1. 리스트의 개념
리스트의 의미
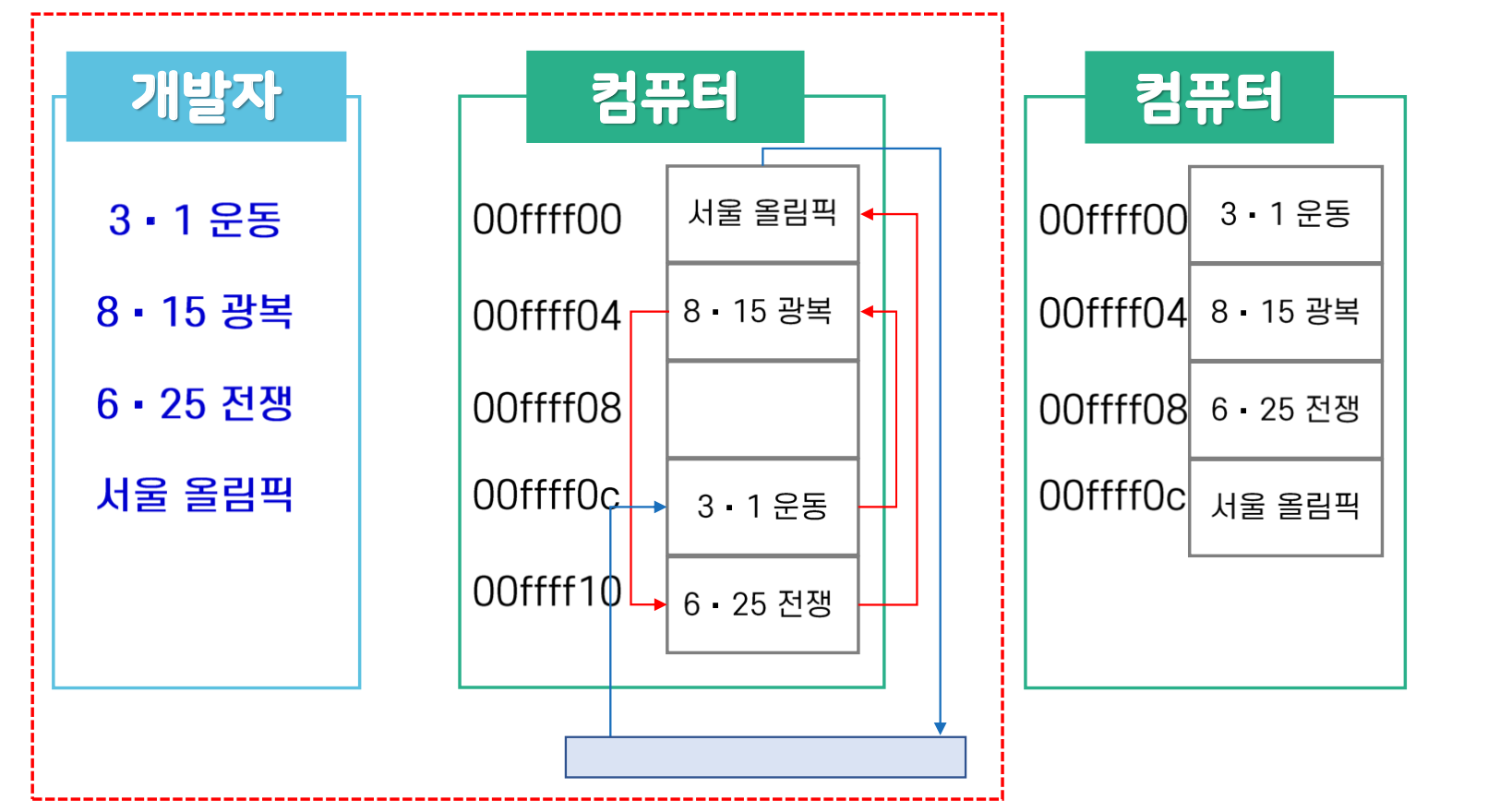
리스트는 일정한 순서로 나열된 데이터의 집합을 말한다. 이 순서는 물리적인 순서가 아닌 논리적인 순서를 의미한다. 이는 리스트가 데이터를 물리적인 메모리 위치에 연속적으로 저장하지 않아도 되며, 논리적인 순서만 유지하면 되는 추상적인 데이터 구조임을 의미한다.
