[Java 기초문법] by Professional Java Developer Career Starter: Java Foundations @ Udemy
Regex 기초 표현
public class RegexPractice {
public static void main(String[] args) {
System.out.println("cat".matches("cat"));
}
}
리턴 true
concept of character classes
System.out.println("Cat".matches("[cC]at"));MEANING => if this word starts with a lower case c or an uppercase C = > matches
bracket = [] 를 사용해서 범위를 지정해주는 방식
public class RegexPractice {
public static void main(String[] args) {
System.out.println("Bat".matches("[cCbB]at"));
}
}
리턴 true
만약 first letter anything from a to z ?
전부 다 기입해줄 수 있지만 more elegant way = range를 지정해주는 것 a-z
public class RegexPractice {
public static void main(String[] args) {
System.out.println("bat".matches("[a-z]at"));
}
}
알파벳 전체를 하고 싶다면
public class RegexPractice {
public static void main(String[] args) {
System.out.println("Bat".matches("[a-zA-Z]at"));
}
}
Negative 표현도 할 수 있다.
public class RegexPractice {
public static void main(String[] args) {
System.out.println("cat".matches("[^c]at"));
}
}=> every character EXCEPT c
=> 리턴 false = c만 아니면 다 true
글자수가 바뀌면 ?
public class RegexPractice {
public static void main(String[] args) {
System.out.println("flat".matches("[^c]at"));
}
}
false 를 리턴한다
= 한 character에대해서만 지정해주었기 때문에
public class RegexPractice {
public static void main(String[] args) {
System.out.println("lat".matches("[^a-z]at"));
}
}
=> don't allow the first character to be in the range of a-z
자바에서 escaping => \
따라서 back slash를 쓰려면 => \\
public class RegexPractice {
public static void main(String[] args) {
System.out.println("lat".matches("\\wat"));
}
}
meaning is => should match any string that contains one word character = that is followed by lowercase a and t = 'at'
따라서 true를 리턴
public class RegexPractice {
public static void main(String[] args) {
System.out.println("_at".matches("\\w\\w\\w"));
}
}
meaning is => match any three word scores
number나 digit에 대해서도 가능하다 =
넘버의 경우 \\d (word의 경우 모든 글자에 대해 가능)
public class RegexPractice {
public static void main(String[] args) {
System.out.println("321-333-7652".matches("\\d\\d\\d-\\d\\d\\d-\\d\\d\\d\\d"));
}
}
좀더 심플하게
public class RegexPractice {
public static void main(String[] args) {
System.out.println("321-333-7652".matches("\\d{3}-\\d{3}-\\d{4}"));
}
}
만약에 중간의 하이픈이 period로 바뀌면 ?
첫번째 방법은 bracket을 사용하는 것
public class RegexPractice {
public static void main(String[] args) {
System.out.println("321-333-7652".matches("\\d{3}[-.]\\d{3}[-.]\\d{4}"));
}
}
\\s로 빈칸 표현
public class RegexPractice {
public static void main(String[] args) {
System.out.println("321-333-7652".matches("\\d{3}[-.,\\s]\\d{3}[-.,\\s]\\d{4}"));
}
}
만약에 중괄호 안에 있는 것들이 여러번 등장해도 모두 허용하도록 한다면 ?
+ 기호를 사용
public class RegexPractice {
public static void main(String[] args) {
System.out.println("321 333 7652".matches("\\d{3}[-.,\\s]+\\d{3}[-.,\\s]+\\d{4}"));
}
}
meaning = one or more of any of the characters in the bracket is allowed
그런데 space가 없다면 ?
sterisk를 쓰면 zero or more
public class RegexPractice {
public static void main(String[] args) {
System.out.println("3213337652".matches("\\d{3}[-.,\\s]*\\d{3}[-.,\\s]*\\d{4}"));
}
}
any of elements in brackets / zero or more / is allowed
0 or just one이 필요하다면 ?
question mark(?)
public class RegexPractice {
public static void main(String[] args) {
System.out.println("321 3337652".matches("\\d{3}[-.,\\s]?\\d{3}[-.,\\s]?\\d{4}"));
}
}
curly braces의 숫자를 범위로 지정해줄 수도 있다.
