0. 이 글의 배경
사이드 프로젝트에서 마이크로서비스 아키텍처(MSA)를 운영한다는 건 어떤 의미일까요?
이 글은 asyncsite라는 스터디 플랫폼 사이드 프로젝트에서 발생한 장애를 분석하고 해결한 과정을 담은 기록입니다.
초창기의 비용 리스크를 제외하고자 클라우드 서비스 대신 고성능 미니 PC 한 대에 개발 환경을 구축했습니다. 이 서버에는 API 게이트웨이를 포함한 약 12개의 서비스가 도커 컨테이너 형태로 실행되고 있었습니다.
중앙 로그 수집을 위해 도입한 ELK(Elasticsearch, Logstash, Kibana) 스택도 그중 하나였습니다. 이 포스트에서는 로그 수집 시스템의 설정 오류 하나가 어떻게 전체 시스템을 마비시켰는지, 그리고 그 문제를 어떤 과정으로 진단하고 해결했는지 공유하고자 합니다.
1. 고요한 실패의 기록: 100% 디스크 사용률의 전말
장애는 서버에 배포된 12개의 모든 서비스가 unhealthy 상태로 응답하지 않는 현상으로 시작되었습니다. 특정 서비스의 문제가 아닌 전방위적인 실패는 시스템 레벨의 문제를 직감하게 했습니다.
$ docker ps
CONTAINER ID IMAGE STATUS NAMES
b8d9770f0676 ghcr.io/asyncsite/job-crawler-service Up 13 hours (unhealthy) asyncsite-job-crawler
3876693bb519 ghcr.io/asyncsite/user-service Up 15 hours (unhealthy) asyncsite-user-service