배열의 정의
배열과 리스트는 상반되는 특성을 지닌다. 배열은 데이터가 메모리에 연속적으로 저장되는 구조로, 물리적인 순서가 중요하다. 배열에서는 각 데이터의 위치가 고정되어 있으며, 데이터에 접근하는 시간이 일정하다는 장점이 있다.
리스트의 구현 방법
리스트는 두 가지 주요 방법으로 구현될 수 있다. 첫 번째는 배열을 사용하는 방법이다. 이 방법은 메모리를 연속적으로 사용하지만, 데이터의 삽입과 삭제가 비효율적이 될 수 있다. 두 번째 방법은 포인터를 사용하는 방법이다. 이 방식은 물리적인 순서에 구애받지 않고 유연한 데이터 관리가 가능하다는 장점이 있다.
- 배열 기반 리스트: 메모리에 연속적으로 저장, 삽입 및 삭제 시 데이터 이동 필요
- 포인터 기반 리스트 (연결 리스트): 물리적 순서 무관, 유연한 데이터 관리 가능
리스트는 데이터의 논리적 순서만 유지하면 되므로, 개발자는 추상화된 순서에 따라 데이터를 조작할 수 있다.
2. 배열을 이용한 리스트의 구현
배열을 이용한 리스트의 구현
배열을 활용하여 리스트를 구현하는 방법은 데이터의 순차적 저장이라는 특징 때문에 구현이 간편하다. 배열의 각 요소는 연속된 메모리 위치에 저장되므로, 특정 인덱스에 접근하는 것이 용이하다. 이는 데이터 검색에 유리한 특성을 제공한다.
원소 삽입
원소 삽입 과정은 배열의 중간에 새로운 요소를 추가하고자 할 때, 그 위치 이후의 모든 요소를 오른쪽으로 이동시켜야 한다. 이는 상당한 연산 부담을 초래할 수 있다. 예를 들어, 1936년의 애국가 작곡을 기존의 역사적 사건 배열에 삽입하고자 할 때, 이후의 모든 요소들이 오른쪽으로 한 칸씩 이동해야 한다.

원소 삭제
원소 삭제 과정에서도 유사한 문제가 발생한다. 특정 요소를 삭제하고 나서, 그 요소 뒤에 위치한 모든 데이터를 왼쪽으로 이동시켜야 한다. 이 과정에서도 상당한 연산 시간이 소요된다. 예컨대, 1936년 애국가 작곡을 삭제한다면, 그 이후의 모든 데이터가 왼쪽으로 이동해야 한다.
배열을 이용한 리스트의 원소 삽입, 삭제시 발생하는 문제
배열을 이용한 리스트에서는 삽입과 삭제 연산이 비효율적일 수 있다. 주된 문제점들은 다음과 같다:
- 메모리 낭비: 배열의 크기를 미리 할당해야 하므로, 실제 사용량보다 많은 메모리를 할당하는 경우가 종종 있다. 예를 들어, 20개의 요소를 예상하여 배열을 생성했으나 실제로는 14개만 사용하는 경우, 남은 6개의 공간은 낭비된다.
- 연산 시간 증가: 삽입 또는 삭제 시, 다수의 원소를 이동해야 하므로 연산 시간이 증가한다. 특히, 배열의 크기가 클수록 이 문제는 더 심각해진다.
- 데이터 이동의 부담: 삽입과 삭제 과정에서 데이터의 이동이 빈번하게 발생한다. 이는 배열의 연속된 메모리 구조 때문에 불가피한 문제다.
