간단 회고
👀 다시 읽고 싶다: ★★★★★
🔥 추천한다: ★★★★★
- 저자
- 루 샤오펑
- 출판
- 길벗
- 출판일
- 2024.03.11
1
저수준 계층의 세부 사항 대 고수준 계층의 추상화
CPU는 실제로 너무 단순합니다! 심지어는 '저에게 물 한 잔 주세요'처럼 말을 조금만 추상적으로 바꾸어도 이해하지 못할 정도입니다. 반면 인간은 천성저으로 추상적인 표현에 익숙합니다. 그렇다면 인간과 기계 사이의 거리를 좁힐 수 있는 방법이 있을까요?
다시 말해 인간의 추상적인 표현을 CPU가 이해할 수 있는 구체적인 구현으로 자동으로 변환할 수 있는 방법이 있다면...
- 29p
<인셉션>과 재귀: 코드 본질
if: if expr statement else statement
for: while expr statement
statement: if | for | statement
앞서 이야기했던 단계가 또 다른 단계에 중첩되는 <인셉션>은 이렇게 간결한 문장 몇 개로 표현할 수 있다는 것을 알았습니다. 여러분은 이 몇 가지 표현에 구문(syntax)이라는 고급스러운 이름을 붙였습니다.
수학은 모든 것을 이렇게 우아하게 만들 수 있습니다.
세상의 모든 코드는 아무리 복잡하더라도 결과적으로는 모두 구문으로 귀결됩니다. 이것이 가능한 이유는 매우 간단한데 모든 코드는 구문에 기초하여 작성되기 때문입니다.
- 35~36p
링커는 이렇게 일한다
링커는 컴파일러와 마찬가지로 일반적인 프로그램에 불과합니다. 링커는 압축 프로그램이 파일 여러 개를 하나의 압축 파일로 묶어 주는 것처럼, 컴파일러가 생성한 대상 파일 여러 개를 하나로 묶어 하나의 최종 실행 파일을 생성합니다.
소스 코드를 담고 있는 func.c 파일이 있다고 가정해 봅시다. 이 파일을 컴파일 하면 func.o라는 이름의 기계 명령어에 해당하는 코드를 저장하는 파일이 생성되는데, 이 파일을 대상 파일(object file)이라고 합니다. 윈도에서 우리가 흔히 보는 EXE 형식의 실행 파일이나 리눅스의 ELF 파일 같은 실행 파일은 링커가 필요한 대상 파일을 한데 모아 구성합니다. 이는 "helloworld" 같은 간단한 응용 프로그램(application)부터 웹 브라우저나 웹 서버 같은 복잡한 응용 프로그램까지 예외가 업습니다.
- 48~49p
심벌 해석: 수요와 공급
이 단계에서 링커가 해야 할 일은 대상 파일에서 참조하고 있는 각각의 모든 외부 심벌마다 대상 정의가 반드시 존재하는지. 단 하나만 존재하는지 확인하는 것입니다.
- 명령어 부분: 소스 파일에 정의된 함수에서 변환된 기계 명령어가 저장되는 부분입니다. 앞으로 이 부분을 코드 영역이라고 하겠습니다.
-데이터 부분: 소스 파일의 전역 변수가 저장되는 부분입니다. 앞으로 이 부분을 데이터 영역이라고 하겠습니다. 참고로 로컬 변수는 프로그램이 실행된 후 스택 영역에서 생성되고 사용하면 제거되기 때문에 대상 파일에는 별도로 저장되지 않습니다.
컴파일러는 컴파일 과정에서 외부에서 정의된 전역 변수나 함수를 발견할 경우, 해당 변순의 선언이 존재하는 한 그 변수가 실제로 정의되었는지 여부는 신경 쓰지 않고 유쾌하게 다음 단계로 넘어갈 것입니다. 참조된 변수 정의를 찾는 일은 컴파일러가 아닌 링커 몫입니다.
비록 컴파일러가 링커에 이 작업을 떠넘기기는 하지만, 링커 부담을 조금이나마 줄여 주고자 대신 다른 작업을 더 합니다. 소스 파일마다 외부에서 참조 가능한 심벌이 어떤 것인지 그 정보를 기록하고, 반대로 어떤 외부 심벌을 참조하고 있는지도 기록합니다. 이렇게 컴파일러가 외부 심벌 정보를 기록하는 표를 심벌 테이블이라고 합니다.
- 50~52p
정적 라이브러리, 동적 라이브러리, 실행 파일
정적 링크는 라이브러리를 실행 파일에 직접 복사하기 때문에 C 표준 라이브러리처럼 거의 모든 프로그램에 적용되는 표준 라이브러리를 사용한다면 정적 링크로 생성된 실행 파일은 모두 동일한 코드와 데이터의 복사본을 갖게 됩니다. 이 경우 디스크와 메모리를 엄청나게 낭비할 수 있습니다. 다시 말해 정적 라이브러리 크기가 2MB고 라이브러리를 사용하는 실행 파일이 500개라면, 1GB 크기의 데이터가 중복된 데이터로 구성된다는 의미입니다. 또 정적 라이브러리의 모든 내용에 종속성이 있다고 가정하면, 정적 라이브러리의 코드가 변경될 때마다 해당 정적 라이브러리에 종속된 프로그램 역시 매번 다시 컴파일해야 합니다.
그렇다면 이 문제를 어떻게 해결할 수 있을까요? 정답은 바로 동적 라이브러리를 사용하는 것입니다.
동적 라이브러리는 공유 라이브러리 또는 동적 링크 라이브러리라고도 합니다. 윈도에서 흔히 볼 수 있는 DLL 파일이 바로 동적 라이브러리이며, 윈도 시스템에서는 동적 라이브러리를 매우 많이 사용합니다. 반면 리눅스의 동적 라이브러리는 .so 확장자를 사용하며, 접두사로는 lib를 사용합니다. 예를 들어 숫자 연산에 사용되는 Math 라이브러리를 컴파일하고 링크하여 생성된 동적 라이브러리 이름은 libMath.so입니다.
만약 두 소스 파일 a.c와 b.c가 있을 때 이를 동적 라이브러리 foo로 생성하고 싶다면, 리눅스에서는 다음 명령어를 사용하여 동적 라이브러리르 생성할 수 있습니다.
$ gcc -shared -fPIC -p libfoo.so a.c b.c
라이브러리라는 이름에서 알 수 있듯이, 동적 라이브러리에도 정적 라이브러리와 마찬가지로 기본적으로 우리가 이미 살펴보았던 코드 영역, 데이터 영역 등이 포함되어 있습니다. 단지 동적 라이브러리의 사용 방식과 사용 시간이 정적 라이브러리와 다를 뿐입니다.
- 56~57p
동적 라이브러리를 사용하면 정적 라이브러리가 실행 파일에 라이브러리 내용을 모두 복사했던 것과 달리, 참조된 동적 라이브러리 이름, 심벌 테이블, 재배치 정보 등 필수 정보만 실행 파일에 포함됩니다. 이는 그림 1-26과 같이 정적 라이브러리에 비해 실행 파일의 크기를 확실히 줄일 수 있다는 점에서 매우 중요합니다.

그렇다면 참조된 동적 라이브러리의 필수 정보는 어디에 저장될까요?
이 정보는 실행 파일 내 저장되며, 이제 실행 파일이 포함할 수 있는 내용은 그림 1-27과 같이 더 늘어납니다.
이 필수 정보는 어느 시점에 사용될까요? 정답은 동적 링크가 일어날 때입니다.
- 58~59p
재배치: 심벌의 실행시 주소 결정하기
컴파일러는 컴파일을 통해 대상 파일을 생성할 때 foo 함수가 어느 메모리에 적재될지, 다시 말해 call 명령어 뒤에 어떤 메모리 주소를 넣어야 할지 알 수 없습니다. 따라서 이 시점에는 일단 다음과 같이 간단하게 0x00으로 지정하여 호출한다는 사실만 기록해 둡니다.
call 0x00
이렇게 컴파일러가 떠넘긴 부분은 이제 링커가 채워야 합니다. 그렇다면 링커는 이 call 명령어를 찾아서 뒤의 0x00을 해당 함수가 최종적으로 실행되는 시점의 메모리 주소로 변경해야 한다는 것을 어떻게 알 수 있을까요?
다행히 컴파이러도 링커가 오늘 하루를 좀 더 즐겁게 보낼 수 있도록 약간의 단서를 남겨 두었습니다. 즉, 메모리 주소를 확정할 수 없는 변수를 발견할 때마다, .relo.text에는 해당 명령어를 저장하고 .relo.data에는 해당 명령어와 관련된 데이터를 저장합니다. 이제 대상 파일은 그림 1-29와 같이 더 많은 내용을 담게 됩니다.

예를 들어 foo 함수의 경우, 컴파일러는 call 명령어를 생성하면서 .relo.texxt에 다음 메시지를 기록합니다. '코드 영역(code segment)의 시작 주소(start address) 기준 오프셋(offset)이 60바이트인 위치에서 foo 심벌을 발견했지만, 실행 시에 어떤 주소에서 실행해야 할지 알 수 없습니다. 따라서 링커인 여러분께서 실행 파일을 생성할 때 이 명령어를 수정해야 합니다.'
- 64~65p
대상 파일에서 각 유형의 영역이 모두 결합되면 모든 기계 명령어와 전역 변수가 프로그램 실행 시간에 위치할 메모리 주소를 결정할 수 있습니다. 이제 foo 함수의 실행 시간 메모리 주소가 0x4004d6이라는 것을 알 수 있습니다.
이어서 링커는 각 대상 파일의 .relo.text 영역(segment)을 하나씩 읽어 기계 명령어를 수정해야 하는 foo라는 심벌이 있으며, 이 심벌의 코드 영역 시작 주소 기준 오프셋이 60바이트라는 것을 확인합니다. 링커는 이렇게 확인한 정보를 이용하여 그림 1-31과 같이 실행 파일에서 해당 call 명령어를 정확히 찾고, 이동할 소스 주소를 0x00에서 0x4004d6으로 수정할 수 있습니다.
- 66p
가상 메모리와 프로그램 메모리 구조
모든 프로그램은 실행된 후 코드 영역이 예외 없이 메모리 주소 0x400000에서 시작합니다. 뭔가 이상하지 않나요? 두 프로그램 A와 B가 동시에 실행중이라고 가정할 때, CPU가 메모리 주소 0x400000에서 가져오는 기계 명령어는 프로그램 A의 코드일까요, 아니면 프로그램 B의 코드일까요?
이 문제에 대한 답이 떠올랐나요?
정답은 CPU가 프로그램 A를 실행할 때 메모리 주소 0x400000에서 가져온 명령어는 프로그램 A에 속하고, 프로그램 B를 실행할 때 메모리 주소 0x400000에서 가져온 명령어는 프로그램 B에 속한다는 것입니다. 둘 다 메모리 주소 0x400000에서 가져온 것이지만 그 데이터는 서로 동일하지 않습니다. 신기하지 않나요? 도대체 어떻게 이런 일이 가능할까요?
이렇게 마법 같은 일을 가능하게 하는 것은 바로 운영 체제의 가상 메모리 기술입니다.
가상 메모리는 말 그대로 물리적으로 존재하지 않는 가짜 메모리입니다. 가상 메모리는 각각의 프로그램이 실행 줄일 때, 자기 자신이 모든 메모리를 모두 독점적으로 사용하고 있는 것처럼 착각하게 만듭니다. 예를 들어 32비트 시스템에서는 실제로 시스템에 설치된 물리적 메모리가 얼마가 되었든 자신이 2^32바이트, 즉 4GB 메모리를 독점하고 있다고 생각합니다.
따라서 그림 1-32의 모습은 실제 물리 메모리의 형상이 아닌 논리로만 존재하는 허상일 뿐입니다. 이는 마치 우리가 파일을 연속적으로 읽고 있다고 생각하지만, 실제로는 그 데이터가 디스크 전체에 무작위로 흩어져 있는 것과 마찬가지입니다.
- 68p
하지만 결국에는 데이터와 명령어가 물리 메모리에 저장되어야 합니다. 그렇다면 CPU가 프로그램 A를 실행하여 메모리 주소 0x400000에 접근할 때, 실제로 명령어를 꺼내는 물리 메모리 주소는 어떻게 찾아야 할까요?
실행 파일을 실행하려면 물리 메모리에 적재되어야 한다는 것은 이미 알고 있습니다. 실행 파일의 코드 영역이 물리 메모리 주소 0x80ef0000에 적재된다고 가정하면, 시스템에는 다음과 같은 사상 관계가 추가 됩니다.
가상 메모리 물리 메모리
0x400000 0x80ef0000
- 모든 프로세스의 가상 메모리는 표준화되어 있고 크기가 동일합니다. 프로세스마다 각 영역의 크기가 다를 수는 있지만 영역이 배치되는 순서는 동일합니다.
- 실제 물리 메모리의 크기는 가상 메모리의 크기와는 무관하며 물리 메모리에는 힙 영역, 스택 영역 등 영역 구분조차 존재하지 않습니다. 단, 운영 제체마다 이는 조금씩 다를 수 있습니다.
- 모든 프로세스는 자신만의 페이지 테이블을 가지고 있으며, 같은 가상 메모리 주소라도 페이지 테이블을 확인하여 서로 다른 물리 메모리 주소를 획득합니다. 이런 이유로 CPU는 동일한 가상 메모리 주소에서 서로 다른 내용을 가져올 수 있습니다.
- 69~70p
링크는 실행 파일로 대표되는 컴파일 시간과 프로세스로 대표되는 실행 시간 사이를 이어 주는 핵심적인 다리로, 최신 운영 체제 설계에서 매우 중요하고 흥미로운 부분인 가상 메모리의 비밀을 품고 있습니다. 이 점을 제대로 이해해야만 프로그램이 실행되는 방식도 명확하게 이해할 수 있습니다.
- 71p
시스템 설계와 추상화
컴퓨터 시스템은 기본적으로 추상화라는 기반 위에 구축됩니다.
CPU를 이야기해 봅시다. CPU의 하드웨어는 트랜지스터 여러 개로 구성되어 있지만, 명령어 집합(instruction set)이라는 개념으로 내부 구현 세부 사항을 보호합니다. 따라서 프로그래머는 트랜지스터의 세부 사항은 전혀 고려할 필요 없이 명령에 집합에 포함된 기계 명령어를 사용 하여 CPU에 작업을 지시하기만 하면 됩니다. 그리고 기계 명령어에 대한 추상화 계층(abstract layer)은 다시 1.1절에서 언급했던 고급 프로그래밍 언어로 이어집니다. 따라서 고급 언어로 프로그래밍하는 프로그래머는 기계 명령어의 세부 사항에 신경 쓸 필요가 없으며, 고급 언어를 이 용하여 CPU를 ‘직접’ 제어할 수 있기 때문에 프로그래밍의 질적 효율성이 크게 높아집니다.
입출력(input/output) 장치는 피일(file)로 추상화되어 있습니디. 따라서 파일을 사용할 때 파일 내용이 정확히 어떻게 저장되는지, 다시 말해 어느 트랙(track)의 어느 섹터(sector)에 정확히 저장되는지 등 세부 사항은 전혀 신경 쓸 필요가 없습니다.
실행 중인 프로그램은 프로세스로 추상화됩니다. 프로그래머는 프로그램을 작성할 때 자신의 프로그램이 CPU를 독점한다고 가정할 수 있기 때문에 단일 CPU 시스템에서도 수많은 프로세스가 동시에 실행될 수 있습니다.
물리 메모리와 파일은 가상 메모리로 추상화됩니다. 프로그래머는 물리 메모리의 크기가 서로 다른 경우에도 자신의 프로그램이 표준적이고 동일한 크기의 메모리에 독점적으로 접근할 수 있다고 가정할 수 있습니다. 또 mmap 작동 방식을 이용하여 가상 메모리를 사용하더라도 실제 메모리를 읽고 쓰는 것처럼 쉽게 파일을 조작할 수 있습니다.
네트워크 프로그래밍(network programming)은 소켓(socket)으로 추상화됩니다. 프로그래머는 네트워크 패킷(packet)이 계층별로 어떻게 해석되는지, 네트워크 카드가 어떻게 데이터를 송수신하는지 전혀 신경 쓸 필요가 없습니다.
프로세스와 프로세스에 종속적인 실행 환경은 컨테이너(container) 추상화됩니다. 프로그래머는 더 이상 개발 환경과 실제 배포 환경의 차이를 걱정할 필요가 없습니다. 프로그래머가 가장 선호하는 ‘제 환경에서는 잘 동작하는데요.' 같은 ‘책임 떠넘기기’ 기술은 이제 공식적으로 역사의 뒤안길로 사라졌습니다. CPU, 운영 쳬제, 응용 프로그램(application)은 가상 머신으로 묶여(packaging) 추상화됩니다. 프로그래머는 더 이상 예전처럼 여러 가지 하드웨어를 구입하여 직접 운영 체제를 설치하고 프로그램을 구성하고 서버 환경을 운영할 필요가 없습니다. 가상 머신은 일종의 데이터로서 빠르게 복제가 가능하기 때문에 프로그래머는 이제 한 손으로 수많은 서버를 운영하고 유지하고 관리할 수 있습니다. 이런 모습은 이전에는 상상조차 할 수 없었지만, 이것은 현재 한창 불타오르고 있는 클라우드 컴퓨팅을 지원하고 있는 기술이기도 합니다.
추상화는 프로그래머를 저수준 계층에서 점점 더 멀어지게 만들고, 점점 더 저수준 계층의 세부 사항도 신경 쓸 필요가 없도록 만듭니다. 또 프로그래밍의 문턱도 점점 더 낮추어 컴퓨터 기초가 전혀 없는 사람도 며칠 동안 간단한 학습만으로도 괜찮은 프로그램을 작성하게 해 줍니다. 이것이 추상화의 위력입니다. 하지만 정말로 프로그래머가 저수준 계층에 관심을 가질 필요가 전혀 없을까요?
- 72~73p
2
모든 것은 CPU에서 시작된다
CPU는 사실 스레드, 프로세스, 운영 체제 가은 개념을 전혀 알지 못합니다.
CPU는 단지 두 가지 사항만 알고 있습니다.
- 메모리에서 명령어(instruction)를 하나 가져옵니다(dispatch).
- 이 명령어를 실행(executue)한 후 다시 1.로 돌아갑니다.
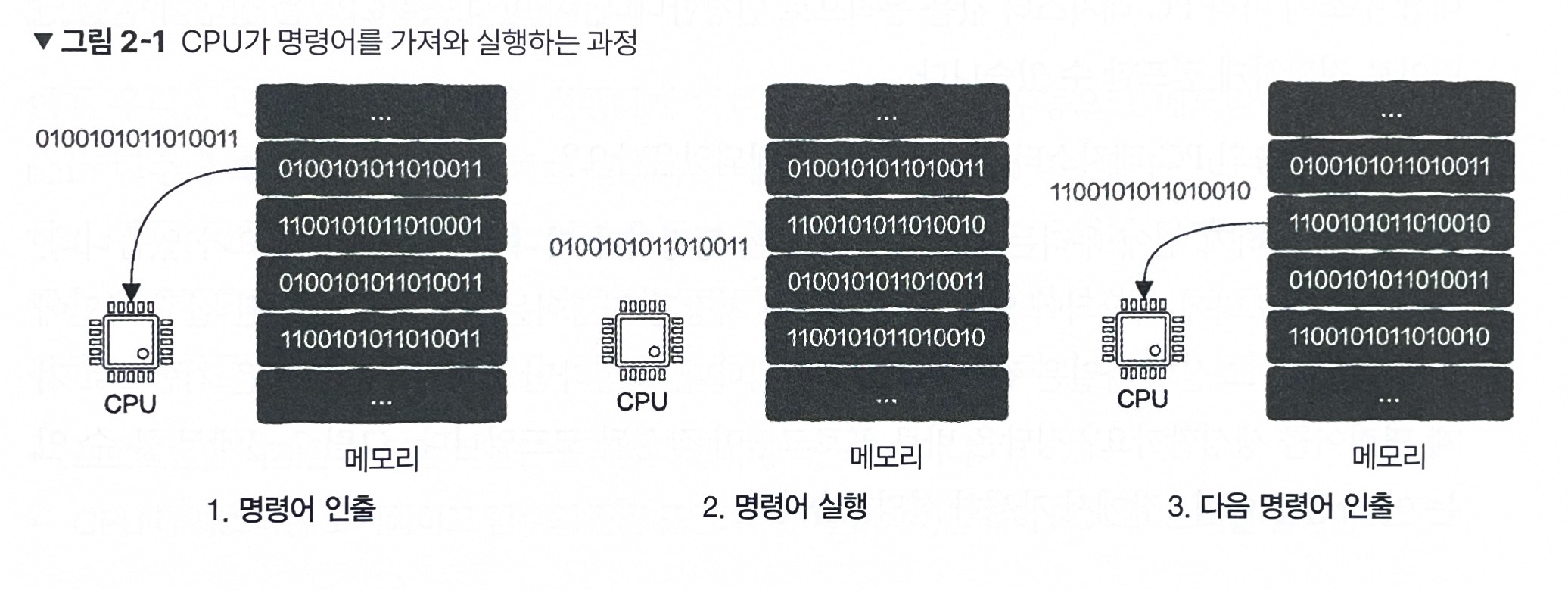
- 76 ~ 77p
그렇다면 최초의 PC 레지스터 값은 어떻게 설정되었을까요?
이 질문에 답하기 전에 우리는 CPU가 실행하는 명령어가 어디서 오는지 알 필요가 있습니다. 명령어는 메모리에 저장되어 있는데, 메모리에 저장된 명령어는 디스크에 저장된 실행 파일에서 적재되고, 그 실행 파일은 컴파일러로 생성됩니다.
그렇다면 컴파일러는 무엇을 기반으로 기계 명령어를 생성할까요? 정답은 바로 프로그램이 작성된 코드입니다.

