목차
1. 개요
2. 목적
3. 테스트 환경 구성
4. 더미데이터 구성
5. 조회 로직
6. 테스트 전략 및 시나리오
7. 테스트 결과 분석
8. 결론 및 추가 과제
개요
사내에서 대규모 시스템 개편을 하면서 차세대 프로젝트에 참여한 경험이 있습니다. 일 평균 160만 건 이상의 데이터가 쌓였기 때문에 맡은 도메인에서 대규모 데이터 처리 시나리오를 고민해야 했습니다. 본 글에서는 효율적인 데이터베이스 매핑 방법을 탐구하면서 결정한 한 가지 방법에 대한 성능 테스트 내용을 다룹니다. 특정 엔티티의 특정 필드(ImportantField)에 대해 String 타입의 집합으로 데이터를 준비하고, 요청 쿼리를 통해 성능을 테스트하고 결과를 분석하는 내용입니다.
목적
ImportantField필드에 대한 다양한 매핑 전략의 성능을 분석하고 비교합니다.- 데이터베이스의 응답 시간 및 처리량 최적화 방안을 모색합니다.
- 데이터 모델 및 쿼리 최적화 기반의 설계 및 구현을 통해 안정적인 시스템 운영을 지원합니다.
테스트 환경 구성
컴퓨터 환경
- 장비: 고성능 컴퓨터 (CPU, RAM, OS 상세 정보 생략)
- 개발 환경: 최신 버전의 Spring Framework, 관계형 데이터베이스 시스템, Java, 개발 도구
테스트 도구
테스트 도구는 Gatling 오픈소스 부하 테스트 프레임워크를 사용했습니다. Gatling은 실제 사용자 상호작용을 모방하는 시뮬레이션을 수행하며, 웹 애플리케이션에 대한 부하를 생성하고 성능을 측정할 수 있어 유저 기반의 요청 응답 성능을 쉽게 측정할 수 있습니다. 또한 결과 리포트를 html 기반의 ui로 제공하여 한눈에 비교 분석이 용이합니다. 가장 큰 장점은 java로 시뮬레이션을 작성할 수 있다는 부분입니다.
- 실제 사용자 시나리오 모방: 실제 사용자의 행동을 모방한 시나리오로 성능 테스트를 진행합니다.
- 동시 사용자 증가 시뮬레이션: 일정 시간 동안 점진적으로 사용자 수를 증가시켜 애플리케이션의 부하 증가를 시뮬레이션합니다. 예를 들어, 1초당 1명의 사용자가 시작하여 5명까지 10초 동안 증가, 이후 40초 동안 5명을 유지하고, 마지막으로 5명에서 1명까지 30초 동안 감소하는 패턴을 사용할 수 있습니다.