이러한 문제들 때문에, 실제 IT 환경에서는 배열을 이용한 리스트 구현이 종종 비효율적으로 여겨진다. 배열을 사용하는 경우, 특히 대량의 데이터를 다룰 때, 이러한 문제점들을 고려해야 한다.
3. 포인터를 이용한 리스트의 구현
노드의 구조
포인터를 이용한 리스트 구현, 일명 연결 리스트에 대해 알아보자. 연결 리스트는 노드(Node)라는 기본 단위로 구성된다. 각 노드는 데이터와 다음 노드를 가리키는 포인터로 이루어진다.
- 데이터 부분: 실제 저장하고자 하는 값이 위치한다.
- 포인터 부분: 다음 노드의 메모리 주소를 저장한다. 이를 통해 연결 리스트의 연결 구조가 형성된다.

노드의 구조 및 연결
연결 리스트에서 노드들은 논리적인 순서를 유지하지만, 물리적으로는 메모리 상의 연속적인 위치에 저장될 필요가 없다. 예를 들어, 3.1운동, 815 광복, 6.25 사변, 서울 88올림픽 등의 역사적 사건들을 노드로 표현하면, 각 사건은 시간 순으로 연결되지만 메모리 상에서는 분산될 수 있다.
- 논리적 순서: 개발자가 정한 순서대로 노드들이 연결된다.
- 실제 메모리 위치: 각 노드는 메모리 상의 임의의 위치에 존재하며, 포인터를 통해 서로 연결된다.

연결 리스트의 논리적 순서와 실제 메모리 표현
연결 리스트의 핵심은 논리적 순서를 유지하면서도, 물리적인 위치의 제약을 받지 않는 유연한 자료 구조를 제공하는 것이다. 이를 통해 삽입과 삭제 연산 시 물리적인 데이터 이동이 필요 없어, 배열을 이용한 리스트에 비해 효율적이다.
- 유연한 삽입 및 삭제: 포인터만 수정하면 되므로, 연산이 간단하고 빠르다.
- 메모리 효율성: 필요한 만큼의 메모리만 사용하고, 불필요한 메모리 낭비가 없다.
- 논리적 연결성: 데이터가 물리적으로 연속적이지 않아도 논리적인 순서를 유지한다.
연결 리스트는 데이터의 추가, 삭제가 빈번한 경우에 효율적인 자료 구조이다. 또한, 노드 사이의 연결이 포인터를 통해 이루어지기 때문에, 데이터를 메모리에 연속적으로 저장할 필요가 없어 자료 구조의 유연성이 높다.
4. 포인터 변수
리스트의 생성과 포인터의 역할
리스트 생성 시 포인터는 중요한 역할을 수행한다. 예를 들어, 메모리 상의 물리적 순서와 관계없이 논리적 순서를 유지할 수 있게 한다. 이는 포인터가 각 노드를 연결하며 리스트의 순서를 정의하기 때문이다.
포인터의 할당과 반환 예
- 포인터 할당: C언어에서는
malloc등의 함수를 사용해 동적으로 메모리를 할당받는다. 예를 들어,Node *ptr = (Node*)malloc(sizeof(Node));코드는 새로운 노드를 위한 메모리를 할당하고, 그 주소를 포인터ptr에 저장한다. - 포인터 반환: 사용이 끝난 메모리는
free함수를 통해 반환해야 한다. 이렇게 하면 운영 체제가 해당 메모리를 다시 사용할 수 있게 된다.