0bc29ece9b75 ghcr.io/asyncsite/gateway Up 18 hours (unhealthy) asyncsite-gateway
fc13ec6a6df7 ghcr.io/asyncsite/eureka-server Up 18 hours (unhealthy) asyncsite-eureka
... (이하 모든 서비스가 unhealthy)
디스코드에 알림을 받고 있었는데, 새벽부터 이런 알림이 와 있었어요.
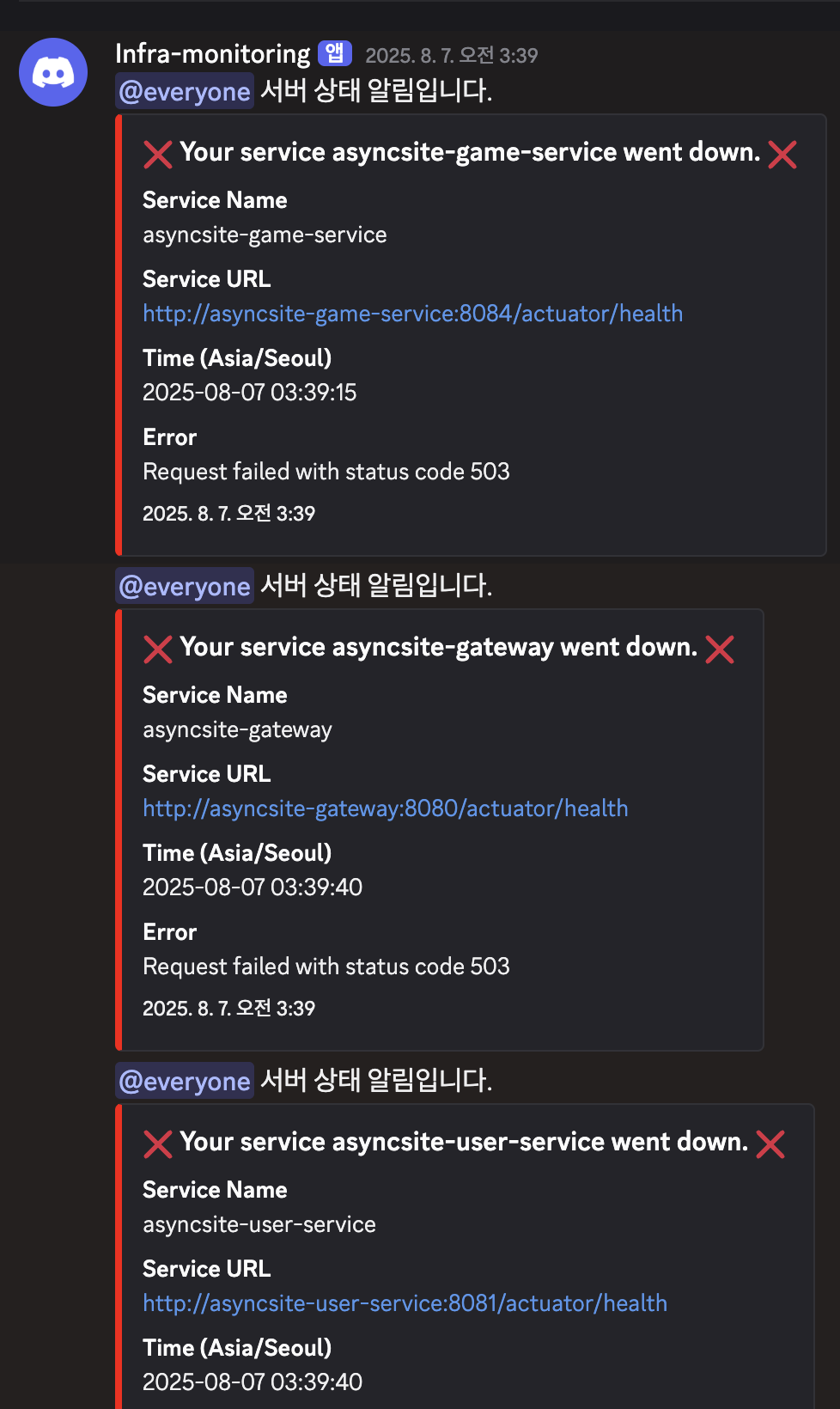
어느 특정 서비스 문제가 아니라 전체적으로 뭔가 죽은 게 분명해보였습니다.
미니 PC로 전체 서비스를 운영하는 우리 컨텍스트의 특성상 가장 먼저 의심되는 부분은 시스템의 기본적인 체력, 즉 CPU, 메모리, 그리고 디스크 리소스였습니다.

확인 결과 CPU와 메모리 사용률은 지극히 정상 범위였지만, 문제는 디스크였습니다.
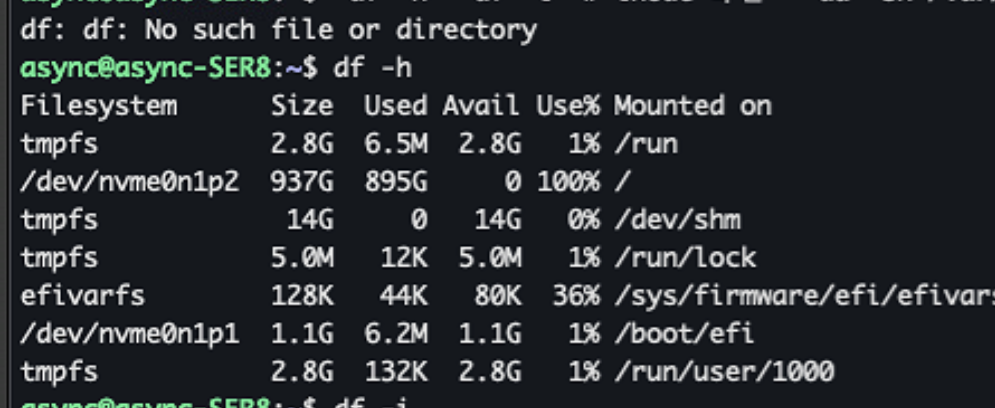
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/nvme0n1p2 937G 895G 0 100% /
출력된 결과는 명확했습니다. 937GB 디스크의 가용 공간이 0, 사용률은 100%. 디스크가 가득 차면 더 이상 어떤 로그도 기록할 수 없고, 임시 파일도 생성할 수 없으니 모든 서비스가 비정상으로 바뀌는 것은 당연한 수순이었습니다.