- 고급 통계 및 결과 보고: 응답 시간, 요청 처리량 및 오류 비율과 같은 성능 지표를 간편한 UI에 제공합니다.
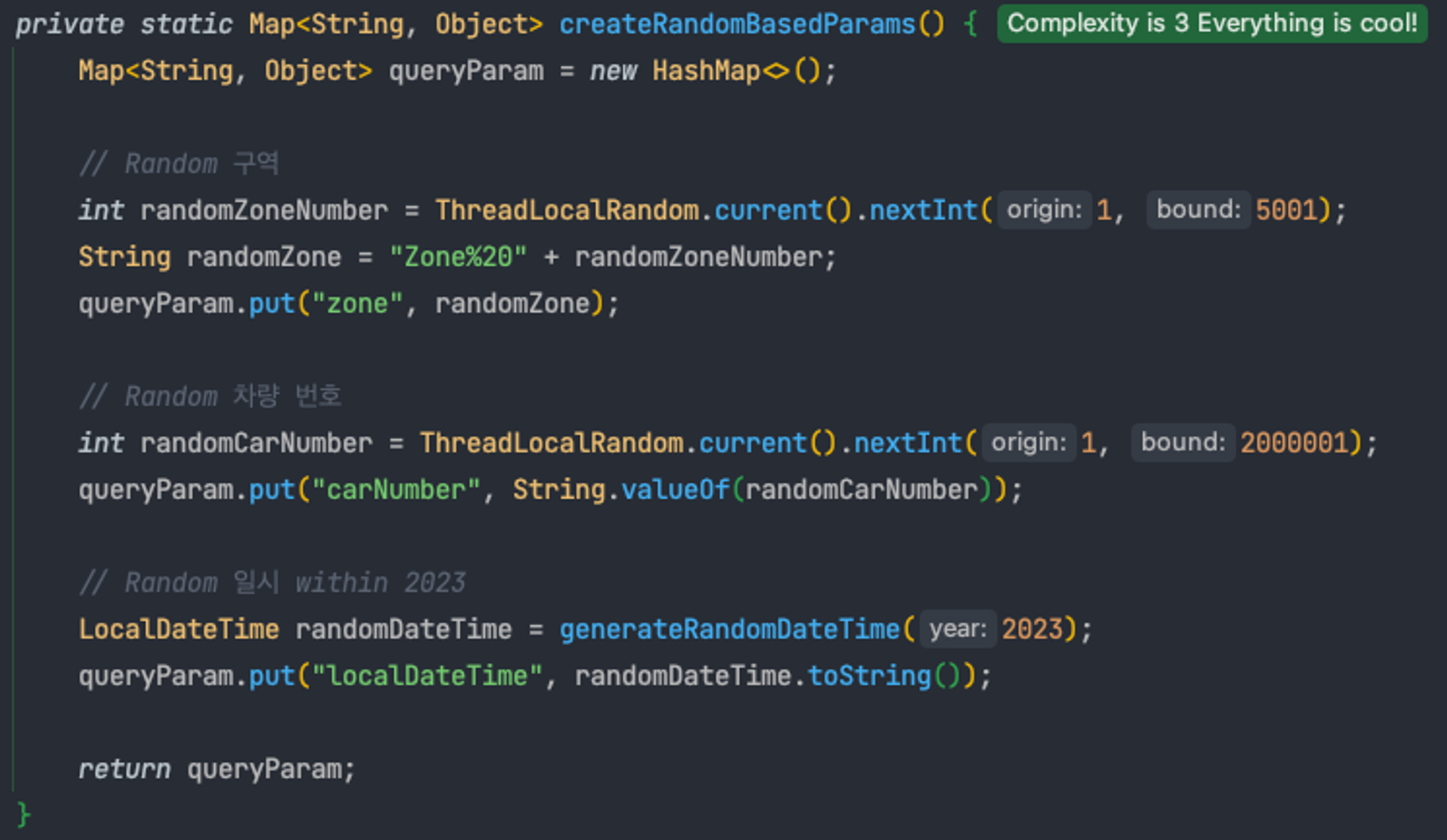
- Java 기반의 테스트 환경: Java 코드로 다양한 시나리오 및 커스텀 쿼리 파라미터 설정을 통해 다양한 테스트 케이스를 구성할 수 있습니다. 본 테스트에서는
ImportantField필드를 중심으로 한 쿼리에 대해 랜덤한 파라미터가 포함된 검색 쿼리를 생성하여 성능을 측정했습니다.
더미데이터 구성
- 더미데이터 엔티티 :
GenericEntity - 데이터 개수 : 1,010,020 개
@Entity
@Getter
@SuperBuilder
@NoArgsConstructor
@AllArgsConstructor
@Table(indexes = {
@Index(name = "IDX_GENERIC_ENTITY_FIELD1", columnList = "field1"),
@Index(name = "IDX_GENERIC_ENTITY_FIELD2", columnList = "field2"),
@Index(name = "IDX_GENERIC_ENTITY_FIELD3", columnList = "field3"),
})
public class GenericEntity extends BaseEntity {
@Id
@Column(length = 30, columnDefinition = "VARCHAR(30) COMMENT '기본 아이디'")
private String id;
private String field1; // 주요 필드 1
@Convert(converter = CustomConverter.class)
private Set<String> field2Set; // 주요 필드 2 집합
}
데이터 생성 규칙
- ID 생성: 각 데이터 항목의 ID는 UUID를 사용하여 중복을 방지하고, 분, 초, 밀리초를 포함합니다.
- 필드1: 테스트 목적으로 1부터 시작하는 연속된 숫자로 구성합니다.