// 노드 구조체 정의
struct Node {
int data;
struct Node* next;
};
// 노드 생성 및 메모리 할당
Node* createNode(int value) {
Node* newNode = (Node*)malloc(sizeof(Node)); // 새 노드를 위한 메모리 할당
newNode->data = value; // 데이터 할당
newNode->next = NULL; // 다음 노드를 NULL로 초기화
return newNode; // 새 노드의 포인터 반환
}
// 노드 삭제 및 메모리 반환
void deleteNode(Node* node) {
free(node); // 노드에 할당된 메모리 반환
node = NULL; // 노드 포인터를 NULL로 설정
}포인터의 할당과 반환의 실행 결과
포인터를 통한 메모리 할당과 반환은 연결 리스트의 효율적인 관리를 가능하게 한다. 메모리가 필요할 때만 할당받고, 더 이상 필요 없을 때 반환함으로써 메모리 낭비를 방지할 수 있다.


- 예시: 리스트에 새 노드를 추가하려 할 때, 포인터를 사용해 동적으로 메모리를 할당받고, 노드 사용이 끝나면 반환하여 메모리를 효율적으로 관리한다.
5. 연결 리스트의 삽입과 삭제
노드의 삭제
연결 리스트에서 노드를 삭제하는 과정은 다음과 같이 진행된다. 먼저, 삭제할 노드와 그 전후의 노드를 식별한다. 이를 위해 '선행 노드'(이전 노드)와 '후행 노드'(다음 노드) 개념을 사용한다. 삭제 과정은 두 단계로 이루어진다:
- 선행 노드의 링크를 삭제할 노드의 후행 노드로 변경한다. 이를 통해 연결 리스트에서 삭제할 노드를 '건너뛰게' 한다.
- 삭제할 노드를 메모리에서 해제한다. 이 과정을 'free'라고 하며, 운영체제에 해당 메모리 영역을 반환한다.

노드의 삽입
노드 삽입은 연결 리스트의 특정 위치에 새로운 노드를 추가하는 과정이다. 삽입 과정은 세부적으로 다음과 같다:
- 먼저 삽입할 위치를 정하고, 새로운 노드를 생성한다.
- 삽입할 위치의 이전 노드와 다음 노드 사이에 새로운 노드를 배치한다.
- 이전 노드의 링크를 새 노드로 변경하고, 새 노드의 링크를 다음 노드로 설정한다.
- 새 노드가 성공적으로 연결 리스트에 포함되면, 이는 연결 리스트의 일부가 된다.

배열을 사용한 리스트와 달리, 연결 리스트에서는 노드의 삽입과 삭제가 빠르고 효율적이다. 배열에서는 삽입이나 삭제 시 다른 원소들을 이동시켜야 하는 반면, 연결 리스트에서는 단순히 몇 개의 포인터만 조정하면 된다.
6. 연결 리스트의 여러 가지 연산
연결 리스트 생성
- 연결 리스트 생성은 리스트의 시작점을 나타내는 헤드 노드를 초기화하는 것으로 시작한다.
- 헤드 노드는 리스트의 첫 번째 요소를 가리키거나, 리스트가 비어 있을 경우 null을 가리킨다.
- 예를 들어, 빈 연결 리스트를 생성한다면, 헤드 노드는 null을 가리키는 상태가 될 것이다.
class Node {
String data;
Node next;
public Node(String data) {
this.data = data;
this.next = null;
}
}class LinkedList {
Node head;
public LinkedList() {
head = null; // 빈 리스트 생성
}
}연결 리스트 노드 삽입
- 노드 삽입은 리스트의 특정 위치에 새로운 요소를 추가하는 과정이다.
- 새 노드를 삽입할 때는, 기존 노드들 사이의 링크를 적절히 조정하여 삽입 위치에 맞게 노드를 연결한다.
public void insertNode(String data) {
Node newNode = new Node(data);
if (head == null) {
head = newNode;
} else {
Node temp = head;
while (temp.next != null) {
temp = temp.next;
}
temp.next = newNode;
}
}연결 리스트의 헤드에 노드 삽입 (빈 연결리스트의 경우)
public void insertAtHead(String data) {
Node newNode = new Node(data);
newNode.next = head;
head = newNode;
}- 헤드 노드가 null을 가리키는 경우, 새 노드를 생성하고 헤드 노드가 이를 가리키도록 설정한다. 예를 들어, 새 노드에 'A'라는 값을 넣는다면, 이 노드가 리스트의 첫 번째 요소가 된다.

