개요
사내에서 차세대 프로젝트에 참여하여 JWT 토큰 기반 인증 인가 개발을 할 기회가 있었다. 설계 단계에서 살펴 보니 필요한 정보를 JWT에 모두 담을 경우 토큰의 길이가 과도하게 길어질 수 있는 문제가 있었다. 사용자별로 다수의 데이터를 소유하고 있는 경우, 이러한 데이터를 토큰에 포함할 때 토큰 길이가 과도하게 길어져 토큰 크기가 일반적인 범위를 초과할 가능성이었다. 토큰의 장점인 무상태성을 유지하면서도 이 문제를 해결하기 위해 새로운 최적화 방안을 모색했다. 이 글은 당시 고민하며 정리했던 글이다. 주요 용어나 코드는 컨셉용으로 대체하였다.
목차
- 목차
- 초기 설계와 문제점
- 대안책
- 이와 같은 대안에 대한 평가
- 타 유스케이스
초기 설계와 문제점
사용자 인증 프로세스는 일반적인 토큰 기반 인증 시스템을 따릅니다. 즉, 사용자가 로그인을 요청하면, 사용자의 ID, 이름, 기타 정보 등을 포함하여 JWT 토큰을 생성하고, 이를 클라이언트에게 전달합니다.

클라이언트 측에서는 이 토큰을 이용하여 사용자 식별하고 권한에 따라 개인화된 사용자 화면을 구성합니다.
생성 예시 코드 (기존)
이러한 시나리오에서 JWT 토큰 생성 예시는 다음과 같습니다.
private String createToken(String userId, long tokenValidityMilliseconds, AdditionalUserInfo additionalUserInfo) {
Date now = new Date();
Date validity = new Date(now.getTime() + tokenValidityMilliseconds);
return Jwts.builder()
.subject(userId)
.claim("additionalUserInfo", additionalUserInfo)
.issuedAt(now)
.expiration(validity)
.signWith(secretKey(), SignatureAlgorithm.HS256)
.compact();
}예상되는 문제점
이러한 설계에서의 문제는 데이터의 과다함에 있습니다. 특히, 다수의 항목을 관리하는 경우, 토큰 길이가 과도하게 커질 수 있어 전송과 처리 과정에서 비효율을 초래합니다. 예를 들어, 7개 항목의 정보가 포함된 경우, SHA256과 base64 인코딩을 사용했을 때 토큰 길이는 1865자(1865 바이트)입니다.
대안책
프로세스 개선: 정보 분산 전략
기존 시나리오에서는 한 번의 토큰 생성과 전달 과정을 통해 모든 필요한 정보를 포함시켜 처리했습니다. 이에 반해, 새로운 접근 방식은 정보의 과부하를 줄이기 위해 필수적인 기본 정보만을 토큰에 포함시키는 전략을 채택합니다. 즉, 토큰은 사용자의 ID만을 포함하고, 그외 사용자 관련 추가 정보는 필요할 때 별도의 API 엔드포인트를 통해 제공합니다.
변경된 토큰 생성 예시 코드
private String createToken(String identifier, long tokenValidityMilliseconds) {
Date now = new Date();
Date validity = new Date(now.getTime() + tokenValidityMilliseconds);
return Jwts.builder()
.subject(identifier)
.issuedAt(now)
.expiration(validity)
.signWith(secretKey(), SignatureAlgorithm.HS256)
.compact();
}
기존의 모든 사용자 정보를 포함하는 대신 사용자 식별자만을 토큰에 포함시켰습니다. 이렇게 할 경우 토큰 길이는 200자(200Byte) 이내로 줄어들어 추가 정보가 포함되었을 때 대비 약 89% 길이 절감 효과를 가져옵니다.
추가 정보 요청을 위한 새로운 엔드포인트 구현
문제는 해당 토큰만 받은 클라이언트는 사용자의 필수 데이터를 받지 못했으므로 개인화된 화면을 구성하지 못합니다. 따라서 토큰을 받은 즉시 다시 서버로 사용자 정보 요청을 보내야 합니다. 이때의 시나리오는 다음과 같습니다.
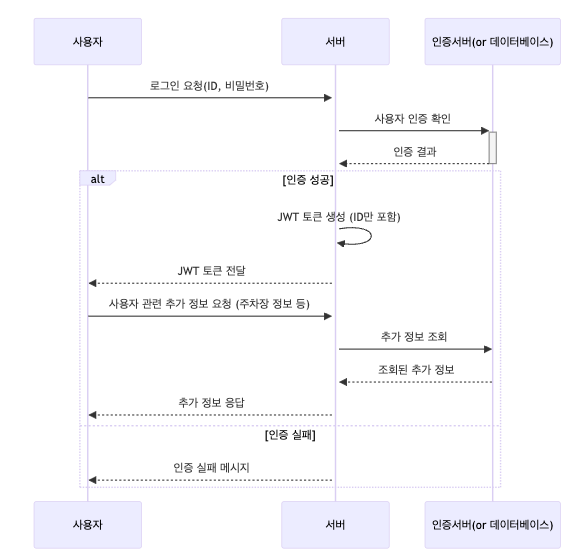
이러한 정보 전달을 위한 별도의 엔드포인트는 다음과 같습니다.