- 필드2:
Set<String>형태의 문자열 집합으로, 1에서 1000 사이의 숫자 중 랜덤하게 1에서 10개를 선택하여 표현합니다. 예: "Item 103, Item 573, Item 651". - 기간: 시작 및 종료 날짜는 랜덤하게 설정되며, 예를 들어 2023년 1월부터 12월 사이에서 선택합니다.
- 시작 기간: 1월 ~ 6월
- 종료 기간: 7월 ~ 12월
- 데이터베이스 인덱스: 필드1, 시작 날짜, 종료 날짜
조회 로직
- 데이터베이스에서의 SQL 검색과 자바에서의 연산을 통해 이루어지는 두 단계 필터링
- 데이터베이스 연산: 필드1과 기간을 이용한 조회
- 자바 연산: 필드2에 대한 필터링
기타
필드1의 유니크함 보장하기
select field1, count(*) as count
from generic_entity
group by field1
having count(*) > 1;
테스트 전략
시나리오 1
- 조회 로직: 데이터베이스에서 일반 필드와 기간을 조회한 후 자바 연산으로 특정 조건을 판단하는 로직.
select entity from table where field1 = 특정값 and 기간 <= end_date - 쿼리 파라미터: 각 요청에 대해 랜덤하게 생성된
특정 조건,기간,일반 필드파라미터를 사용. - 사용자 증가 시뮬레이션:
- 시작 단계: 1초당 1명의 사용자가 시스템에 접속, 180초 동안 5명까지 증가합니다.
- 유지 단계: 5명의 사용자가 240초 동안 시스템을 지속적으로 사용합니다.
- 종료 단계: 사용자 수가 5명에서 1명으로 180초 동안 감소합니다.
- API 요청 실행:
- 각각 케이스에 대한 요청 실행
GET <http://localhost:9999/api/dummy/generic/3?field1=1&dateTime=2023-08-01T12:00:00&condition=Condition%20347>

테스트 결과 분석
시나리오 1 결과
총 3번의 테스트를 진행했고 각각의 결과 내용은 다음과 같습니다.
1회차

2회차

3회차

테스트 결과 요약
- 실행 회차: 총 3회
- 요청 수: 각 회차별로 2280개의 요청
- 응답 시간 범위:
- 최소 응답 시간: 8~9ms
- 최대 응답 시간: 139~374ms
- 평균 응답 시간:
- 1회차: 21ms
- 2회차: 23ms
- 3회차: 17ms
- 표준 편차:
- 1회차: 10ms
- 2회차: 24ms
- 3회차: 8ms
- 응답 시간 분포:
- 800ms 미만: 100%
- 1200ms 이상: 0%
분석
- 성능 일관성: 모든 요청이 800ms 미만이며, 평균 17ms ~ 23ms 에서 나타나고 있으므로 일관적인 패턴을 보여준다고 할 수 있습니다.
- 고부하 처리 능력: 표준 편차의 변동성과 최대 응답시간이 374ms 까지 나타난 것을 보았을 때, 상대적으로 높은 것은 고부하 상황에서 시스템이 느려질 수 있음을 시사합니다.
결론
100만 건의 데이터 셋 기준 최대 5명의 동시접속자가 240초간 유지되는 상황은 적당한 부하 상황에 대한 시뮬레이션이라고 판단합니다.
평균 응답 시간은 적절한 수치를 보여준다고 생각하나 최대 응답 시간은 높은 수치를 보여주고 있으므로 특정 조건 하에서 성능 저하가 발생 할 가능성이 있습니다. 실제 상황에서의 추가 연산 과정을 고려할 때 현재 확인된 최대 응답 수치보다 더 높은 수치가 나올 가능성을 고려해야 합니다.
따라서 성능 최적화와 안정성 향상을 위한 추가적인 조치가 필요할 것으로 판단됩니다.