이제 문제는 '무엇이 이 디스크를 모두 집어삼켰는가'로 좁혀졌습니다.
du 명령어를 통해 거대한 파일(혹은 디렉토리)을 찾아 나서는 논리적 추적을 시작했습니다.
- 가장 상위 디렉토리(
/)부터 시작:/var디렉토리가 대부분의 공간을 차지하고 있었습니다. /var내부로: 예상대로 컨테이너 관련 데이터가 모여있는/var/lib/docker가 범인으로 지목되었습니다.docker디렉토리 해부: Docker가 사용하는 여러 디렉토리 중, 유독 컨테이너의 런타임 정보와 로그가 저장되는/var/lib/docker/containers디렉토리가 845GB라는 비정상적인 크기를 보였습니다.
이제 용의선상은 모든 컨테이너로 좁혀졌습니다. 마지막으로 각 컨테이너 디렉토리의 크기를 하나씩 확인했습니다.
$ sudo du -h --max-depth=1 /var/lib/docker/containers/ 2>/dev/null
625M /var/lib/docker/containers/f75f25265eb7... # elasticsearch
... (대부분의 서비스는 수십 ~ 수백 MB)
844G /var/lib/docker/containers/9b2af3a5f7fe... # logstash ⚠️
결과는 충격적이었습니다. 다른 모든 컨테이너의 로그가 많아봤자 수백 MB에 불과한데, logstash 컨테이너 하나가 무려 844GB를 차지하고 있었습니다. 범인은 logstash였습니다.
하지만 진짜 질문은 지금부터입니다.
며칠 전만해도 넉넉한 용량을 확인했었는데,
어떻게 하루 아침에 1TB에 가까운 메모리가 쌓인 걸까?
로그 수집기인 Logstash는 왜 스스로 이렇게
엄청난 양의 로그를 만들어내며 시스템 전체를 마비시킨 걸까?
Git 히스토리를 확인하고 나서야 우리는 그 전말을 파악할 수 있었습니다.
장애 발생일 새벽, Filebeat 설정 파일에서 단 한 줄의 코드가 주석 처리되었습니다.
# AsyncSite 서비스만 포함
# - drop_event: # 이 줄이 주석 처리됨!
# when:
# not:
# regexp:
# container.name: "^asyncsite-"
역시 시스템은 잘못이 없습니다. 결국 휴먼 에러였던 거죠.
이 drop_event 필터는 asyncsite-로 시작하는 우리 서비스의 로그만 수집하고 나머지는 버리는 역할을 했습니다. 하지만 이 필터가 주석 처리되면서 Filebeat는 서버의 모든 컨테이너 로그를 수집하기 시작했습니다. 그리고 바로 여기에 치명적인 함정이 있었습니다.
'모든 컨테이너'에는 로그를 처리하는 Logstash 자신도 포함되었기 때문입니다.
결과적으로 아래와 같은 '로그 무한 루프'가 발생했습니다.
Logstash가 로그를 한 줄 생성합니다.Filebeat가 이 로그를 감지하고 수집합니다.Filebeat는 수집한 로그를 다시Logstash로 전송합니다.- 로그를 처리하며
Logstash는 또 다른 로그를 생성합니다. (→ 1번으로 돌아가 무한 반복)
이 치명적인 순환은 불과 한두 시간 만에 844GB의 로그 파일을 만들어냈고, 결국 디스크를 가득 채워 서버 전체를 침묵시키는 '고요한 실패'를 완성했던 것입니다.
다행히 시스템이 지금 운영 단계 전이었기 때문에 당장 '일단 살려놓기'보다는 좀 더 근본적으로 대책을 마련할 여유가 있었습니다. 덕분에 위의 내용처럼 문제의 본질을 파악하는 데 많은 시간을 쓸 수 있었구요.
확실한 레슨런을 한 뒤 이제 해결 과정으로 돌입했습니다.
2. 응급처치와 항구 대책: 두 단계의 해결 과정
원인을 파악했으니 이제 해결할 차례입니다.