우리가 작성하는 프로그램에는 반드시 시작 지점이 있어야 하는데, 여러분이 잘 알고 있는 main 함수가 바로 그것입니다. 프로그램이 시작되면 먼저 main 함수에 대응하는 첫 번째 기계 명령어를 찾고, 이어서 그 메모리 주소를 PC 레지스터에 기록합니다.
- 77p
CPU에서 운영 체제까지
CPU는 한 번에 한 가지 일만 할 수 있습니다. 따라서 프로그램 A의 기계 명령어를 실행하거나 프로그램 B의 기계 명령어를 실행하는 것 중 하나만 할 수 있습니다. 그렇다면 프로그램 A와 프로그램 B가 동시에 실행되는 것처럼 보이게 하는 방법은 없을까요?
이는 매우 간단합니다. CPU는 먼저 프로그램 A를 실행했다가 이를 잠시 중지하고 프로그램 B의 실행으로 넘어갑니다. 그리고 프로그램 B를 실행했다가 이를 잠시 중지하고 다시 프로그램 A의 실행으로 돌아갈 수 있습니다. 이때 CPU의 전환 빈도가 충분히 빠르다면 그림 2-4와 같이 프로그랜 A와 프로그랜 B가 '동시에 실행'되는 것처럼 보입니다.
- 80p
여기에서 관건은 어떻게 하면 프로그램을 일시 중지했다가 다시 시작하느냐 하는 것입니다. 이는 물고기를 급속 냉동했다가 해동하면 다시 깨이나 헤엄치는 것에 비유할 수 있습니다. 물론 좋은 비유이기는 하지만, 문제를 해결하는 데 큰 도움은 되지 않습니다. 여러분은 고민하다가 농구 경기를 떠올립니다.
농구 경기도 타임 아웃으로 일시 중지할 수 있습니다. 일시 중지하는 동안 모든 플레이어는 자신이 어디에 있는지와 누가 공을 가지고 있는지, 게임 시간이 얼마나 남았는지를 기억합니다. 이후 게임이 재개되면 모든 플레이어는 자신의 위치로 돌아가고 심판에게 공을 넘겨받으면 게임 시간은 다시 흘러갑니다. 농구 경기를 일시 중지했다가 다시 재개할 때 중요한 점은 게임이 일시 중지되었을 때 상태가 유지되고, 그 유지되었던 상태를 이용하여 다시 경기를 재개한다는 것입니다. 지금 우리에게 필요한 것이 바로 이런 작동 방식입니다.
이때 저장되는 상태를 상황 정보(context)라고 합니다. 프로그램 실행 역시 농구 경기와 비슷합니다. CPU가 어떤 기계 명령어를 실행했는지와 CPU 내부의 기타 레지스터 값 등 상태 값이 있습니다. 이 정보를 저장할 수 있다면 프로그램을 일시 중지했다가도 저장된 상황 정보를 이용하여 마치 물고기를 해동하듯 프로그램 실행을 재개할 수 있습니다. 이런 아이디어가 떠오른 여러분은 다음과 같이 프로그램 실행 상대를 저장하고 복구할 때 사용할 구조쳬(structure)를 정의하는 코드를 직접 작정하기 시작합니다.
struct ***
{
context cts; // CPU의 상황 정보 저장
...
}
실행 중인 모든 프로그램은 필요한 정보를 기록할 수 있는 이런 형태의 구조쳬를 가지고 있어야 합니다. 이제 '이해 불가능' 원칙에 따라 이 구조체에 듣기에 매우 신비한 프로세스라는 이름을 붙입니다.
이렇게 프로세스가 탄생했습니다. 이제 모든 프로그램은 실행된 후 프로세스 형태로 관리됩니다.
프로세스를 사용하면 모든 프로세스를 원하는 대로 일시중지하거나 다시 시작할 수 있습니다. 따라서 CPU가 프로세스 사이를 충분히 빠르게 전환하는 한, CPU가 하나뿐인 시스템에서도 수많은 프로세스를 동시에 실행하거나 적어도 동시에 실행 중인 것처럼 보이게 할 수 있습니다. 이렇게 가장 간단하고 정상적으로 동작하는 기본 멀티태스킹 기능을 구현했습니다.
- 80~81p
프로세스에서 스레드로 진화
CPU 여러 개가 한 지붕 아래에 있는 것과 마찬가지로 공유 프로세스 주소 공간에서 동일한 프로세스에 속한 명령어를 동시에 실행할 수 있습니다. 다시 말해 하나의 프로세스 안에 여러 실행 흐름이 존재할 수 있습니다.
실행 흐름이라는 용어는 너무 이해하기 쉬우니 다시 한 번 '이해 불가능' 원칙을 적용해서 여기에 이해하기 힘든 스레드라는 이름을 붙였습니다.
이거이 바로 스레드가 탄생한 배경입니다.
- 86p
여기에서는 스레드 두 개를 생성하고, 먼저 funcA와 funcB를 각각 구분해서 실행합니다. 그리고 그 결과를 전역 변수인 resA와 resB에 저장하고, 마지막으로 이 값을 서로 더하는 방식으로 funcA와 funcB를 동시에 스레드 두 개에서 실행할 수 있습니다. 앞의 경우처럼 두 함수의 실행 시간이 각각 3분과 4분이라고 가정합니다. 또 이상적인 상황에서 이 스레드 두 개가 CPU 코어 두 개에서 동시에 실행된다고 가정하면, 전체 프로그램의 실행 시간은 더 오래 실행되는 함수에 따라 달라지므로 4분이 걸립니다.
여기에서는 두 값을 더하는 과정에서 프로세스 간 통신이 일어나지 않았다는 점에 주목할 필요가 있습니다. 심지어 스레드 사이에는 근본적으로 통신이라는 개념이 존재하지 않는데, 이는 resA 변수와 resB 변수가 다중 프로세스 프로그래밍 때처럼 더 이상 서로 다른 주소 공간이 아닌 동일한 프로세스 주소 공간에 속해 있기 때문입니다. 이 경우 동일한 프로세스 내에 있는 모든 스레드는 이 변수들을 직접 사용할 수 있습니다. 이것은 스레드가 자신이 속해 있는 프로세 스의 주소 공간을 공유한다는 의미이며, 이는 스레드가 프로세스보다 훨씬 가볍고 생성 속도가 빠른 이유이기도 합니다. 이런 이유로 스레드를 경량 프로세스(light weight Process)라고도 합니다.

- 87p
다중 스레드와 메모리 구조
함수가 실행될 때 필요한 정보에는 함수의 매개변수(parameter), 지역 변수, 반환 주소(return address) 등이 있습니다. 이런 정보는 대응하는 스택 프레임(stack frame)에 저장되며, 모든 함수는 실행 시에 자신만의 실행 시간 스택 프레임(runtime stack frame)을 가집니다. 함수가 호출되고 반환될 때마다 이 스택 프레임은 후입선출(last in first out) 순서로 증가하거나 감소하며, 이런 스택 프레임의 증감이 프로세스 주소 공간에서 스택 영역을 형성합니다.
- 88p
이 스레드라는 개념이 존재하기 전에는 프로세스 내에 실행 흐름은 단 하나만 존재했었고, 스택 영역도 하나만 있었습니다. 하지만 스레드가 있는 경우에는 어떻게 될까요?
스레드를 사용한 이래 하나의 프로세스에실행 진입점(execution entry point)이 여럿 존재할 수 있게 되었고, 동시에 실행 흐름도 여러 개 존재할 수 있게 되었습니다. 실행 흐름이 하나뿐인 프로세스는 실행 시 정보를 저장하는 스택 영역이 하나만 있으면 됩니다. 확실한 점은 실행 흐름 여러 개를 가지는 프로세스는 각 흐름이 실행될 때 정보를 저장하기 위해 스택 영역이 여러 개 필요하다는 것입니다. 또 프로세스의 주소 공간에 각 스레드를 위한 스택 영역이 별도로 있어야 합니다. 즉 모든 스레드는 각자 자신만의 스택 영역을 가지는데, 스레드가 이를 인지하고 있는 것이 매우 중요합니다.

