0. 이 글의 배경
새로운 기능을 사용자에게 안전하게 선보이는 것은 모든 개발팀의 숙제입니다. 제가 현재 근무하고 있는 팀 역시 리스크를 최소화하기 위해 점진적으로 트래픽을 열어주는 '카나리 배포'를 적극적으로 활용하고 있습니다. 여기에 더해, 배포 과정 중 QA를 함께 진행하여 안정성을 이중으로 확인하는 견고한 프로세스도 갖추고 있어요.
이 글은 바로 그 "안전장치(카나리 배포 + QA)" 덕분에 발견할 수 있었던 데이터 정합성 이슈에 대한 경험담입니다. 엄밀한 의미에서 버그나 문제 해결 이야기는 아니에요. 오히려 우리의 안전장치가 성공적으로 작동해, 더 큰 장애를 막고 귀중한 교훈을 얻게 된 과정을 공유하고자 합니다.
겉보기엔 완벽해 보였던 우리의 배포 플랜에 어떤 숨은 함정이 있었는지, 그리고 이 경험을 통해 멀티 인스턴스 환경에서 상태(State)를 다루는 기능을 배포할 때 무엇을 더 고려해야 하는지 함께 깊이 들어가 보겠습니다.
※ 이 글은 실제 경험을 바탕으로 하되, 보안을 위해 시스템 명칭, 코드 등은 일부 각색되었습니다.
- 서비스 및 컴포넌트 명칭 (e.g., order-api)
- 데이터베이스 테이블 및 필드명
- 코드 스니펫 내 변수 및 메소드명
- 로그 및 아키텍처 다이어그램
1. 문제의 배경: 아키텍처와 배포 계획
이야기를 시작하기에 앞서, 어떤 환경에서 어떤 과제를 마주했는지 먼저 설명해보겠습니다.
현 시스템 아키텍처
먼저, 이슈가 발생한 주문 처리 시스템의 전체 아키텍처를 상세히 살펴볼 필요가 있을 것 같아요. 각 컴포넌트의 역할과 상호작용을 이해하는 것이 문제의 본질을 파악하는 첫걸음이죠.
이 시스템은 크게 동기적인 API 흐름과 비동기적인 Consumer 흐름으로 나뉩니다.
1. 동기적 흐름 (Synchronous Flow): 사용자의 구매 요청 처리
- Network & Application: 사용자의 요청은 AWS Application Load Balancer를 통해 들어와 Auto Scaling Group으로 관리되는 다수의 EC2 인스턴스에 분산됩니다. 각 인스턴스는 동일한 버전의 Spring Boot 기반 주문 API(
order-api)를 실행합니다. - Database: 모든 API 인스턴스는 공유 데이터 저장소로 AWS DynamoDB를 사용합니다.
order-api의 핵심 설계 사상은 'Stateless'로, 각 API 인스턴스는 상태 정보를 가지지 않고 모든 영속 데이터는 DynamoDB에 의존합니다.
2. 비동기적 흐름 (Asynchronous Flow): 이벤트 기반 쿠폰 지급 처리
- Event Stream:
order-api의 역할은 구매 요청을 검증하고 거래를 원장에 기록하는 데까지입니다. 실제 디지털 쿠폰을 지급하는 책임은 가지지 않아요. 대신, 검증이 완료되면 '구매 성공' 이벤트를 Apache Kafka와 같은 이벤트 스트림에 발행합니다. - Event Consumer: 별도로 배포된
payment-consumer애플리케이션이 Kafka 토픽을 구독하고 있다가, '구매 성공' 이벤트를 감지하면 실제 쿠폰 지급 로직을 수행합니다.
이 두 흐름을 종합한 전체 아키텍처는 다음과 같습니다.