연결 리스트 뒤에 한 개의 노드 삽입
- 리스트의 맨 끝에 새 노드를 추가하는 과정은, 마지막 노드를 찾고, 그 노드의 링크를 새 노드로 설정하는 것을 포함한다. 예를 들어, 'B'라는 값을 가진 노드를 추가한다면, 이전 마지막 노드가 'B'를 가리키도록 링크를 업데이트한다.
연결 리스트의 특정 노드 뒤에 새 노드의 삽입 연산
- 기존 노드 뒤에 새 노드를 삽입하는 것은 더 복잡하다. 예를 들어, 'A' 뒤에 'C'를 삽입하려면, 'A'의 링크를 'C'로 설정하고, 'C'의 링크를 'A'가 가리키던 다음 노드로 설정한다.
public void insertAfter(Node prevNode, String data) {
if (prevNode == null) {
System.out.println("이전 노드가 null일 수 없습니다.");
return;
}
Node newNode = new Node(data);
newNode.next = prevNode.next;
prevNode.next = newNode;
}연결 리스트의 마지막 노드 삭제
- 마지막 노드 삭제는 리스트의 끝까지 이동하여 마지막 노드를 삭제하는 것을 의미한다.
public void deleteLastNode() {
if (head == null || head.next == null) {
head = null;
return;
}
Node temp = head;
while (temp.next.next != null) {
temp = temp.next;
}
temp.next = null;
}하나의 노드
- 리스트에 노드가 하나만 있는 경우, 헤드 노드를 null로 설정하면 된다. 예를 들어, 'A'만 있는 리스트에서 'A'를 삭제한다면, 헤드는 null을 가리키게 된다.
여러 개의 노드
- 여러 개의 노드가 있는 경우, 마지막 노드 전까지 이동하여 마지막 노드를 삭제한다. 예를 들어, 'A' -> 'B' -> 'C'의 리스트에서 'C'를 삭제하면, 'B'의 링크는 null을 가리키게 된다.
연결 리스트의 특정 노드 검색 및 삭제
- 특정 노드를 검색하는 과정은, 리스트를 순회하며 특정 조건에 맞는 노드를 찾는 것을 포함한다.
- 연결 리스트에서 특정 노드를 삭제하는 과정은 이전 노드의 링크를 삭제할 노드의 다음 노드로 변경하는 것을 포함한다. 예를 들어, 'B'를 삭제하려면 'A'의 링크를 'B'의 다음 노드인 'C'로 변경한다.
public void deleteNode(String key) {
Node temp = head, prev = null;
if (temp != null && temp.data.equals(key)) {
head = temp.next;
return;
}
while (temp != null && !temp.data.equals(key)) {
prev = temp;
temp = temp.next;
}
if (temp == null) return;
prev.next = temp.next;
}
참고 자료: 자료구조 (강태원, 정광식 공저, KNOU press 출판)
'CS > 자료구조' 카테고리의 다른 글
| 깊이 우선 탐색 (Depth-First Search) (0) | 2023.11.24 |
|---|---|
| 연결 리스트의 변형: 원형 연결 리스트, 이중 연결 리스트 (1) | 2023.11.19 |
| 큐 - 큐의 개념, 큐의 추상 자료형, 큐의 응용, 배열 큐, 원형 큐 (0) | 2023.11.18 |
| 스택 - 스택의 개념, 스택의 추상 자료형, 연산 및 응용, 사칙연산식의 전위 중위 후위 표현 (0) | 2023.11.18 |
| 배열 - 정의, 추상 자료형, 연산, 희소 행렬 (0) | 2023.11.18 |



