본 글에 대해서
회사 수습 기간 중에 한 도메인의 비즈니스 오케스트레이션 서비스를 들여다 볼 기회가 있었다. 해당 오케스트레이션의 취약점을 분석하고 해결 전략을 제시하는 업무를 맡았었다. 그 일을 하면서 본 업무와는 별개로 해당 프로젝트에 대해 코드 레벨 수준의 리팩토링을 제안했었다. 왜냐하면 막상 코드를 읽으니 읽는 것 자체가 너무 어렵고 흐름 파악하는 데 시간이 너무 오래 걸렸기 때문이다. 내 실력이 부족해서 이해 비용이 많이 들었을 수도 있다. 하지만 조금 더 구조화가 잘 되어 있고 코드가 클린했다면 유지보수에 있어서 범용성과 효율성이 많이 높아졌을 것이라 생각했다.
본 글은 그때 리팩토링을 제안하면서 쓴 글을 각색해서 재작성한 글이다. 주요 용어나 실제 코드는 컨셉용으로 대체하였고 민감한 부분은 삭제하였다.
0. 개요
특정 도메인의 오케스트레이션인 sample-processor 서비스의 코드 레벨에서의 현 상황을 진단하고, 개선점에 대해 제안합니다.
1. 배경
관련 이슈에서 발견된 문제점들과 잠재적 문제들을 분석하고 해결책을 찾는 과정 중 sample-processor의 개선이 필요하다고 판단되었습니다.
- 테스트 코드의 부재
→ 작은 수정이 발생하더라도 기존과 동일한 작동을 보장 받을 수 없으므로 수정에 따라 발생하는 리스크가 너무 큽니다.
→ 향후 기능 추가 등의 요청이 발생할 때 해당 문제는 더 커질 수 있습니다. - 테스트 코드 작성의 어려움
→ 현재 작성된 코드에서는 복잡한 코드 구조, 정돈이 필요한 패키지 및 레이어 구조, 많은 중복 코드와 파라미터, 잘 분리되지 않은 책임과 역할 등의 이유로 코드를 읽고 파악하는 데 오랜 시간이 걸리며, 파악을 했다고 하더라도 많은 관련 기능들이 복잡하게 얽혀 있어 단위 테스트 작성이 어렵습니다. - 유지보수성과 확장성의 저해
→ 이러한 문제는 향후 확장성과 유지보수성을 고려할 때 해결이 필요합니다.
1. 목차
- 개요
- 배경
- 목차
- AS-IS 및 및 제안
- 외부 연결과 내부 비즈니스 로직 처리 패키지를 구분하자
- AS-IS 패키지 구조
- 문제
- 제안
- 예시
- 비즈니스 도메인에서는 추상화된 행위만 정의하고 세부 로직은 구현 레이어로 밀어넣자
- AS-IS 데이터 플로우 및 아키텍처
- 문제
- 제안
- 얻는 것과 잃는 것
- 주요 비즈니스 로직과 부가 로직을 분리하자... 최대한 !
- AS-IS
- 제안
- 데이터 전송시 의미 있는 네이밍의 VO를 활용하자
- 기타 제안
- 외부 연결과 내부 비즈니스 로직 처리 패키지를 구분하자
- 리팩토링 전략
3. AS-IS 및 제안
1. 외부 연결과 내부 비즈니스 로직 처리 패키지를 구분하자
1) 현 패키지 구조

1. api 패키지
- 예시 클래스:
SampleConfigurationControllerV16 - 설명: API 엔드포인트를 제공하는 컨트롤러 클래스들이 위치합니다. RESTful API를 통해 클라이언트와 상호 작용하며, 비즈니스 로직을 실행합니다.
2. client 패키지
- 예시 클래스:
SampleClientV1 - 설명: 외부 서비스와의 통신을 담당하는 Feign 클라이언트나 다른 HTTP 클라이언트 구현이 위치합니다.
3. common 패키지
- 예시 클래스:
StartupConfig - 설명: 애플리케이션 전반에서 공통적으로 사용되는 설정, 유틸리티, 상수 등이 위치합니다. 설정 관련 클래스들도 이곳에 정의됩니다.
4. stream 패키지
- 하위 패키지
sampledomain: 메인 비즈니스 처리와 관련된 클래스들이 위치합니다.consumer: 메시지 큐나 스트림을 통한 데이터 처리와 관련된 클래스들이 위치합니다.
- 예시 클래스:
SampleDomainExchangeFacadeV1(sampledomain)StreamFunctionConfig(consumer)
- 설명: 비동기 메시지 처리나 스트리밍 처리와 관련된 로직이 위치합니다.
5. util 패키지
- 예시 클래스:
StringUtil - 설명: 문자열 처리, 날짜 변환 등과 같은 공통 유틸리티 함수를 포함합니다.
요약
api패키지는 사용자 요청을 받아 처리하는 역할을 담당합니다.client패키지는 외부 서비스에 요청을 보내는 클라이언트 로직을 담당합니다.common패키지는 공통적으로 사용되는 로직과 설정을 관리합니다.stream패키지는 비동기 처리나 스트리밍과 관련된 로직을 담당합니다.util패키지는 공통 유틸리티 기능을 제공합니다.
2) 문제
- stream 네이밍에 대한 불명확성:
api패키지는REST요청을 받고 관련 처리를stream패키지 내부에 존재하는service로 이관합니다.stream패키지는 카프카 요청을 받고 내부의service에서 처리합니다. 이때stream이라는 네이밍의 의도가 불분명합니다. - 비즈니스 로직과의 분리가 안되어 있음: 현재 비즈니스 로직은 주로
stream패키지 내부에 구현되어 있습니다. 그런데 외부와의 통신을 담당하는 로직과 비즈니스의 핵심 로직인 service 로직이 해당 패키지에 상존합니다. 패키지의 책임의 구분이 명확하지 않고 혼재되어 있는 상황으로 혼란이 발생합니다. 그 외에도stream의samplechannel내부에는 다양한 종류의 클래스가 혼재되어 있습니다. (constant,document,dto,event,facade,repository,scheduler,service등).
3) 제안
- 비즈니스 로직 패키지 생성: 비즈니스 로직을 처리하는 별도의 패키지를 생성하여 외부 요청 처리 패키지와 비즈니스 로직 처리 패키지를 구분합니다(
e.g. domain, infrastructure). stream패키지의 책임 재정의:stream패키지는 외부 메시지를 받아서 내부로 전달하는 역할만 담당하도록 합니다. 기존의 비즈니스 로직은 위에서 정의한 새로운 패키지로 이동시킵니다. 이렇게 함으로써api와 패키지와stream패키지는 동등한 위상으로 존재하게 됩니다. 외부 요청을 담당하는 패키지에는controller, facade, dto만 존재하도록 합니다.- 패키지 내부의 클래스 정리: 2의 작업을 진행하면서
stream내부의 혼재되어 있는 여러 패키지 역시 명확한 역할에 따라 재배치합니다.

4) 예시
AS-IS
orchestration.stream...