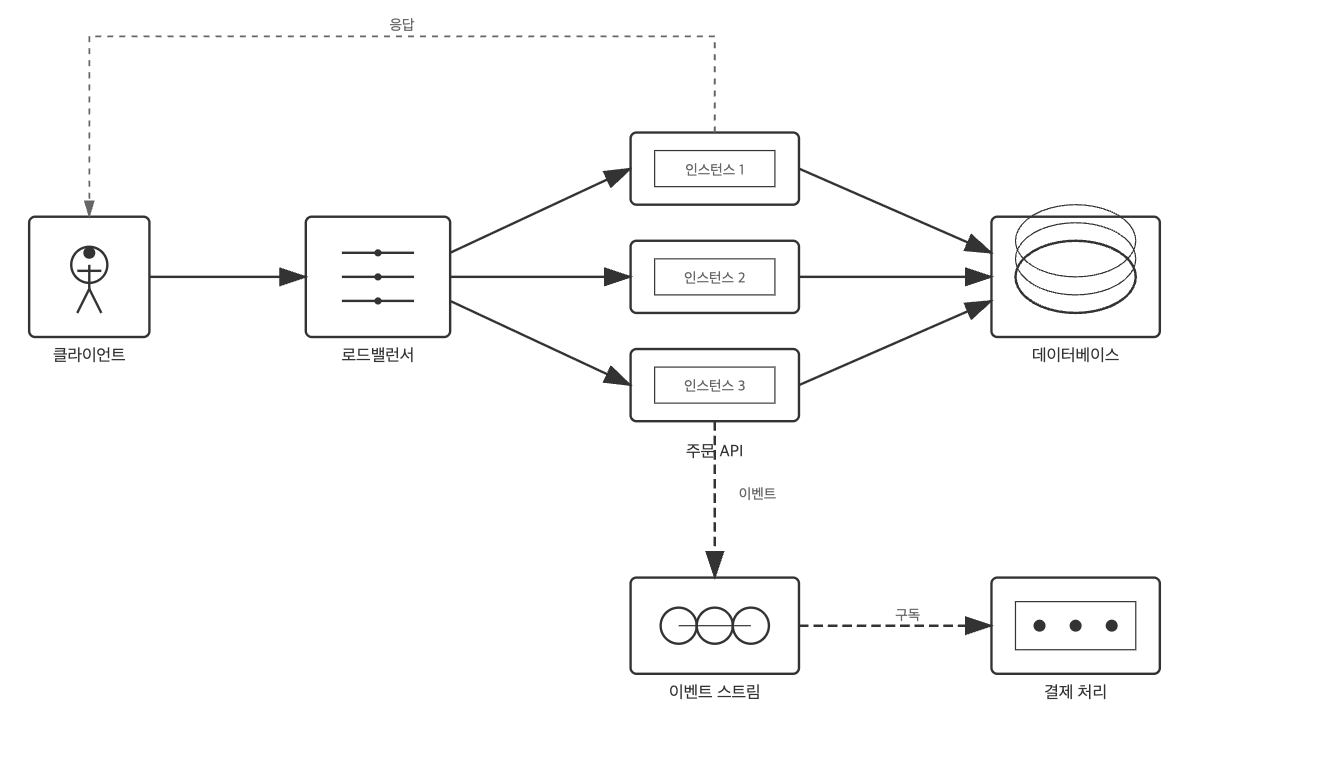
이 아키텍처에서 주목할 점은 무엇일까요? 바로 Stateless API의 암묵적인 가정, 즉 "모든 order-api 인스턴스는 동일한 로직을 수행한다"는 전제가 깨졌을 때, 공유 자원인 DynamoDB와 Kafka로 예측 불가능한 데이터가 흘러 들어갈 수 있다는 점입니다.
무엇이, 어떻게 엮여 있었나?: 구매와 복구 로직의 의존성
배포 대상이었던 기능은 gatewayTxId라는 신규 필드를 구매 트랜잭션에 추가하는 것이었습니다.
여기서 시스템의 데이터 처리 방식을 좀 더 깊이 들여다볼 필요가 있어요. '구매'와 '복구' 흐름은 데이터베이스 테이블 레벨에서 다음과 같이 강하게 결합되어 있습니다.
- 구매(Purchase) 시점: 구매 요청이 성공하면,
order-api는 트랜잭션의 상세 정보를Purchase테이블에 기록합니다. 이와 동시에, 쿠폰 지급 실패와 같은 예외 상황을 대비하여 복구에 필요한 최소한의 데이터 스냅샷을PurchaseRecovery테이블에 별도로 저장합니다. - 복구(Restore) 시점:
payment-consumer에서의 지급 실패 등으로 복구 요청이 들어오면,order-api는 PG사에 다시 검증을 요청하지 않아요. 대신, 이미 내부 DB에 저장된PurchaseRecovery테이블의 데이터를 100% 신뢰하고 그대로 읽어서 복구 절차를 진행합니다.
이 구조가 의미하는 바는 명확합니다. 만약 최초 '구매' 단계에서 PurchaseRecovery 테이블에 불완전한 데이터가 기록된다면, 이후의 '복구' 단계에서는 그 오류를 스스로 인지하거나 바로잡을 방법이 없다는 것이죠.
그렇다면, 어떤 경우에 데이터가 불완전하게 기록될 수 있었을까요?
