1. 연결 리스트의 변형
단순 연결 리스트의 문제점
단순 연결 리스트는 각 노드가 단일 링크(포인터)만을 갖는 구조로, 다음 노드에 대한 접근은 용이하지만, 이전 노드로의 접근이 어렵다. 즉, 노드 검색 시 처음부터 순차적으로 탐색해야 하므로 효율성이 떨어진다. 이러한 제한은 데이터 구조에서의 유연성을 감소시키며, 특정 애플리케이션에서는 이러한 단일 링크 구조가 비효율적일 수 있다.
이중 연결 리스트
이중 연결 리스트는 각 노드가 두 개의 링크를 갖는 구조로, 하나는 다음 노드를, 다른 하나는 이전 노드를 가리킨다. 이 구조는 노드 검색과 조작이 더 유연해지며, 특히 노드의 삽입과 삭제가 더 간단하고 빠르다. 하지만, 추가적인 메모리가 필요하다는 단점이 있다.
자바 코드 예시:
class DoublyLinkedList {
Node head; // 리스트의 시작을 가리키는 노드
class Node {
int data;
Node prev;
Node next;
Node(int d) {
data = d;
}
}
// 노드 삽입, 삭제 등의 메서드 추가...
}원형 연결 리스트
원형 연결 리스트는 마지막 노드가 첫 번째 노드를 가리키는 형태로, 리스트의 끝과 시작이 연결되어 있다. 이 구조는 전체 노드를 순회하는데 유용하며, 리스트의 시작과 끝을 쉽게 접근할 수 있다. 하지만, 일반적인 연결 리스트보다 구현이 복잡할 수 있다.
자바 코드 예시:
class CircularLinkedList {
Node head; // 리스트의 시작을 가리키는 노드
class Node {
int data;
Node next;
Node(int d) {
data = d;
}
}
// 노드 삽입, 삭제 등의 메서드 추가...
}2. 원형 연결 리스트
개념
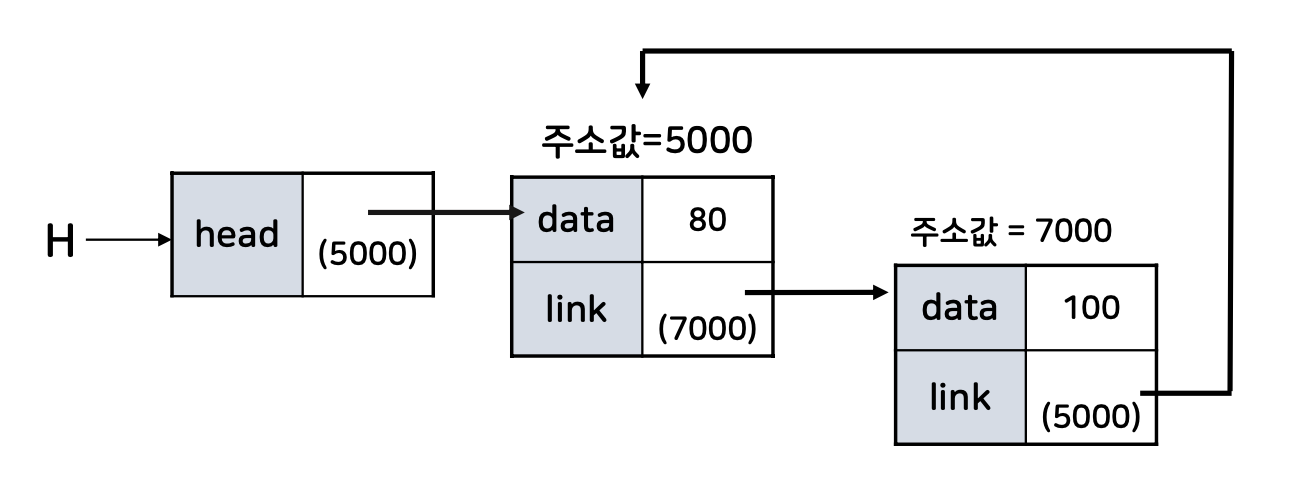
원형 연결 리스트는 마지막 노드가 첫 번째 노드를 가리키는 구조로, 전체 노드를 순회하는데 용이하다. 이 구조는 노드의 시작과 끝을 쉽게 찾을 수 있지만, 일반 연결 리스트보다 구현이 복잡하다.

