1. 배열의 정의
배열의 정의
배열은 여러 값을 연속적으로 저장하는 자료 구조로서, 프로그래밍에서 기본적인 역할을 한다. 배열은 특정한 순서로 정렬된 원소들의 집합이며, 이 원소들은 모두 같은 자료형을 가진다.
배열의 각 원소는 인덱스(index)라고 불리는 숫자로 식별된다. 이 인덱스는 배열의 시작점으로부터 특정 거리만큼 떨어진 위치에 있는 원소를 참조하는 데 사용된다.

배열의 의미
배열은 데이터를 메모리상에 효율적으로 저장하고 접근할 수 있는 방법을 제공한다. 각 원소들은 연속적인 메모리 공간에 저장되어 있으므로, 배열을 통해 데이터를 빠르고 쉽게 처리할 수 있다. 배열은 순서가 중요한 데이터를 다룰 때 특히 유용하며, 인덱스를 사용해 각 원소에 빠르게 접근할 수 있다는 점에서 큰 이점을 가진다.
배열의 이러한 특징은 프로그래밍에서 다양한 알고리즘과 데이터 처리 방식의 기초를 제공한다. 예를 들어, 정렬, 검색, 데이터 저장 및 관리 등의 작업에서 배열은 필수적인 역할을 한다. 배열은 기본적인 데이터 구조임에도 불구하고 그 활용도는 매우 높으며, 다양한 프로그래밍 언어와 환경에서 광범위하게 사용된다.

2. 배열의 추상 자료형
추상 자료형의 정의와 배열
배열은 데이터를 순서대로 나열하는 기본적인 자료 구조이다. 추상 자료형(ADT, Abstract Data Type)은 데이터와 그 데이터에 적용할 수 있는 연산들을 함께 묶어 정의한다. 배열의 추상 자료형은 순서가 중요한 데이터의 나열을 표현하며, 이에 대한 다양한 연산을 제공한다.
배열의 추상 자료형 특성
배열의 추상 자료형은 다음과 같은 특성을 갖는다:
- 순서 보장: 배열은 데이터의 순서를 보장하며, 이 순서는 메모리 상의 물리적인 위치로 표현된다.
- 인덱싱: 각 데이터는 특정 인덱스에 할당되며, 이 인덱스를 통해 데이터에 접근할 수 있다.
- 동일 자료형 저장: 배열은 동일한 타입의 데이터들을 저장다.
배열의 추상 자료형과 메모리
배열의 메모리 저장 구조는 다음과 같다:
- 물리적 순서: 배열의 각 원소는 메모리 상에서 연속적인 위치에 저장된다.
- 주소 계산: 배열 원소의 주소는 기본 주소와 인덱스를 이용하여 계산된다. 예를 들어,
array[3]의 주소는base_address + (3 * element_size)와 같은 방식으로 계산된다.
배열과 추상화
배열은 추상화된 자료형의 한 예이다. 프로그래밍에서 배열을 사용함으로써, 개발자는 데이터의 구체적인 저장 방법을 신경 쓰지 않고, 데이터의 순서와 접근 방법에만 집중할 수 있다.
배열의 활용
- 데이터 집합 관리: 배열은 데이터를 효율적으로 관리하고 접근하는 데 사용된다.
- 알고리즘 구현: 정렬, 검색 등 다양한 알고리즘에서 배열이 기본적으로 사용된다.
배열의 추상 자료형 연산
생성과 접근
- 생성(Create): 배열을 생성하고 초기화한다.
- 검색(Retrieve): 주어진 인덱스에 해당하는 데이터를 검색한다.
- 저장(Store): 배열의 특정 인덱스에 데이터를 저장한다.
배열의 효율성과 제한
- 효율적 접근: 배열은 인덱스를 통한 빠른 데이터 접근을 제공한다.
- 크기 제한: 배열은 생성 시점에 크기가 고정되며, 동적으로 크기를 변경하는 것이 어렵다.
실무적 관점
- 메모리 관리: 배열은 메모리 관리에 있어서 중요한 역할을 한다. 연속적인 메모리 할당이 필요하기 때문에 큰 배열은 메모리 공간에 영향을 줄 수 있다.
- 성능 최적화: 배열의 사용은 프로그램의 성능에 직접적인 영향을 미친다. 효율적인 데이터 저장과 접근은 애플리케이션의 전반적인 성능 향상에 기여한다.