배포 전략: 이론적으로 완벽했던 Canary 시나리오
앞서 설명한 시스템 환경과 요구사항을 바탕으로, 안정성을 최우선 목표로 하는 배포 계획이 수립되었어요. 선택한 전략은 전형적인 Canary 배포였습니다.
CI/CD 파이프라인을 통해 다음과 같은 단계로 배포가 진행되도록 설정되었습니다.
- 신규 버전 그룹 생성:
gatewayTxId필드를 추가하는 로직이 담긴 신규 버전의 애플리케이션으로 새로운 Auto Scaling Group을 생성합니다. 이 시점까지 실제 사용자 트래픽은 이 그룹으로 들어오지 않습니다. - 가중치 기반 트래픽 전환 (Weighted Routing): ALB의 Target Group 설정을 변경하여, 전체 트래픽 중 10%만 방금 생성된 신규 버전 그룹으로 향하도록 하고, 나머지 90%는 기존 버전 그룹이 계속 처리하도록 합니다. 이로써 신/구 버전의 인스턴스가 동시에 운영되는 환경이 만들어집니다.
- 혼합 환경에서의 QA 검증: QA팀은 바로 이 10%의 트래픽이 신규 버전으로 들어가는 제한된 환경에서 기능 테스트를 집중적으로 수행합니다. 여기서 문제가 발견되면 즉시 트래픽을 100% 기존 버전으로 되돌려(Rollback) 장애 전파를 막는 것이 핵심이에요.
- 점진적 확대: QA 검증이 성공적으로 완료되면, 트래픽 가중치를 30%, 50%, 최종적으로 100%까지 점진적으로 늘려 배포를 안전하게 완료합니다.
이 배포 계획은 이론적으로는 안정성을 확보하는 매우 합리적인 접근 방식입니다. 한 번에 모든 것을 바꾸는 '빅뱅' 방식의 위험을 피하고, 문제가 생겨도 소수의 사용자에게만 영향을 미치도록 통제할 수 있으니까요.
그렇다면, 이토록 합리적으로 보이는 '이론'과 실제 마주했던 '현실'의 간극은 도대체 어디에서 발생했던 것일까요?
문제의 본질은 Stateless 아키텍처의 암묵적인 가정, 즉 "모든 인스턴스의 코드는 동일하다"는 전제가 의도적으로 깨지는 바로 그 지점에 있습니다.
신/구 버전의 코드가 공존하며 동일한 데이터베이스를 바라보는 그 짧은 시간 동안, '구매'와 '복구' 흐름의 강한 의존성이란 약한 고리가 드러나는 지점인 것이죠.
만약 한 사용자의 '구매' 요청은 구버전 인스턴스가, 잠시 후의 '복구' 요청은 신버전 인스턴스가 처리하게 된다면 과연 어떤 일이 벌어질까요?
2. 문제 발견: QA 과정에서 드러난 데이터 불일치
1장에서 수립된 배포 계획은 그대로 실행되었어요. CI/CD 파이프라인이 동작했고, 전체 운영 트래픽의 10%가 gatewayTxId 로직이 추가된 신규 버전의 order-api 인스턴스로 흐르기 시작했습니다. 시스템 모니터링 대시보드 상의 에러율이나 지표는 모두 안정적이었어요.
이제 공은 QA팀에게로 넘어갔습니다. 이 신/구 버전이 혼재된 환경의 안정성을 증명하는 마지막 관문이에요.
초기 검증: 'Happy Path'는 이상 없음
QA팀은 준비된 테스트 프로토콜에 따라 검증을 시작했어요. 초기 검증은 주로 '해피 패스(Happy Path)', 즉 정상적인 구매 성공 시나리오에 집중되었습니다.
예상대로, 이 시나리오에서는 문제가 발견되지 않았어요. 신규 버전 인스턴스를 통해 처리된 구매 요청의 경우, gatewayTxId는 정상적으로 생성되어 데이터베이스에 기록되었습니다. 기존 버전 인스턴스가 처리한 요청은 당연히 해당 필드가 없었지만, 이는 의도된 동작입니다. 시스템은 겉보기엔 안정적으로 작동했어요.
엣지 케이스 테스트에서 발견된 '비결정적' 동작
하지만 시스템의 진짜 안정성은 예외 상황을 얼마나 잘 처리하는지에 달려있습니다. QA 프로토콜에는 다음과 같은 핵심 엣지 케이스(Edge Case) 시나리오가 포함되어 있었습니다.
"사용자가 정상적으로 구매를 완료했으나, payment-consumer의 일시적인 문제로 쿠폰 지급이 실패했다고 가정합니다. 이후 사용자가 구매 내역 '복구'를 요청합니다."