TO-BE
orchestration.domain...
2. 비즈니스 도메인에서는 추상화된 행위만 정의하고 세부 로직은 구현 레이어로 밀어넣자
1) 현 데이터 플로우 및 아키텍처
1. Rest 요청시
REST 요청이 들어올 때의 데이터 플로우는 다음과 같습니다. GeneralRequestControllerV1 예시입니다.
- 클라이언트로부터
REST요청이GeneralRequestControllerV1클래스에 도착합니다. GeneralRequestControllerV1는 해당 요청을 처리할RequestFacadeV1의 메서드를 호출합니다.RequestFacadeV1은 실제 비즈니스 로직을 처리하는Service의 메서드를 호출합니다.Service는 데이터를 데이터베이스에서 조회하기 위해DatabaseSessionRepository를 사용합니다.- 조회된 데이터는
ResponseSessionDTO로 변환되어 클라이언트에 응답으로 반환됩니다.

2. channel 메시지 consume시
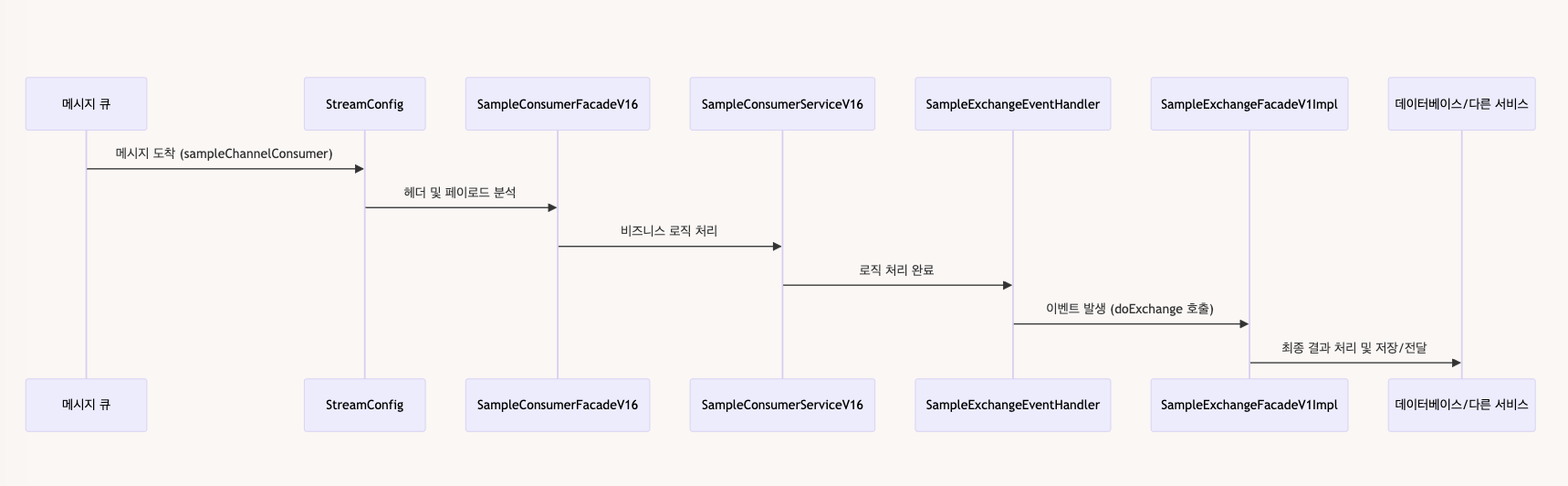
sample 메시지가 소비될 때의 데이터 플로우는 다음과 같습니다. StreamConfig의 sampleChannelConsumer 메서드로부터 시작된 데이터 요청이 핸들러로 이어지는 예시입니다.
- 메시지 큐로부터 메시지가
StreamConfig의sampleChannelConsumer메서드에 도착합니다. - 메시지 헤더와 페이로드를 분석하여, 버전, 메시지 유형, 클라이언트 ID 등을 추출합니다.
- 메시지 유형과 버전에 따라
SampleConsumerFacadeV16의 적절한 메서드가 호출됩니다. SampleConsumerFacadeV16는SampleConsumerServiceV16의 메서드를 호출하여 실제 비즈니스 로직을 처리합니다.- 비즈니스 로직 처리가 완료되면,
SampleExchangeEventHandler가 이벤트를 발생시켜SampleExchangeFacadeV1Impl의doExchange메서드를 호출합니다. doExchange메서드는 추가적인 비즈니스 로직을 처리합니다.- 최종 결과가 데이터베이스에 저장되거나 다른 서비스에 전달됩니다.
3. 핵심 비즈니스 로직으로 데이터가 전달되는 플로우
stream으로부터 파싱된 요청을 내부적으로 publish 하고 이 요청에 대해 listening 하면서부터 데이터 인입이 시작됩니다. 이벤트 리스닝이 일어나는 구체적인 시점은 현 패키지 상의 stream>samplechannel>event>handler의 핸들러에서 담당합니다.
@Slf4j
@Component
public class SampleChannelExchangeEventHandler {
private final SampleChannelExchangeFacade sampleChannelExchangeFacade;
public SampleChannelExchangeEventHandler(SampleChannelExchangeFacade sampleChannelExchangeFacade) {
this.sampleChannelExchangeFacade = sampleChannelExchangeFacade;
}
// Exchange 바인더
@Async("sampleChannelExchangeEventTaskExecutor")
@EventListener
public void asyncSampleChannelExchangeEvent(SampleChannelExchangeEvent sampleChannelExchangeEvent) {
sampleChannelExchangeFacade.doExchange(sampleChannelExchangeEvent.getMessageId());
}
}
따라서 해당 리스너는 Rest API의 컨트롤러와 같은 위상의 역할을 담당하면서 요청된 데이터를 파사드 레벨로 전달합니다. 이때 리스너는 해당 메시지를 위임할 파사드를 의존하면서 파사드의 doExchange 메서드를 실행하도록 요청합니다.
public interface SampleChannelExchangeFacade {
void doExchange(String messageId);
}
파사드는 서비스를 의존하고 있고 받은 메시지를 전처리한 뒤 서비스에 메시지를 전달하면서 본격적인 비즈니스 로직의 수행을 요청합니다.
@Slf4j
@Component
public class SampleChannelExchangeFacadeV1Impl implements SampleChannelExchangeFacadeV1, ProcessorExchangeable<SampleChannelMessage> {
private final SampleChannelExchangeServiceV1 sampleChannelExchangeServiceV1;
private final SampleChannelResponseServiceV1 sampleChannelResponseServiceV1;
//...
@Override
public void doExchange(String messageId) {
//... 1. 예약 검증(자신에게 바인딩된 예약건인지 판단)
final SampleChannelMessage sampleChannelMessage = getMessage(messageId);
//... 2. 전처리
//... 3. 비즈니스 로직
exchange(sampleChannelMessage);
//... 4. 후처리
}
}
즉, 본격적인 비즈니스 로직이 시작되는 시점은 service의 exchange 메서드가 호출되는 시점입니다.
exchange 메서드의 흐름을 살펴보면 다음과 같습니다.