@GetMapping("{userId}/resources")
@Operation(summary = "특정 유저와 관련된 모든 리소스 정보 요청")
public CommonResponseEntity<List<ResourceInfo>> getResourcesByUser(@PathVariable String userId) {
return OK(facade.fetchAllResources(userId));
}
사용자의 ID를 받아 해당 사용자와 관련된 모든 필요한 정보를 반환합니다.
캐싱 전략의 적용
사용자 정보의 경우 캐싱 서버를 통해 관리합니다. 또한 해당 정보의 유효기간(TTL)은 리프레시 토큰의 만료 기간과 일치하도록 설정합니다.
이와 같은 대안에 대한 평가
JWT 토큰에 사용자의 모든 필요한 정보를 포함할 경우 서버와 클라이언트 간의 상호작용이 1회성으로 축소되어 인증 시스템의 효율을 극대화합니다. 하지만 위에서와 같이 대안으로 채택한 방식에서는 JWT 토큰에 기본 정보(ID)만 포함시키고, 필요한 추가 정보(예: 특정 리소스)는 별도의 API 요청을 통해 획득하는 방식을 채택합니다. 이 변경은 모든 정보를 토큰에 포함시키는 경우 대비 토큰의 길이를 줄여 네트워크 트래픽을 감소시키고, 토큰 해석 시간을 단축하는 데에는 기여합니다. 하지만, 추가 정보를 얻기 위한 별도의 API 호출이 필요하다는 또 다른 트레이드 오프가 발생합니다.
재호출 방식이라는 점에서 세션 기반 인증 방식과 유사하다면 JWT를 사용하는 것의 의미가 없지 않겠나를 고민했습니다. 세션 기반 방식에서는 클라이언트의 상태 정보를 서버가 유지하고, 클라이언트는 세션 ID만을 가지고 있습니다. 이 점에서, 새로운 JWT 접근 방식은 매 요청마다 서버로부터 필요한 정보를 조회해야 한다는 점에서 세션과 유사한 패턴을 보입니다.
주요 차이점은 무상태성(statelessness)과 확장성이 아닐까 합니다. 현재 방식에서 서버는 여전히 JWT 토큰의 상태를 관리하지 않습니다. 각 요청마다 단지 토큰을 검증하고 인증하며 필요한 정보를 전달합니다. 따라서 필요한 추가 정보를 별도의 API 요청을 통해 획득하는 방식은 네트워크 트래픽과 토큰 처리 시간을 줄이면서도, JWT의 핵심 이점인 무상태성 장점을 유지하는 것 같습니다. 또한, 서비스 확장성 측면에서 필요한 경우 MSA 분산 환경에서의 호환성을 보장하는 것도 장점으로 파악할 수 있을 것 같습니다.
결론적으로 토큰의 정보를 최소화하고 클라이언트 상호작용을 재구성함으로써 길이 제한 문제를 해결한 이 방식은, 적절한 트레이드 오프이자 최적의 해결책이라고 생각합니다.
타 비즈니스 유스케이스
비슷한 메커니즘으로 실제 비즈니스에서 JWT 토큰 기반 프로세스를 운영하는 사례를 찾으면 좋을 것 같습니다.
'이슈와해결' 카테고리의 다른 글
| @RequestBody 컨텐츠 유실 문제 - 컨트롤러에도 디버깅이 찍히지 않으면 어디를 봐야할까? (1) | 2023.12.21 |
|---|---|
| 일부러 정규화를 하지 않는 스키마는 어떨까? - 인가 프로세스에서 권한 관련 스키마 최적 설계 탐구 (feat. EAV, JsonB) (1) | 2023.12.18 |
| JWT 토큰 기반의 상태 관리시 로그아웃 처리 문제와 간단한 해결 방법 (1) | 2023.12.18 |
| 리팩토링 회고 - 입사 3개월 차에 만난 거대한 코드를 넘어가기 위해 생각했던 방법들 (0) | 2023.12.17 |
| 엔티티 필드 매핑 전략 탐구: 성능 테스터 Gatling을 이용한 Json 필드 매핑 사례 분석 (0) | 2023.12.16 |