추가 과제
- 데이터베이스 검색 조건과 자바 연산을 다양하게 조합하여 여러 가지 경우의 수에 대한 성능 분석 및 최적화 탐구
- 주차장 필드를 추가하여 데이터베이스 연산에서 필터링 강화
조회 로직 다변화
- 주차장 필드를 추가
- 차량 번호, 기간, 이용 구역, 주차장 속성에 대한 다양한 조합으로 자바와 데이터베이스 상의 연산을 분산하기
사용자 시뮬레이션 다변화
- 부하가 발생하지 않는 최소 동시 접속자수 분석하기
- 최대 병목이 발생하는 트래픽 예측하기
조회 로직 강화
- 캐시 도입으로 인한 성능 개선 탐구
- 추가 최적화 방안 탐구
후속 테스트: 시나리오 2
구현 고도화에 따라 추가 테스트 필요성이 발생하여 후속 테스트를 진행했습니다.
먼저 엔티티의 기본 설정과 검색 조건을 변경합니다.
엔티티 필드 추가
- 일반적인 필드
private String field2추가
엔티티 인덱스 설정 변경
@Table(indexes = {
@Index(name = "IDX_GENERIC_ENTITY_COMPOSITE", columnList = "field1, startAt, endAt"),
@Index(name = "IDX_GENERIC_ENTITY_FIELD2", columnList = "field2")
})
public class GenericEntity extends BaseTicket { 생략 }
쿼리 변경
- start 조건 추가
@Query("SELECT g FROM GenericEntity g WHERE g.field2 = :field2 AND g.field1 = :field1 AND :localDateTime >= g.startAt AND :localDateTime <= g.endAt")
GenericEntity findByField2AndField1AndPeriod(@Param("field2") String field2, @Param("field1") String field1, @Param("localDateTime") LocalDateTime localDateTime);
;
시나리오 2
- 조회 로직: 데이터베이스에서 필드1, 필드2 및 기간을 조회한 후 자바 연산으로 특정 조건을 판단하는 로직
@Query("SELECT g FROM GenericEntity g WHERE g.field2 = :field2 AND g.field1 = :field1 AND :localDateTime >= g.startAt AND :localDateTime <= g.endAt") - 쿼리 파라미터: 요청마다 랜덤하게 생성된
