성을 높일 수 있을 것이다.
마지막으로, 만에 하나 향후 PK 관련 문제가 발생한다면 어떻게 책임을 확인할 것인가에 대해 고려해야 했다.
- 잘못된 ID 생성: 클라이언트에서 잘못된
id를 생성하는 경우가 발생하지 않도록 해당id의 유효성이 충분히 검토되어야 한다. - 보안 문제:
id가 예측 가능하다면 보안 문제가 될 수 있습니다. 위의 문제와 같은 맥락이다.
결론
이 경험을 하면서 뇌리를 자주 스치던 주제가 '비즈니스적인 관점에서의 개발'이 아니었나 싶다. 여러가지 다양한 개발의 모습들이 있겠지만 어찌되었건 굴러가는 바퀴가 되기, 개발의 쓸모에 대해서 생각해볼 수도 있던 경험이었다.
'이슈와해결' 카테고리의 다른 글
| 리팩토링 회고 - 입사 3개월 차에 만난 거대한 코드를 넘어가기 위해 생각했던 방법들 (0) | 2023.12.17 |
|---|---|
| 엔티티 필드 매핑 전략 탐구: 성능 테스터 Gatling을 이용한 Json 필드 매핑 사례 분석 (0) | 2023.12.16 |
| 입사 0년차 주니어의 첫 운영 배포와 실수 경험 (0) | 2023.12.14 |
| 엔티티가 연장되는 속성을 가진 경우 효율적인 참조 관계 맺기 (1) | 2023.12.14 |
| 리팩토링 회고 - QueryDsl 검색 로직을 좀 더 클린하게 만들어보기 (0) | 2023.12.13 |

