[Java 기초문법] by Professional Java Developer Career Starter: Java Foundations @ Udemy
Real Text Parsing
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class TranscriptParser {
public static void main(String[] args) {
String transcript = """
Student Number: 1234598872 Grade: 11
Birthdate: 01/02/2000 Gender: M
State ID: 8923827123
Cumulative GPA (Weighted) 3.82
Cumulative GPA (Unweighted) 3.46
""";
Pattern pat = Pattern.compile("");
Matcher mat = pat.matcher(transcript);
if (mat.matches()){
}
}
}
먼저 studentnumber를 보자. 10개의 number를 세팅하고 capture group으로 네이밍을 해준다.
String regex = "Student Number: (?<StudentNum>\\d{10})";import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class TranscriptParser {
public static void main(String[] args) {
String transcript = """
Student Number: 1234598872 Grade: 11
Birthdate: 01/02/2000 Gender: M
State ID: 8923827123
Cumulative GPA (Weighted) 3.82
Cumulative GPA (Unweighted) 3.46
""";
String regex = "Student Number: (?<StudentNum>\\d{10})";
Pattern pat = Pattern.compile(regex);
Matcher mat = pat.matcher(transcript);
if (mat.matches()){
System.out.println(mat.group("studentNum"));
}
}
}
이때 아무것도 리턴하지 못함 = 그 뒤로 다른 것들이 같이 계산이 되어서
start text가 carrot return을 갖고 있기 때문에 단순히 .*로는 인식하지 못함.
Pattern pat = Pattern.compile(regex, Pattern.DOTALL);
=> return all that characters that normally expected to but also carriage returnand new lines
여전히 리턴 nothing
"student number"에서 띄어진 스페이스를 명시적으로 하드코딩해주면 match
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class TranscriptParser {
public static void main(String[] args) {
String transcript = """
Student Number: 1234598872 Grade: 11
Birthdate: 01/02/2000 Gender: M
State ID: 8923827123
Cumulative GPA (Weighted) 3.82
Cumulative GPA (Unweighted) 3.46
""";
String regex = "Student\\sNumber:\\s(?<studentNum>\\d{10}).*";
Pattern pat = Pattern.compile(regex, Pattern.DOTALL);
Matcher mat = pat.matcher(transcript);
if (mat.matches()){
System.out.println(mat.group("studentNum"));
}
}
}
return 1234598872
grade를 가져와보자
one or more space를 표현하기 위해 +를 기입
두자리수를 표현하기 위해 대괄호에 1,2를 기입
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class TranscriptParser {
public static void main(String[] args) {
String transcript = """
Student Number: 1234598872 Grade: 11
Birthdate: 01/02/2000 Gender: M
State ID: 8923827123
Cumulative GPA (Weighted) 3.82
Cumulative GPA (Unweighted) 3.46
""";
String regex = """
Student\\sNumber:\\s(?<studentNum>\\d{10}).* # Grab Student Number
Grade:\\s+(?<grade>\\d{1,2}).* # Grab Grab
Birthdate:\\s+(?<grade>\\d{1,2}).* # Grab Grab
""";
Pattern pat = Pattern.compile(regex, Pattern.DOTALL | Pattern.COMMENTS);
Matcher mat = pat.matcher(transcript);
if (mat.matches()){
System.out.println(mat.group("studentNum"));
System.out.println(mat.group("grade"));
}
}
}
birthdate를 가져와보자.