이 문제를 두 단계로 나누어 접근했습니다. 당장 시스템을 정상으로 돌리는 '응급처치'와, 두 번 다시 같은 일이 생기지 않도록 시스템의 체질을 개선하는 '항구적인 대책'입니다.
첫 번째 단계: 호흡기 확보 (응급처치)
가장 시급한 문제는 844GB에 달하는 로그 파일이 디스크를 점유하고 있다는 사실이었습니다. 이 공간을 즉시 확보해야 다른 서비스들이 정상적으로 숨을 쉴 수 있었습니다.
단순히 rm으로 파일을 삭제하는 대신, truncate 명령어를 사용했습니다. Logstash 프로세스가 로그 파일을 계속 사용 중일 수 있기 때문에, rm으로 삭제해도 프로세스가 종료되기 전까지는 디스크 공간이 실제로 반환되지 않는 경우가 많습니다. 반면 truncate는 파일 자체는 유지한 채 내용만 0으로 비워주기 때문에, 실행 즉시 공간을 확보할 수 있는 더 안전하고 확실한 방법입니다.
# 844GB 로그 파일의 내용을 즉시 0으로 비워 디스크 공간 확보
sudo truncate -s 0 /var/lib/docker/containers/9b2af3a5f7fe*/*-json.log
동시에, 무한 루프의 근원이던 filebeat-server.yml의 drop_event 설정 주석을 제거하여 원래대로 복구했습니다. 이 두 가지 조치로 시스템은 일단 급한 불을 끄고 정상 상태로 돌아올 수 있었습니다.
두 번째 단계: 시스템 체질 개선 (항구 대책)
응급처치는 임시방편일 뿐, 근본적인 원인은 그대로 남아있었습니다. 이 장애를 계기로 다시는 로그 때문에 서버가 멈추는 일이 없도록 시스템 전반에 몇 가지 안전장치를 마련했습니다.
1. Docker 데몬에 글로벌 로그 로테이션 설정
가장 먼저, Docker 데몬 자체에 로그 로테이션 정책을 적용했습니다. 이는 개별 컨테이너에 로깅 설정을 깜빡하더라도, 모든 컨테이너에 최소한의 안전망을 제공하는 중요한 조치입니다. /etc/docker/daemon.json 파일에 아래와 같이 설정했습니다.
{
"log-driver": "json-file",
"log-opts": {
"max-size": "100m",
"max-file": "3"
}
}
이제 모든 컨테이너는 개별 로그 파일이 100MB를 넘으면 자동으로 새 파일로 교체되며, 최대 3개의 파일만 유지하게 됩니다. (총 300MB)
2. 컨테이너별 맞춤형 로깅 정책 적용
글로벌 설정만으로는 부족합니다. 서비스의 특성에 따라 로그 발생량은 천차만별이기 때문입니다. 저희는 각 서비스의 docker-compose.yml 파일에 직접 로깅 옵션을 명시하여 더 정교하게 제어하기로 했습니다. 특히 이번 문제의 원인이었던 Logstash에는 더 엄격한 기준을 적용했습니다.
# 각 서비스의 docker-compose.yml에 추가
services:
your-service:
logging:
driver: "json-file"
options:
max-size: "100m" # 일반 서비스
max-file: "3"
logstash: # 문제가 됐던 로그스태시
logging:
driver: "json-file"
options:
max-size: "30m" # 더 작은 사이즈로 제한
max-file: "3"
숨어있던 복병: Elasticsearch의 인덱스 정책 충돌
문제가 모두 해결된 줄 알았을 때, 저희는 또 다른 복병을 마주했습니다. Logstash가 Elasticsearch로 로그를 전송하지 못하고 계속 오류를 내뱉고 있었습니다. 디스크 문제는 해결되었는데 왜일까요?
원인은 Logstash의 데이터 전송 방식과 Elasticsearch의 인덱스 템플릿 간의 충돌 때문이었습니다.