스레드 활용 예
아마 여러분은 서버가 하나의 요청을 받으면 해당 작업을 처리하는 스레드를 생성하고 처리가 완료되면 스레드를 종료하면 된다고 간단하게 생각할지도 모르겠습니다. 이 방법은 일반적으로 요청당 스레드(thred-per-request)라고 합니다. 이는 요청이 들어올 때마다 매번 스레드가 생성된다는 의미로, 긴 작업 대상으로는 매우 잘 동작합니다. 하지만 대량의 짧은 작업에서는 구현이 간단한 장점이 있는 동시에 다음 몇 가지 단점이 있습니다.
- 스레드의 생성과 종료에 많은 시간을 허비합니다.
- 스레드마다 각자 독립적인 스택 영역이 필요한데 많은 수의 스레드를 생성하면 메모리와 기타 시스템 리소스를 너무많이 소비하게 됩니다.
- 스레드 수가 많으면 스레드 간 전환에 따른 부담이 증가합니다.
이는 여러분이 공장의 사장이고, 주문이 매우 많은 상황에 비유할 수 있습니다. 주문 하나가 새로 추가될 때마다 새로운 근로자를 고용한다고생각해 봅시다. 제품 생산 과정이 매우 간단하고 짧기 때문에 근로자는 주문을 빠르게 처리할 수 있습니다. 주문 처리가 완료되면 천신만고 끝에 고용한 근로자를 금방 해고하고, 새로운 주문이 들어오면 어렵사리 또 다른 근로자를 고용합니다. 이처럼 일하는 시간은 단 5분이지만 고용에 드는 시간은 10시간이므로, 한 번 근로자를 고용한 후 써먹고 나면 바로 해고하는 대신 주문이 들어오면 주문을 처리하고 없을 때는 모두 휴식하는 것이 훨씬 더 나은 전략입니다.
이거이 바로 스레드 풀(thread pool)이 탄생하게 된 이유입니다.
- 89~90p
스레드 풀의 동작 방식
이제 스레드는 생성되어 있지만, 이런 작업을 어떻게 스레드 풀 내에 있는 스레드에 전달해야 할까요?
너무나 당연하게도 이런 시나리오에 적합한 것은 자료 구조의 대기열(queue)입니다. 여기에서 작업을 전달하는 것은 생산자(producer)이며, 작업을 처리하는 스레드는 소비자입니다.
- 91p
본질적으로 스레드 풀에 전달되는 작업은 처리할 데이터와 데이터를 처리하는 함수 두 부분으로 구성되며, 이는 다음과 같이 정의할 수 있습니다.
struct task
{
void* data; // 작업이 처리할 데이터
hadler handle; // 데이터 처리 함수
}
먼저 스레드 풀의 스레드는 작업 대기열(jobs queue)에서 블로킹 상태로 대기합니다. 생산자가 작업 대기열에 데이터를 기록하면 스레드 풀의 스레드가 깨어나고, 깨어난 스레드는 작업 대기열에서 앞서 정의한 구조체를 가져온 후 구조체의 handler이 가리키는 처리 함수(handler functioin)를 실행합니다.
while (true)
{
struct task = GetFromQueue(); // 작업 대기열에서 데이터 꺼내기
task -> hanlder(task->data); // 데이터 처리
} - 92p
스레드 풀의 스레드 수
CPU 집약적인 작업이란 과학 연산, 행렬 연산 등 작업을 처리할 때 외부 입출력에 의존할 필요 없이 처리할 수 있는 작업을 의미합니다. 이 경우 스레드 수와 CPU의 코어 수가 기본적으로 동일하다면 CPU의 리소스를 충분히 활용할 수 있습니다.
- 93p
입출력 집약적인 작업이란 연산 부분이 차지하는 시간은 많지 않은 대신 대부분의 시간을 디스크 입출력이나 네트워크 입출력 등에 소비하는 작업을 의미합니다. 이 경우 필요한 스레드 수의 계산은 좀 더 복잡한데, 성능 테스트 도구를 사용하여 WT(Wait Time)라는 입출력 대기 시간과 CT(Computing Time)라는 CPU 연산에 필요한 시간을 평가해야 합니다. N개의 코어를 가진 시스템에서 적절한 스레드 수는 대략 N x (1+WT ÷CT)이며, WT와 CT가 동일하다고 가정하면 대략 2N개의 스레드가 있어야 CPU 리소스를 최대한 활용할 수 있습니다. 하지만 이는 이론 적인 값에 불과하며, 일반적으로 입출력에 소요되는 시간을 평가하는 것은 쉬운 일이 아닙니다. 여기에서는 실제 상황을 기반으로 테스트를 실시하여 필요한 스레드 수를 결정하길 추천합니다.
여기에서 볼 수 있듯이, 스레드 수를 결정하는 절대 공식은 없으며, 이를 위해서는 구쳬적인 상황과 그에 대한 분석이 필요합니다.
- 93p
코드 영역: 모든 함수를 스레드에 배치하여 실행할 수 있다
코드 영역은 스레드 간에 공유되므로 어떤 함수든지 모두 스레드에 적재하여 실행할 수 있고, 특정 함수를 특정 스레드에서만 실행되도록 하는 것은 불가능합니다. 이런 관점에서 볼 때, 이 영역은 모든 스레드가 공유하는 영역입니다.
여기에서 한 가지 주의할 점은 코드 영역은 읽기 전용(read-only)이기 때문에 프로그램이 실행되는 동안에는 어떤 스레드도 코드 영역 내용을 변경할 수 없다는 것입니다. 이는 프로그램의 올바른 실행을 위해 당연한 것입니다. 따라서 프로세스 내 모든 스레드가 코드 영역을 공유하고 있지만, 코드 영역에 관해서는 스레드 안전 문제(thread safety issue)가 발생하지 않습니다.
- 97p
데이터 영역: 모든 스레드가 데이터 영역의 변수에 접근할 수 있다
데이터 영역은 전역 변수가 저장되는 곳입니다.
- 97p
프로그램이 실행되는 동안 데이터 영역 내에 전역 변수의 인스턴스는 하나만 있기 때문에 모든 스레드는 이 전역 변수에 접근할 수 있습니다. 다시 말해 어떤 스레드가 이 전역 변수 값을 변경하면 이후 다른 스레드에서 이 전역 변수 값을 확인해도 변경된 상태라는 의미입니다.
- 98p
힙 영역: 포인터가 핵심이다
힙 영역은 프로그래머에게는 비교적 친숙한 영역으로, C/C++ 언어에서 mallo 함수와 new 예약어로 요청하는 메모리가 이 영역에 할당됩니다. 물론 모든 스레드는 해당 변수 주소만 알고 있다면, 다시 말해 포인터(pointer)를 얻을 수 있다면 포인터가 가리키는 데이터에 접근할 수 있습니다. 따라서 힙 영역은 그림 2-17과 같이 스레드 간 공유 간 리소스이기도 합니다.
- 98~99p
스택 영역: 공유 공간 내 전용 데이터
비록 스택 영역은 스레드 전용 데이터에 속하지만, 스택 영역에는 별도의 보호를 위한 작동 방식이 존재하지 안기 때문에 다른 스레드에서 특정 스레드의 스택 영역을 볼 수 있다는 것을 알았습니다. 다시 말해 스레드 여러 개가 하나의 프로세스에 속하는 경우에는 하나의 스레드가 다른 스레드의 스택 영역이라고 하더라도 모두 데이터를 읽고 쓸 수 있습니다.
- 101p
동적 링크 라이브러리와 파일
프로그램이 동작 중에 특정 파일을 열면 프로세스 주소 공간에 열린 파일 정보도 저장됩니다. 프로세스가 연 팡리 정보는 모두 스레드에서 사용할 수 있으며, 이것 역시 스레드 간 공유 리소스에 속합니다.
- 103p
스레드 전용 저장소
스레드 전용 저장소에 저장되는 변수는 다음과 같은 두 가지 의미가 있습니다.
- 이 영역에 저장된 변수는 모든 스레드에서 접근할 수 있습니다.
- 모든 스레드가 동일한 변수에 접근하는 것처럼 보일 수 있지만, 사실 변수의 인스턴스는 각각의 스레드에 속합니다. 따라서 하나의 스레드에서 변수 값을 변경해도 다른 스레드에는 반영되지 않습니다.
__thread int a = 1; // 스레드 전용 저장소
전역 변수 a 앞에 __thread라는 수식어가 붙는데, 이는 컴파일러가 전역 변수 a를 스레드 전용 저장소에 넣도록 지시하는 것입니다.
이렇게 스레드 전용 저장소를 사용하면 각각의 스레드에서 독점적으로 변수를 사용할 수 있습니다.
- 103~ 105p
스레드 안전이란 무엇일까?
어떤 코드가 주어졌을 때, 그 코드가 스레드 몇 개에서 호출되든 이 스레드들이 어떤 순서로 호출되든 간에 상관없이 올바른 결과가 나온다면, 이 코드를 스레드 안전이라고 말합니다.
- 108p
스레드 전용 리소스만 사용하기
int func() {
int a = 1;
int b = 1;
return a +b;
}이 함수는 어떤 전역 변수나 매개변수에 의존하지 않고 오로지 스레드 전용 리소스인 지역 변수만 사용한느데, 이런 변수는 그림 2-24와 같이 실행된 후 스레드의 스택 영역에서 관리합니다. 이런 코드를 무상태 함수라고도 하며, 이런 코드가 스레드 안전이라는 것은 분명합니다.
- 110p
스레드 전용 리소스와 함수 매개변수
함수 매개변수를 값으로 전달(call by value)하는 경우라면 문제없으며, 이 코드는 여전히 스레드 안전입니다.
int func(int num){
num++;
return num;
}하지만 포인터를 전달하면 상황은 달라집니다.
스레드 두 개가 func 함수를 호출할 때 전달하는 포인터가 힙 영역에 저장된 동일한 변수를 가리키고 있다면, 해당 변수는 이 두 스레드가 공유하는 리소스로 간주됩니다. 따라서 잠금 등으로 보호되지 않는 한 func 함수는 여전히 스레드 안전이 아닙니다.
- 111~113p
전역 변수 사용
만약 사용되는 전역 변수가 처음 프로그램일 실행될 때 한 번 초기화되고 나서 모든 코드가 이 변수를 읽기만 한다면 문제없습니다.
- 114p
스레드 전용 저장소
전역 변수를 정의하는 global_num =100; 앞에 __thread가 추가되었습니다. 이 시점에서 func 함수는 다시 스레드 안전이 됩니다.

- 116p
스레드 안전 코드는 어떻게 구현할까?
- 스레드 전용 저장소
- 읽기 전용
- 원자성 연산
- 동기화 시 상호 배제
일반 함수에서 코루틴으로
def func():
print("a")
일시 중지 및 반환
print("b")
일시 중지 및 반환
print("c")func 함수가 코루틴에서 실행 중이라면, func 함수는 print("a") 실행 후 '일시 중지 및 반환' 코드와 함께 호출한 함수로 반환됩니다.
어째서 이것이 신기하냐고 물을 수도 있습니다. return 명령어 한 줄이면 역시 반환이 가능하니까요.
직접 return 명령어를 작성해도 분명히 반환되기는 하지만, 이 경우에는 return 명령어 이후 코드를 실행할 방법이 전혀 없습니다.
코루틴은 자신의 실행 상태를 저장할 수 있기 때문에 코루틴이 반환된 후에도 계속 호출이 가능하며, 더군가나 마지막으로 일시 중지된 지점에서 다시 이어서 실행된다는 점이 놀랍습니다.
- 123p
파이썬에서는 이 '멈춰라'는 단어와 같은 의미로 yield라는 예약어를 사용합니다. 이제 func 함수는 다음과 같이 바뀝니다.
def func():
print("a")
yeild
print("b")
yeild
print("c")
func 함수는 더 이상 간단한 함수가 아니라 코루틴으로 업그레이드되었습니다. 그럼 이 코루틴을 어떻게 사용해야 할까요?
def A():
co = func() # 코루틴 획득
next(co) # 코루틴 호출
print("in function A") # 작업 실행
next(co) # 코루틴 재호출
이어지는 다섯 번째 줄이 핵심입니다. 코루틴이 다시 호출되면 어떤 내용이 출력될까요?
func가 일반 함수라면 func의 첫 줄이 실행되기 때문에 a가 출력될 것입니다.
하지만 func는 일반 함수가 아닌 코루틴이며, 코루틴은 일시 중지되었던 지점에서 계속 실행됩니다. 따라서 여기에서 실행되어야 하는 것은 첫 번째 yield 이후의 코드인 print("b")입니다.
- 124~125p
함수는 그저 코루틴의 특별한 예에 불과하다
기시감이 들 것입니다. 운영 체제가 스레드를 스케줄링하는 것과 똑같지 않나요? 스레드도 일시 중지될 수 있으며, 운영 체제가 먼저 스레드의 실행 상태를 저장했다가 다른 스레드의 스케줄링을 진행합니다. 그리고 일시 중지된 스레드가 다시 CPU의 리소스를 하당받으면 스레드는 마치 일시 중지된 적이 없는 것처럼 이어서 실행합니다.
컴퓨터 시스템은 주기적으로 타이머 인터럽트를 생성하고, 인터럽트가 처리될 때마다 운영 체제는 현재 스레드의 일시 중지 여부를 결정할 기회를 가집니다. 이것이 바로 프로그래머가 명시적으로 스레드를 언제 일시 중지시키고 CPU의 리소스를 내어 줄지 지정할 필요가 없는 이유입니다. 그러나 사용자 상태에서는 타이머 인터럽트를 위한 작동 방식이 없기 때문에 여러분은 코루틴에서 반드시 yiled와 같은 예약어를 사용하여 어디에서 일시 중지하고 CPU의 리소스를 내어 줄 것인지 명시적으로 지정해야합니다.
- 127p
코루틴은 어떻게 구현될까
코루틴의 구현은 사실 스레드의 구현과 본질적으로 차이가 없습니다.
코루틴은 일시 중지되거나 다시 시작될 수 있으며, 일시 중지될 때의 상태 정보를 반드시 기록해야 합니다. 이를 기반으로 코루틴을 다시 시작해야 합니다.
상태 정보에는 CPU의 레지스터 정보, 함수 실행 시 상태 정보가 포함됩니다.
- 129p
이런 의문이 들 수도 있습니다. 그렇다면 프로세스 주소 공간의 최상단에 있는 스택 영역의 역할은 무엇인가요?
스택 영역은 여전히 함수 스택 프레임을 보관하는 데 사용됩니다. 단지 이 함수들이 코루틴이 아닌 일반 함수라는 차이가 있습니다.
- 130p
우리에게 왜 코루틴과 같은 기술이 필요하며 어떤 문제를 해결하는 데 도움을 줄 수 있을까요?
답을 먼저 제시하면, 코루틴의 중요한 역할 중 하나는 바로 프로그래머가 동기 방식으로 비동기 프로그래밍을 가능하게 한다는 것입니다.
- 130p
모든 것은 다음 요구에서 시작된다
이전처럼 이런 시긍로 코드를 작성한다면, 프로그램 안에는 else if 문이 수천 개 필요할 뿐만 아니라, 새로운 현지화 요청이 있을 때마다 make_donut 함수를 수정해야 합니다. 이것은 명백히 매우 잘못된 설계입니다. 그렇다면 이 문제는 어떻게 해결해야 할까요?
- 134p
콜백이 필요한 이유
함수를 변수처럼 사용할 수도 있습니다.
이제 make_donut 함수를 새롭게 수정해 봅시다.
void make_donut(func f){
...
f();
...
}
이렇게 하면 B 팀은 더 이상 서로 다른 도넛 현지화 요구에 맞추어서 코드를 계속 바꿀 필요가 없습니다. 이제 make_donut 함수를 사용하고 싶은 프로그래머는 자신이 정의한 현지화 함수를 전달만 하면 되므로 함수 변수로 한 번에 문제를 해결할 수 있었습니다.
예를 들어 C 팀에 자체적인 도넛 형성 함수인 formed_C가 있다고 하면 다음과 같이 make_donut 함수를 사용할 수 있습니다.
void formed_C(){
...
}
make_donut(formed_C);
함수 변수라는 이름은 너무 이해하기 쉬우므로 '이해 불가능'원칙에 따라 이 함수 변수를 앞으로는 콜백 함수라고 부르겠습니다.
여기에서 볼 수 있듯이, 일반적으로 콜백 함수 코드는 여러분이 직접 구현합니다. 그러나 그 함수를 호출하는 것은 여러분 자신이 아닙니다. 보통은 다른 모듈이나 스레드에서 해당 함수를 호출하게 됩니다.
- 134 ~ 135p
비동기 콜백은 새로운 프로그래밍 사고방식으로 이어진다
정보 관점에서 보면, 함수는 사실 홓출자가 정보를 채워 넣기 전까지는 매객 변수 정보가 무엇인지 알 수 없습니다. 컴퓨터 관점에서 보면, 정보에는 두 가지 유형이 있습니다. 첫 번째 유형은 정수, 포인터, 구조체, 객체 등 데이터이며, 두 번째 유형은 함수 같은 코드입니다.
따라서 프로그래머가 함수를 호출할 때 데이터 형태의 일반적인 변수 외에 코드로 된 함수 형태의 변수도 전달할 수 있습니다. 그렇기 때문에 handle 함수를 직접 호출하는 대신 다음과 같이 해당 함수를 request 함수의 매개변수로 전닳할 수 있습니다.
request(handle);
우리는 handle 함수가 언제 호출될지는 아예 신경쓸 필요가 없으며, 이는 request 함수가 신경 써야 하는 부분입니다.
다시 비동기화를 이야기해 보겠습니다.
앞서 언급했던 함수 호출이 비동기 콜백이라면 request 함수는 즉시 반환될 수 있으며, 실제로 결과를 받아 처리하는 프로세스는 다른 스레드와 프로세스, 심지어는 다른 시스템에서 완료될 수 있습니다.
이것이 바로 그림 2-38에서 볼 수 있는 비동기 호출입니다.

프로그래밍 관점에서 보면, 비동기 호출과 동기 호출은 매우 큰 차이가 있습니다. 처리 흐름을 하나의 작업으로 생각할 때, 동기 호출 프로그래밍 방식에서는 함수를 호출한 스레드에서 전체 작업이 처리되는 데 반해 비동기 호출 프로그래밍 방식에서는 작업 처리가 두 부분으로 나뉩니다.
- 첫 번째 부분음 함수를 호출하는 스레드에서 처리됩니다. 즉, request가 호출되기 전에 해당하는 부분입니다.
- 두 번째 부분은 함수를 호춣하는 스레드에서 처리되지 않고 다른 스레드, 프로세스 또는 다른 시스템에서 처리됩니다.
- 137~139p
콜백 함수의 정의
컴퓨터 과학에서 콜백 함수는 다른 코드에 매개변수로 전달되는 실행 가능한 코드입니다.
이것이 콜백 함수의 정의입니다. 콜백 함수는 실행 가능한 코드인 함수로서 일반적인 다른 함수와 다르지 않습니다.
- 140p
콜백 함수와 주 프로그램은 같은 계층에 있지만 우리는 해당 콜백 함수를 작성할 책임만 있을 뿐 직접 호출하지는 않는다는 것입니다.
마지막으로 콜백 함수가 호출되는 시점을 알아보겠습니다. 일반적으로 시스템에서 네트워크 데이터 수신이나 파일 전송 완료처럼 관심 대상인 이벤트가 발생하면 이를 처리할 수 있는 코드를 호출하고 싶을 것입니다. 이때는 콜백 함수가 유용하며, 특정 이벤트에 대응하는 콜백 함수를 등록할 수 있습니다. 시스템에서 이벤트가 발생하면 상응하는 콜백 함수가 자동으로 호출되며. 이 관점에서 보면 콜백 함수는 이벤트 처리 도구(event handler)이기에 콜백 함수는 이벤트 중심 프로그래밍에 적합합니다.
- 140~141p
블로킹과 논블로킹
함수 A와 함수 B가 있다고 가정해 봅시다. 함수 A가 함수 B를 호출할 때, 함수 B를 호출함과 동시에 운영체제가 함수 A가 실행 중인 스레드나 프로세스를 일시 중지시킨다면 함수 B에 대한 호출 방식은 블로킹 방식이며, 그렇지 않다면 논블로킹 방식입니다.

- 160p
논블로킹과 비동기 입출력
데이터를 수신하는 함수인 recv가 논블로킹이면 이 함수를 호출할 때 운영체제는 스레드를 일시 중지시키는 대신 recv 함수를 즉시 반환합니다. 이후 호출 스레드는 자신의 작업을 계신 진행하며, 데이터 수신 작업은 커널이 처리합니다. 그림 2-59에서 볼 수 있듯이 이 두가지 작업은 병행 처리됩니다.