@Override
public boolean exchange(SampleChannelMessage sampleChannelMessage) {
// 처리중 상태로 변경
sampleChannelExchangeServiceV1.setMessageExchangingStatus(sampleChannelMessage);
try {
SampleServiceResponseDTOV1 sampleServiceResponseDTOV1 = bindClientServiceId(sampleChannelMessage);
switch (sampleChannelMessage.getCreator()) {
case SAMPLE_CREATOR1:
// ...
break;
case SAMPLE_CREATOR2:
// ...
}
} catch (Exception e) {
// ...
return false;
}
return true;
}
즉, 현 프로젝트에서 featureHandler는 3tier 아키텍처의 서비스에 대응되는 개념으로 해석할 수 있습니다.
2) 문제: 추상화된 정의와 구현의 혼재
비즈니스 레벨이 시작되는 레이어를 도메인 레이어라고 한다면, 해당 레이어에서는 추상화 레벨을 최대한 높게 설정하여 정의로서만 행위를 규정하면 가독성과 변경 용이성 면에서 이점을 얻을 수 있습니다. 이때 추상화된 표현을 실재화하는 구현체들은 또 infrastructure 레이어를 만들어 해당 레이어에서 구현하도록 합니다.
먼저 AS-IS로서 그렇지 못한 케이스를 살펴보면 다음과 같습니다.
서비스 클래스의 기능을 하는 FeatureHandler의 추상화된 명령 구조를 보면 다음과 같습니다.
public interface FeatureHandler {
// 처리 후 responsePayload 항목을 생성한다.
// ...
// Feature Type 결정
ActionType getActionType();
}
@Slf4j
public abstract class AbstractFeatureHandler<P, R> implements FeatureHandler {
protected final Gson gson;
protected AbstractFeatureHandler(Gson gson) {
this.gson = gson;
}
@Override
public JsonObject process(SampleChannelMessage sampleChannelRequestDTO, SampleServiceResponseDTO sampleServiceResponseDTO) {
// ...
// 특정 트랜잭션과 관련된 메세지일 경우 세팅한다.
sampleRequestPayload.getOptionalTransactionId().ifPresent(sampleChannelRequestDTO::setTransactionId);
return parseResponsePayload(sampleResponsePayload);
}
public SampleRequestPayload parseRequestPayload(JsonObject jsonObject) {
return ...;
}
public abstract SampleResponsePayload process(SampleRequestPayload sampleRequestPayload);
public JsonObject parseResponsePayload(SampleResponsePayload sampleResponsePayload) {
return ...;
}
핸들러의 구현체들은 9개가 존재합니다.
상위에 추상화된 액션은 exchange가 유일하며, 9개의 핸들러들은 모두 이 exchange를 구현합니다.
첫 번째 생각해볼 점은 서비스의 시작 지점에서 추상화된 명령이 너무 적다는 것입니다.
추상화된 명령이 너무 적다
AS-IS 상태에서는 FeatureHandler 인터페이스가 exchange라는 단일 메서드만을 정의하고 있습니다. 이로 인해 상속받은 구현체들은 이 exchange 메서드를 구현해야만 합니다. 그러나 이러한 설계는 다음과 같은 문제점을 가집니다.
- 단일 책임 원칙 위배:
exchange메서드 하나에 너무 많은 책임이 몰리게 됩니다. - 확장성 부족: 새로운 기능이나 비즈니스 로직이 추가될 경우,
exchange메서드 자체를 수정해야 할 가능성이 높습니다. - 가독성과 유지보수성 저하: 하나의 메서드에서 여러 가지 일을 처리하게 되면서 가독성이 저해되고 유지보수성이 떨어집니다.
AS-IS 상태에서의 구현체 복합도
구현체 하나인 StartSampleHandler 를 살펴보면 다음과 같습니다.
@Service
@Slf4j
public class SampleHandler extends AbstractHandler<SampleRequestPayload, SampleResponsePayload> {
@Override
public SampleResponsePayload process(SampleRequestPayload requestPayload) {
ServiceResponseDTO serviceResponseDTO = requestPayload.getServiceResponseDTO();
String serviceId = serviceResponseDTO.getServiceId();
String domainZoneId = serviceResponseDTO.getDomainZoneId();
String tagId = requestPayload.getTagId();
switch (tagId.length()) {
case Constant.USER_A_LENGTH:
return processForUserA(requestPayload, serviceResponseDTO, serviceId, domainZoneId, tagId);
case Constant.USER_B_LENGTH:
return processForUserB(requestPayload, serviceResponseDTO, serviceId, domainZoneId, tagId);
default:
throw new HandlerException(ResponseCode.INVALID_TARGET);
}
}
private SampleResponsePayload processForUserA(SampleRequestPayload requestPayload, ServiceResponseDTO serviceResponseDTO, String serviceId, String domainZoneId, String tagId) {
// 로직 구현
}
private SampleResponsePayload processForUserB(SampleRequestPayload requestPayload, ServiceResponseDTO serviceResponseDTO, String serviceId, String domainZoneId, String tagId) {
// 로직 구현
}
// 추가 메서드 및 로직 구현...
}
구현체인 SampleHandler를 살펴보면, process 메서드 안에서 다양한 로직을 처리하고 있습니다. 이로 인해 다음과 같은 문제점이 발생합니다.
- 메서드 내의 분기 처리 증가: 하나의 메서드에서 다양한 경우를 다루고 있기 때문에 분기문이 많아집니다.
→ 1차 분기:SystemA와SystemB
→ 2차 분기: 예비 처리, 병합 처리
→ 3차 분기:ModuleX,ModuleY - 재사용성 저하: 메서드가 특정 경우에 지나치게 최적화되어 있어, 다른 곳에서 재사용하기 어려움.
- 테스트 어려움: 하나의 메서드에서 여러 경우를 처리하므로, 테스트 케이스 작성이 복잡해짐.
- SRP(단일 책임 원칙) 위배: 하나의 메서드나 클래스가 다양한 책임을 가지게 되어, 단일 책임 원칙이 위배됨.
너무 많은 메서드 호출과 반환값
하나의 exchange 메서드가 여러 서비스를 호출하고 다양한 타입의 값을 반환하고 있습니다.
private GenericResponse processSample(GenericServiceResponseDTO genericServiceResponseDTO, GenericRequestPayload requestPayload, String identifier
, UserPaymentResponseDTO userPaymentResponseDTO, ConnectorResponseDTO connectorResponseDTO
, String transactionId, PaymentModel paymentModel
, DomainFeatureCodeVo domainFeatureCodeVo, ResponseEntity<TxCalculationResponseDTO> calculationStartResponse
, TxCalculationResponseDTO txCalculationResponseDTO, Long transactionId) {
...
}
이로 인해 다음과 같은 문제가 발생할 수 있습니다.
- 가독성 저하: 읽고 해석하는 데 너무 오랜 시간이 걸립니다.