- Logstash 설정:
asyncsite-user-service-2025.08.12와 같이 '일별 인덱스'를 생성하도록 설정되어 있었습니다. - Elasticsearch 템플릿: 하지만
asyncsite-*패턴의 이름으로 데이터가 들어오면, 이를 '데이터 스트림(Data Stream)'으로 처리하라는 템플릿이 적용되어 있었습니다.
데이터 스트림은 시계열 데이터에 최적화된 방식이지만, 일반 인덱스와 달리 데이터 추가 시에만(create) 사용할 수 있는 등 엄격한 규칙이 있습니다. 저희의 Logstash는 기존 방식대로 데이터를 '덮어쓰기/생성(index)'하려고 했고, Elasticsearch는 데이터 스트림 규칙에 따라 이를 거부하며 충돌이 발생한 것입니다.
저희는 운영의 일관성을 위해 기존의 '일별 인덱스' 방식을 유지하기로 결정하고, 데이터 스트림을 생성하던 템플릿을 수정하여 이 숨어있던 문제까지 완전히 해결했습니다.
3. 로그 파일이 우리에게 남긴 교훈
무사히 장애를 해결하고 나자, 단순한 안도감을 넘어 몇 가지 중요한 교훈이 머릿속을 맴돌았습니다. 이번 사건은 단순한 기술적 해프닝이 아니라, 우리가 당연하게 여겼던 것들에 대해 다시 한번 생각하게 만드는 계기가 되었습니다.
"개발 서버니까" 라는 안일함이 부르는 대가
"아직 정식 오픈 전인 개발 서버에서 일어난 일이라 다행이야." 처음에는 이렇게 생각했습니다. 하지만 곱씹어볼수록 이건 굉장히 위험한 생각이었습니다. 만약 이 문제가 잠복한 채로 프로덕션 환경까지 넘어갔다면 어땠을까요? 수많은 사용자들이 불편을 겪고, 저희는 허둥지둥하며 신뢰를 잃었을 것입니다.
개발 환경은 프로덕션 환경의 '연습장'이 아니라 '예고편'입니다. 이곳에서 발생하는 문제는 언제든 실제 환경에서도 똑같이 발생할 수 있다는 강력한 신호입니다. 이번 경험을 통해 저희는 개발 단계의 시스템 안정성 확보와 잠재적 위험 관리가 얼마나 중요한지 뼈저리게 깨달았습니다.
편리한 자동화의 이면에 숨겨진 위험성
GitHub Actions를 통해 코드가 머지되면 자동으로 서버에 배포되는 CI/CD 파이프라인을 사용하고 있었습니다. 이는 개발 속도를 높여주는 매우 편리한 도구입니다. 하지만 이번 장애의 시발점이 된 설정 변경 역시 이 자동화 파이프라인을 통해 새벽 시간에 아무런 제지 없이 서버에 적용되었습니다.
편리함은 때로 책임감을 무디게 만듭니다. drop_event 필터처럼 시스템 전반에 영향을 미칠 수 있는 중요한 설정 변경은, 자동화에만 의존하면 안되겠다는 생각이 들었어요. '이 코드 한 줄이 시스템 전체를 멈출 수도 있다'는 경각심을 가지고, 자동화의 편리함 속에서 우리가 놓치고 있는 것은 없는지 항상 되돌아봐야 한다는 교훈을 얻었습니다.
단순히 로그를 쌓는 것을 넘어, '관측 가능성'을 설계해야 하는 이유
장애가 발생하기 전까지 저희의 ELK 스택은 단순히 '로그를 모아두는 창고'에 가까웠습니다. 정작 그 로그가 얼마나 쌓이는지, 디스크 용량은 얼마나 남았는지, Logstash와 Elasticsearch는 서로 통신을 잘하고 있는지에 대한 모니터링은 부족했습니다.
로그(Log), 메트릭(Metric), 추적(Trace)은 '관측 가능성(Observability)'을 구성하는 세 가지 기둥입니다. 단순히 데이터를 쌓아두는 것을 넘어, 시스템의 상태를 언제든 파악하고 이상 징후를 미리 감지할 수 있도록 만드는 것이 진정한 관측 가능성의 목표입니다. 이번 장애 이후 저희는 디스크 사용률 80% 경고 알람, Logstash-Elasticsearch 간 연결 상태 모니터링 등을 추가했습니다. 문제가 터지고 나서 로그를 뒤지는 '사후 분석'에서, 문제가 터지기 전에 알아채는 '사전 예방'으로 나아가야 함을 배웠습니다.