- 163~164p
피자 주문에 비유하기
블로킹 호출은 피자 가게에 직접 가서 피자를 주문하는 것에 비유할 수 있습니다. 여러분은 피자가 완성될 때까지 가게 안에서 기다리고 있어야 합니다. 이는 여러분이 피자를 주문했기 때문에 '블로킹'된 것으로 볼 수 있으며, 피자가 완성되어야만 그 피자를 들고 가서 다른 일을 할 수 있습니다.
반면에 논블로킹 호출은 전화로 피자를 주문하는 것에 비유할 수 있습니다. 전화로 피자를 주문한 후 현관문 앞에서 하염없이 피자를 기다리는 사람은 아무도 없습니다. 여러분은 피자가 오기 전까지 다른 일을 할 수 있는 것이죠. 이렇게 전화 주문 방식으로 피자를 주문하는 것이 바로 논블로킹 호출입니다.
논 블로킹 호출 상황에서는 피자가 완성되었는지 어떻게 알 수 있을까요? 여러분 인내심에 따라 두 가지 상황이 있을 수 있습니다.
- 매우 인내심이 강한 경우: 여러분은 피자가 언제 완성되는지, 언제 배달이 도착하는지 전혀 관심이 없습니다. 어찌 되었든 배달이 도착하면 전화가 올 것이기 때문에 여러분은 할 일을 하고 있으면 됩니다. 여기에서 여러분과 피자를 굽는 작업은 비동기입니다.
- 인내심이 부족한 경우: 여러분은 5분마다 전화를 걸어 피자가 완성되었는지 물어봅니다. 물론 5분 마다 전화는 해야 하지만, 여전히 여러분은 할 일을 할 수 있습니다. 이때 여러분과 피자를 굽는 작업은 여전히 비동기입니다. 인내심 부족을 넘어 아예 인내심이 없다면 어떨까요? 5분마다 전화를 걸어 피자가 완성되었는지 묻고, 5분마다 전홯하는 일을 제외하고는 아무것도 하지 않는다면요? 이제 여러분과 피자를 굽는 작업은 더 이상 비동기가 아닌 동기가 되어 버립니다. 그림 2-60에서 볼 수 있듯이, 논블로킹이 반드시 비동기를 의미하지 않습니다.
- 164~165p
동기와 블로킹
동기 호출은 반드시 블로킹이 아닌 반면에 블로킹 호출은 모두 확실한 동기 호출입니다.
int sum(int a, int b){
return a+b;
}
여기에서 sum 함수에 대한 호출은 동기이지만, funcA 함수가 sum 함수를 호출했다고 해서 블로킹되거나 스레드가 일시 중지되지는 않습니다. 반면에 어떤 함수가 블로킹 방식으로 호출된 경우 반드시 동기 호출이라는 것은 더 말할 필요도 없는 사실입니다.
- 166p
비동기와 논블로킹
void handler(void *buf){
// 수신된 네트워크 데이터를 처리합니다
...
}
while (true) {
fd = accept();
recv(fc, buf, NON_BLOCKING_FLAG, hanlder); // 호출 후 바로 반환, 논블로킹
}
이제 recv 함수는 논블로킹 호출이므로, 네트워크 데이터를 처리해 주는 hanlder 함수를 recv 함수에 콜백으로 전달해야 합니다. 따라서 앞의 코드는 비동기이자 논블로킹입니다.
그러나 시스템이 네트워크 데이터의 도착을 감지하는 전용 함수인 check 함수를 제공한다면, 이제 코드를 다음과 같이 변경할 수 있습니다.
while (true) {
fd = accept();
recv(fc, buf, NON_BLOCKING_FLAG); // 호출 후 바로 반환, 논블로킹
while(!check(fd)){
// 순환 감지
}
handler(buf);
}
여기에서도 recv 함수는 논블로킹으로 호출되지만, while 반복문에서 끊임없이 감지를 시도하여 데이터가 도착하기 전까지는 handler 함수를 사용할 수 없게 합니다. 따라서 recv 함수는 비록 논블로킹이지만, 전체적인 관점에서 보면 이 코드는 동기입니다.
- 166~167p
이벤트 순환과 이벤트 구동
이벤트 기반 프로그래밍 기술에는 두 가지 요소가 필요합니다.
- 이벤트: 계속해서 이벤트 기반이라고 말해왔듯이 이벤트는 당연히 필요합니다. 이 절에서는 주로 서버를 다루고 있기 때문에 여기에서 말하는 이벤트는 대부분 입출력에 관계된 것입니다. 예를 들어 네트워크 데이터의 수신 여부, 파일의 읽기 쓰기 가능 여부 등이 관심 대상인 이벤트에 해당합니다.
- 이벤트를 처리하는 함수: 이 함수를 일반적으로 이벤트 핸들러(event hanlder)라고 합니다.
- 172p
이벤트 순환에서 수행해야 하는 작업은 사실 매우 간단합니다. 이벤트가 도착할 때까지 기다렸다가 대응하는 이벤트 핸들러를 호출하면 됩니다.
이 정도면 꽤 괜찮아 보이지만, 해결해야 할 두 가지 문제가 남아 있습니다.
- 이벤트 소스에 관한 문제입니다. 앞의 의사 코드에 있는 getEvent 같은 함수 하나로 어떻게 여러 이벤트를 가져올 수 있을까요?
- 이벤트를 처리하는 handler 함수가 반드시 이벤트 순환과 동일한 스레드에서 실행되어야 할까요?
- 173p
첫 번째 문제: 이벤트 소스와 입출력 다중화
각 서술자를 무턱대로 순차적으로 처리하는 것은 좋은 생각이 아닙니다. 더 나은 접근 방식은 운영 체제에 다음 내용을 전달하는 작동 방식을 사용하는 것입니다. '저 대신 소켓 서술자 열 개를 감시하고 있다가, 데이터가 들어오면 저에게 알려주세요.' 이런 작동 방식을 입출력 다중화라고 하며, 이와 같은 작동 방식 중 리눅스 세계에서 제일 유명한 것이 바로 epoll입니다.
- 174p
두번째 문제: 이벤트 순환과 다중 스레드
이제 이벤트 핸들러는 더 이상 이벤트 순환과 동일한 스레드에서 실행되지 않고 그림 2-67과 같이 독립적인 스레드에 배치됩니다. 여기에서는 작업자 스레드(worker thread) 네 개와 이벤트 순환 스레드(event loop thread) 한 개가 생성되어 있는데, 이벤트 순환은 요청을 수신하면 간단한 처리 후 바로 각각의 작업자 스레드에 분배할 수 있습니다. 다중 스레드를 이용한 병행 실행은 시스템의 다중 코어를 최대한 활용하여 요청 처리를 가속화합니다. 물론 이 작업자 스레드를 스레드 풀(thread pool)로 구현하는 것도 가능합니다.
이런 설계 방법에는 반응자 패턴(reactor pattern)이라는 이름이 붙어 있습니다.
- 176p
이벤트 순환과 입출력
- 입출력 작업에 대응하는 논블로킹 인터페이스가 있는 경우: 이때는 직접 논블로킹 인터페이스를 호출해도 스레드가 일시 중지되지 않으며, 인터페이스가 즉시 반환되므로 이벤트 순환에서 직접 호출하는 것이 가능합니다.
- 입출력 작업에 블로킹 인터페이스만 있는 경우: 이때는 이벤트 순환 내에서 절대로 어떤 블로킹 인터페이스도 호출하면 안 된다는 것을 반드시 알아 두어야 합니다. 그렇지 않으면 이벤트 순환 스레드가 일시 중지될 수 있으며, 이는 당연하게도 이벤트 순환이라는 엔진이 멈추는 것에 해당하기 때문에 전체 시스템이 모두 앞으로 나아갈 수 없게 됩니다.

- 177p
코루틴: 동기 방식의 비동기 프로그래밍
실제로 프로그래밍 언어나 프레임워크가 코루틴을 지원하는 경우 그림 2-70과 같이 handler 함수가 코루틴에서 실행되도록 할 수 있습니다.
A
B
GetUserInfo();
C;
D;
GetQueryInfo();
E;
F;
GetStorkInfo();
G;
H;
hanlder 함수의 코드 구현은 여전히 동기로 작성됩니다. 하지만 yield로 CPU 제어권을 반환하는 등 RPC 통신이 시작된 후 적극적으로 바로 호출된다는 점은 다릅니다. 이때 RPC 호출 함수 또는 네트워크 데이터 전송 함수를 수정해야 yield로 CPU 제어권을 반환할 수 있다는 점을 기억하세요. 여기에서 가장 중요한 점은 코루틴이 일시 중지되더라도 작업자 스레드가 블로킹되지 않는다는 것입니다. 이것이 코루틴과 스레드를 사용하는 블로킹 호출의 가장 큰 차이점 입니다.
코루틴이 일시 중지되면 작업자 스레드는 준비 완료된 다른 코루틴을 실행하기 위해 전환되며, 일시 중지된 코루틴에 할당된 사용자 서비스가 응답한 후 그 처리 결과를 반환하면 다시 준비 상태가 되어 스케줄링 차례가 돌아오길 기다립니다. 이후 코루틴은 마지막으로 중지되었던 곳에서 이어서 계속 실행됩니다.
- 182p
CPU, 스레드, 코루틴
CPU는 많이 이야기할 필요가 없을 것입니다. CPU는 기계 명령어를 실행하여 컴퓨터를 움직이게 합니다. 스레드는 일반적으로 커널 상태 스레드라고도 하며, 커널로 생성되고 스케줄링을 합니다. 이때 커널은 스레드 우선순위에 따라 CPU 연산 리소스를 할당합니다. 반면에 코루틴은 커널 입장에서는 알 수 없는 요소로, 코루틴이 얼마나 많이 생성되었든 커널은 이와 관계없이 스레드에 따라 CPU 시간을 할당합니다. 프로그래머는 스레드에 할당된 시간 내 실행할 코루틴을 결정할 수 있는데, 이는 본질적으로 그림 2-74와 같이 스레드에 할당된 CPU 시간을 사용자 상태에서 재차 할당하는 것에 해당합니다. 이 할당은 사용자 상태에서 발생하므로 코루틴을 사용자 상태 스레드라고도 합니다.

- 185p
3
메모리의 본질은 무엇일까? 사물함, 비트, 바이트, 객체
프로그래밍 언어에서 사용되는 개념이 간단하든 복잡하든 상관없이 사물함에 저장되는 것은 0 또는 1뿐이며, 모든 개념은 사실 우리가 해석하기 나름입니다. 여러분은 8비트를 1바이트로 생각할 수도 있고 4바이트를 정수로 생각할 수도 있으며, 연속된 메모리를 이용하여 구조체나 객체를 저장할 수도 있습니다. 하지만 메모리는 이것에 전혀 관심이 없으며, 메모리 안에 저장된 것은 어찌 되었든 모두 0 또는 1뿐입니다. 메모리 내 사물함에는 0 또는 1만 저장할 수 있으며, 이것은 우리가 컴퓨터가 0과 1만 이해할 수 있다고 이야기하는 이유이기도 합니다.
- 198p
변수에서 포인터로
고급 언어에서 포인터는 하나의 변수에 불과합니다. 단지 이 변수가 저장하기에 적합한 것이 메모리 주소일 뿐입니다. 포인터는 메모리 주소를 더 높은 수준으로 추상화한 것입니다.
- 204p
포인터에서 참조로: 메모리 주소 감추기
만약 태진이 지금 북위 37.5519, 동경 126.9918라는 구체적인 곳에 위치해 있을 때, 모든 사람이 태진을 이야기하면서 호칭을 사용하는 대신 '북위 37.5519, 동경 126.9918에 있는 그 사람'이라고 말했다면 해당 위치가 곧 포인터가 됩니다.
이와 마찬가지 원리로 포인터를 지원하는 대신 참조라는 개념을 제공하는 프로그래밍 언어에서 참조를 사용할 때는 변수의 구체적인 메모리 주소를 얻을 수 없으며, 참조는 포인터와 유사한 구조의 산술 연산을 할 수 없습니다. 예를 들어 앞서 언급했던 경위도 기반의 위치를 알고 있다면 경도를 동쪽으로 조금 더하고 위도를 북쪽으로 조금 빼는 간단한 산술 연산으로 각 위치에 있는 사람들을 볼 수 있습니다. 이와 마찬가지로 메모리 위치에 값을 더하거나 빼면 각각의 메모리 주소에 저장되어 있는 데이터를 볼 수 있지만, 참조에는 이런 기능이 없기 때문에 '태진'이라는 이 참조에 1을 더하거나 1을 빼는 것은 아무런 의미가 없습니다.
참조를 사용하면 데이터를 복사할 필요가 없기 때문에 포인터를 사용할 때와 동일한 효과를 얻을 수 있습니다. 여러분과 그녀의 가족이 '태진'이라는 참조에 대해 이야기할 때, 실제로 태진을 옆에 앚혀 놓고 가리키며 이야기할 필요는 없습니다. 따라서 대부분의 경우 포인터가 없더라도 사실상 동일하게 프로그래밍하는 것이 가능함을 알 수 있습니다.
간단히 요약하면, 포인터는 메모리 주소를 추상화한 것이고 참조는 포인터를 한 번 더 추상화한 것이라고 할 수 있습니다.
- 209p
함수 점프와 반환은 어떻게 구현될까?
함수 A가 함수 B를 호출하면, 제어권이 함수 A에서 함수 B로 옮겨집니다. 여기에서 제어권은 실제로 CPU가 어떤 함수에 속하는 기계 명령어를 실행하는지 의미합니다. CPU가 함수 A의 명령어를 실행하다가 함수 B의 명령어로 점프하는 것을 제어권이 함수 A에서 함수 B로 이전되었다고 이야기합니다.
제어권이 이전될 때는 다음 두 가지 정보가 필요합니다.
- 반환(return): 어디에서 왔는지에 대한 정보
- 점프(jump): 어디로 가는지에 대한 정보
- 219p
힙 영역이 필요한 이유
그렇다면 특정 데이터를 여러 함수에 걸쳐 사용해야 한다면 어떻게 해야 할까요? 누군가는 전역 변수를 사용하라고 할 수도 있지만 전역 변수는 모든 모듈에 노출되어 있으며, 때로는 데이터를 모든 모듈에 노출하고 싶지 않을 때도 있을 것입니다. 당연히 이런 종류의 데이터는 프로그래머가 직접 관리하는 특정 메모리 영역에 저장해야 하며, 프로그래머는 이런 메모리 영역을 언제 요청할지와 데이터를 저장하는 데 얼마나 많은 메모리 영역을 요청할지 직접 결정해야 합니다. 이 메모리는 함수의 호출 횟수와 관계없이 프로그래머가 해당 메모리 영역의 사용이 완료되었다고 확신할 때까지 유효하게 유지됩니다. 이후 해당 메모리는 무효화되며, 이 과정을 동적 메모리 할당과 해제라고 합니다.
이와 같은 이유로 메모리 수명 주기에는 프그래머가 완전히 직접 제어할 수 있는 매우 큰 메모리 영역이 필요하며, 이 영역을 바로 힙 영역(heap segment)이라고 합니다.
- 229p
메모리 할당의 전체 이야기
우리가 malloc을 호출하여 메모리를 호출하면 다음 일이 일어납니다.
- malloc이 여유 메모리 조각을 검색하기 시작하고 적절한 크기의 조각을 찾으면 이를 할당합니다.
- malloc이 적절한 여유 메모리를 찾지 못하면 brk 같은 시스템 호출을 통해 힙 영역을 확장하여 더 많은 여유 메모리를 얻습니다.
- malloc이 brk를 호출하면 커널 상태로 전환되는데 이때 운영 체제의 가상 메모리 시스템이 힙 영역을 확장하는 작업을 시작합니다. 주의할 점은 이렇게 확장된 메모리 영역은 가상 메모리에 불과하며, 운영 체제는 아직 실제 물리 메모리를 할당하지 않았을 수 있다는 것입니다.
- brk 실행이 종료되면 malloc으로 제어권이 돌아가며 CPU도 커널 상태에서 사용자 상태로 전환됩니다. malloc은 이제 적절한 여유 메모리 조각을 찾아 반환합니다.
- 우리 프로그램은 메모리를 성공적으로 요청했기 때문에 계속 다음 단계를 실행합니다.
- 코드가 새로 요청된 메모리를 읽거나 쓰면 그림 3-68과 같이 시스템 내에서 페이지 누락 인터럽트 (page fault interrupt)가 발생합니다. 이때 CPU는 다시 사용자 상태에서 커널 상태로 전환되며, 운영 제제가 실제 물리 메모리를 할당하기 시작합니다. 페이지 테이블 내 가상 메모리와 실제 물리 메모리의 사상 관계가 설정된 후, CPU는 다시 커널 상태에서 사용자 상태로 돌아가고 다음 처리로 넘어갑니다.
- 257p
약간 더 복잡한 메모리 풀 구현하기
여러 크기의 메모리를 할당하려면, 당연하게도 여유 메모리 조각을 관리할 필요가 있습니다. 따라서 그림 3-73과 같이 먼저 모든 메모리 조각을 연결 리스트로 연결하고 포인터를 사용하여 현재 여유 메모리 조각의 위치를 기록할 수 있습니다.

- 261~262p
메모리 풀의 스레드 안전 문제
메모리 풀에 직접 잠금 보호를 적용하면 되지 않느냐고 단순하게 생각할 수도 있습니다. 메모리 풀에 잠금 보호를 적용한다면 그림 3-75와 같은 형태가 될 것입니다.