바로 이 '복구' 시나리오를 테스트하던 중, 분석이 필요한 이상 현상이 처음으로 감지되었어요. 결과가 비결정적(Non-deterministic)이었기 때문이입니다.
동일한 조건으로 테스트를 반복했음에도 불구하고, 복구된 데이터에 gatewayTxId가 어떨 때는 정상적으로 포함되었지만, 또 어떨 때는 명백히 null 값으로 반환되었습니다. 분명히 구매 시점에는 존재했던 데이터가, 복구 과정에서 간헐적으로 소실되는 것처럼 보였어요.
결제 시스템에서 이와 같은 비결정적 동작은 심각한 데이터 정합성 문제의 징후입니다. 즉각적인 원인 분석이 필요했어요. 이 간헐적인 현상은 왜 발생하고 있었을까요? 그 첫 번째 단서는 로그 속에 있었습니다.
로그에 남은 증거: 데이터 불일치의 실체
비결정적인 현상의 원인을 추적하기 위해 가장 먼저 살펴본 것은 당연히 애플리케이션 로그였습니다. QA팀은 문제 현상이 발생한 특정 order_id를 특정하여, 관련 이벤트 로그를 정확히 전달해주었습니다.
로그는 현상을 명확하게 증명하고 있었어요.
[증거 1: 정상 복구 케이스의 이벤트 로그]
gateway_tx_id가 정상적으로 포함된 데이터
{
"@timestamp": "2025-08-15T14:35:10.123Z",
"message": "Restore event processed successfully.",
"trace_id": "trace-id-normal-xyz",
"_message": {
"order_id": "ord-a1b2c3d4-e5f6-7890-gh12-i3j4k5l6m7n8",
"delivery_type": "RESTORE",
"gateway_tx_id": "704271406374732158"
}
}
[증거 2: 문제 발생 케이스의 이벤트 로그]
바로 위와 동일한 order_id에 대한 복구 이벤트임에도 gateway_tx_id가 누락됨
{
"@timestamp": "2025-08-15T14:36:25.456Z",
"message": "Restore event processed successfully.",
"trace_id": "trace-id-problem-abc",
"_message": {
"order_id": "ord-a1b2c3d4-e5f6-7890-gh12-i3j4k5l6m7n8",
"delivery_type": "RESTORE",
"gateway_tx_id": null
}
}
두 로그는 동일한 주문 건(order_id)에 대한 복구 이벤트임에도 불구하고 왜 결과가 달랐을까요?
물론 이 로그만으로는 근본적인 '왜'라는 질문에 바로 답할 수는 없었습니다. 하지만 이 로그는 훨씬 더 중요한 사실을 알려주었어요. 바로 이 문제가 어떤 인스턴스가 요청을 처리하느냐에 따라 결과가 달라지는 '라우팅 종속적인(Routing-dependent)' 버그일 가능성이 매우 높다는 점입니다. ALB가 요청을 신규 버전 인스턴스로 보냈을 때와 구버전 인스턴스로 보냈을 때, 내부적으로 무언가 다르게 동작하고 있음이 분명했습니다.
만약 빅뱅 방식으로 100% 동시 배포를 진행하고, 그 이후에 QA를 했다면 이 문제는 발견되지 않았을 것이에요. 모든 인스턴스가 동일하게 동작하며 일관된 결과(아마도 정상적인)만을 보여주었을 것이기 때문이죠. 역설적으로, 점진적으로 변화를 적용하는 Canary 환경이었기에 비로소 드러날 수 있었던 문제였습니다.
이제 명확한 증거가 확보되었어요. 다음 과제는 이 '라우팅 종속성'이 정확히 어떤 코드 경로의 차이로 인해 발생하는지, 즉 신/구 버전 코드의 어떤 차이가 이 데이터 소실을 유발했는지를 밝혀내는 것이었습니다.
두 번째 원인: 상태 전이 과정의 '의도된' 누락
최초 구매 시점에 gatewayTxId가 누락된 불완전한 데이터가 PurchaseRecovery 테이블에 저장되었습니다. 그렇다면 이 데이터는 어떤 경로를 거쳐 '복구' 시점까지 살아남았을까요? 그 과정을 추적하기 위해 payment-consumer에서 지급이 실패한 후, 트랜잭션의 상태가 변경되는 로직을 살펴봐야 했어요.