- 디버깅 어려움: 하나의 메서드에서 문제가 발생했을 때, 어디서 문제가 발생했는지 추적하기 어렵습니다.
- 결합도 증가: 하나의 메서드가 여러 서비스와 강하게 결합되어 있어, 하나의 변경이 여러 곳에 영향을 미칩니다.
3) 제안
facade-service 레벨에서의 명령 세분화
- 명령 세분화:
FeatureHandler인터페이스를 더 세분화하여, 예를 들어preProcess,process,postProcess와 같이 여러 단계로 나눕니다. public interface FeatureHandler { boolean preProcess(SampleChannelMessage message); JsonObject process(SampleChannelMessage message, SampleServiceResponseDTOV1 responseDTO); boolean postProcess(SampleChannelMessage message); ActionType getActionType(); }- 인터페이스 분리 원칙 적용: 특정 핸들러가 다루지 않는 기능은 별도의 인터페이스로 분리합니다.
public interface TransactionalFeatureHandler extends FeatureHandler { void startTransaction(); void endTransaction(); }
도메인 레벨에서는 추상화 레벨을 최대한 높이고 누구나 읽어도 이해할 수 있는 플로우를 작성하자
Domain layer: 비즈니스 로직의 개념, 행위, 규칙을 규정하고 수행하되, 최대한 추상화된 표현으로 주요 로직을 정의합니다. 세부 구현은 전부 인프라 계층에 위임합니다.Infrastructure layer: 상위 계층을 지원하는 기술적 구현을 담당합니다. 예를 들어,Repository와 같은 영속화 외에 도메인 레이어에서 규정한 기능들에 대한 low-level 수준의 구현을 담당합니다.
도메인 레벨의 추상화된 내용은 다음과 같습니다. SampleAction을 예시로 듭니다.
@Service
@Slf4j
@RequiredArgsConstructor
public class SampleActionHandler extends AbstractFeatureHandler<SampleActionRequest, SampleActionResponse> {
private final SampleClientResolver sampleClientResolver;
@Override
public ResponsePayload exchange(RequestPayload requestPayload) {
return sampleClientResolver
.findBy(requestPayload.getIdentifier().length())
.performAction(requestPayload);
}
@Override
public ActionType getActionType() {
return ActionType.SampleAction;
}
}
SampleActionHandler는 도메인 레이어에서 정의된 행위를 수행하며, 실제 로직 구현은 SampleClientResolver와 같은 인프라 레이어의 컴포넌트에게 위임합니다. 로직의 추상화와 구현을 분리합니다.
@Service
@RequiredArgsConstructor
public class SampleClientResolver {
private final List<SampleClient> clients;
public SampleClient findBy(int identifierLength) {
return clients.stream()
.filter(client -> client.support(identifierLength))
.findFirst()
.orElseThrow(() -> new ClientException(INVALID_SERVICE_TARGET));
}
}
if 문으로 분기하는 대신 객체에게 위임하여, identifierLength 기반으로 매핑되는 SampleClient를 찾습니다.
이와 같은 Resolving 방식은 스프링의 ArgumentResolver와 유사합니다. 예를 들어 Controller에서 인증이 필요한 경우와 같은 구현을 참조할 수 있습니다.
@PostMapping("/tasks")
public ResponseEntity<Void> createTask(@RequestBody TaskCreateReq taskCreateReq,HttpSession session) {
final Long userId = (Long) session.getAttribute(LOGIN_SESSION_KEY);
if (userId == null) {
throw new RuntimeException("bad request. no session.");
}
taskService.create(taskCreateReq, AuthUser.of(userId));
return ResponseEntity.ok().build();
}
그러나 스프링의 ArgumentResolver의 구현체 중 하나인 AuthUserArgumentResolver 의해 해당 코드는 다음과 같이 축약됩니다.
@PostMapping("/tasks")
public ResponseEntity<Void> createTask(@RequestBody TaskCreateReq taskCreateReq,HttpSession session, AuthUser authUser) {
taskService.create(taskCreateReq, authUser);
return ResponseEntity.ok().build();
}
어딘가에서 인증 기능이 미리 수행되고 AuthUser를 인자로 넘겨받기만 하면 됩니다. 이렇게 책임이 분리됨으로써 특정 로직을 수행하는 메서드가 본인에게 할당된 역할 이외의 다른 기능에 대해서는 신경쓰지 않아도 되게 됩니다. 같은 관점을 적용하여 Resolving 로직을 분리하였습니다.
그 외 도메인 레벨에서 정의할 수 있는 다양한 책임 객체들은 다음과 같습니다.
public interface GeneralClient {
boolean support(int parameter);
String retrieveUniqueId(ServiceResponseDTO serviceResponseDTO, String identifier);
GeneralResponsePayload initiateProcess(GeneralRequestPayload requestPayload);
GeneralResponsePayload terminateProcess(GeneralRequestPayload requestPayload);
}
public interface ContextFactory {
String retrieveUniqueId(ServiceResponseDTO serviceResponse, String identifier);
ProcessDetails createProcess(GeneralRequestPayload requestPayload, Details details);
Context retrieveContext(GeneralRequestPayload requestPayload);
void saveStartResult(Context context, PaymentContext paymentContext, ResultInfo resultInfo);
void saveStopResult(Context context, ResultInfo resultInfo);
ProcessDetails retrieveProcess(String id, ResponseCode code);
boolean isInProcess(String id);
void updateTerminateProcess(ProcessDetails details, RequestTerminateProcess request);
}
public interface PaymentContextFactory {
PaymentContext retrievePaymentContext(Context context);
ResultInfo processPayment(Context context, PaymentContext paymentContext);
ResultInfo completePayment(Context context);
}
public interface Operator {
ResponseDTO startProcess1(Context context, PaymentContext paymentContext, ResultInfo resultInfo);
ResponseDTO startProcess2(RequestStartProcess transaction);
void stopProcess2(ProcessDetails details, RequestTerminateProcess request);
void stopProcess1(Context context, ResultInfo resultInfo);
}
public interface Provider {
ProcessDetails createProcess1(GeneralRequestPayload requestPayload, Details details);
ProcessDetails createProcess2(GeneralRequestPayload requestPayload, Details details);
}
public interface Strategy {
boolean support(Model model);
FeatureCodeVo fetchProfile(Context context);
ResultInfo processPayment(Context context, PaymentContext paymentContext);
ResultInfo completePayment(Context context, CalculationResponseDTO response);
}
public interface Resolver {
Model fetchModel(GeneralRequestPayload requestPayload, ProcessDetails details);
}
이렇게 변경하면 개인 블로그에 공개하기 적합한 수준으로 코드의 세부 사항이 일반화되며, 중요한 로직은 그대로 유지됩니다.
이 인터페이스들은 서비스 레이어에서 수행해야 할 다양한 역할을 나누어 처리합니다. 각각의 인터페이스는 맡겨진 역할만 수행하도록 책임을 명확히 나눕니다.