이 방법은 스레드 풀이 올바르게 작동하는 것을 보장합니다. 하지만 프로그램에서 대량의 스레드가 메모리 할당과 해제를 요청하면 이 방식은 잠금 경쟁이 매우 격렬해질 수 있습니다. 시스템 성능이 저하될 수 있기 때문에 더 나은 방법이 있어야만 합니다.
잠금을 추가하면 성능 문제가 따라올 수 있으므로, 각 스레드마다 메모리 풀을 유지하여 스레드 간 경챙 문제를 근본적으로 해결하면 좋습니다.
각 스레드에 대한 메모리 풀은 어떻게 유지할 수 있을까요? 이때는 2장에서 언급한 '스레드 전용 저장소(thread local storage)'가 유용하게 쓰입니다. 그림 3-76과 같이 스레드 풀을 스레드 전용 저장소에 넣을 수 있으며, 이렇게 하면 각 스레드가 자신에게 속한 스레드 풀만 사용할 수 있습니다.

스레드 전용 저장소를 사용하면 매우 흥미로운 문제가 하나 발생합니다. 스레드 A가 메모리 조각을 요청했지만 그 수명 주기가 스레드 A 자체를 넘어서는 상황을 가정해봅시다. 즉, 스레드 A의 실행이 완료된 후에도 다른 스레드에서 해당 메모리를 계속 사용한다면, 해당 메모리는 스레드 A에 속해 있음에도 스레드 B에서 이를 해제해야 합니다. 이를 어떻게 해결할 수 있을까요?
- 236~264p
왜 SSD는 메모리로 사용할 수 없을까?
메모리의 주소 지정 단위는 바이트입니다. 즉, 각 바이트마다 메모리 주소가 부여되어 있고, CPU가 이 주소를 이용하여 해당 내용에 직접 접근할 수 있다는 것을 의미합니다. 하지만 SSD는 그렇지 않습니다. 앞의 실험에서도 알 수 있듯이 사실 SSD는 조각 단위로 데이터를 관리하며, 이 조각 크기는 매우 다양합니다. 여기에서 중요한 점은 CPU가 파일의 특정 바이트에 직접 접근할 수 있는 방법이 없다는 것입니다. 다시 말해 바이트 단위 주소 지정이 지원되지 않는다는 의미입니다. 그림 3-88과 같이 메모리는 바이트 단위로, 디스크는 조각 단위로 주소가 지정됩니다.
- 277p
4.
도는 하나를 낳고, 하나는 둘을 낳고, 둘은 셋을 낳으며, 셋은 만물을 낳는다
가장 놀라운 것은 다음과 같습니다. 여러분이 만든 회로 세 개는 의외로 특성이 매우 매혹적인데 바로 논리곱 게이트, 논리합 게이트, 논리부정 게이트로 모든 논리 함수를 표현할 수 있다는 것입니다. 그리고 놀랍게도 이것을 논리적 완전성이라고 합니다.
다시 말해 충분한 논리곱 게이트, 논리합 게이트, 논리 부정 게이트가 있으면 어떤 논리 함수도 구현할 수 있습니다. 그 외에는 어떤 형태의 논리 게이트 회로도 필요하지 않습니다.
- 284p
신기한 기억 능력
D 단자가 0이면 전체 회로가 저장하는 것은 0이며, 그렇지 않으면 1이 됩니다. 그리고 이것이 바로 우리가 원하는 것입니다. 이제 1비트를 저장하기가 훨씬 편해졌습니다. 앞의 회로가 바로 이 1비트를 저장할 수 있는 사물함입니다.
- 287p
하드웨어 아니면 소프트웨어? 범용장치
모든 연산 논리를 반드시 회로 같은 하드웨어로 구현할 필요는 없습니다. 하드웨어는 가장 기본적인 기능만 제공하고 모든 연산 논리는 이런 가장 기본적인 기능을 이용하여 소프트웨어로 표현하는 것이 좋은 방법입니다. 이것이 소프트웨어라는 단어의 기원입니다. 하드웨어는 변하지 않지만 소프트웨어는 변할 수 있기에 변하지 않는 하드웨어에 서로 다른 소프트웨어를 제공하면 하드웨어가 완전히 새로운 기능을 구현할 수 있습니다.
- 289p
회로에는 지휘자가 필요하다.
회로는 많은 부분으로 구성되어 있는데, 일부는 데이터를 계산하는 데 사용되고 일부는 정보를 저장하는 데 사용됩니다. 가장 간단한 덧셈인 1 + 1을 계산한다고 가정해 봅시다. 계산에 필요한 두 숫자는 각각 레지스터 R1과 레지스터 R2에 저장되어야 합니다. 레지스터는 어떤 값이든 저장할 수 있는데, 가산기가 작동을 시작할 때 레지스터 R1과 레지스터 R2가 반드시 1을 저장하도록 어떻게 보장할 수 있을까요?
다시 말해 각 부분의 회로가 함께 작업할 수 있도록 조정하거나 동기화하려면 어떻게 해야 할까요?
CPU에서 지휘자 역할을 맡고 있는 것이 클럭 신호(clock signal)입니다.
이제 클럭 주파수(clock rate)가 무엇을 의미하는지 알아야겠죠? 클럭 주파수는 1초 동안 지휘봉을 몇 번 흔드는가를 의미하며, 클럭 주파수가 높을수록 CPU가 1초에 더 많은 작업을 할 수 있음은 자명합니다.
- 292p
프로세스 관리와 스케줄링
우리는 프로그램이 메모리에서 실행되면 프로세스 형태로 존재하고, 프로세스가 생성되면 운영체제가 관리하고 스케줄링한다는 것을 알고 있습니다. 그렇다면 운영 체제는 프로세스를 어떻게 관리할까요?
프로세스 스케줄링은 운영 체제가 구현해야 하는 핵심 기능 중 하나입니다.
- 295~296p
유휴 프로세스와 CPU의 저전력 상태
스케줄링 가능한 프로세스가 더 이상 존재하지 않으면 스케줄러가 유휴 프로세스를 실행하는데, 이것으로 순환 구조에서 계속 halt 명령어가 실행됩니다. 이 halt 명령어로 그림 4-13과 같이 CPU는 저전력 상태로 진입하기 시작합니다.
while(1){
while (!need_resched()){
cpuidle_idle_call();
}
}
정리하자면, 컴퓨터 시스템이 유휴 상태일 때 CPU가 하는 일은 바로 이와 같으며 그것은 사실 halt 명령어를 실행하는 것입니다. 실제로 컴퓨터 입장에서는 CPU가 가장 많이 실행하는 명령어는 halt 명령어일 것입니다.
- 298~299p
무한 순환 탈출: 인터럽트
앞서 설명했던 순환은 while(1) 같은 무한 순환 구조인데, 내부에는 break 문도 없고 return 문도 없습니다. 그럼 운영 체제는 어떻게 이 순환을 빠져나올까요?
- 299p
원래 컴퓨터 운영 체제는 일정 시간마다 타이머 인터럽트를 생성하고, CPU는 인터럽트 신호를 감지하고, 운영 체제 내부의 인터럽트 처리 프로그램을 실행합니다. 상응하는 인터럽트 처리 함수에서는 프로세스가 실행될 준비가 되었는지 판단하고, 준비가 되었다면 중단되었던 프로세스를 계속 실행합니다. 준비되어 있지 않았다면 프로세스를 일시 중지시키고, 스케줄러는 준비 완료 상태인 프로세스를 스케줄링합니다.
- 299p
양수에 음수 기호를 붙이면 바로 대응하는 음수: 부호-크기 표현
이 설계 방식은 매우 간단합니다. 0010이 +2를 의미하므로 최상위 비트를 1로 바꾸기만 한 1010은 대응하는 음수인 -2가 됩니다.
- 302p
부호-크기 표현의 반전: 1의 보수
0010이 +2를 의미하니까, 이를 완전히 반전시킨 1101을 -2로 표시하면 되지 않을까요?
이 방법을 일컬어 1의 보수라고 합니다.
- 303~304p
컴퓨터 친화적 표현 방식: 2의 보수
핵심은 A + (-A) = 0을 가능하게 하면서 동시에 0을 표현할 때 2진법에서 0000이라는 표현 한가지만 존재하는 표현 방법이 필요하다는 것입니다.
A = 2라고 가정하고 2+ (-2) = 0(0000)이 되는 표현 방법을 중점적으로 연구해 봅시다.
먼저 양수 2는 간단합니다. 이 수를 2진법으로 표현하면 0010입니다. 하지만 -2에 대해서는 아직 최상위 비트가 1이라는 것만 확정 지을 수 있습니다. 이제 이를 표현하면 다음과 같습니다.
0010
+1???
----
0000
이 수식은 -2가 1110인 경우 올바르며, 이때 2 + (-2)는 실제로 0이 됩니다. 이것에서 다른 음수의 2진법 표현을 추론해 낼 수 있습니다.
이런 숫자 표현 방식이 바로 현대 컴퓨터 시스템에서 사용되는 2의 보수입니다.
- 305~306p
if가 파이프라인을 만나면
프로그래머가 작성한 if 문은 일반적으로 컴파일러가 조건부 점프 명령어로 변환하며, 이 명령어는 분기 역할을 합니다. 조건이 참이면 점프해야 하고, 그렇지 않으면 순차적으로 실행됩니다. 하지만 조건부 점프 명령어를 실행하기 전까지는 우리가 점프해야 할지 알 수 없으며, 이는 파이프라인에 영향을 미칩니다. 도대체 어떤 영향을 미칠까요?
자동차 조립 라인을 자세히 관찰해 보면, 그림 4-21과 같이 앞쪽 자동차 제작이 완료되기 전에 이미 다음 자동차가 조립 라인에 들어가 있는 것을 알 수 있습니다.
CPU에도 마찬가지 방식이 적용됩니다. 분기 점프 명령어가 실행을 완료하기 전에 다음 명령어는 이미 파이프라인에 들어가 있어야 하는데, 그렇지 않으면 파이프라인에 '빈 공간'이 생겨 프로세스의 리소스를 완전하게 사용할 수 없기 때문입니다. 이때 문제가 발생합니다.
그림 4-22와 같이 분기 점프 명령어는 자신의 실행 결과에 따라 점프 여부를 결정해야 하는데, 이 명령어 실행이 완료되지 않은 시점에 CPU는 어떤 분기의 명령어를 파이프라인에 넣어야 할지 어떻게 알 수 있을까요?

사실 CPU 역시 이를 알지 못한다면 어떻게 해야 할까요? 답은 매우 간단합니다. 미리 예측을 하는 것이죠.
- 314~315p
분기 예측: 가능한 한 CPU가 올바르게 추측하도록
CPU는 뒤이어 어디로 분기할 가능성이 있는지 추측합니다. 추측이 맞았다면 파이프라인은 계속 앞으로 흘러갈 것입니다. 추측이 틀렸다면 안타깝게도 파이프라인에서 이미 실행 중이던 잘못된 분기 명령어 전부를 무효화합니다. 여기에서 알 수 있듯이, CPU 추측이 틀리면 바로 성능 손실이 발생합니다.
최신 CPU의 이런 '추측' 과정을 분기 예측이라고 합니다. 물론 이 예측은 동전 던지기처럼 간단하지 않으며, 프로그램 실행 이력을 기반으로 예측을 실행하는 등 여러 가지 데이터를 기반으로 합니다.
- 315p
레시피와 코드, 볶음 요리와 스레드
레시피에 따라 돼지고기를 볶으면 돼지 두루치기 스레드가 되는 것이고, 소시지와 야채를 볶으면 소시지 야채 볶음 스레드가 되는 것입니다.
요리사 수는 CPU 코어 수에 비유할 수 있으며, 일정 시간 동안 볶을 수 있는 요리 수는 스레드 수에 비유할 수 있습니다. 여러분은 요리사 수가 동시에 얼마나 많은 요리를 할 수 있는지 여부와 관련이 있다고 생각하나요 ?
물론 그렇지 않습니다. CPU 코어 수와 스레드 수 사이에는 어떤 필연 관계도 없습니다. CPU는 하드웨어인데 반해 스레드는 소프트웨어 개념, 더 정확하게는 실행 흐름이자 작업입니다. 따라서 단일 코어 시스템에서도 얼마든지 많은 스레드를 생성할 수 있습니다. 물론 메모리가 충분하고 운영체제에 제한이 없어야 합니다.
CPU는 근본적으로 자신이 실행하는 명령어가 어떤 스레드에 속하는지 이해하지 못하며, 사실 CPU 입장에서도 이를 이해할 필요가 없습니다. 이를 이해해야 하는 것은 운영 체제입니다. CPU가 해야 하는 일은 그림 4-26과 같이 PC 레지스터 주소에 따라 메모리에서 기계 명령어를 꺼내 실행하는 것뿐입니다. PC 레지스터는 자료에 따라 다른 이름일 수 있지만, 다음에 실행할 기계 명령어를 가리키는 역할을 한다는 것은 동일합니다.
- 318p
작업 분할과 블로킹 입출력
작업 A와 작업 B 두 작업이 있고 각 작업이 완료되는 데 필요한 시간이 각각 5분이라고 가정해 봅시다. 작업 A와 작업 B를 연속으로 실행하든 스레드 두 개에 담아 병렬로 실행하든 간에 단일 코어 환경에서 두 작ㅇ버을 완료하는 데 필요한 시간은 동일하게 10분입니다. 단일 코어 시스템에서 CPU는 일정 시간 동안 단 하나의 스레드만 실행할 수 있어 스레드 여러 개가 번갈아 실행되기는 하지만, 진정한 병렬 처리라고는 할 수 없습니다.
- 319p
다중 코어와 다중 스레드
다중 프로세스도 다중 코어를 최대한 활용할 수 있지만 다중 프로세스 프로그래밍은 매우 번거롭습니다. 여기에는 더 복잡한 프로세스 간 통신 방식이 필요하며, 프로세스 간 전환에 드는 비용과 같은 문제가 있습니다. 스레드 개념이 이런 문제에 대한 좋은 해결책이 되면서 다중 코어 시대의 주인공이 되었습니다. 다중 코어 리소스를 최대한 활용해야 할 때 프로그래머가 가장 선호하는 도구는 스레드입니다.
- 320p
다중 코어를 최대한 활용해야 한다면 시스템에 코어가 몇 개 있는지 알고 있어야 합니다. 일반적으로 생성되는 스레드 수는 코어 수와 일정한 선형 관계를 유지해야 합니다.
특히 스레드는 많다고 좋은 것이 아님을 잊지 말아야 합니다.
여러분 스레드가 순수하게 계산을 위한 것이고 입출력이나 동기화 같은 작업이 없다면, 코어당 스레드 하나가 가장 나은 선택입니다. 그러나 스레드에는 일정한 입출력과 동기화 등이 필요하므로 이때는 스레드 수를 적당히 늘려 운영 체제가 CPU에 할당할 수 있는 충분한 스레드를 확보하면 시스템 성능을 향상시킬 수 있습니다. 하지만 스레드 수가 한계에 달하면 운영 체제 성능이 떨어지기 시작하는데, 이는 한 스레드에서 다른 스레드로 전화할 때 부담이 증가하기 때문입니다.
여기에서 적당하다는 단어를 쓴 것은 단순히 수치화하기가 어렵고 실제로 프로그램을 사용하여 상황에 따라 지속적으로 테스트해야만 값을 얻을 수 있기 때문입니다.
- 321p
오늘날의 컴퓨터는 기본적으로 폰 노이만 구조를 따릅니다. 이 구조의 핵심 사상은 '저장 개념에서 프로그램과 프로그램이 사용하는 데이터에 어떤 차이도 없어야 하며, 모두 컴퓨터의 저장 장치 안에 저장될 수 있어야 한다'는 것입니다.
- 324p
필연적인 복잡 명령어 집합의 탄생
대부분의 명령어에 포함된 연산을 더 간단한 명령어로 구성된 작은 프로그램으로 정의하고 이를 CPU에 저장하면, 모든 기계 명령어에 대응하여 전용 하드웨어 회로를 설계할 필요가 없습니다. 즉, 소프트웨어가 하드웨어를 대체하게 되는 것입니다. 여기에서 사용되는 더 간단한 명령어가 바로 마이크로코드입니다.
더 많은 명령어를 추가할 때, 주요 작업은 마이크로코드 수정에 집중되며 하드웨어 수정은 거의 필요하지 않기에 CPU 설계 복잡도를 낮출 수 있습니다.
- 326p
명령어 파이프라인
복잡 명령어 집합에서는 명령어 사이에 비교적 차이가 크기에 실행 시간이 고르지 않습니다. 따라서 기계 명령어를 효율적으로 실행하기 위해 파이프라인 방식을 제대로 활용할 방법이 없습니다. 앞으로 4.8절에서는 복잡 명령어 집합이 이 문제를 해결하는 방법도 살펴볼 것입니다.
1세대 축소 명령어 집합 프로세서는 전체가 파이프라인 기반으로 설계되어 일반적으로 5단계 파이프라인을 기준으로 명령어 하나가 1~2클럭 주기로 실행됩니다. 반면에 동시대의 복잡 명령어 집합 프로세서는 명령어 하나를 실행하는 데 5~10클럭 주기가 필요합니다. 축소 명령어 집합 구조에서 컴파일된 프로그램에는 더 많은 명령어가 필요합니다. 하지만 축소 명령어 집합의 간소화된 설계는 마이크로코드가 없기 때문에 더 적은 트랜지스터가 필요하며, 더 작은 CPU를 만들 수 있습니다. 또 더 높은 클럭 주파수를 가지게 되어 축소 명령어 집합 구조의 CPU는 동일한 작업을 할 때 복잡 명령어 집합 구조보다 훨씬 우수합니다.
파이프라인 기술의 축복 덕분에 축소 명령어 집합으로 설계된 CPU는 성능 면에서 복잡 명령어 집합으로 설계된 상대를 쓸어버리기 시작했습니다.
- 335p
하이퍼스레딩이라는 필살기
복잡 명령에 집합 진영은 복잡 명령에 집합을 축소 명령에 집합처럼 보이게 하는 것 외에 또 다른 기술을 추가로 개발했는데, 바로 하이퍼스레딩(hyper-threading)입니다. 하이퍼스레딩은 하드웨어 스레드(hardware thread)라고도 하는데, 사실 기술적으로는 하드웨어 스레드가 더 적합한 표현이라고 생각합니다. 그러나 대부분의 자료에서는 하이퍼스레딩을 사용하므로 여기에서도 하이퍼스레딩이라는 표현을 사용하겠습니다. 지금까지는 그림 4-36과 같이 CPU가 한 번에 한 가지 일만 할 수 있다고 간단하게 간주할 수 있었습니다.
사각형은 각각 기계 명령에 하나를 나타내며, 이것으로 CPU가 한 번에 하나의 스레드에 속한 기계 명령어만 실행할 수 있다는 것을 알 수 있습니다. 시스템에 N개의 CPU 코어가 있다면 운영 체제는 N개의 준비 완료 상태인 스레드를 N개의 CPU 코어에 할당해서 동시에 실행할 수 있습니다.
하지만 하이퍼스레딩을 사용하면 하이퍼스레딩 기능이 탑재된 하나의 물리 CPU 코어는 운영 쳬제에 환각을 심어 주게 되는데, 실제로는 컴퓨터 시스템에 물리 CPU 코어가 하나만 있지만 운영 체제는 논리적으로 CPU 코어가 여러 개 있는 것으로 인식합니다. 하이퍼스레딩 기능이 있는 CPU 코어가 실제로 동시에 스레드 두 개를 실행할 수 있다는 것이 놀랍지 않나요? 지금까지 우리는 원래 물리 CPU 코어 하나는 한 번에 스레드 하나판 실행할 수 있다고 알고 있었습니다. 어떻게 이를 구현한 것일까요?
그 비밀은 하이퍼스레딩 기술이 탑재된 CPU는 한 번에 스레드 두 개에 속하는 명령에 흐름을 처리할 수 있으며, 이를 통해 CPU 코어 한 개가 CPU 코어 여러 개인 것처럼 보이게 할 수 있다는 것입니다. 그림 4-37은 하이퍼스레딩의 본질을 설명하고 있습니다.