1. 지급 실패 처리 (DeliveryFailService)
payment-consumer가 쿠폰 지급에 실패하면, 이 사실을 다시 order-api에 알립니다. 그러면 order-api는 해당 트랜잭션의 상태를 VERIFIED에서 DELIVERY_FAILED로 변경합니다. 이때의 코드는 다음과 같았어요.
// DeliveryFailService.java
@Transactional
public void markAsFailed(String orderId) {
// 1. Purchase 테이블에서 메인 트랜잭션 데이터를 로드
Purchase purchase = purchaseRepository.findById(orderId);
// 2. 트랜잭션 상태를 '지급 실패'로 변경
purchase.changeStatus(TxStatus.DELIVERY_FAILED);
// 3. 변경된 상태를 Purchase 테이블에만 저장
purchaseRepository.save(purchase);
// ❓ 여기서 PurchaseRecovery 테이블은 건드리지 않는다.
}
코드에서 가장 중요한 지점은 PurchaseRecovery 테이블에 대해서는 어떠한 업데이트도 수행하지 않는다는 점입니다. 이는 과거의 정책상 '의도된' 설계였어요. PurchaseRecovery 테이블은 최초 구매 시점의 스냅샷 역할만을 수행하며, 이후 트랜잭션 상태가 어떻게 변하든 원본 스냅샷을 그대로 유지하는 것이 원칙이었기 때문입니다.
이 '의도된 누락' 때문에, 구버전 인스턴스가 만들어낸 불완전한 스냅샷은 지급 실패 상태를 거치면서도 수정될 기회를 완벽히 놓쳐버렸어요.
2. 복구 로직 (RestoreService)
마침내 사용자가 '복구'를 요청하는 시점입니다. 복구 로직은 단순해요.
// RestoreService.java
public RestoredData restore(String orderId) {
// 1. PurchaseRecovery 테이블에서 스냅샷 데이터를 로드
PurchaseRecovery recoveryData = purchaseRecoveryRepository.findById(orderId);
// 2. 이 스냅샷 데이터를 기반으로 복구 이벤트 발행 및 쿠폰 재지급 시도
eventStream.publish(new RestoreEvent(recoveryData));
return recoveryData.toRestoredData();
}
복구 서비스는 최초 설계대로 PurchaseRecovery 테이블의 데이터를 '신뢰하고' 그대로 가져다 씁니다. 만약 이 recoveryData가 Canary 환경에서 구버전 인스턴스에 의해 생성된 것이라면, gatewayTxId 필드는 당연히 null일 것입니다.
결론: 시나리오의 완성
이제 모든 조각이 맞춰졌습니다. 앞서 발견한 비결정적 데이터 불일치 현상은 다음과 같은 시나리오로 정리해볼 수 있겠습니다.
- Phase 1 (구매): 사용자 A의 구매 요청이 ALB에 의해 구버전
order-api인스턴스로 라우팅됩니다. - 데이터 생성: 구버전 코드는
gatewayTxId가 없는 불완전한 스냅샷을PurchaseRecovery테이블에 저장합니다. - Phase 2 (지급 실패):
payment-consumer가 쿠폰 지급에 실패하고, 이 요청은 어떤 버전의order-api가 처리하든PurchaseRecovery테이블을 건드리지 않아요. 불완전한 데이터는 그대로 유지됩니다. - Phase 3 (복구): 사용자 A가 복구를 요청하고, 이 요청은 ALB에 의해 신규 버전
order-api인스턴스로 라우팅됩니다. - 데이터 불일치 발생: 신규 버전 코드는
PurchaseRecovery테이블에서 데이터를 조회합니다. 하지만 이 데이터는 Phase 1에서 구버전 인스턴스에 의해 생성된 것이므로, 애초에gatewayTxId를 매핑하는 로직 자체가 누락되어null로 저장되어 있었습니다. 신규 버전 코드는 이null값을 그대로 읽어오게 되고, 결국gatewayTxId가 누락된, 반쪽짜리 복구 이벤트가 발행됩니다.
이것이 바로 Canary 배포 환경이 시스템의 잠재적 문제를 수면 위로 드러낸 과정의 전말이에요. 각 버전의 코드는 그 자체로 버그가 없었지만, 두 버전이 공존하며 하나의 데이터베이스를 공유하는 '중간 상태'에 대한 고려가 누락되었을 때, 이러한 데이터 정합성 문제가 발생한 것입니다.
3. 근본 원인 분석: 삽질, 그리고 발견
2장에서 확보된 명백한 증거, 즉 동일한 주문임에도 복구 시 gatewayTxId가 간헐적으로 누락되는 로그를 처음 마주했을 때, 솔직히 말해 개발자의 본능은 코드의 버그를 먼저 의심했어요.