뒤에를 지정하지 않으면 at least만 지정한 효과
public class RegexPractice {
public static void main(String[] args) {
System.out.println("321 3337652".matches("\\d{3}[-.,\\s]?\\d{3}[-.,\\s]?\\d{3,4}"));
}
}
전화번호를 보면 처음 3 / 중간에 3 / 뒤에 4 가 나오는 패턴 = 3이 반복된다
이 중복을 get rid of 하는 방법?
=> group하는 것이다 = 소괄호 + quantifier
public class RegexPractice {
public static void main(String[] args) {
System.out.println("321 3337652".matches("(\\d{3}[-.,\\s]?){2}\\d{3,4}"));
}
}
3자리가 하나만 등장해도 가능
public class RegexPractice {
public static void main(String[] args) {
System.out.println("321 1421".matches("(\\d{3}[-.,\\s]?){1,2}\\d{3,4}"));
}
}
만약에 맨 앞에 1이 추가된다면?
public class RegexPractice {
public static void main(String[] args) {
System.out.println("1.351.321.1421".matches("\\d[-.,\\s]?(\\d{3}[-.,\\s]?){1,2}\\d{3,4}"));
}
}
question mark를 넣어서 0 or 1을 구현해줌
public class RegexPractice {
public static void main(String[] args) {
System.out.println("1.351.321.1421".matches("(\\d[-.,\\s])?(\\d{3}[-.,\\s]?){1,2}\\d{3,4}"));
}
}
= works
public class RegexPractice {
public static void main(String[] args) {
System.out.println("351.321.1421".matches("(\\d[-.,\\s])?(\\d{3}[-.,\\s]?){1,2}\\d{3,4}"));
}
}
= also works
Capture Groups
pattern 패키지
패턴을 호출할 때 new를 써도 되지만 conventional 하게 이렇게 쓴다.

자동 변수화 하는 단축키 (ctrl +alt +v / 맥 option command v)
import java.util.regex.Pattern;
public class RegexPractice {
public static void main(String[] args) {
String regex = "(\\d[-.,\\s])?(\\d{3}[-.,\\s]?){1,2}\\d{3,4}";
System.out.println("351.321.1421".matches(regex));
Pattern pat = Pattern.compile()
}
}

자바의 기본 로직을 생각해보자.
사람의 언어 (일반적으로 영어)를 컴퓨터가 그대로 읽지 않고 byte로 된 머신 코드로 바꿔서 읽는다.
그렇게 컴파일 하는 과정이 필요한데 마찬가지로 regex에서도 같은 로직이 명시적으로 쓰인다고 이해.
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexPractice {
public static void main(String[] args) {
String regex = "(\\d[-.,\\s])?(\\d{3}[-.,\\s]?){1,2}\\d{3,4}";
String phoneNumber = "351.321.1421";
System.out.println(phoneNumber.matches(regex));
Pattern pat = Pattern.compile(regex);
Matcher mat = pat.matcher(phoneNumber); // does this phoneNumber matches above regex?
}
}
현재 두개의 소괄호가 있는데 이것을 capture group으로 본다.
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexPractice {
public static void main(String[] args) {
String regex = "(\\d[-.,\\s])?(\\d{3}[-.,\\s]?){1,2}\\d{3,4}";
String phoneNumber = "351.321.1421";
System.out.println(phoneNumber.matches(regex));
Pattern pat = Pattern.compile(regex);
Matcher mat = pat.matcher(phoneNumber);
if (mat.matches()){
System.out.println(mat.group(1));
System.out.println(mat.group(2));
}
}
}
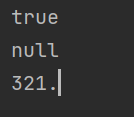
country code가 없어서 2번째는 null을 출력했다
이때 curly braces를 사용하면 앞에 것이 없으면 건너뛰고 capture group이 카운팅이 되어서 오류가 발생할 수 있음
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexPractice {
public static void main(String[] args) {
String regex = "(1[-.,\\s])?(\\d{3}[-.,\\s]?)(\\d{3}[-.,\\s]?)\\d{4}";
String phoneNumber = "1.351.321.1421";
// System.out.println(phoneNumber.matches(regex));
Pattern pat = Pattern.compile(regex);
Matcher mat = pat.matcher(phoneNumber);
if (mat.matches()){
System.out.println(mat.group(1));
System.out.println(mat.group(2));
}
}
}
리턴 1, 351
캡쳐 그룹에 0을 넣으면 어떻게 될까?
if (mat.matches()){
System.out.println(mat.group(0));
전체를 리턴
1.351.321.1421
캡쳐 그룹을 다음과 같이 만들어준다.