그렇다면 하이퍼스레딩 기술은 어떻게 가능할까요? 이것을 이야기하려면 다시 파이프라인 기술로 돌아가야 합니다.
원래 명령어 간 종속성으로 파이프라인이 항상 완벽하게 채워진 상태에서 실행될 수는 없으며 결국에는 ‘빈 공간’이 생기게 됩니다. 이때 추가 명령어 흐름을 도입하여 빈 공간을 채우면 전체 파이프라인을 채워서 실행할 수 있어 CPU의 리소스를 최대한 활용할 수 있습니다.
여기에서 강조하고 싶은 점은 소프트웨어 스레드, 즉 프로그래머가 인지할 수 있는 스레드는 생성, 스케줄링, 관리의 주체가 운영 체제라는 것입니다. 반면에 하드웨어 스레드에 해당하는 하이퍼스레딩은 CPU 하드웨어의 기능으로 운영 체제와는 상관없습니다. 따라서 운영 체제 입장에서는 알 수 없는 대상에 해당하며, 기껏해야 운영 체제가 시스템에 더 많은 CPU 코어가 사용 가능하다고 인식하게 하는 정도입니다. 물론 이것은 가상이며 실제 물리 코어는 운영 체제가 아는 것보다 적습니다.
- 338~340p
기술이 전부는 아니다: CISC와 RISC 간 상업적 전쟁
오늘날에도 복잡 명령어 집합 진영의 x86은 여전히 데스크톱과 서버 영역의 주도적인 위치를 점유하고 있습니다. 반면에 축소 명령어 집합 기반의 ARM은 모바일 시장의 대부분을 차지하고 있습니다. 양측 모두 상대방 시장을 공략했지만 효과는 미미했습니다. 기술은 빠르게 발전하고 시대는 변하고 있습니다. 미래가 어찌 될지는 아직 알 수 없지만, 복잡 명령어 집합과 축소 명령어 집합 간 경쟁은 더욱더 흥미진진하게 흘러갈 것입니다.
지금까지 CPU 역사를 간략하게 소개했습니다. 4.6절에서 언급한 바와 같이 기술 탄생은 필연적이며, 복잡 명령어 집함은 한정된 자원의 시대에 적응한 결과입니다. 하지만 기술 발전과 함께 축소 명령어 집합이 등장했고, 그 이후 두 기술은 서로 경챙하고 서로를 거울로 삼아가며 오늘날의 모습으로 발전해 왔습니다. 예측하건대 복잡 명령어 집합과 축소 명령어 집함은 오랫동안 공존하게 될 것입니다.
- 342p
레지스터
CPU에 레지스터가 필요한 이유는 무엇일까요?
이유는 매우 간단한데, 바로 속도 때문입니다. CPU가 메모리에 접근하는 속도는 레지스터에 접근하는 속도의 대략 100분의 1 정도이므로, CPU에 레지스터가 없어 전적으로 메모리에 의존한다면 계산 속도는 지금보다 매우 많이 느려지게 될 것입니다.
- 343p
실행되는 모든 함수는 스택 프레임을 가집니다. 스택의 가장 중요한 정보는 스택 상단(stack top)으로, 이 스택 상단 정보는 스택 하단(stack bottom)을 가리키는 스택 포인터(stack pointer)에 저장됩니다.
- 344p
함수가 실행될 때 함수에 정의된 로컬 변수와 전달된 매개변수 등을 저장하는 독립적인 메모리 공간이 있는데, 이 독립적인 메모리 공간을 스택 프레임(stack frame)이라고 합니다. 함수 호출 단계가 깊어질수록 스택 프레임수도 증가하며, 함수 호출이 완료되면 함수 호출의 반대 순서로 스택 프레임 수가 줄어듭니다.
- 344p
명렁어 주소 레지스터는 이름이 여러 개 입니다. 대다수 프로그래머는 프로그램 카운터(program counter), 줄여서 PC라고 부릅니다.
-345p
5.
도서관,책상,캐시
도서관에 자주 가는 사람이라면 알다시피 필요한 자료가 서가에 있으면 그 책을 찾아서 가져오기 위해 시간을 들여야 합니다. 하지만 한번 가져온 후에는 일정 시간이 지나 다시 그 자료를 찾 을 때 일이 훨씬 쉬워집니다. 그 책은 이미 여러분 책상 위에 놓여 있기 때문에 직접 조사하기만 하면 되니까요. 이후 책상은 분명히 최근 일정 시간 동안 사용했던 자료로 가득 찰 것이고, 이제 더 이상 서가로 가서 책을 찾을 필요가 없습니다.
여기에서 책상은 캐시(cache)에 비유할 수 있고, 서가는 메모리에 비유할 수 있습니다.
CPU와 메모리 사이의 속도 불일치 문제를 해결하는 것은 역시 같은 흐름으로 가능합니다.
최신 CPU는 메모리 사이에 캐시 계층이 추가되어 있습니다. 캐시는 가격이 비싸고 용량이 제한적이지만 접근 속도가 거의 CPU 속도에 필적합니다. 캐시 안에는 최근에 메모리에서 얻은 데이터가 저장되며, CPU는 메모리에시 명령어와 데이터를 꺼내야 할 때도 무조건 먼저 캐시에서 해당 내용을 찾습니다. 캐시가 적중하면 메모리에 접근할 필요가 없어 CPU가 명령어를 실행하는 속도를 크게 끌어올리는 목적을 쉽게 달성할 수 있습니다.
- 364p
일반적으로 x86 같은 최신 CPU와 메모리 사이에는 실제로 세 단계의 캐시가 추가되어 있으며 L1 캐시, L2 캐시, L3 캐시로 구분됩니다.
L1 캐시의 접근 속도는 레지스터 접근 속도에 비해 약간 느리지만 거의 대동소이하기 때문에 대략 4클럭 주기가 소요됩니다. 또 L2 캐시의 접근 속도는 대략 10클럭 주기가 소요되며, L3 캐시의 접근 속도는 대략 50클럭 주기가 소요됩니다. 캐시 단계에 따라 접근 속도는 낮아지지만 용량은 증가합니다.