그 결과, 다음과 같이 주요 비즈니스 흐름을 단순하면서도 명확하게 표현할 수 있습니다.
AS-IS
한 메서드에 약 100줄의 코드
TO-BE
메서드 별 길이가 최대 10줄을 넘지 않음
domain-infrastructure 레벨에서의 구현 레이어 분리
앞서 정의한 내용에 따라 도메인 레벨에서는 추상화된 액션을 단순히 정의만 하므로 모든 객체들이 인터페이스로 존재합니다.
이에 대한 구현체들은 infra 레벨에서 작성합니다.
예를 들어 한 분기를 처리하는 Strategy로서 SampleStrategy는 다음과 같이 구현됩니다.
@Component
@RequiredArgsConstructor
public class SampleStrategy implements DomainStrategy {
private final List<Processor> processors;
private final Operator operator;
private final PublishService publishService;
@Override
public boolean support(DomainModel model) {
return model.equals(특정 조건);
}
@Override
public DomainFeatureCodeVo fetchProfile(Context context) {
return retrieveProcessor(context)
.fetchResponse(context.getRequestPayload())
.andValidate(ILLEGAL_DOMAIN_PROFILE)
.andLog("[Log Message] [특정 상황] 메시지 --> {} ")
.toResponse()
.getBody();
}
private Processor retrieveProcessor(Context context) {
return processors.stream()
.filter(p -> p.support(context.fetchType()))
.findFirst().orElseThrow(() -> new IllegalArgumentException("Unknown Type"));
}
@Override
public ResultInfo process(DomainContext context, Context secondaryContext) {
ResponseVo orderResponse = operator.createOrder(context, secondaryContext);
ResponseVo processResponse = operator.processOrder(orderResponse, context, secondaryContext);
return new ResultInfo(orderResponse, processResponse, secondaryContext.getCalculationResponse());
}
@Override
public ResultInfo endProcess(Context context, CalculationResponseDTO calculationResponse) {
BigDecimal partialCancelAmount = calculationResponse.getPartialCancelAmount();
if (isExceedsCondition(partialCancelAmount)) {
publishService.publishEvent(calculationResponse.createEvent(context));
} else {
return ResultInfo.builder()
.responseVo(operator.cancelPartialAmount(context.getDetails().getId(), partialCancelAmount.intValue()))
.calculationResponse(calculationResponse)
.build();
}
return ResultInfo.builder().build();
}
private boolean isExceedsCondition(BigDecimal amount) {
return amount.compareTo(BigDecimal.ZERO) < 0;
}
}
SampleStrategy 클래스는 특정 도메인에 대한 전략을 구현합니다. DomainStrategy 인터페이스를 구현하여 다형성을 보장하고, 복잡한 로직을 처리합니다.
Processor, Operator, PublishService 등과 협력하여 로직을 수행하며, 각 메서드는 명확한 책임을 가집니다. 이 클래스는 특정 도메인에 특화된 로직을 캡슐화하고, 추상화 수준을 높여 인프라 레이어와의 결합을 최소화합니다.
4) 얻는 것과 잃는 것
얻는 것
- 읽기 쉬운 코드: 메서드명과 클래스명만 보아도 해당 객체나 메서드의 역할과 책임을 쉽게 파악할 수 있습니다. 코드의 가독성을 높여 협력이 필요한 경우 빠르고 효율적으로 진행할 수 있을 것입니다.
- 단위 테스트 용이: 각각의 기능이 분화되고 캡슐화되어 있기 때문에 단위 테스트를 작성하기가 더 쉽습니다. (가장 중요한 부분이라고 생각합니다.)
- 유지보수성 증대: 메서드나 클래스가 하나의 명확한 책임만을 가지고 있으므로, 유지보수가 필요할 때 해당 부분만을 수정하면 됩니다. 단위테스트가 잘 작성되어 있다면 수정 발생시 큰 안정감을 줄 것입니다.
- 확장성 증대:
- 도메인 레벨에서 추상화를 극대화시키면 변경에는 닫혀 있고 확장에는 자유로운
OCP원칙을 적용할 수 있습니다. 변경이 필요한 시점에 하부 구현체들만 교체하는 방식으로 변경하면, 변경의 영향이infrastructure레이어에만 한정됩니다. 핵심은 내부 구현체들을 변경해도 도메인 레벨에서는 코드 수정이 필요 없다는 것입니다. 다음과 같은 비즈니스 요구사항 변화에도 유연하게 대응할 수 있습니다. - 새로운 클라이언트 추가: 현재는
ClientA,ClientB를 다루지만, 새로운 클라이언트를 추가할 때 기존 코드를 수정하지 않고, 해당 클라이언트를 처리하는 새로운 컴포넌트만 추가하면 됩니다. - 다양한 처리 방식: 기존의 방식 외에도 다양한 처리 방식을 쉽게 추가할 수 있습니다. 새로운 전략을 구현한 클래스를 추가하기만 하면 됩니다.
- 다양한 플랫폼 지원: 현재는
PlatformA,PlatformB만 지원하지만, 다른 플랫폼을 도입할 경우, 해당 플랫폼을 처리하는 새로운Processor를 추가하면 됩니다.
- 도메인 레벨에서 추상화를 극대화시키면 변경에는 닫혀 있고 확장에는 자유로운
잃는 것
- 초기 개발 복잡성: 상위 수준의 추상화와 세분화된 인터페이스로 인해 초기 개발 과정에서는 복잡성이 증가할 수 있습니다.
- 런타임 성능: 각 요청이 여러 객체와 메서드를 거쳐 처리되기 때문에, 메서드 호출과 객체 생성이 늘어나며 이로 인해 성능 저하가 발생할 수 있습니다.
3. 주요 비즈니스 로직과 부가 로직을 분리하자... 최대한 !
1) AS-IS
메인 로직의 흐름에 부가 기능인 Dto 변환 로직, 검증 로직, 로그 기록 기능이 섞여 있습니다.