각 숫자에 한번더 소괄호를 넣어줌.
String regex = "((\\d{1,2})[-.,\\s])?((\\d{3})[-.,\\s]?)((\\d{3})[-.,\\s]?)(\\d{4})";
리턴

works diffrently
첫번째 capture group :
(\\d{1,2})[-.,\\s]두번째 capture group :
\\d{1,2}
이런식으로 바깥 것이 먼저 group을 형성하고 embedded in의 것은 두번째로 카운트 됨
=> 총 7개의 캡처그룹 형성
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexPractice {
public static void main(String[] args) {
String regex = "((\\d{1,2})[-.,\\s])?((\\d{3})[-.,\\s]?)((\\d{3})[-.,\\s]?)(\\d{4})";
String phoneNumber = "82.351.321.1421";
// System.out.println(phoneNumber.matches(regex));
Pattern pat = Pattern.compile(regex);
Matcher mat = pat.matcher(phoneNumber);
if (mat.matches()){
System.out.format("Country code : %s\n",mat.group(2));
System.out.format("Area code : %s\n",mat.group(4));
System.out.format("Exchange code : %s\n",mat.group(6));
System.out.format("Line code : %s\n",mat.group(7));
}
}
}
리턴
Country code : 82
Area code : 351
Exchange code : 321
Line code : 1421
과거의 코드를 볼 때
for programmer : readable
but 프로그램 관점에서 not consice and not flexible

regex를 활용한 것이 more advanced라고 할 수 있다.
다음과 같은 표현으로 group으로 캡처하는 영역을 filter할 수 있음 = not to caputre
?:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexPractice {
public static void main(String[] args) {
String regex = "(?:(\\d{1,2})[-.,\\s])?(?:(\\d{3})[-.,\\s]?)(?:(\\d{3})[-.,\\s]?)(\\d{4})";
String phoneNumber = "82.351.321.1421";
// System.out.println(phoneNumber.matches(regex));
Pattern pat = Pattern.compile(regex);
Matcher mat = pat.matcher(phoneNumber);
if (mat.matches()){
System.out.format("Country code : %s\n",mat.group(1));
System.out.format("Area code : %s\n",mat.group(2));
System.out.format("Exchange code : %s\n",mat.group(3));
System.out.format("Line code : %s\n",mat.group(4));
}
}
}
Country code : 82
Area code : 351
Exchange code : 321
Line code : 1421
less than and greater than symbol <>을 사용하기
? = starting point
String regex = "(?:(?<countryCode>\\d{1,2})[-.,\\s])?(?:(\\d{3})[-.,\\s]?)(?:(\\d{3})[-.,\\s]?)(\\d{4})";
String phoneNumber = "82.351.321.1421";
if (mat.matches()){
System.out.format("Country code : %s\n",mat.group("countryCode55"));
이름이 맞으면 제대로 된 것을 리턴
틀리면 blow up
name이 지정된 capture group
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexPractice {
public static void main(String[] args) {
String regex = "(?:(?<countryCode>\\d{1,2})[-.,\\s])?(?:(?<areaCode>\\d{3})[-.,\\s]?)(?:(?<exchangeCode>\\d{3})[-.,\\s]?)(?<lineNumber>\\d{4})";
String phoneNumber = "82.351.321.1421";
// System.out.println(phoneNumber.matches(regex));
Pattern pat = Pattern.compile(regex);
Matcher mat = pat.matcher(phoneNumber);
if (mat.matches()){
System.out.format("Country code : %s\n",mat.group("countryCode"));
System.out.format("Area code : %s\n",mat.group("areaCode"));
System.out.format("Exchange code : %s\n",mat.group("exchangeCode"));
System.out.format("Line code : %s\n",mat.group("lineNumber"));
}
}
}
패턴의 comments를 사용하기
:tell Regex engine ignore space
// "I am good"
// "I\\am\\good" <= COMMENT를 사용하면 introduce that there is a space
커멘트 모드에서는 이렇게 문단을 나누는 게 가능한데 space를 ignore하기 때문
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexPractice {
public static void main(String[] args) {
String regex = """
(?:(?<countryCode>\\d{1,2})[-.,\\s])?