"신규 버전의 복구 로직 어딘가에 데이터를 누락시키는 실수가 있을 것이다."
이 가설에 확신을 갖고 몇 시간 동안 신규 버전의 코드만 샅샅이 훑었어요. 변수가 덮어씌워지는 곳은 없는지, 객체 매핑이 잘못된 곳은 없는지 수없이 디버깅했지만, 코드는 아무리 봐도 논리적으로 완벽했습니다. 막다른 길에 도달한 것 같았어요.
바로 그 지점에서 관점을 180도 바꿔야 한다는 것을 깨닫게 됩니다. 만약 코드가 문제가 아니라면? 만약 코드 실행 '환경' 자체가 문제의 원인이라면? 혹시 ALB의 라우팅에 따라 결과가 달라지는 것이라면, 최초 '구매' 요청이 어느 버전의 인스턴스에서 처리되었는지가 중요하지 않을까?
이 새로운 가설을 바탕으로, 신/구 버전 코드 전체를 비교 분석하는 작업에 착수해봅시다.
두 버전의 코드: 명백한 차이점
분석의 핵심은 order-api의 PurchaseService 클래스 내에 있었습니다. 이 서비스는 외부 PG사의 결제 영수증을 검증하고, 그 결과를 데이터베이스에 저장하는 책임을 가집니다.
1. 신규 버전 코드 (PurchaseService.verifyAndSave)
신규 버전의 코드에는 gatewayTxId를 처리하는 로직이 명시적으로 추가되어 있었습니다.
// PurchaseService.java - New Version
public PurchaseData verifyAndSave(Receipt receipt) {
// ... (기존 검증 로직)
// 외부 PG사로부터 받은 검증 결과
VerificationResult result = pgVerificationClient.verify(receipt);
PurchaseData purchaseData = new PurchaseData();
purchaseData.setOrderId(result.getOrderId());
// ✅ 신규 추가된 로직: 검증 결과에서 gatewayTxId를 추출하여 설정
purchaseData.setGatewayTxId(result.getGatewayTransactionId());
// 이 purchaseData 객체를 기반으로 PurchaseRecovery 테이블에 데이터 저장
purchaseRecoveryRepository.save(purchaseData.toRecoveryEntity());
return purchaseData;
}
2. 구버전 코드 (PurchaseService.verifyAndSave)
반면, 구버전 코드에는 당연하게도 해당 로직이 존재하지 않구요.
// PurchaseService.java - Old Version
public PurchaseData verifyAndSave(Receipt receipt) {
// ... (기존 검증 로직)
VerificationResult result = pgVerificationClient.verify(receipt);
PurchaseData purchaseData = new PurchaseData();
purchaseData.setOrderId(result.getOrderId());
// ❌ gatewayTxId를 설정하는 로직 자체가 없음
// gatewayTxId가 비어있는 purchaseData 객체로 Recovery 데이터 저장
purchaseRecoveryRepository.save(purchaseData.toRecoveryEntity());
return purchaseData;
}
첫 번째 원인: 불완전한 데이터의 생성
두 버전의 코드 차이는 명백하죠. 그리고 이 차이가 Canary 배포 환경과 만났을 때 어떤 일이 벌어지는지는 쉽게 추론할 수 있을 것입니다.
- 사용자의 '구매' 요청이 발생한다.
- ALB는 이 요청을 가중치 기반 라우팅 정책에 따라 분배한다.
- 만약 이 요청이 90%의 확률로 구버전 인스턴스 중 하나로 라우팅된다면,
verifyAndSave메소드는gatewayTxId가null인 상태의PurchaseData객체를 생성한다. - 그리고 이 불완전한 데이터가
PurchaseRecovery테이블에 그대로 저장(Snapshot)된다.
이것이 바로 문제의 시작입니다. 시스템 내부에 오염된 데이터가 생성되는 첫 번째 원인이 밝혀진 것입니다.
하지만 아직 한 가지 의문이 남아요. 최초 구매 시점에 데이터가 잘못 저장되었다면, 이후의 과정에서 바로잡을 기회는 없었을까? 왜 이 불완전한 데이터는 '복구' 시점까지 살아남아 문제를 일으켰을까? 그 해답은 '지급 실패'와 '복구'를 처리하는 로직 속에 있습니다.
두 번째 원인: 상태 전이 과정의 '의도된' 누락
최초 구매 시점에 gatewayTxId가 누락된 불완전한 데이터가 PurchaseRecovery 테이블에 저장됩니다. 이 데이터가 어떻게 '복구' 시점까지 수정되지 않고 살아남았을까요? 그 과정을 추적하기 위해 payment-consumer에서 지급이 실패한 후, 트랜잭션의 상태가 변경되는 로직을 살펴봐야 합니다.