원형 연결 리스트의 구조 및 특성
- 원형 연결 리스트는 마지막 노드가 첫 번째 노드(head)를 가리키는 연결 리스트의 변형이다.
- 순회가 용이하며, 시작과 끝을 쉽게 찾을 수 있다.
- 노드 삽입과 삭제에서의 효율성이 높다.
- 단순 연결 리스트와 비교하여 코드의 복잡도는 증가하지만, 순회 및 수정 작업에서 유연성이 증가한다.
생성
원형 연결 리스트의 생성은 첫 번째 노드(head)를 초기화하여 시작된다. Node head;와 같이 선언한 후, 해당 노드에 데이터를 할당하고, next 포인터를 자기 자신으로 설정하여 원형 구조를 형성한다.
class Node {
int data;
Node next;
Node(int d) {
data = d;
next = this; // 자기 자신을 가리키게 설정
}
}노드 삽입 1 - 초기 상태에서의 삽입
공백 상태의 리스트에서 새로운 노드를 삽입할 때, 새 노드의 next는 자기 자신을 가리키도록 설정한다. 이를 통해 리스트가 원형 구조를 유지한다.
```java
if (head == null) {
newNode.next = newNode;
head = newNode;
}
```노드 삽입 2 - 특정 위치에 삽입
특정 위치에 노드를 삽입할 때는 해당 위치의 이전 노드를 찾아 next 포인터를 새 노드로, 새 노드의 next를 이전 노드의 다음 노드로 설정한다.
```java
Node temp = head;
for (int i = 0; i < position - 1; i++) {
temp = temp.next;
}
newNode.next = temp.next;
temp.next = newNode;
```- 마지막에 삽입: 마지막 노드를 찾고,
next를 첫 번째 노드(head)로 설정한다.Node last = head; while (last.next != head) { last = last.next; } newNode.next = head; last.next = newNode;
노드 삽입 3 - 마지막에 삽입
마지막 노드에 삽입하는 경우, 마지막 노드를 찾아 그 next를 새 노드로 설정하고, 새 노드의 next는 첫 번째 노드(head)를 가리키도록 한다.
원형 연결 리스트의 노드 삭제를 위한 탐색
노드를 삭제하기 전에 해당 노드를 찾는 과정이 필요하다. 이는 주어진 값을 가진 노드를 찾거나, 특정 위치의 노드를 탐색하여 그 노드를 삭제 대상으로 설정한다.
원형 연결 리스트의 삭제
노드 삭제 시, 삭제하려는 노드의 이전 노드를 찾아 그 next 포인터를 삭제 노드의 다음 노드로 설정함으로써 연결 리스트의 연속성을 유지한다.
public void deleteNode(int key) {
Node temp = head, prev = null;
if (temp != null && temp.data == key) {
head = temp.next;
return;
}
do {
prev = temp;
temp = temp.next;
} while (temp != head && temp.data != key);
if (temp == head) return;
prev.next = temp.next;
}
3. 이중 연결 리스트
이중 연결 리스트의 정의 및 생성
이중 연결 리스트는 각 노드가 이전 노드와 다음 노드를 가리키는 두 개의 포인터(링크)를 갖는 데이터 구조다. 이를 통해 양방향 탐색이 가능하며, 삽입과 삭제 연산이 용이해진다. 초기 생성 시에는 빈 리스트를 만들며, 이후 노드를 추가하거나 삭제하는 연산을 통해 데이터를 관리한다.
Java 코드 예시:
class DoublyLinkedList {
Node head; // 리스트의 시작을 가리키는 노드
class Node {
int data;
Node prev;
Node next;
Node(int d) {
data = d;
}
}
// 노드 삽입, 삭제 등의 메서드 추가...
}이중 연결 리스트의 노드 삽입
이중 연결 리스트에서의 노드 삽입은 각 노드가 자신의 이전과 다음 노드를 가리키는 방식으로 이루어진다. 노드 삽입 과정에서 중요한 것은 새 노드의 prev와 next 포인터를 적절히 설정하는 것이다. 삽입 과정은 다음과 같이 진행된다.