leading zero가 있으므로 대괄호를 flexible하게 할 필요 없이 2로 통일
year도 항상 4이므로 4로 통일
안에 백슬래시만 넣어주면 동일한 형식
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class TranscriptParser {
public static void main(String[] args) {
String transcript = """
Student Number: 1234598872 Grade: 11
Birthdate: 01/02/2000 Gender: M
State ID: 8923827123
Cumulative GPA (Weighted) 3.82
Cumulative GPA (Unweighted) 3.46
""";
String regex = """
Student\\sNumber:\\s(?<studentNum>\\d{10}).* # Grab Student Number
Grade:\\s+(?<grade>\\d{1,2}).* # Grab Grab
Birthdate:\\s+(?<birthMonth>\\d{2})/(?<birthDay>\\d{2})/(?<birthYear>\\d{4}).* # Grab Grab
""";
Pattern pat = Pattern.compile(regex, Pattern.DOTALL | Pattern.COMMENTS);
Matcher mat = pat.matcher(transcript);
if (mat.matches()){
System.out.println(mat.group("studentNum"));
System.out.println(mat.group("grade"));
System.out.println(mat.group("birthMonth"));
System.out.println(mat.group("birthDay"));
System.out.println(mat.group("birthYear"));
}
}
}
젠더와 State id도 같은 맥락으로 가져온다.
gender에서 특이한 점은 boundary를 한정해주어 추가 space가 겹치지 않도록 막아줌
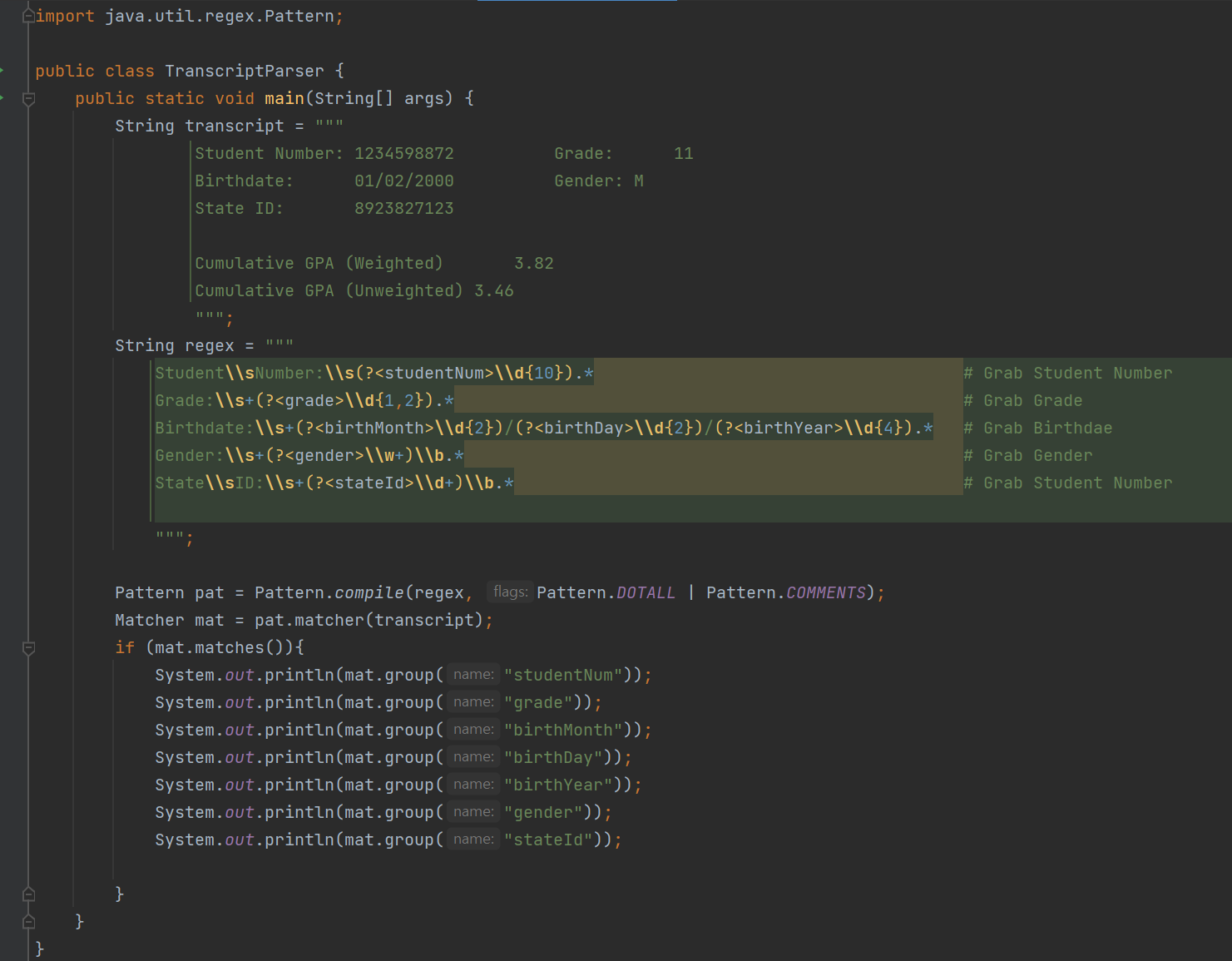
GPA를 가져와보자.