1. 지급 실패 처리 (DeliveryFailService)
payment-consumer가 쿠폰 지급에 실패하면, order-api는 해당 트랜잭션의 상태를 VERIFIED에서 DELIVERY_FAILED로 변경합니다. 이때의 코드는 다음과 같아요.
// DeliveryFailService.java
@Transactional
public void markAsFailed(String orderId) {
// 1. Purchase 테이블에서 메인 트랜잭션 데이터를 로드
Purchase purchase = purchaseRepository.findById(orderId);
// 2. 트랜잭션 상태를 '지급 실패'로 변경
purchase.changeStatus(TxStatus.DELIVERY_FAILED);
// 3. 변경된 상태를 Purchase 테이블에만 저장
purchaseRepository.save(purchase);
// ❓ 여기서 PurchaseRecovery 테이블은 건드리지 않는다.
}
코드에서 가장 중요한 지점은 PurchaseRecovery 테이블에 대해서는 어떠한 업데이트도 수행하지 않는다는 점입니다. 이는 과거의 정책상 '의도된' 설계였습니다. PurchaseRecovery 테이블은 최초 구매 시점의 스냅샷 역할만을 수행하며, 이후 트랜잭션 상태가 어떻게 변하든 원본 스냅샷을 그대로 유지하는 것이 원칙이었기 때문이죠. (과거에는 이 스냅샷 데이터의 불변성을 지키는 것이 더 중요하다고 판단했던 것이겠죠?)
이 '의도된 누락' 때문에, 구버전 인스턴스가 만들어낸 불완전한 스냅샷은 지급 실패 상태를 거치면서도 수정될 기회를 완벽히 놓쳐버리게 됩니다.
2. 복구 로직 (RestoreService)
마침내 사용자가 '복구'를 요청하는 시점입니다. 복구 로직 자체는 단순해요.
// RestoreService.java
public RestoredData restore(String orderId) {
// 1. PurchaseRecovery 테이블에서 스냅샷 데이터를 로드
PurchaseRecovery recoveryData = purchaseRecoveryRepository.findById(orderId);
// 2. 이 스냅샷 데이터를 기반으로 복구 이벤트 발행 및 쿠폰 재지급 시도
eventStream.publish(new RestoreEvent(recoveryData));
return recoveryData.toRestoredData();
}
복구 서비스는 최초 설계대로 PurchaseRecovery 테이블의 데이터를 '신뢰하고' 그대로 가져다 씁니다. 만약 이 recoveryData가 Canary 환경에서 구버전 인스턴스에 의해 생성된 것이라면, gatewayTxId 필드는 당연히 null일 것입니다.
결론: 시나리오의 완성
이제 모든 조각이 맞춰졌습니다. 다시 한 번 시나리오를 정리해 봅시다.
- Phase 1 (구매): 사용자 A의 구매 요청이 ALB에 의해 구버전
order-api인스턴스로 라우팅된다. - 데이터 생성: 구버전 코드는
gatewayTxId가 없는 불완전한 스냅샷을PurchaseRecovery테이블에 저장한다. - Phase 2 (지급 실패):
payment-consumer가 쿠폰 지급에 실패하고, 이 요청은 어떤 버전의order-api가 처리하든PurchaseRecovery테이블을 건드리지 않는다. 불완전한 데이터는 그대로 유지된다. - Phase 3 (복구): 사용자 A가 복구를 요청하고, 이 요청은 ALB에 의해 신규 버전
order-api인스턴스로 라우팅된다. - 데이터 불일치 발생: 신규 버전 코드는
PurchaseRecovery테이블에서 데이터를 조회한다. 하지만 이 데이터는 Phase 1에서 구버전 인스턴스에 의해 생성된 것이므로, 애초에gatewayTxId를 매핑하는 로직 자체가 누락되어null로 저장되어 있었다. 신규 버전 코드는 이null값을 그대로 읽어오게 되고, 결국gatewayTxId가 누락된, 반쪽짜리 복구 이벤트가 발행된다.
이것이 바로 Canary 배포 환경이 시스템의 잠재적 문제를 수면 위로 드러낸 과정의 전말입니다. 각 버전의 코드는 그 자체로 버그가 없었지만, 두 버전이 공존하며 하나의 데이터베이스를 공유하는 '중간 상태'에 대한 고려가 누락되었을 때, 이러한 데이터 정합성 문제가 발생한 것입니다.