Java 코드 예시:
public void insertNode(int data) {
Node newNode = new Node(data); // 새 노드 생성
newNode.data = data;
newNode.prev = null;
newNode.next = null;
if (head == null) { // 리스트가 비어있는 경우
head = newNode;
} else {
Node temp = head;
while (temp.next != null) {
temp = temp.next;
}
temp.next = newNode;
newNode.prev = temp;
}
}삽입 예시:
예를 들어, 초기 상태의 리스트가 다음과 같다고 가정하자.
H head
(5000) data 100
link (5500)
data 200
link (6000)
data 300
link NULL여기에 데이터 값이 500인 새 노드를 삽입하고자 한다면, 이 노드는 주소값 3500을 갖는다고 가정하자. 삽입 과정은 다음과 같다.
- 새 노드(
data 500, 주소값 3500) 생성 - 리스트의 마지막 노드(
data 300, 주소값 6000)를 찾는다. - 마지막 노드의
next를 새 노드의 주소값 3500으로 설정 - 새 노드의
prev를 마지막 노드의 주소값 6000으로 설정
이렇게 하면 새 노드가 리스트의 마지막에 성공적으로 삽입된다. 최종 리스트는 다음과 같은 형태를 가진다:
H Lhead(5000)
주소값 = 3000
Llink NULL
Fhead(3000) data 100
주소값 = 4000
Llink (3000) 주소값 = 5000
Rlink (4000) NewNode
주소값 = 3500
Llink NULL
Data 300
Rlink (5000)
Llink (4000)
data 500
Rlink NULL
data 200
Rlink NULL이 예시는 리스트의 끝에 새 노드를 추가하는 상황을 보여준다. 이중 연결 리스트에서는 이런 방식으로 어떤 위치에든 노드를 삽입할 수 있으며, 각 노드는 자신의 이전 노드(prev)와 다음 노드(next)에 대한 정보를 유지한다.
특정 노드의 삭제
이중 연결 리스트에서 특정 노드를 삭제하는 과정은 해당 노드의 prev와 next 링크를 적절히 조정하여 리스트에서 분리하는 것을 포함한다. 예를 들어, 주소값이 3000인 노드를 삭제하려는 경우, 이 노드는 데이터 100을 가지며, next 링크는 주소값 4000인 노드를, prev 링크는 null을 가리키고 있다.
삭제 과정은 다음과 같다:
- 노드의
prev링크가null이 아닌 경우, 즉 이전 노드가 존재하는 경우, 해당 이전 노드의next링크를 삭제하려는 노드의next로 업데이트한다. 예를 들어, 주소값이 3000인 노드의 이전 노드(만약 존재한다면)의next링크를 주소값이 4000인 노드로 설정한다. - 노드의
next링크가null이 아닌 경우, 즉 다음 노드가 존재하는 경우, 해당 다음 노드의prev링크를 삭제하려는 노드의prev로 업데이트한다. 예를 들어, 주소값이 4000인 노드의prev링크를 주소값이 3000인 노드의prev로 설정한다.
이러한 방식으로 노드를 연결 리스트에서 분리하고, 가비지 컬렉터가 나중에 사용하지 않는 메모리를 회수할 수 있도록 한다.
Java 코드 예시:
public void deleteNode(Node del) {
if (head == null || del == null) {
return;
}
if (head == del) {
head = del.next;
}
if (del.next != null) {
del.next.prev = del.prev;
}
if (del.prev != null) {
del.prev.next = del.next;
}
}노드가 리스트의 첫 번째 노드인 경우, 다음 노드가 존재하는 경우, 그리고 이전 노드가 존재하는 경우에 대해 처리한다.
참고 자료: 자료구조 (강태원, 정광식 공저, KNOU press 출판)
'CS > 자료구조' 카테고리의 다른 글
| 트리 용어 및 개념, 이진 트리, 순회 연산, 생성 삭제 조회 연산 - 자바 코드 (0) | 2023.11.24 |
|---|---|
| 깊이 우선 탐색 (Depth-First Search) (0) | 2023.11.24 |
| 연결 리스트, 리스트의 개념 및 구현, 포인터 변수, 여러 연산들 (1) | 2023.11.19 |
| 큐 - 큐의 개념, 큐의 추상 자료형, 큐의 응용, 배열 큐, 원형 큐 (0) | 2023.11.18 |
| 스택 - 스택의 개념, 스택의 추상 자료형, 연산 및 응용, 사칙연산식의 전위 중위 후위 표현 (0) | 2023.11.18 |