그냥 DIGIT이 아니라 x.xx로 되어 있기 때문에 .을 escape로 함께 처리해서 기입해주어야 한다.
Weighted\\)\\s+(?<weightedGpa>\\d+\\.)\\b.*
하지만 보다 더 flexible하게 하는 방법이 있다.
Weighted\\)\\s+(?<weightedGpa>[\\d\\.]+)\\b.* # Grab W GPA=> works
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class TranscriptParser {
public static void main(String[] args) {
String transcript = """
Student Number: 1234598872 Grade: 11
Birthdate: 01/02/2000 Gender: M
State ID: 8923827123
Cumulative GPA (Weighted) 3.82
Cumulative GPA (Unweighted) 3.46
""";
String regex = """
Student\\sNumber:\\s(?<studentNum>\\d{10}).* # Grab Student Number
Grade:\\s+(?<grade>\\d{1,2}).* # Grab Grade
Birthdate:\\s+(?<birthMonth>\\d{2})/(?<birthDay>\\d{2})/(?<birthYear>\\d{4}).* # Grab Birthdae
Gender:\\s+(?<gender>\\w+)\\b.* # Grab Gender
State\\sID:\\s+(?<stateId>\\d+)\\b.* # Grab Student Number
Weighted\\)\\s+(?<weightedGpa>[\\d\\.]+)\\b.* # Grab W GPA
Unweighted\\)\\s+(?<unweightedGpa>[\\d\\.]+)\\b.* # Grab UW GPA
""";
Pattern pat = Pattern.compile(regex, Pattern.DOTALL | Pattern.COMMENTS);
Matcher mat = pat.matcher(transcript);
if (mat.matches()){
System.out.println(mat.group("studentNum"));
System.out.println(mat.group("grade"));
System.out.println(mat.group("birthMonth"));
System.out.println(mat.group("birthDay"));
System.out.println(mat.group("birthYear"));
System.out.println(mat.group("gender"));
System.out.println(mat.group("stateId"));
System.out.println(mat.group("weightedGpa"));
System.out.println(mat.group("unweightedGpa"));
}
}
}
greedy operator
그런데 *은 greedy한 operator로 너무 광범위하다.
위의 코드는 분명 working 하지만 너무 specific 하지 못하다는 단점이 있음.