private SampleResponsePayload exchangeForSpecificUser(SampleRequestPayload sampleRequestPayload, SampleServiceResponseDTO sampleServiceResponseDTO, String userId) {
ResponseEntity response = sampleEnvironmentClient.getAvailableResource(userId);
if (!HttpStatus.OK.equals(response.getStatusCode())) {
SampleAuthorizeRequestDTO sampleAuthorizeFailDTO = getSampleAuthorizeFailDTO(sampleRequestPayload, sampleServiceResponseDTO, userId);
ResponseEntity<SampleAuthorizeResponseDTO> createResponse = sampleClient.authorize(sampleAuthorizeFailDTO);
log.info("[Authorize] 특정 도메인 인증 실패 저장 --> {}", createResponse.getBody());
return rejectAuthorize();
}
final SampleAuthorizeRequestDTO sampleAuthorizeDTO = getSampleAuthorizeDTO(sampleRequestPayload, sampleServiceResponseDTO, userId);
log.info("[Authorize] [1] 특정 도메인 인증 성공 저장 요청 --> {}", sampleAuthorizeDTO);
final ResponseEntity<SampleAuthorizeResponseDTO> createResponse = sampleClient.authorize(sampleAuthorizeDTO);
AssertUtil.isTrue(HttpStatus.CREATED.equals(createResponse.getStatusCode()), ResponseCode.EXCHANGE_FALLBACK);
log.info("[Authorize] [2] 특정 도메인 인증 성공 저장 응답 --> {}", createResponse.getBody());
final SampleAuthorizeResponseDTO sampleAuthorizeResponseDTO = createResponse.getBody();
String transactionId = sampleAuthorizeResponseDTO.getAuthorizeId();
sampleRequestPayload.setOptionalTransactionId(Optional.ofNullable(transactionId));
log.info("[Authorize] [3] 특정 도메인 인증 아이디 캐시 발행");
applicationEventPublisher.publishEvent(SampleCacheEvent.builder()
.service(SERVICE_NAME)
.entity(ENTITY_SAMPLE)
.transactionId(transactionId)
.serviceId(sampleServiceResponseDTO.getServiceId())
.userId(userId)
.timeToLiveMilliSeconds(AUTH_TIMEOUT_MILLISECOND)
.build());
return acceptAuthorize(ParentType.SAMPLE, userId);
}
2) 제안
1. Dto 변환 로직 개선
- 정적 팩토리 메서드와
MapStruct를 사용 Dto와 도메인 객체 간의 변환 로직을 분리하여 가독성과 유지보수성을 높일 수 있습니다.- 기존의
Dto변환 로직을MapStruct와 정적 팩토리 메서드를 사용해 분리합니다.메인 로직에서는 변환 로직을 명시적으로 기술할 필요가 없어져 코드가 간결해집니다.
AS-IS
public class UserConverter {
public UserDto toDto(User user) {
return UserDto.builder()
.userId(user.getId())
.userName(user.getName())
.userEmail(user.getEmail())
.build();
}
public User toEntity(UserDto userDto) {
return User.builder()
.id(userDto.getUserId())
.name(userDto.getUserName())
.email(userDto.getUserEmail())
.build();
}
}
T0-BE
// MapStruct를 사용한 Dto 변환 예시
@Mapper(componentModel = "spring")
public interface UserMapper {
UserDto toDto(User user);
User toEntity(UserDto userDto);
}
2.검증 로직 개선
Optional을 사용하여 인증 로직을 매끄럽고 단순하게 구현할 수 있습니다(관련글 검증 방식에 대한 고찰 ).- 특정 기능에 대한 담당 객체나 메서드가 인증도 함께 담당하도록 위임합니다.
feign요청에 대한 인증 책임을 feign 요청을 처리하는Wrapper클래스를 만들어 위임하는 예시입니다.
AS-IS
클라이언트로부터 받아온 ResponseEntity를 그대로 다른 레이어로 이동시켜서 필요 시점에 검증을 하는 코드
TO-BE
@Slf4j
@Component
@RequiredArgsConstructor
public class SampleProfileClientAdapter {
private final SampleProfileClientV1 sampleProfileClientV1;
public FeignResponse<PageVo<SampleDomainFeatureCodeVoV1>> searchSampleDomainFeatureCode(
SampleDomainFeatureCodeSearchParamVoV1 searchParamVoV1, PageableVo pageableVo) {
return new FeignResponse<>(sampleProfileClientV1.search(searchParamVoV1, pageableVo));
}
public FeignResponse<SampleDomainFeatureCodeVoV1> getSampleDomainFeatureCode(String id) {
return new FeignResponse<>(sampleProfileClientV1.getSampleDomainFeatureCode(id));
}
public FeignResponse<GlobalCodeVoV1> getGlobalCode(String id) {
return new FeignResponse<>(sampleProfileClientV1.getGlobalCode(id));
}
public FeignResponse<SampleServiceFeatureCodeVoV1> getSampleServiceFeatureCode(String id) {
return new FeignResponse<>(sampleProfileClientV1.getSampleServiceFeatureCode(id));
}
}
FeignResponse는 다음과 같이 Feign응답을 감싸는 래퍼 클래스입니다. 검증 기능이나 로그 기능이 필요한 경우 직접 호출하여 구현할 수도 있고, 래퍼 클래스나 어댑터 클래스에 구현할 수도 있습니다. 어느 경우든 검증과 로깅의 책임을 하위 레벨에서 작동하도록 하여 메인 로직 플로우에서 벗어나지 않도록 합니다.
3. 로그 로직 개선
- 중간 과정에서 로깅이 필요하다면
AOP기반의 로그 추적기를 도입해보는 것은 어떨까요? - 아래 내용은 개인 프로젝트에서 사용했었던 로그 추적 기능의 예시 코드입니다.
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface LogTrace {
}
@Slf4j
@Aspect
@Component
@RequiredArgsConstructor
public class GlobalTraceHandler {
private final LogTrace logTrace;
@Around("ko.co...specificNamingClasses()")
public Object execute(ProceedingJoinPoint joinPoint) throws Throwable {
TraceStatus status = null;
Object result = null;
try {
String message = joinPoint.getSignature().toShortString();
status = logTrace.begin(message);
result = joinPoint.proceed();
logTrace.end(result, status);
return result;
} catch (Exception exception) {
logTrace.exception(result, status, exception);
throw exception;
}
}
//...
@Pointcut("execution(* ko.co...*Controller.*(..)) || execution(* ko.co...*Service.*(..)) || execution(* ko.co...*Facade.*(..)) || execution(* ko.co...*Validator.*(..))")
public void specificNamingClasses(){}
}
public interface LogTrace {
TraceStatus begin(String message);
void end(Object result, TraceStatus status);
void exception(Object result, TraceStatus status, Exception e);
}4. 데이터 전송시 의미 있는 네이밍의 VO를 활용하자
1) AS-IS
현재는 데이터를 전송할 때 파라미터가 너무 많이 사용되고 있습니다.
private SampleTransactionRequestDTO.RequestInitTransaction getSampleTransaction(SampleServiceResponseDTO serviceResponseDTO, InitTransactionPayload payload, String memberId, DeviceResponseDTO deviceResponseDTO, String transactionId, Long systemTransactionId) {
return SampleTransactionRequestDTO.RequestInitTransaction.builder()
.transactionId(transactionId)
.transactionStatus(SampleTxStatus.Processing)
.systemTransactionId(systemTransactionId)
.deviceId(deviceResponseDTO.getDeviceId())
.memberNumber(memberId)
.transactionStartTime(payload.getTimestamp())
.initialReading(new BigDecimal(String.valueOf(payload.getInitialReading())).setScale(5, RoundingMode.FLOOR))
.startRequestTime(payload.getRequestTime())
.startResponseTime(LocalDateTime.now())
.transactionInitResult(SystemConstant.TRANSACTION_INIT_SUCCESS)
.build();
}
다음과 같은 문제점들이 발생할 수 있습니다.
- 가독성 저하: 많은 수의 파라미터가 메서드에 전달되면, 코드의 가독성이 떨어집니다. 이로 인해 코드를 이해하거나 디버깅하는 데 시간이 더 걸립니다.