조건1,기간,조건2,필드1파라미터 사용. - 사용자 증가 시뮬레이션:
- 시작 단계: 1초당 1명의 사용자가 시스템에 접속, 180초 동안 5명까지 증가.
- 유지 단계: 5명의 사용자가 240초 동안 시스템을 지속적으로 사용.
- 종료 단계: 사용자 수가 5명에서 1명으로 180초 동안 감소.
- API 요청 실행:
- 각 케이스에 대한 요청 실행
GET <http://localhost:9602/generic-entity/dummy/4?field1=1234&localDateTime=2023-08-01T12:00:00&field2=5678>
시나리오 2 결과 분석
1회차
2회차

3회차

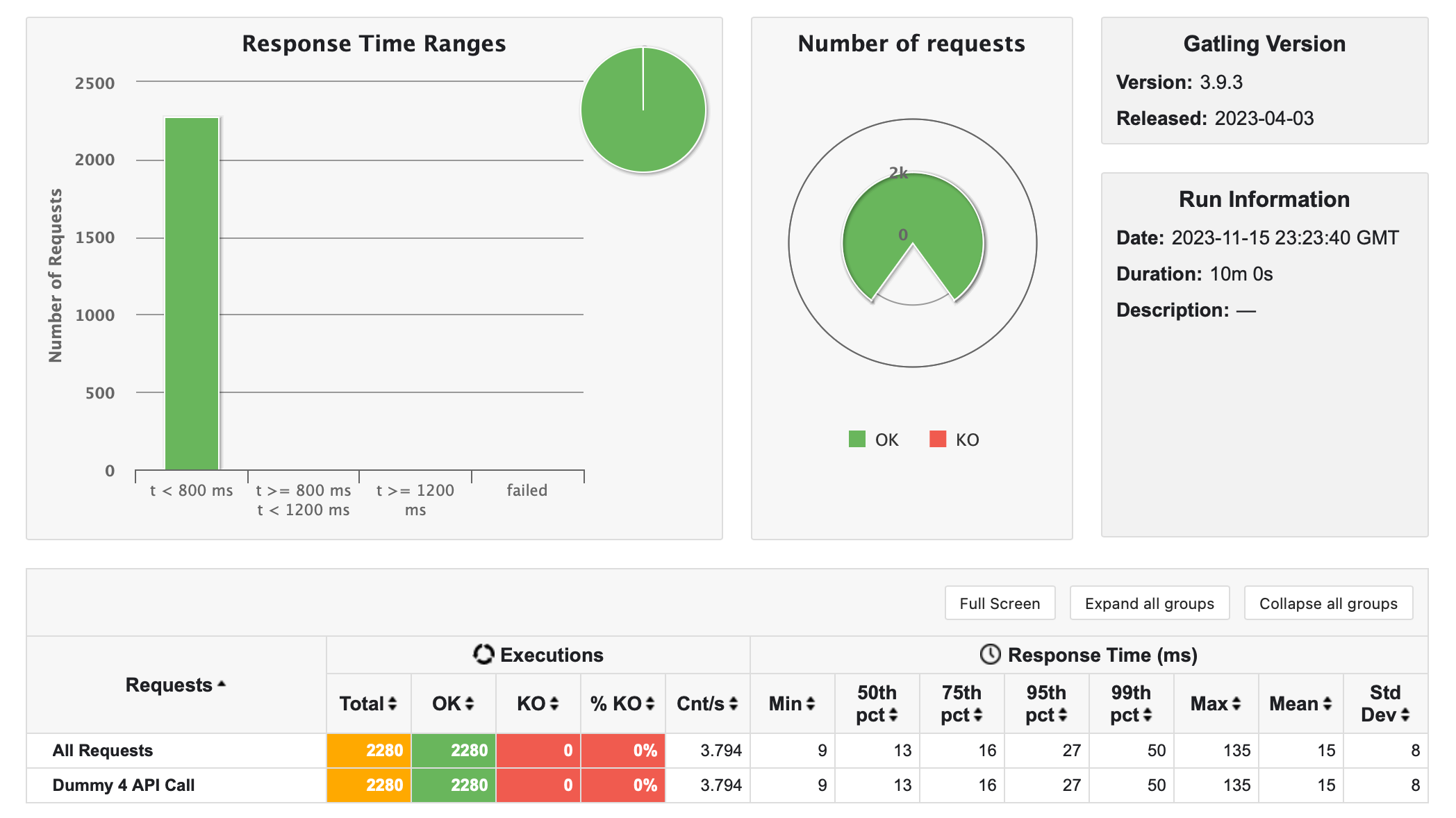
테스트 결과 요약
- 실행 회차: 총 3회
- 요청 수: 각 회차별로 240개의 요청
- 응답 시간 범위:
- 최소 응답 시간: 8~9ms
- 최대 응답 시간: 135~264ms
- 평균 응답 시간:
- 1회차: 15ms
- 2회차: 17ms
- 3회차: 15ms
- 표준 편차:
- 1회차: 9ms
- 2회차: 14ms
- 3회차: 10ms
- 응답 시간 분포:
- 800ms 미만: 100%
- 1200ms 이상: 0%
분석
- 성능 일관성: 모든 요청 800ms 미만으로 일관된 패턴을 유지하였습니다.
- 고부하 처리 능력: 최대 응답 시간의 개선이 발생했고 이는 3개의 인덱스를 통합하고 1개의 인덱스를 설정하여 총 2개의 인덱스로 로직을 변경한 결과로 추정할 수 있습니다. 시나리오 1에서 기간 조건에서 종료 일자만 설정했던 것에 대비 시작 조건을 추가한 쿼리 역시 성능에 큰 영향을 주지 않은 것으로 판단할 수 있습니다.
'이슈와해결' 카테고리의 다른 글
| JWT 토큰 기반의 상태 관리시 로그아웃 처리 문제와 간단한 해결 방법 (1) | 2023.12.18 |
|---|---|
| 리팩토링 회고 - 입사 3개월 차에 만난 거대한 코드를 넘어가기 위해 생각했던 방법들 (0) | 2023.12.17 |
| MSA 도메인 서비스에서 id 채번 방식 - 멱등성 보장하기 (1) | 2023.12.15 |
| 입사 0년차 주니어의 첫 운영 배포와 실수 경험 (0) | 2023.12.14 |
| 엔티티가 연장되는 속성을 가진 경우 효율적인 참조 관계 맺기 (1) | 2023.12.14 |