결론
배열의 추상 자료형은 프로그래밍에서 기본적이면서도 중요한 역할을 한다. 데이터의 효율적인 저장과 접근을 가능하게 하며, 다양한 애플리케이션과 알고리즘의 기반을 제공한다.
3. 배열 연산의 구현
배열의 생성과 초기화
- 배열 생성: 프로그래밍 언어의 구조를 이해하는 데 필수적인 개념. 배열 생성은 메모리 공간에 연속된 위치를 할당하는 과정을 포함.
- 초기화: 배열이 생성되면, 각 요소는 초기화되어야 함. 초기화 과정은 배열의 유형과 목적에 따라 다를 수 있음.
배열 요소의 검색
- 인덱스를 이용한 접근: 배열의 각 요소는 고유한 인덱스에 의해 식별됨. 이 인덱스를 사용하여 특정 요소를 빠르게 찾고 접근 가능.
- 검색 알고리즘: 특정 값이나 조건을 만족하는 요소를 찾기 위해 다양한 검색 알고리즘이 사용될 수 있음.
데이터의 저장 및 업데이트
- 데이터 저장: 배열에 새 데이터를 저장할 때는 인덱스를 활용하여 적절한 위치에 데이터를 배치.
- 업데이트: 기존 데이터의 수정이 필요한 경우, 해당 인덱스의 값을 새로운 값으로 갱신.
배열의 장점과 한계
- 장점: 데이터의 연속적 저장으로 인해 메모리 관리가 용이하고, 인덱스를 통한 빠른 접근 가능.
- 한계: 고정된 크기로 인한 유연성 부족, 크기 변경이 어려움.
4. 1차원 배열
1차원 배열의 정의
1차원 배열은 연속적인 메모리 공간에 동일한 데이터 타입의 원소들을 순차적으로 저장하는 데이터 구조.
배열의 각 원소는 고유한 인덱스에 의해 식별되며, 이 인덱스를 사용하여 배열의 각 원소에 빠르게 접근할 수 있다.

1차원 배열에서의 주소 계산
1차원 배열의 주소 계산은 배열의 시작 주소와 원소의 인덱스를 사용하여 수행된다. 주소 계산은 배열의 시작 주소에 인덱스와 원소의 크기를 곱한 값을 더함으로써 이루어진다. 예를 들어, 배열의 시작 주소가 alpha이고 각 원소의 크기가 8비트일 때, array[3]의 주소는 alpha + 3 * 8이 된다. 이러한 방식으로 배열의 특정 위치에 빠르게 접근하여 데이터를 읽거나 쓸 수 있다.
- 배열의 효율적인 사용: 배열은 연속적인 메모리 할당 덕분에 데이터의 저장 및 접근이 효율적이다. 특히, 인덱스를 통한 빠른 접근은 배열의 주요 장점 중 하나이다.
- 메모리 관리의 중요성: 배열의 크기는 선언 시 고정되므로, 필요한 메모리 공간을 사전에 정확히 파악하고 관리하는 것이 중요하다.
- 주소 계산의 중요성: 배열에서 특정 원소에 접근하기 위해 주소를 계산하는 과정은 프로그래밍에서 중요한 역할을 하다. 이는 배열을 효율적으로 사용하기 위한 핵심적인 요소이다.
주소 계산 방법
- 계산 공식:
배열 주소 = 기본 주소 + (인덱스 × 데이터 타입 크기)- 기본 주소: 배열의 첫 번째 원소의 주소
- 인덱스: 접근하고자 하는 원소의 위치
- 데이터 타입 크기: 배열의 원소 하나가 차지하는 메모리의 크기
- 예시:
int타입의 1차원 배열arr[5]가 있다고 가정할 때,arr[3]의 주소는arr의 기본 주소에서 시작해 3 ×int의 크기만큼 떨어진 위치에 있다.
메모리 효율성
- 연속적 할당의 장점: 1차원 배열은 메모리를 연속적으로 할당받기 때문에, 원소들에 대한 접근 속도가 빠르다.
- 주소 계산의 효율성: 각 원소의 주소를 쉽게 계산할 수 있어, 데이터의 검색과 수정이 간편하다.