- 유지보수 어려움: 파라미터가 많을수록, 그 중 하나가 변경되었을 때 해당 메서드를 호출하는 모든 부분을 수정해야 합니다.
- 타입 안정성 부족: 파라미터의 순서나 타입을 잘못 전달하는 실수가 쉽게 발생할 수 있습니다.
- 의미 전달 부족: 변수 이름만으로는 전달되는 데이터의 의미를 완전히 파악하기 어렵습니다. 따라서 코드를 처음 보는 사람은 문맥을 이해하기 위해 추가적인 문서나 설명이 필요할 수 있습니다.
2) 제안
이러한 문제를 해결하기 위해 dto, vo를 사용할 때 유의미한 네이밍으로 고안된 새로운 vo 객체를 만들어 사용하면 어떨까요? 아래는 AtransactionId와 BTransactionId가 사용되어야 하는 상황에서 이를 감싸는 객체로서 TransactionDetails라는 vo를 사용할 수 있을 것입니다.
5. 기타 제안들
1) Dto, Vo의 사용 범위를 정하고 계층에 따라 유의미한 네이밍의 용도를 정하기
Dto와 Vo의 사용 범위를 정하고 (제한하고) 데이터 흐름을 쉽게 파악할 수 있도록 계층 사용별로 유의미한 네이밍과 사용 범례를 정하면 어떨까요?
예를 들어 3티어 아키텍처를 확장하여 다음과 같은 레이어 구조를 사용한다면, 이때 각 계층별로 사용되는 Vo의 네이밍과 범위를 지정하는 것입니다.

외부와의 연결이 가능한 Presentation 레이어의 interfaces, application 층에서는 dto라는 네이밍의 vo를 사용합니다. 그러나 dto는 domain 레이어로 침투하지 못합니다. domain 레이어로 들어올 때 vo는 command 객체로 변환하여 들어옵니다. command는 엔티티로 변환되어 영속화 레벨로 침투할 수 있습니다. 이후 엔티티가 도메인 레이어를 벗어날 때는 info 객체로 변환되어 나갑니다.
이렇게 dto, command, entity, info 객체를 분리하되 일관된 네이밍을 지정하면 가독성 측면에서는 물론이고 데이터와 타입 안정성에 있어서도 이점이 있을 것입니다. 프로젝트나 서비스 특성에 따라 적절한 vo 네이밍을 정할 수도 있을 것입니다. 어찌됐든 하나의 프로젝트에서 vo 객체를 다룰 때는 일관된 컨벤션으로 기준점을 잡아두는 것이 유의미하다고 생각합니다.
2) 숫자를 다루고 계산이 필요한 경우라면 BigDecimal이 아닌 직접 구현한 객체를 사용하기
직접 숫자 객체를 구현할 때의 장점은 필요한 연산들을 커스터마이징하게 도메인 지향적으로 사용할 수 있다는 점입니다. 다음은 한 프로젝트에서 구현해 본 숫자 클래스의 예시 코드입니다.
public abstract class Numeral extends Number implements Comparable<Numeral> {
protected double value;
public Numeral(double value) {
this.value = value;
}
public double value() {
return value;
}
public Numeral plus(double augend) {
return new Numeral(this.value + augend) {};
}
public Numeral plus(Numeral augend) {
return new Numeral(this.value + augend.value()) {};
}
public Numeral minus(double subtrahend) {
return new Numeral(this.value - subtrahend) {};
}
public Numeral minus(Numeral subtrahend) {
return new Numeral(this.value - subtrahend.value()) {};
}
// ...
public boolean isGreaterThan(Numeral other) {
return this.value > other.value;
}
// ...
public Amount toAmount() {
return Amount.of(this.value);
}
public Price toPrice() {
return Price.of(this.value);
}
@Override
public int compareTo(Numeral o) {
return Double.compare(this.value, o.value);
}
public boolean isZero() {
return this.value==0;
}
public boolean isNotZero() {
return !isZero();
}
/**
* 주어진 값과 정밀도를 이용하여 Numeral 값을 반올림합니다.
*
* <p>작동 원리: <br>
* 1. 정밀도를 이용하여 스케일 팩터(scale factor)를 구합니다. <br>
* 2. 값에 스케일 팩터를 곱합니다. <br>
* 3. 결과값을 반올림합니다. <br>
* 4. 반올림한 값에 다시 스케일 팩터로 나눕니다.
* </p>
*
* <p>BigDecimal을 사용한 이유: <br>
* 부동소수점의 정밀도 문제를 해결하기 위해 BigDecimal을 사용합니다.<br>
* <p>precision 예시: <br>
* 1->25675.3
* 2 -> 1626.59
* 3 -> 0.433
* 4 -> 0.4993
* 5 -> 0.05929
* 6 -> 0.06341 -> adjust -> 5와 동일
* 7 -> 0.10837 -> adjust -> 5와 동일
* </p>
*
* @param value 반올림할 값
* @param precision 적용할 정밀도
* @return 반올림된 값
*/
public Numeral computePrecision(double value, Index precision) {
BigDecimal valueBD = BigDecimal.valueOf(value);
BigDecimal scale = BigDecimal.valueOf(Math.pow(10, precision.value()));
BigDecimal scaledValue = valueBD.multiply(scale);
BigDecimal roundedValue = scaledValue.setScale(0, BigDecimal.ROUND_HALF_UP);
return new Numeral(roundedValue.divide(scale).doubleValue()) {};
}
/**
* 주어진 값과 tickSize를 이용하여 Numeral 값을 조정합니다.
*
* <p>작동 원리: <br>
* 1. tickSize로 value를 나눕니다. <br>
* 2. 그 결과를 반올림합니다. <br>
* 3. 반올림한 값을 다시 tickSize로 곱합니다.
* </p>
*
* <p>BigDecimal을 사용한 이유: <br>
* 부동소수점의 정밀도 문제를 해결하기 위해 BigDecimal을 사용합니다. 예를 들어, tickSize가 1.0E-5,
* rawValue가 0.10802562, deviationFactor가 1.002, pricePrecision이 7.00인 경우,
* Price.of(rawValue).toAdjustWithPrecision(pricePrecision).toAdjustWithTickSize(tickSize)
* 를 사용하면 부동소수점 문제로 인해 0.10803000000000001과 같은 값이 나올 수 있습니다.
* 실제로 정확한 값은 0.10803이어야 합니다.
* </p>
*
* @param value 조정할 값
* @param tickSize 적용할 tickSize
* @return 조정된 Numeral 객체
*/
public Numeral computeTickSize(double value, Index tickSize) {
BigDecimal valueBD = BigDecimal.valueOf(value);
BigDecimal tickBD = BigDecimal.valueOf(tickSize.value());
BigDecimal scaledValue = valueBD.divide(tickBD, RoundingMode.HALF_UP);
BigDecimal roundedValue = scaledValue.setScale(0, RoundingMode.HALF_UP);
return new Numeral(roundedValue.multiply(tickBD).doubleValue()) {};
}
}
이 객체를 구현한 다양한 숫자 객체들은 다음과 같습니다.