public static void main(String[] args) {
String transcript = """
Student Number: 1234598872 Grade: 11
Birthdate: 01/02/2000 Gender: M
State ID: 8923827123
Cumulative GPA (Weighted) 3.82
Cumulative GPA (Unweighted) 3.46
""";
String regex = """
Student\\sNumber:\\s(?<studentNum>\\d{10}).* # Grab Student Number
Grade:\\s+(?<grade>\\d{1,2}).* # Grab Grade
Birthdate:\\s+(?<birthMonth>\\d{2})/(?<birthDay>\\d{2})/(?<birthYear>\\d{4}).* # Grab Birthdae
Gender:\\s+(?<gender>\\w+)\\b.* # Grab Gender
State\\sID:\\s+(?<stateId>\\d+)\\b.* # Grab Student Number
Cumulative.*(?<weightedGPA>[\\d\\.]+)\\b.* # Grab Student Number
#Weighted\\)\\s+(?<weightedGpa>[\\d\\.]+)\\b.* # Grab W GPA
#Unweighted\\)\\s+(?<unweightedGpa>[\\d\\.]+)\\b.* # Grab UW GPA
""";
예를 들어 .*의 명령은
State\\sID:\\s+(?<stateId>\\d+)\\b.*
Cumulative.*(?<weightedGPA>[\d\.]+)\b.*Stateid가 끝나는 지점부터 해서 Cumultative를 만나면 그만 멈추는 게 아니라
grab the entire rest of the string => all the way to the string > then go backward => until matches expressed expression
탐색하고 끝내는 영역

그 다음에 선택되는 영역이

결론적으로 6이 return 된다
how can we make it less greedy of regex engine ?
asterisk 뒤에 물음표를 넣어주기
State\\sID:\\s+(?<stateId>\\d+)\\b.*? # Grab Student Number
이렇게 했을 때 탐색 영역 :

마찬가지로 Cumulative .* 뒤에 ?를 넣으면
Cumulative.*?(?<weightedGPA>[\\d\\.]+)\\b.*

dot starts from Cumulative, including this space, unti it meets digits or dot, and the grap all of that.
이 스크립트에서처럼 반복되는 표현 (Cumulative)이 나오면 greedy operator를 사용할 때 조심해야 한다.
Finding Multiple Matches
아래와 같은 상황에서 regex를 이용해 추출한다고 해보자.
public class PeopleMatching {
private String people = """
Flinstone, Fred, 1/1/1990
Rubble, Barney, 2/2/1905
Flinstone, Wilma, 3/3/1910
Rubble, Betty, 4/4/1915
""";
}
string 추출하는 regex
String regex = "(?<lastName>\\w+),\\s*(?<firstName>\\w+),\\s*(?<dob>\\d{1,2}/\\d{1,2}/\\d{4})\\n";
}
지금은 하나하나씩 match를 해주는 코드를 짰는데
데이터가 늘어날 경우 좀 더 압축적인 표현이 필요하지 않을까?
find()를 쓰면
if one regex matches of these lines properly => it should help us to zero in each of these four lines.
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class PeopleMatching {
public static void main(String[] args) {
String people = """
Flinstone, Fred, 1/1/1990
Rubble, Barney, 2/2/1905
Flinstone, Wilma, 3/3/1910
Rubble, Betty, 4/4/1915
""";
String regex = "(?<lastName>\\w+),\\s*(?<firstName>\\w+),\\s*(?<dob>\\d{1,2}/\\d{1,2}/\\d{4})\\n";
Pattern pat = Pattern.compile(regex);
Matcher mat = pat.matcher(people);
mat.find();
System.out.println(mat.group("lastName"));
System.out.println(mat.group("firstName"));
System.out.println(mat.group("dob"));
}
}
match가 성공하면 그 다음것으로 넘어가기 때문에 한번 더 늘리면 그 다음것을 찾아준다.

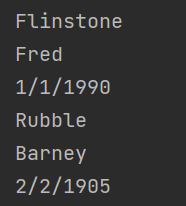
we can tell a certain number to start from

리턴
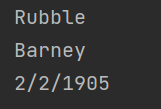
인덱스 추출 기능
mat.find(35);
System.out.println(mat.group("lastName"));
System.out.println(mat.group("firstName"));
System.out.println(mat.group("dob"));
System.out.println(mat.start("firstName"));
System.out.println(mat.end("firstName"));
Flinstone
Wilma
3/3/1910
62
67