파수꾼을 세우다: 모니터링 시스템 구축
장애를 겪고 나니 명확해진 것이 있었습니다. 로그를 쌓는 것과 시스템을 '관찰'하는 것은 전혀 다른 차원의 문제라는 것이죠. 우리에게 필요한 것은 단순한 로그 수집기가 아니라, 24시간 깨어있는 파수꾼이었습니다. 그래서 우리는 두 개의 핵심 모니터링 도구를 도입했습니다.
첫 번째는 Uptime Kuma입니다. 우리 서비스들의 심장박동을 체크하는 역할을 맡았습니다. Gateway, Study Service, Notification Service 등 11개 마이크로서비스의 health 엔드포인트를 매분 호출하며 살아있는지 확인합니다. MySQL과 Redis 같은 데이터베이스까지 포함해서 말이죠. 평균 응답시간은 3ms 내외로 매우 안정적입니다. 무엇보다 중요한 것은, 문제가 감지되면 즉시 Discord 웹훅을 통해 @everyone 멘션과 함께 알림이 날아온다는 점입니다. "서버 상태 알림입니다"라는 메시지와 함께 어떤 서비스가 다운됐는지 구체적으로 알려주죠.
두 번째는 Netdata로, 시스템 레벨의 메트릭을 실시간으로 수집합니다. CPU 사용률, 메모리 사용량, 그리고 무엇보다 중요한 디스크 사용률까지. 이전 장애의 직접적 원인이었던 디스크 풀 상황을 미리 감지할 수 있게 되었습니다. Docker 컨테이너별 리소스 사용량도 추적하여, 특정 서비스가 비정상적으로 리소스를 소비하는 상황도 즉시 파악할 수 있습니다.
이 두 도구의 조합으로 우리는 응용 레벨(서비스 health)과 인프라 레벨(시스템 메트릭) 모두를 커버하는 관측 체계를 갖추게 되었습니다.
돌이켜보면 조금 부끄러운 이야기입니다. 우리는 기능 구현에만 매몰된 나머지, 정작 우리가 만든 서비스가 제대로 '살아있는지' 증명하는 가장 기본적인 일을 소홀히 했습니다. 코드가 localhost를 떠나 서버에서 실행되는 순간, 그것은 더 이상 단순한 프로그램이 아니라 관리가 필요한 생명체라는 인식이 반드시 필요합니다.
4. 인간, 서버, 그리고 AI: 문제 해결 방식의 미래
장애의 흔적을 모두 지우고 시스템이 다시 안정적으로 돌아가는 것을 보며, 저는 우리가 거쳐온 문제 해결 과정을 천천히 복기해 보았습니다. df로 디스크를 확인하고, du로 용의자를 좁혀가고, Git 히스토리를 뒤져 결정적인 단서를 찾아냈던 그 모든 수작업의 절차들. 바로 그 지점에서 문득 이런 생각이 머리를 스쳤습니다.
"이 모든 과정을 AI가 했다면 어땠을까?"
그래서 시켜보았어요.
AI는 인간보다 훨씬 빠르고 지치지 않습니다. 우리가 했던 것처럼 서버에 접속했습니다. 분명 이전에는 안되었던 거 같은데, 클로코드에게 ssh 접속하라고 시키니 잘 접속을 합니다. 그런 뒤 확실하게 필요한 명령어들을 생각해 냈습니다. 빠르게 실행하고, 텍스트로 된 결과를 분석하여 이상 징후를 감지할 수 있습니다. 844GB를 차지한 Logstash 컨테이너를 찾아내는 것은 물론, 그와 관련된 코드 저장소를 분석해 불과 몇 시간 전에 변경된 filebeat.yml의 설정 한 줄을 원인으로 지목하는 것까지, 제가 했던 과정보다 더욱 명확하고 확실하게, 그리고 빠르고 정확하게 해내는 모습을 실시간으로 지켜보았습니다.