@Getter
public class Amount extends Numeral {
private Amount(double value) {
super(value);
}
public static Amount of(double value) {
return new Amount(value);
}
public static Amount of(Numeral value) {
return Amount.of(value.value());
}
public static Amount of(String value) {
return Amount.of(Double.parseDouble(value));
}
public Amount toAdjustMinimumThreshold(double value) {
if (this.value() < value) {
this.value = value;
}
return this;
}
public Amount toAdjustMinimumThreshold(Amount value) {
return toAdjustMinimumThreshold(value.value());
}
public Amount toAdjustWithPrecision(Index precision) {
return computePrecision(this.value,precision).toAmount();
}
public static class AmountBuilder {
private double value;
public Amount.AmountBuilder value(double value) {
this.value = value;
return this;
}
public Amount build() {
return new Amount(value);
}
}
public static Amount.AmountBuilder builder() {
return new Amount.AmountBuilder();
}
}public class Price extends Numeral {
private Price(double value) {
super(value);
}
public static Price of(double value) {
return new Price(value);
}
public static Price of(Numeral value) {
return Price.of(value.value());
}
public static Price of(String currentPrice) {
return Price.of(Double.parseDouble(currentPrice));
}
public Price toAdjustWithPrecision(Index precision) {
return computePrecision(this.value,precision).toPrice();
}
/**
* tickSize:
* 0.0000010 -> 0.003934
* 0.0001000 -> 1.1465
* 0.0000100 -> 0.09684
* @param tickSize
* @return
*/
public Price toAdjustWithTickSize(Index tickSize) {
return computeTickSize(this.value, tickSize).toPrice();
}
public static class PriceBuilder {
private double value;
public Price.PriceBuilder value(double value) {
this.value = value;
return this;
}
public Price build() {
return new Price(value);
}
}
public static Price.PriceBuilder builder() {
return new Price.PriceBuilder();
}
}
이와 같이 숫자 커스텀 객체들을 사용하면 커스텀 연산이 필요한 경우 일관성을 보장 받으면서 계산을 할 수 있다는 장점이 있습니다. 아래와 같이 사용할 수 있습니다.
@Override
public SampleResult calculateSampleValue(Sample sample, SampleFactor sampleFactor, SamplePrecision samplePrecision, SampleUnit sampleUnit) {
GeneralNumber calculationFactor = one().plus(sampleFactor.dividedBy(aStandardValue()));
GeneralNumber calculatedValue = sample.multipliedBy(calculationFactor);
return SampleResult.of(calculatedValue).adjustWithPrecision(samplePrecision).adjustWithUnit(sampleUnit);
}
단, 단점은 Bigdecimal이 보장하는 기능들에 대하서 직접 구현을 해야 한다는 점입니다. 예를 들어 double 연산의 부동 소수점 오차 발생과 같은 문제를 직접 해결해야 합니다.
그러한 트레이드 오프가 적절한 수준이라면 숫자 객체를 직접 구현하는 것도 괜찮다고 생각합니다.
4. 리팩토링 전략
1. 범위
- 서비스:
sample-processor - 패키지:
GeneralDomain,GeneralInfrastructure패키지 생성 및Flow내부 패키지의 이동 - 클래스:
GeneralProcessor<T>하위의process메서드로부터 호출되는handlers - 대상:
handlers내부 로직 및 연관된 부수 로직
2. 목표
- 현재 작성된
handlers의 코드를 리팩토링하여 모든 세부 기능별 단위테스트가 가능하도록 함 - 향후 유지보수성과 확장성을 고려하여 각 클래스, 메서드별 명확한 책임과 역할을 부여함
- 코드의 이해도를 높이고 범용성을 위한 섬세한 문서화
3. 방법
- 각각의 핸들러에 대한 리팩토링 후 테스트 코드 작성
- e.g.
ActionHandlerV2->ActionHandlerV2Test - 필요시 순서는 변경 가능
- e.g.
- 코드
git branch commit commit코드에 대한 전체 팀원 대상 리뷰 요청(필요시 미팅, 기본 온라인)- 지정 리뷰 기한 이내 특이사항이 없을시
PR - 위의 절차를 반복
4. 테스트 코드 작성 전략
코드 작성 및 변경시 관련된 내용의 메서드 단위별 테스트와 전체 플로우 테스트를 진행함
- 단위 테스트
Mockito Extension을 활용한Mock기반 테스트Fixture를 활용해 실제 데이터를 주입하고 해당 데이터에 대한 처리와 결과값을 검증함- 실제 데이터 획득: 로그를 통한 역추적
- 통합 테스트
Springboot통합 테스트db의 경우dev환경의 실제host를 이용할 수도 있고,TestContainer를 이용한docker기반의mock db를 이용할 수도 있음
5. 적용 전략
- 팀원과의 논의 후 작성 예정
6. 변경 후 기대사항
- 아키텍처
- 외부 노출 레이어와 핵심 비즈니스 레이어의 분리
- 데이터 전송 오브젝트의 구분된 사용
- 추상화된 비즈니스 로직과 실제 구현의 분리
- 기대 효과:
- 유지보수성 향상: 각 레이어와 객체가 명확한 책임과 역할을 가지게 되므로, 유지보수가 쉬워질 것입니다. 새로운 기능을 추가하거나 기존 기능을 변경할 때, 그 범위가 명확해져서 작업 속도가 빨라질 것입니다.
- 확장성 증가: 아키텍처 및 비즈니스 로직이 명확하게 분리되어 있으면 시스템을 확장하기 쉽습니다. 예를
SampleClientA과SampleClientB같은 다른 클라이언트를 추가해야 하는 경우가 생긴다면 기존 코드를 변경할 일이 없이 단순히 추가만 하면 됩니다. 인프라 레이어에서PaymentMethodA,PaymentMethodB외에 새로운 결제 방식 도입시 마찬가지로 새로운 클래스를 추가만 하면 됩니다. - 재상용성 증가: 단위별 클래스와 메서드는 프로젝트 내의 코드에서도 재사용성을 증가시켜 코드의 신뢰도를 높여줍니다.
architecture

layer relation

7. 예시

'이슈와해결' 카테고리의 다른 글
| JWT 토큰 길이가 과도하게 길어질 때 - 토큰 생성 로직 및 인증 프로세스 최적화 탐구 (1) | 2023.12.18 |
|---|---|
| JWT 토큰 기반의 상태 관리시 로그아웃 처리 문제와 간단한 해결 방법 (1) | 2023.12.18 |
| 엔티티 필드 매핑 전략 탐구: 성능 테스터 Gatling을 이용한 Json 필드 매핑 사례 분석 (0) | 2023.12.16 |
| MSA 도메인 서비스에서 id 채번 방식 - 멱등성 보장하기 (1) | 2023.12.15 |
| 입사 0년차 주니어의 첫 운영 배포와 실수 경험 (0) | 2023.12.14 |