- 365p
캐시 갱신
캐시의 데이터는 갱신되었지만 메모리의 데이터는 아직 예전 것이 남아 있습니다. 이것이 바로 불일치의 문제입니다.
- 366p
이 문제를 해결하는 가장 간단한 방법은 바로 캐시를 갱신할 때 메모리도 함께 갱신하는 것입니다. 이 방식은 연속 기입(write-through)이라고 하는데, 이는 매우 직관적인 이름이라고 할 수 있습니다. 이 방식으로 캐시를 업데이트하면 어쩔 수 없이 메모리에 접근해야 합니다. 다시 말해 CPU는 메모리가 갱신될 때까지 대기하고 있어야 하는데, 이는 분명히 동기식 설계 방법에 해당합니다.
- 367p
CPU가 메모리에 기록할 때는 캐시를 직접 갱신하지만, 이때 반드시 메모리가 갱신이 완료되기를 기다릴 필요 없이 CPU는 계속해서 다음 명령어를 실행할 수 있습니다. 그렇다면 캐시의 최신 데이터는 언제 메모리에 갱신되는 것일까요?
결국 캐시 용량에도 한계가 있어 용량이 부족하면 반드시 자주 사용되지 않는 데이터를 제거해야 하는데, 이때 캐시에서 제거된 데이터가 수정된 적이 있다면 이를 메모리에 갱신해야 합니다. 이렇게 캐시의 갱신과 메모리의 갱신이 분리되므로 이 방식은 비동기에 해당하며, 이를 후기입(write-back)이라고 합니다. 이 방법은 연속 기입보다 훨씬 복잡하지만 성능은 분명히 더 낫습니다.
- 367p
서버에서는 최근 메모리가 디스크를 대체하는 것이 대세입니다. 이제 RAM 자체가 새로운 디스크 역할을 하고 있습니다.
그 이유는 아주 간단합니다. 메모리가 점점 더 저렴해지고 있기 때문입니다. 1995년부터 2015년까지 메모리의 GB당 가격은 6000분의 1까지 떨어졌습니다. 아마존 AWS는 이미 2TB 메모리를 탑재한 인스턴스(instance)를 제공하기 시작했습니다. 2TB 용량의 디스크가 아닌 2TB 용량의 메모리라는 것에 주목하기 바랍니다.
- 373p
가상 메모리와 디스크
시스템에 프로세스가 N개가 있을 때, 이프로세스 N개가 실제 물리 메모리를 모두 사용하고 있을 때, 새로운 프로세스가 생성되어 이 N + 1 번째 프로세스도 메모리를 요청한다고 가정해 봅시다. 시스템은 이를 어떻게 처리할 수 있을까요?
사실 이 문제를 5.1절 안에서 이미 만난 적이 있습니다. 파일을 읽고 쓸 때 메모리를 디스크의 캐시로 쓸 수 있는데 이때 디스크는 메모리의 '창고' 역할을 할 수 있습니다. 이것은 무슨 의미일까요? 일부 프로세스에서 자주 사용하지 않은 메모리 데이터를 디스크에 기록하고 이 데이터가 차지하던 물리 메모리 공간을 해제합니다. 그러면 N + 1번째 프로세스가 다시 메모리를 요청할 수 있습니다.
- 374p
캐시와 메모리 상호 작용의 기본 단위: 캐시 라인
프로그램의 공간적 지역성 원리는 어떤 의미가 있을까요? 프로그램이 어떤 데이터에 접근하면 다음에는 인접한 데이터에 접근할 가능성이 높으므로 접근해야 할 데이터만 캐시에 접근하는 것은 현명하지 않습니다. 따라서 더 나은 방법은 해당 데이터가 있는 곳의 '묶음' 데이터를 캐시에 저장하는 것입니다.
이 '묶음' 데이터는 캐시 라인(cache line)이라는 이름을 갖고 있으며, 그림 5-22에서 볼 수 있듯이 이 이름은 데이터 한 줄이라는 의미가 있습니다.
- 388p
첫 번째 성능 방해자: 캐시 튕김 문제
첫 번째 프로그램은 두 개의 스레드를 시작하는데, 각각의 스레드는 전역 변수 a 값을 1씩 5억 번 증가시킵니다. 두 번째 프로그램은 단일 스레드로서 전역 변수 a 값을 1씩 10억 번 증가시킵니다. 어떤 프로그램이 더 빨리 실행될 것이라고 생각하나요?
다중 코어 컴퓨터 기준으로 첫 번째 프로그램의 실행 시간은 16초였고, 두 번째 프로그램의 실행 시간은 8초에 불과했습니다. 병렬 계산임에도 다중 스레드가 단일 스레드보다 느린 이유가 무엇일까요?
- 390p
다중 스레드 프로그램의 'insn per cycle'은 0.15로, 이는 하나의 클럭 주기 동안 기계 명령어가 0.15개 실행되었음을 의미합니다. 반면에 단일 스레드 프로그램의 'insn per cycle'은 0.6으로, 하나의 클럭 주기 동안 기계 명령어가 0.6개 실행되었음을 의미하며, 실제로 다중 스레드 프로그램의 네 배에 달합니다.
참고로 다중 스레드 프로그램과 차이를 줄이고자 단일 스레드 프로그램의 전역 변수 a도 원자적 변수로 정의했습니다. 단일 스레드 프로그램에서 a 변수를 일반적인 int 형으로 정의하면 실행 시간은 더욱 빨라져 필자 컴퓨터에서 다중 스레드보다 여덟 배 빠른 2초 만에 실행이 완료됩니다. 이때 'insn per cycle'은 1.03이 됩니다. 즉, 클럭 주기 한 번에 기계 명령어를 하나 이상 실행할 수 있습니다.
여기에서 의문점이 하나 떠오릅니다. 왜 이렇게 다중 스레드 프로그램의 성능은 좋지 않을까요?
사실 캐시 일관성이 어떻게 이루어지는지 확실히 이해하고 있다면 그리 놀랄 일이 아닙니다.
- 391~392p
C1 캐시와 C2 캐시는 끊임없이 서로 상대 캐시를 무효화하면서 튕겨 냅니다. 빈번하게 캐시 일관성을 유지하면 캐시가 자신의 역할을 하지 못할 뿐만 아니라 프로그램 성능까지 저하시킵니다. 이것이 바로 그림 5-28에서 볼 수 있는 캐시 튕김(cache line bouncing) 또는 캐시 핑퐁(cache ping-pong)이라는 흥미로운 문제입니다.
이런 상황에서는 캐시를 유지하는 데 드는 부담과 메모리에서 매번 새로 데이터를 읽어 오는 부담이 전체 흐름을 방해할 만큼 매우 커서 이런 다중 스레드 프로그램의 성능은 단일 스레드 프로그램의 성능에 미치지 못합니다.
- 394p
두 번째 성능 방해자: 거짓 공유 문제
앞의 예제에서 얻은 경험을 기반으로 자세히 살펴봅시다. 두 스레드는 변수를 공유하지 않으므로 앞서 언급한 캐시 튕김 문제가 없을 것이라고 유추할 수 있습니다. 따라서 대담하게 추론해보면, 첫 번째 다중 스레드 프로그램이 더 빠르게 실행되며 두 번째 단일 스레드 프로그램보다 두 배 더 빠르게 실행될 것처럼 보입니다.
하지만 실제 결과는 어떨까요?
필자 다중 코어 컴퓨터에서 첫 번째 다중 스레드 프로그램의 실행 시간은 3초였고, 두 번째 단일 스레드 프로그램의 실행 시간은 2초에 불과했습니다. 여러분은 또다시 의아하게 느낄 수도 있습니다. 실제로는 어떤 변수도 공유하지 않으며, 다중 코어를 충분히 활용하는 다중 스레드 프로그램이 어째서 단일 스레드 프로그램보다 느리게 실행될까요?
사실 두 스레드는 어떤 변수도 공유하지 않지만, 이 두 변수는 동일한 캐시 라인(cache line)에 있을 가능성이 높습니다. 다시 말해 이 두 변수가 하나의 캐시 라인을 공유하고 있을 수 있습니다. 캐시와 메모리는 캐시 라인 단위로 상호 작용한다는 것을 잊으면 안 됩니다. a 변수에 접근할 때 캐시가 적중하지 않으면 그림 5-29와 같이 a 변수가 포함된 캐시 라인이 캐시에 저장되는데, 이때 b 변수도 캐시에 함께 저장될 가능성이 매우 높습니다.
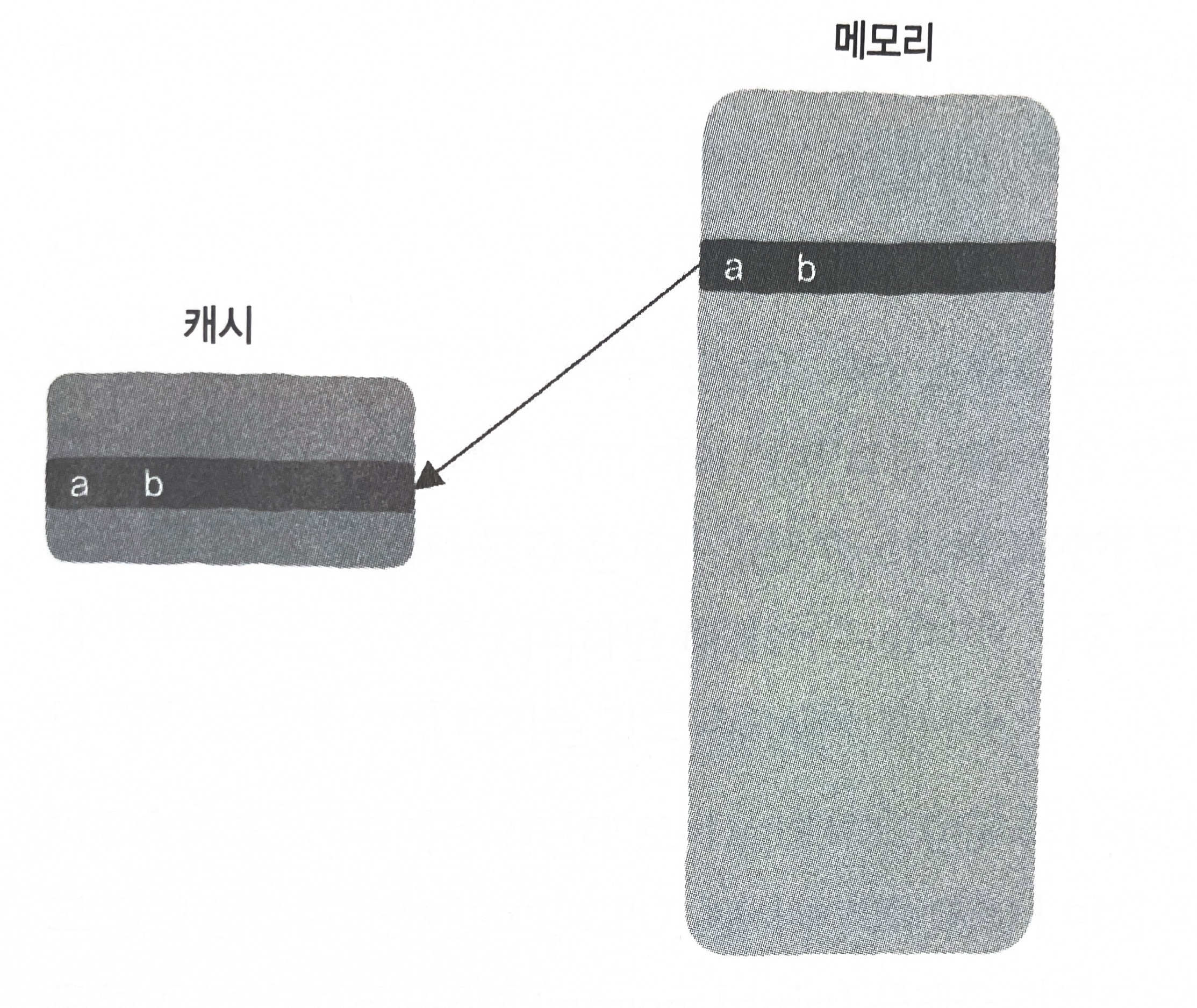
비록 스레드 두 개가 어떤 데이터도 공유하지 않는 것처럼 보이더라도 캐시의 동작 방식에 따라 캐시 라인을 공유할 가능성이 있습니다. 이것은 거짓 공유(false sharing)라고 하는 흥미로운 문제이며, 이 역시 캐시 튕김 문제를 발생시킵니다.
이제 다중 스레드 프로그램이 느리게 실행되는 이유를 이해하게 되었을 것입니다.
원인을 알면 개선도 매우 간단합니다. 여기에서 선보이는 방법은 다음과 같이 두 변수 사시에 사용되지 않는 데이터를 채우는 것입니다.
struct data{
int a;
int arr[16];
int b;
};
필자 다중 코어 컴퓨터에서는 캐시 라인 크기가 64바이트이며, a 변수와 b 변수 사이에 요소 16개를 가진 int 형식의 배열을 채우면, a 변수와 b 변수는 배열로 쪼개지므로 그림 5-30과 같이 같은 캐시 라인에 위치하지 않게 됩니다.
- 396~397p
명령어의 비순차적 실행: 컴파일러와 OoOE
지금까지는 CPU의 작업 과정이 간단하게 다음과 같다고 여겨 왔습니다.
- 기계 명령어(opcode)를 가져옵니다.
- 명령어의 피연산자(operand)가 레지스터에 저장되는 등 이미 준비 완료 상태라면 명령어는 실행 단계에 들어갑니다. 가끔 명령어의 피연산자가 아직 메모리에서 레지스터로 저장되지 않아 준비가 완료되지 않았다면, CPU는 피연산자가 메모리에서 레지스터로 저장될 때까지 기다려야 합니다. 이는 CPU 속도에 비해 메모리의 접근 속도가 매우 느리기 때문입니다.
- 데이터가 이미 준비되었다면 명령어가 실행되기 시작합니다.
- 실행 결과를 다시 기록합니다.
이 명령에 실행 방법은 매우 직관적이지만 필요한 피연산자가 아직 준비되지 않은 경우 CPU가 반드시 대기해야 하기 때문에 비효율적입니다. 이 문제는 다음과 같이 개선할 수 있습니다.
- 기계 명령어를 가져옵니다.
- 명령어를 대기열(reservation station)에 넣고 명령어에 필요한 피연산자를 읽습니다.
- 명령어는 대기열에서 피연산자의 준비가 완료될 때까지 대기합니다. 이때 이미 준비가 완료된 명령어 가 먼저 실행 단계에 들어갈 수 있습니다.
- 기계 명령어를 실행하면 실행 결과를 대기열에 넣습니다.
- 이전 명령어의 실행 결과가 기록될 때까지 기다렸다가 현재 명령어의 실행 결과를 기록합니다. 이는 명 령어의 원래 실행 순서에 따라 유효한 결과를 얻기 위한 것입니다.
이 과정에서 명령에 실행은 사실 엄격한 순서대로 진행되지 않는다는 것을 알수 있으며, 이것이 바로 비순차적 명령에 처리(Out of Order Execution, OoOE)입니다.
CPU와 메모리 사이의 속도 차이가 엄청나기 때문에 CPU가 기계 명령어를 엄격한 순서대로 실행하면 명령어가 의존하는 피연산자를 기다리는 동안 파이프라인 내부에 ‘빈 공간’인 슬롯 (slot) 이 생깁니다. 이때 이미 준비 완료된 다른 명령어로 이 ‘빈 공간’을 메꿀 수 있다면, 명령어의 실행 속도를 확실히 끌어올릴 수 있습니다. 따라저 비순차적 명령에 실행 기능은 파이프라인을 최대한 활용할 수 있으며, 단지 CPU 외부에서 볼 때는 명령어가 순서대로 실행되는 것처럼 보일 뿐만 아니라 명령어가 순서대로 실행된 것과 같은 결과를 얻습니다. 하지만 이는 전후 관계의 두 명령어가 서로 어떤 의존 관계도 없을 때에 한하면, CPU가 이런 방식으로 뒤의 명령어를 미리 실행할 수 있다는 점을 반드시 유의해야 합니다.
비순차적 명령에 실행 기능이 있는 CPU에서는 명령어가 비순차적으로 실행될 수 있지만, 모든 CPU가 이 기능을 가지고 있지는 않다는 점을 다시 한 번 강조합니다.
- 403~404p
캐시도 고려해야 한다
캐시가 있는 모든 시스템은 반드시 동일한 문제에 맞닥뜨리게 되는데, 그것은 바로 어떻게 캐시를 갱신하고 캐시의 일관성을 유지시키느냐 하는 것입니다. 이 과정은 비교적 시간을 많이 소모하고, 이 작업 전에 CPU는 반드시 대기 상태를 중지해야 합니다. 이 과정을 최적화하기 위해 일부 시스템은 그림 5 -33과 같이 저장 버퍼(store buffer) 등 대기열을 추가합니다. 기록 작업이 있을 때 대기열에 직접 기록하기 때문에 캐시는 즉시 갱신되지 않습니다. 그리고 CPU는 캐시 가 갱신되기를 기다리지 않고 다음 명령어를 계속 실행할 수 있습니다.
CPU가 실행하는 명령어와 비교할 때 기록 작업은 사실 비동기 과정입니다. 다시 말해 CPU는 기록 작업이 실제로 캐시와 메모리를 갱신할 때까지 기다리지 않고 다음 명령어를 실행할 수 있습니다. 이런 비동기 기록 작업은 매우 흥미로운 현상을 보여줍니다. 다음과 같은 코드가 있을 때, a 변수의 초깃값은 0이고 y 변수의 초깃값은 100이라고 가정해 봅시다.
a = 1;
b = y;
CPU의 코어 A가 a=1 코드 줄을 실행할 때, 1이라는 데이터는 아직 코어 A의 캐시에 갱신되지 않았지만 저장 버퍼에는 있어, 코어 A는 1이라는 데이터가 캐시에 완전히 갱신되기를 기다릴 필요 없이 바로 다음 줄의 코드인 b=y를 실행할 수 있습니다. 이때 b 변수 값은 100이 됩니다. 하지만 코어 B와 같은 또 다른 CPU 코어가 b 값이 100임을 인지하는 시점에 a 값은 코어 B 입장에서 볼 때 여전히 초깃값인 0일 가능성이 있습니다. 이는 캐시와 메모리가 아직 갱신되지 않았기 때문입니다. 따라서 최종적으로는 마치 두 번째 줄의 코드가 먼저 실행되고, 이어서 첫 번째 줄의 코드가 실행된 것처럼 보일 수 있습니다.
여기에서 꼭 주의해야 할 점은 해당 스레드 내부에서는 비순차적 실행을 볼 수 없다는 것입니다. 예를 들어 a=1과 b=y 두 줄의 코드를 실행한 후 a 값을 출력하면 분명히 초깃값인 0이 아닌 1이 출력됩니다. 이것은 CPU 설계가 이를 보장하기 때문입니다.
a = 1;
b = y;
print(a);
다시 말해 이런 비순차적 실행은 자기 자신 이외의 또 다른 코어가 해당 코어를 바라볼 때만 나타나는 현상입니다. C1이 1, 2, 3 순서로 명령어를 실행하더라도 C2에서는 1, 3, 2 순서로 명령어를 실행하는 것처럼 보입니다. 이는 마치 C1이 '123이라고 외칩니다’고 이야기했지만, C2가 들은 것은 '132’이 며, C1에 ‘언행불일치' 상황이 발생한 것과 같습니다. 이것 역시 명령어의 비순차적 실행 일종으로, 적어도 그렇게 보입니다.
이런 CPU의 관련 없는 명령어를 미리 실행하는 형태의 ‘부정 출발’처럼 보이는 동작은 명백하게 더 나은 성능을 얻는 것입니다. 이것은 모든 명령어의 비순차적 실행이 발생하는 근본적인 원인에 해당함니다. 가장 흥미로운 점은 어떤 유형의 명령어가 비순자적으로 실행되더라도 단일 스레드 내에서는 어쨌든 이런 비순차적 실행을 볼 수 없으며, 다른 스레드 역시 해당 공유 데이터에 접근해야만 이런 비순차적 실행을 볼 수 있다는 것입니다. 이것이 우리가 반드시 기억해야 할 두 번째 문장 입니다. 다시 말해 단일 스레드 환경에서 프로그래밍할 경우, 근본적으로 이 문제를 신경 쓸 필요가 없습니다.
- 404~406p
예를 들어, 어떤 명령어가 실행을 위해 특정 데이터를 기다리는 동안, 다른 명령어는 이미 필요한 데이터를 가지고 있을 수 있다. 이 경우, 컴퓨터는 기다리는 명령어를 건너뛰고 먼저 준비된 명령어를 실행다. 이후 원래 순서에 맞게 결과를 정리하여, 마치 모든 명령어가 순서대로 실행된 것처럼 결과를 제공하는 것.
컴퓨터는 캐시를 최신 상태로 유지하기 위해 '저장 버퍼' 같은 특별한 도구를 사용한다. 이 도구는 캐시에 저장될 데이터를 임시로 보관하면서, CPU가 다른 작업을 계속 할 수 있도록 한다. 이 방식 덕분에, 컴퓨터는 데이터를 캐시에 저장하는 동안에도 명령어를 계속 실행할 수 있다. 하지만, 이런 최적화 기술로 인해 다른 컴퓨터 코어가 같은 데이터를 다른 상태로 보는 문제가 발생할 수 있다는 것. 예를 들어, 하나의 코어가 어떤 데이터를 변경했지만, 그 변경 사항이 아직 캐시에 반영되지 않았다면, 다른 코어는 여전히 변경 전의 데이터를 보게 된다. 이런 현상은 프로그램이 어떻게 동작하는지를 이해하는데 혼란을 줄 수 있지만, 이것을 저수준에서 컴퓨터가 처리한다는 것.
잠금 없는 프로그래밍은 잠금을 통한 보호를 사용하지 않는 상태에서 다중 스레드의 공유 리소스를 처리하는 것입니다. 일반적으로 다중 스레드에서 공유 리소스를 사용하는 작업은 잠금을 통한 보호가 필요하다고 이야기합니다. 하지만 실제로는 잠금이 반드시 필요한 것은 아니며, 잠금이 없어도 공유 리소스에 접근할 수 있습니다. 그 원리는 비교와 교환(compare-and-swap), 즉 CAS 알고리즘과 같은 원자성 작업을 사용하는 것입니다. 이런 명령어는 실행되거나 되지 않는 두 가지 상태만 존재하며, 중간 상태는 존재하지 않습니다.
- 407p
그렇다면 여기에서 언급된 명령어의 비순차적 실행 문제는 어떻게 해결해야 할까요?
그 답은 이 절의 주제이기도 한 메모리 장벽(memory barrier)이며, 이는 사실 구체적인 기계 명령어입니다.
명령어는 비순차적으로 실행될 수 있지만, 메모리 장벽 기계 명령어를 통해 해당 스레드의 CPU 코어에 다음 명령을 내릴 수 있습니다. '여기에서는 어떤 수작도 부릴 생각하지 말고 성실하게 순서에 따라 실행해서 다른 코어가 이 코어를 보았을 때 비순차적 명령어 실행을 하는 것으로 보이면 안 됩니다.' 간단히 말해 메모리 장벽의 목적은 특정 코어를 다른 코어가 보았을 때 언행이 일치하도록 하는 것입니다.
메모리를 이야기 할 때는 읽기와 쓰기, 즉 Load와 Store 단 두가지 유형의 작업만 존재합니다. 따라서 이를 조합하면 LoadLoad, StoreStore, LoadStore, StoreLoad 네 가지 메모리 장벽 유형이 존재합니다. 이때 모든 이름은 이런 비순차적 실행을 금지한다는 의미를 가집니다.
- 407p
네 가지 메모리 장벽 유형
첫 번째 메모리 장벽 유형은 LoadLoad입니다.
이름에서 알 수 있듯이, 이는 CPU가 Load 명령어를 실행할 때 그림 5-34와 같이 다음에 오는 Load 명령어가 '부정 출발' 형태로 먼저 실행되는 것을 방지합니다.
- 408p
두 번째 메모리 장벽 유형은 StoreStore입니다.
앞의 유형과 마찬가지로 이름에서 알 수 있듯이, 이는 CPU가 Store 명령어를 실행할 때 그림 5-36과 같이 다음에 오는 Store 명령어가 '부정 출발' 형태로 먼저 실행되는 것을 방지합니다.
- 409p
세 번째 메모리 장벽 유형은 LoadStore입니다.
쓰기 작업은 상대적으로 무거운데, 어떻게 Load 명령어보다 먼저 실행될 수 있을까요? Load 명령어가 캐시에 적중하지 못하면 일부 CPU에서는 다음에 오는 Store 명령어가 먼저 실행될 수 있습니다.
- 410p
네 번째 메모리 장벽 유형은 StoreLoad입니다.
- 411p
획득 해제 의미론
봉화희제후 예에서도 획득-해제 의미론을 직접 사용하여 문제를 해결할 수 있습니다.
그림 5-43과 같이 주유왕 스레드에서는 해제 의미론을 사용하여 모든 메모리의 읽기와 쓰기 작업을 봉화 신호를 설정한 후 하지 않도록 하고, 제후 스레드에서는 획득 의미론을 사용하여 모든 메모리 읽기와 쓰기 작업이 봉화 신호 이전에는 하지 않도록 합니다.
- 414p
잠금 프로그래밍과 잠금 없는 프로그래밍
먼저 시스템에서 일반적으로 사용되는 잠금(lock)을 살펴보겠습니다.
다중 스레드 프로그래밍에서 일반적으로 사용되는 상호 배제(mutual exclusion)는 공유 리소스를 보호하는 데 사용됩니다. 동시에 최대 스레드 하나만 상호 배제를 보유할수 있으며, 해당 잠금이 사용되면 해당 잠금을 요청하는 다른 스레드는 운영 체제에 의해 대기 상태로 진입합니다. 이는 잠금을 사용한 스레드가 잠금을 해제할 때까지 계속됩니다.
이외에도 또 다른 형태의 잠금이 있는데, 해당 잠금이 사용된 후 잠금을 요청하는 스레드는 계속 잠금이 해제되었는지 여부를 반복적으로 확인합니다. 이때 잠금을 요청하는 다른 스레드는 운영 체제에 의해 대기 상태로 진입하지 않으므로 이를 스핀 잠금(spinlock)이라고 합니다.
이 두 가지 모두 잠금을 이용한 프로그래밍입니다. 잠금을 이용한 프로그래밍의 가장 큰 특징은 잠금을 사용하고 있을 때, 잠금을 요청하는 다른 스레드는 반드시 그 자리에서 대기해야 한다는 것입니다. 이것이 운영 쳬제가 대기 상태로 만드는 것이든 계속 반복적으로 검사를 하는 것이든 간에 이 스레드들은 모두 계속 앞으로 나아갈 수 없습니다.
잠금 없는 프로그래밍은 어떤 스레드가 공유 자원을 사용하고 있을 때, 다른 스레드도 해당 공유 자원의 사용이 필요하더라도 상호 배제 사용을 요청하는 스레드와 달리 운영 체제에서 대기 상태로 만들지 않으며, 스핀 잠금처럼 제자리에서 순환 대기하지 않음을 의미합니다. 또 공유 리소스가 사용되는 것을 감지하면 일단 다른 필요한 작업으로 넘어가는데, 이것이 잠금 프로그래밍과 잠금 없는 프로그래밍의 가장 큰 차이입니다.
여기에서 알 수 있듯이, 잠금 없는 프로그래밍은 시스템 성능 향상에 사용되지 않고 스레드가 항상 대기 없이 어떤 일을 하도록 하는 것에 가치를 두고 있습니다. 이것은 실시간 요구 사항이 높은 시스템에는 매우 중요하지만, 잠금 없는 프로그래밍은 매우 많고 복잡한 리소스 경쟁문제와 ABA 문제를 처리해야 하며 잠금 프로그래밍에 비해 코드 구현이 훨씬 복잡합니다. 그러나 매우 간단한 특정 상황에서는 적은 수의 원자적 작업으로 구현 가능하며, 이 경우 잠금 없는 프로그래밍 성능이 더 나을 수 있습니다.
- 418~419p
명령어 재정렬에 대한 논쟁
- 성능을 위해, CPU는 반드시 프로그래머가 코드를 작성한 순서대로 엄격하게 기계 명령어를 실행할 필요가 없습니다.
- 프로그램이 단일 스레드인 경우 프로그래머는 명령어의 비순차적 실행을 볼 수 없으므로, 단일 스레드 프로그램은 명령어 재정렬에 신경 쓸 필요가 없습니다.
- 메모리 장벽의 목적은 특정 코어가 명령어를 실행하는 순서와 다른 코어에서 보이는 순서가 코드 순서와 일치하도록 만드는 것입니다.
- 멀티 스레드 잠금 없는 프로그래밍을 사용할 필요가 없다면 명령어 재정렬을 걱정할 필요가 없습니다.
- 420p
6.
메모리 사상 입출력
주소 공간의 일부분을 장치에 할당하여, 메모리를 읽고 쓰는 것처럼 장치를 제어하는 방법이 바로 메모리 사상 입출력(memory mapping input and output)입니다.
따라서 컴퓨터의 저수준 계층에는 본질적으로 두 가지 입출력 구현 방법이 있습니다. 첫 번째는 특정 입출력 기계 명령어를 사용하는 것이고,
두 번째는 메모리의 읽기와 쓰기 명령어를 함께 사용하지만 주소 공간의 일부분을 장치에 할당하는 것입니다.
- 427p
CPU가 키보드를 읽고 쓰는 것의 본질
문제는 사용자가 언제 키보드를 누를지 확실하지 않다는 사실입니다. 키보드는 어떻게 데이터를 언제 읽어야 할지 알 수 있을까요?
- 427p
최신 CPU의 클럭 주파수는 일반적으로 2~3GHz입니다. CPU의 클럭 주파수를 2GHz라고 가정하면, 이는 하나의 클럭 주기에 0.5ns가 소요된다는 것을 의미합니다. 여기에서 단위가 ns임에 주의해야 합니다. 1초는 1,000,000,000ns에 해당합니다.
이와 동시에 하나의 기계 명령어가 하나의 클럭 주기마다 실행된다고 가정해 봅시다. 즉, CPU가 하나의 기계 명령어를 실행하는 데 걸리는 시간은 0.5ns에 불과합니다.
- 428p
폴링: 계속 검사하기
START
Load R1 0xFE00
BLZ START
Load R0 0xFE01
BL OTHER_TASK
이 코드를 고급 언어로 번역하면 다음과 같습니다.
while (키가 눌리지 않음) {
// 키가 눌릴 때까지 대기
}
문제는 사용자가 키를 누르지 않으면 CPU는 항상 불필요하게 순환하며 대기하게 된다는 것입니다.
본질적으로 폴링은 일종의 동기식 설계 방식입니다. CPU는 누군가가 키를 누를 때까지 계속 대기하므로, 이를 자연스럽게 개선할 수 있는 방법은 바로 동기를 비동기로 바꾸는 것입니다.
- 429p
배달 음식 주문과 중단 처리
CPU가 특정 프로세스의 기계 명령어를 즐겁게 실행하고 있을 때(게임에 해당) 새로운 이벤트가 발생하는 경우를 살펴봅시다. 예를 들어 네트워크 카드에 새로운 데이터가 들어오면 외부 장치가 인터럽트 신호를 보내고(초인종에 해당), CPU는 실행 중인 현재 작업의 우선순위가 인터럽트 요청보다 높은지 판단(게임과 점심 식사)합니다. 인터럽트가 더 높다면 현재 작업 실행을 일시 중지하고 인터럽트를 처리하며(배달 음식을 받는 것에 해당), 인터럽트 처리를 끝낸 후에 다시 현재 작업으로 돌아옵니다.
- 431p
인터럽트 구동식 입출력
이제 동기 기반의 폴링에서 비동기 인터럽트 처리로 바뀌었지만, 아직 해결되지 않은 두 가지 문제가 남아 있습니다.
- CPU는 인터럽트 신호가 오는 것을 어떻게 감지할까요?
- 중단된 프로그램의 실행 상태를 저장하고 복원하는 방법은 무엇일까요?
CPU는 어떻게 인터럽트 신호를 감지할까?
CPU가 기계 명령어를 실행하는 과정은 명령어 인출(instruction fetch), 명령어 해독(instruction decode), 실행(execude), 다시 쓰기(writeback) 같은 몇 가지 전형적인 단계로 나눌 수 있습니다. 이제 여기에 CPU가 하드웨어의 인터럽트 신호를 감지하는 단계가 추가되어야 합니다.
- 433p
인터럽트를 처리할 때는 그림 6-3과 같이 먼저 중단된 작업 상태를 보존해야 합니다. 이어서 CPU는 인터럽트 처리 함수의 시작 위치로 점프하여 인터럽트 처리 함수의 명령어를 실행한 후 처리가 끝나면 다시 원래 자리로 점프하여 중단되었던 작업을 계속 실행합니다.