(?:(?<areaCode>\\d{3})[-.,\\s]?)(?:(?<exchangeCode>\\d{3})[-.,\\s]?)(?<lineNumber>\\d{4})""";
String phoneNumber = "82.351.321.1421";
// System.out.println(phoneNumber.matches(regex));
Pattern pat = Pattern.compile(regex, Pattern.COMMENTS);
Matcher mat = pat.matcher(phoneNumber);
if (mat.matches()){
System.out.format("Country code : %s\n",mat.group("countryCode"));
System.out.format("Area code : %s\n",mat.group("areaCode"));
System.out.format("Exchange code : %s\n",mat.group("exchangeCode"));
System.out.format("Line code : %s\n",mat.group("lineNumber"));
}
}
}
좀 더 보기 좋게 만들기
more logical and intuitive
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexPractice {
public static void main(String[] args) {
String regex = """
# regex 테스트
(?:(?<countryCode>\\d{1,2})[-.,\\s])? # Country code
(?:(?<areaCode>\\d{3})[-.,\\s]?) # Area code
(?:(?<exchangeCode>\\d{3})[-.,\\s]?) # Exhance
(?<lineNumber>\\d{4}) # Line number
""";
String phoneNumber = "82.351.321.1421";
// System.out.println(phoneNumber.matches(regex));
Pattern pat = Pattern.compile(regex, Pattern.COMMENTS);
Matcher mat = pat.matcher(phoneNumber);
if (mat.matches()){
System.out.format("Country code : %s\n",mat.group("countryCode"));
System.out.format("Area code : %s\n",mat.group("areaCode"));
System.out.format("Exchange code : %s\n",mat.group("exchangeCode"));
System.out.format("Line code : %s\n",mat.group("lineNumber"));
}
}
}
만약 전화번호가 이렇게 바뀐다면 ?
String phoneNumber = "(351) 321-1421";
optionally accept 괄호
문제는 regex에서 parentheses가 특별한 기호로 여겨지기 때문에 literally escape 하게 해주어야 한다 => \\ 사용
0 or 1를 의미하는 ?와 함께 사용
(?:\\(?(?<areaCode>\\d{3})\\)?[-.,\\s]?) # Area code
여러가지 표현들
public class RegexPractice2 {
public static void main(String[] args) {
System.out.println("doggy".matches("....."));
}
}
. => 같은 글자수 내에서 모든 것 허용
=> 5개 글자이므로 항상 true
asterisk를 사용하면 더 간단해진다.
public class RegexPractice2 {
public static void main(String[] args) {
System.out.println("doggy".matches(".*"));
}
}
=> means one or more
public class RegexPractice2 {
public static void main(String[] args) {
System.out.println("doggy".matches("[^afda]"));
}
}
=> means match any character that isn't inside a or f or d
하지만 괄호 바깥에서 사용하면
public class RegexPractice2 {
public static void main(String[] args) {
System.out.println("doggy".matches("^"));
}
}=> means this matches the beginning of a line or the beginning of a string
public class RegexPractice2 {
public static void main(String[] args) {
System.out.println("doggy".matches("^....."));
}
}
=> 리턴 true
시작하는 것에서부터 any 5 character 매치하는지 확인
반면 dollar sign은 끝을 나타내준다
public class RegexPractice2 {
public static void main(String[] args) {
System.out.println("doggy".matches("^.....$"));
}
}
왜 ^나 $ 이런 문자들이 특정 기능을 하는 것일까?
ASCII 코드에서 특정 기능을 하는 Character이기 때문이다.

represent space : \s
represebt boundary : \b
public class RegexPractice2 {
public static void main(String[] args) {
System.out.println("cat doggy".matches("...\\s\\b....."));
}
}
true
represent all word : \w
하지만 반대로 대문자로 하면
public class RegexPractice2 {
public static void main(String[] args) {
System.out.println("---".matches("\\W\\W\\W"));
}
}
하이픈은 word로 취급되지 않기 때문에 리턴 true
마찬가지로 \d일때도 대문자면 => non digit words
\S => non space characters
public class RegexPractice2 {
public static void main(String[] args) {
System.out.println(" ".matches("\\S"));
}
}
False