5. 배열의 확장
행렬의 배열 표현
행렬을 배열로 표현하는 방법은 데이터의 관리와 처리를 효율적으로 할 수 있게 해준다. 행렬을 배열로 변환할 때는 각 원소의 위치와 값을 배열의 형태로 저장한다. 이를 통해 컴퓨터 메모리에서의 데이터 접근이 용이해지며, 행렬 연산이 보다 간단해진다.
- 행렬의 각 원소는 배열의 원소로 변환
- 위치 정보와 함께 데이터 저장
- 행렬 연산의 효율성 향상
행렬의 2차원 배열 표현
2차원 배열은 행렬 데이터를 효과적으로 표현하는 방법이다. 여기서 행과 열의 개념을 배열에 적용하여, 데이터의 물리적 저장과 접근을 용이하게 한다.
- 2차원 배열로 행렬 표현
- 행과 열을 기반으로 한 데이터 구조화
- 메모리에서의 효율적인 데이터 관리

행 우선 배열
행 우선 배열은 2차원 배열을 메모리에 저장할 때 각 행의 데이터를 연속적으로 배치하는 방식이다. 이 방법은 메모리 접근 시간을 줄이고, 데이터 처리 속도를 향상시킨다.
- 연속적인 메모리 저장을 위한 행의 순차적 배치
- 데이터 접근 및 처리 속도 향상
- 메모리 관리의 효율성 증가
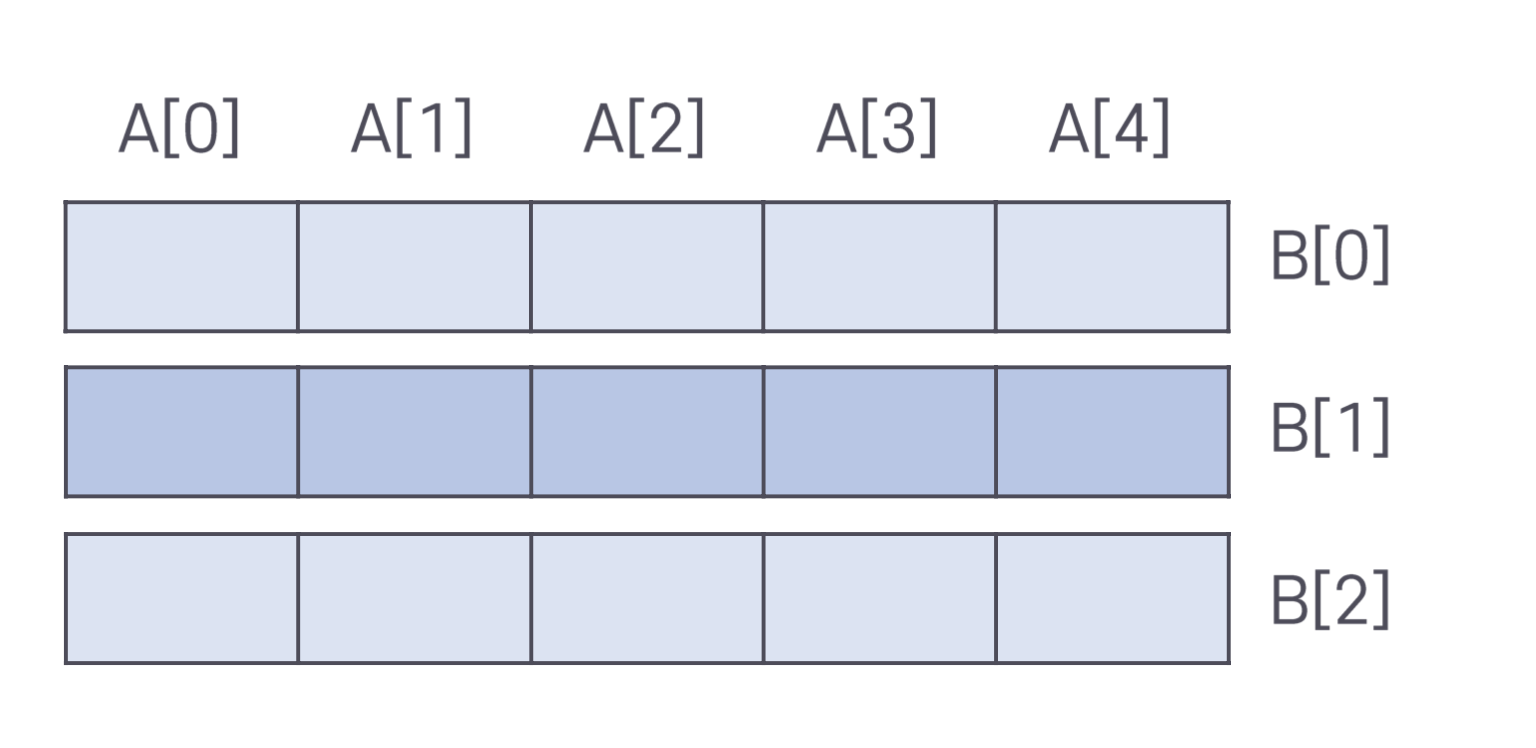
열 우선 배열
열 우선 배열은 행 우선 배열과 반대로, 각 열의 데이터를 연속적으로 저장하는 방식이다. 이는 특정 연산에서 행 우선 배열보다 더 효율적일 수 있으며, 사용 목적에 따라 선택된다.