- 433p
디스크가 입출력을 처리할 때 CPU가 하는 일은 무엇일까?
디스크가 입출력을 처리할 때 CPU 개입이 필요하지 않습니다.
- 438p
직접 메모리 접근
CPU가 직접 데이터를 복사할 필요는 없습니다. 그러나 CPU는 반드시 어떻게 데이터를 복사할지 알려 주는 명령어를 DMA에 전달해야 합니다.
DMA는 자신의 작업 목표를 명확히 하고 버스 중재(bus arbitration), 다시 말해 버스의 사용 권한을 요청한 후 이어서 장치를 작동시킵니다. 디스크에서 데이터를 읽는다고 가정했을 때, 장치 제어기의 버퍼에서 데이터를 읽으면 DMA가 지정된 ㅔㅁ모리 주소에 데이터를 쓰는 방식으로 데이터 복사가 완료됩니다.
- 442p
메모리 관점에서 입출력
메모리 관점에서 입출력은 단순한 메모리의 복사일 뿐, 그 이상도 이하도 아닙니다.
- 447p
복사 데이터는 어디에서 어디로 복사될까요? 데이터가 외부 장치에서 메모리로 복사되면 그것이 바로 입력이며, 반대로 외부 장치로 복사되면 그것이 바로 출력입니다. 즉, 메모리와 외부 장치 사이에 복사 데이터가 왔다 갔다 하는 것을 입출력(input/output)이라고 하며, 흔히 약어로 I/O라고 표현합니다.
- 447p
CPU가 명령어를 실행하는 속도에 비해 디스크 입출력은 매우 느려 운영 체제는 귀중한 계산 리소스를 불필요한 대기에 낭비할 수 없습니다. 여기에서 중요한 내용이 등장합니다.
외부 장치가 입출력 작업을 실행하는 것은 매우 느리기 때문에 입출력 작업이 끝나기 전까지 프로세스는 앞으로 나아갈 수 없으며, 이것이 3장에서 이야기했던 블로킹(blocking)입니다. 운영 체제는 그림 6-20과 같이 현재 프로세스의 실행을 일시 중지하고 입출력 블로킹 대기열에 넣습니다.
이때 운영 체제는 이미 디스크에 입출력 요청을 보낸 상태이며, 디스크는 6.2절에서 설명한 DMA 작동 방식을 사용하여 데이터를 특정 메모리 영역으로 복사하는 작업을 시작합니다. 이 메모리 영역이 바로 read 함수를 호출할 때 지정했던 buffer이며 전체 과정은 그림 6-21에서 볼 수 있습니다.

- 449p
다중 입출력을 어떻게 효율적으로 처리하는 것일까?
서버의 처리 작동 방식은 일반적으로 먼저 사용자 요청 데이터를 읽고, 이에 따라 특정한 처리를 실행하는 것입니다.
if (read(conn_fd, buff > 0){
do_something(buff);
}
단순한 이해를 위해 서버가동시에 사용자 요청 두 개를 처리한다고 가정해 보겠습니다.
if (read(socket_fd1, buff > 0){
// 첫 번째 처리
do_something();
}
if (read(socket_fd2, buff > 0){
// 두 번째 처리
do_something();
}
여기에서 read 함수는 일반적으로 블로킹 입출력입니다. 이때 첫 번째 사용자가 어떤 데이터도 보내지 않으면 해당 코드를 사용하는 스레드 전체가 일시 중지됩니다. 두 번째 사용자가 요청 데이터를 이미 보냈더라도 두 번째 사용자 요청을 처리할 방법이 없습니다. 이는 동시에 사용자 요청 수천수만 개를 처리해야 하는 서버에 있어서는 안 되는 일입니다.
- 458p
상대방이 아닌 내가 전화하게 만들기
read 함수를 사용하여 해당 파일 서술자에 대응하는 파일을 읽을 수 있는지 여부를 주동적으로 커널에 묻는 방법은 항상 '첫 번째 파일 서술자를 읽고 쓸 수 있습니까?', '두 번째 파일 서술자를 읽고 쓸 수 있습니까?', '세 번째 파일 서술자를 읽고 쓸 수 있습니까?'처럼 매번 질문 하는 것입니다. 따라서 이보다 더 나은 방법은 관심 대상인 파일 서술자를 커널에 알려주고, 커널에 '여기 파일 서술자 10,000개 있으니 대신 감사하다가 읽고 쓸 수 있는 파일 서술자가 있을 때 알려 주면 처리하겠습니다.'라고 이야기하는 것입니다.
이것이 프로그래머가 동시에 많은 수의 파일 서술자를 다룰 수 있는 방법인 입출력 다중화(input/output multiplexing) 기술입니다.
- 459p
입출력 다중화
입출력 다중화는 다음과 같은 과정을 의미합니다.
- 파일 서술자를 획득합니다. 이때 서술자 종류는 네트워크 관련이든 파일 관련이든 어떤 파일 서술자든 간에 상관없습니다.
- 특정 함수를 호출하여 커널에 다음과 같이 알립니다. '이 함수를 먼저 반환하는 대신, 이 파일 서술자를 감시하다 읽거나 쓸 수 있는 파일 서술자가 나타날 때 반환해 주세요.'
- 해당 함수가 반환되면 읽고 쓸 수 있는 조건이 준비된 파일 서술자를 획득할 수 있으며, 이를 통해 상응하는 처리를 할 수 있습니다.
- 460p
리눅스 세계에서 입출력 다중화 기술을 사용하는 방법에는 select, poll, epoll 세 가지가 있습니다.
- 460p
컴퓨터 시스템의 각 부분에서 얼만큼 지연이 일어날까?

먼저 캐시와 메모리 관련 항목을 살펴봅시다. L2 캐시 접근 시간은 L1 캐시 접근 시간에 비해 14나 길고, 메모리 접근 시간은 L2 캐시 접근 시간보다 20배, L1 캐시 접근 시간보다 200배나 더 깁니다. 이 통계는 CPU 속도에 비해 메모리 접근이 매우 느리다는 사실을 알려 주며, 이 것이 바로 CPU와 메모리 사이에 캐시 계층이 추가된 이유입니다.
다음으로 분기 예측 실패에 대한 대가를 살펴봅시다. 분기 예측은 4장에서 이미 살펴본 바 있습니다. 최신 CPU 내부에서는 일반적으로 파이프라인 방식으로 기계 명령어를 처리하는 방식을 채택하고 있으므로, if 판단 구문에 대응하는 기계 명령어가 없다면 다음 명령어가 바로 파이프 라인에 들어갑니다. 이때 CPU는 반드시 if 구문이 참인지 여부를 추측해야 합니다. CPU 추측 이 맞으면 파이프라인이 평소처럼 실행되지만, 추측에 실패하면 파이프라인에서 이미 실행되었 던 일부 명령어가 무효화됩니다. 통계에서 보면 분기 예측 실패에 따른 대가는 몇 ns 수준임을 알 수 있습니다.
모든 프로그래머는 메모리에 접근하는 속도가 SSD에 접근하는 속도보다 빠르고, SSD에 접근하는 속도가 디스크에 접근하는 속도보다 빠르다는 것을 알고 있습니다. 그렇다면 도대체 얼마나 빠를까요? 동일한 1MB 데이터를 순차적으로 읽을 때(sequential read) 걸리는 시간은 메모 리의 경우 250,000ns, SSD는 1,000,000ns, 디스크는 20,000,000ns입니다. 즉, 디스크가 처리하는 시간은 SSD보다 20배, 메모리보다 80배 오래 걸리고, SSD는 메모리보다 네 배 더 오래 걸리는 것을 알 수 있습니다. 디스크를 순차적으로 읽는 속도는 생각만큼 그렇게 느리지 않습니다. 하지만 디스크 탐색 시간은 수 ms 단위로 매우 오래 걸립니다. 디스크를 임의로 읽을 때(random read) 디스크 탐색이 발생할 가능성이 높으므로, 많은 고성능 데이터베이스는 ‘추가 (append)' 방식을 채택하고 있습니다. 다시 말해 순차 기록 방식으로 디스크에 데이터를 기록합니다.
- 473p
L1 캐시의 접근 지연이 1초라고 가정하면 메모리 접근 지연은 최대 3분이 됩니다. 1MB 데이터를 읽는 데 메모리는 5일, SSD는 20일, 디스크는 최대 1년이 걸립니다.
더 재미있는 것은 컴퓨터를 다시 시작하는 데 걸리는 시간이 2분이라고 가정하면, 이와 같이 0.5ns를 1초로 환산한 경우 2분은 5600년에 해당합니다. 동아시아 문명이 탄생한 것이 5000년 쯤 되었으니 CPU가 보기에 컴퓨터의 재시작은 이 정도로 느립니다.
- 474p
'Book' 카테고리의 다른 글
| [독서 기록] 늦깎이 천재들의 비밀 (0) | 2024.07.26 |
|---|---|
| [독서 기록] 자바 병렬 프로그래밍 (1) | 2024.04.18 |
| [독서 기록] 웹 개발자를 위한 대규모 서비스를 지탱하는 기술 (1) | 2024.04.14 |
| [독서 기록] 일류의 조건 (0) | 2024.04.13 |
| REAL MySQL 8.0 - 1권 (1) | 2024.04.01 |