이 상상은 더 큰 질문으로 이어집니다. 만약 코드를 작성하고, 테스트하고, 배포하고, 심지어 장애의 원인까지 파악하는 이 모든 사이클에 AI가 깊숙이 관여한다면, 우리가 그토록 중요하게 여겨온 '인간을 위한 베스트 프랙티스'는 과연 미래에도 유효할까요?
가독성 높은 변수명, 클린 아키텍처, 디자인 패턴 같은 원칙들은 본질적으로 '인간의 실수를 줄이고, 인간 동료와의 협업을 원활하게' 하기 위해 만들어졌습니다. 하지만 주된 협업 대상이 인간이 아닌 AI가 되는 시대가 온다면, 이 원칙들의 무게는 지금과 같을 수 없을 것입니다.
저는 이번 경험을 통해 AI 시대 개발자에게 필요한 지식과 기술이 세 가지 층위로 재편될 것이라는 생각을 하게 되었습니다.
- AI에게 맡겨도 좋은 것 (The 'How')
반복적인 코드 작성, 테스트 실행, 배포, 그리고 이번에 경험한 것과 같은 명확한 패턴이 있는 시스템의 초기 진단. 이 영역에서 AI는 인간보다 훨씬 빠르고 정확한 조수가 될 것입니다. - 알아두면 좋은 것 (The 'Human-Centric How')
과거에는 필수였던 클린 아키텍처나 여러 설계 원칙들. 이제 이 지식들은 그 자체가 목적이 되기보다, AI의 결과물을 검증하고, 더 나은 결과물을 만들도록 유도하며, 더 좋은 질문을 던지기 위한 '지렛대' 역할을 하게 될 것입니다. - 반드시 붙잡아야 할 것 (The 'Why')
결코 AI에게 맡길 수 없는 영역입니다. 바로 비즈니스의 본질을 이해하고, 사용자의 진짜 문제를 파악하여 '무엇을, 왜 만들어야 하는지'를 정의하는 능력입니다. 기술을 통해 어떤 가치를 만들어낼 것인가에 대한 근본적인 고민은 인간의 몫으로 남지 않을까 합니다. 물론 이 영역도 중첩이 있겠지만요.
결국 "로컬 호스트 밖을 벗어나야 진짜 개발"이라는 말이 있습니다. 이런 장애야 말로, 역설적으로 우리가 localhost를 벗어나 진짜 문제를 마주하고 있다는 가장 확실한 증거가 아닐까 합니다.
AI 시대의 성장이란 어쩌면 이런 과정의 반복일지도 모릅니다.
AI라는 강력한 도구의 도움을 받아 더 빠르게, 더 과감하게 localhost 밖으로 나아가고, 그 과정에서 부서지고 깨지더라도 결국 무언가를 '성취'해내는 경험. 그리고 그 성취의 경험이야말로 우리를 성장시키는 진짜 동력일 것입니다.
하나의 장애는 기술적인 숙제를 남겼지만, 그 해결 과정에서 다시 한 번 'AI 시대의 진짜 성장이란 무엇인가'에 대한 우리 나름의 생각을 발전시킬 수 있는 기회가 되었습니다.

'회고' 카테고리의 다른 글
| AWS Q 해커톤 회고 - "야 AI 개발, 그렇게 하는 거 아니야!" (3) | 2025.09.07 |
|---|---|
| 결국, 세상은 만드는 사람들의 것 (0) | 2025.09.07 |
| 제가 만든 AI가 처참히 패배했습니다 (그리고 그보다 짜릿한 순간은 없었습니다) (4) | 2025.08.01 |
| 테스트 30분 → 3분: MSA 인증 시스템과 E2E 자동화 플랫폼 20시간 구축 썰 (3) | 2025.07.13 |
| 프론트 제가 한번 세팅해봤는데요 (← 프론트 1도 모르는 백엔드 개발자) (1) | 2025.07.07 |