- 각 열을 연속적으로 저장하는 방식
- 특정 연산에서 효율적인 데이터 관리
- 상황에 따른 선택적 사용


C 언어에서의 2차원 배열(행 우선 순서 저장)
C 언어에서 2차원 배열은 기본적으로 행 우선 순서로 저장된다. 이는 메모리에 배열이 연속적으로 저장되며, 이로 인해 데이터 접근이 빠르고 효율적이다.
- C 언어의 기본적인 배열 저장 방식
- 메모리에 연속적인 저장으로 빠른 접근 가능
- 프로그래밍 언어에 따른 배열 구현의 차이 인지
6 희소 행렬
희소 행렬(Sparse Matrix)은 대부분의 원소가 0인 행렬을 의미한다. 이러한 행렬에서는 0이 아닌 원소만을 효율적으로 저장하고 관리하는 것이 중요하다.

희소 행렬의 정의
- 대부분의 원소가 0인 행렬
- 메모리 사용의 최적화가 필요한 특수한 경우
희소 행렬의 효율적 배열 표현
- 희소 행렬의 표현 방식: 일반적인 2차원 배열 방식과는 다른 특수한 저장 방식을 필요로 한다.
- 0이 아닌 원소만 저장: 희소 행렬에서는 0이 아닌 원소의 위치와 값을 저장함으로써 메모리를 효율적으로 사용한다.
- 저장 방식의 예시: 예를 들어, 행렬의 크기, 0이 아닌 원소의 수, 각 원소의 위치 및 값 등을 저장하는 방식을 사용할 수 있다.
- 효율성과 복잡성의 균형: 희소 행렬은 메모리 효율성을 높이지만, 연산 처리에 있어서는 일반적인 2차원 배열보다 복잡한 알고리즘을 요구한다.
요약
- 희소 행렬은 대부분의 원소가 0으로 구성된 특수한 형태의 행렬.
- 메모리 최적화를 위해 0이 아닌 원소들만을 저장하는 방법을 채택.
- 이러한 방식은 메모리 사용은 줄이지만, 연산 복잡성은 증가시킬 수 있음.
주의 사항
- 복잡한 연산 처리로 인해 프로그래밍 시 주의가 필요.
- 희소 행렬의 구현은 메모리 효율성과 연산 복잡성 사이에서 균형을 맞춰야 한다.
참고 자료: 자료구조 (강태원, 정광식 공저, KNOU press 출판)
'CS > 자료구조' 카테고리의 다른 글
| 큐 - 큐의 개념, 큐의 추상 자료형, 큐의 응용, 배열 큐, 원형 큐 (0) | 2023.11.18 |
|---|---|
| 스택 - 스택의 개념, 스택의 추상 자료형, 연산 및 응용, 사칙연산식의 전위 중위 후위 표현 (0) | 2023.11.18 |
| 자료구조, 추상화의 개념, 자료구조와 알고리즘, 알고리즘의 개념과 조건 및 성능 (0) | 2023.11.18 |
| pointer 방식 LinkedList 자바 구현 코드 (0) | 2023.06.18 |
| ring 방식 int queue 자바 구현 코드 (0) | 2023.06.17 |