4. 재발 방지를 위한 고민: 대안을 검토해보자
앞 장에서 문제의 근본 원인이 'Canary 배포 환경에서 발생하는 코드 버전 불일치'와 '불완전한 데이터를 수정 없이 보존하는 애플리케이션 로직'의 조합에 있음을 확인했습니다.
근본적인 해결책을 생각해볼 수 있을까요 ?
단순히 "앞으로 배포 시 주의하자"는 구두 경고나 인적 실수 방지에만 의존하는 것은 근본적인 해결이 아닐 것입니다. 이런 종류의 데이터 정합성 문제를 시스템적으로 방지하기 위해, 아키텍처나 프로세스 수준에서 어떤 개선을 할 수 있을지 여러 대안을 검토해보았어요.
대안 1: 기능 플래그(Feature Flag)의 도입 검토
가장 먼저, 그리고 가장 강력한 대안으로 검토된 것은 기능 플래그(혹은 피처 토글)의 도입입니다.
- 핵심 아이디어?
코드 배포(Deploy)와 기능 출시(Release)를 논리적으로 완전히 분리하는 전략입니다.gatewayTxId를 추가하는 신규 로직이 담긴 코드를 모든 인스턴스에 100% 동일하게 배포합니다. 하지만 코드 내에는 기능 플래그를 심어두어, 외부 설정 값을 통해 이 신규 로직을 통과할지 말지를 런타임에 결정합니다.
// 예시: 기능 플래그가 적용된 서비스 코드
public PurchaseData verifyAndSave(Receipt receipt) {
// ... (기존 검증 로직)
VerificationResult result = pgVerificationClient.verify(receipt);
PurchaseData purchaseData = createFrom(result);
// ✅ 기능 플래그 시스템에 "new-gateway-tx-id" 기능이 활성화되어 있는지 확인
if (featureFlagClient.isEnabled("new-gateway-tx-id")) {
// 활성화된 경우에만 신규 로직 실행
purchaseData.setGatewayTxId(result.getGatewayTransactionId());
}
purchaseRecoveryRepository.save(purchaseData.toRecoveryEntity());
return purchaseData;
}
- 이 문제가 어떻게 해결되는가?
모든 인스턴스가 물리적으로 동일한 버전의 코드를 실행하므로, Canary 배포 환경에서 발생했던 '라우팅 종속적인' 문제가 원천적으로 발생하지 않습니다. 트래픽의 10%에게만 신규 기능을 노출하고 싶다면, 코드 배포와는 무관하게 기능 플래그의 노출 설정을 10%로 조절하기만 하면 됩니다. - 장점
- 최상의 안정성: 버전 불일치로 인한 데이터 정합성 문제를 원천적으로 차단할 수 있습니다.
- 즉각적인 롤백: 문제가 발생하면 코드 재배포 없이, 기능 플래그를 끄는 것만으로 즉시 기능을 비활성화할 수 있습니다.
- 고려할 점
- 복잡도 증가: 기능 플래그를 관리하기 위한 별도의 설정 시스템(직접 구축하거나 상용 솔루션 사용)이 필요합니다. 또한, 코드베이스 내에
if/else분기문이 늘어나 기술 부채가 될 수 있습니다.
- 복잡도 증가: 기능 플래그를 관리하기 위한 별도의 설정 시스템(직접 구축하거나 상용 솔루션 사용)이 필요합니다. 또한, 코드베이스 내에
대안 2: 고정 세션(Sticky Session)의 활용 검토
두 번째로 검토한 대안은 인프라 레벨에서 비교적 간단하게 적용할 수 있는 고정 세션(Sticky Session) 방식입니다.
- 핵심 아이디어?
로드 밸런서(ALB)의 라우팅 알고리즘을 변경하여, 특정 사용자의 첫 번째 요청을 처리한 인스턴스가 이후 해당 사용자의 모든 요청을 계속해서 처리하도록 보장하는 방식입니다. 사용자의 쿠키나 IP 주소 등을 기반으로 세션을 '고정'시킵니다. - 이 문제가 어떻게 해결되는가?
한 사용자의 '구매' 요청과 잠시 후의 '복구' 요청은 100% 동일한 인스턴스로 전달됩니다. 따라서 해당 사용자의 트랜잭션 흐름 전체는 무조건 동일한 버전의 코드(구버전이든 신버전이든)에 의해 처리되므로, 버전 미스매치로 인한 데이터 불일치 시나리오 자체가 발생하지 않습니다. - 장점
- 간단한 적용: 애플리케이션 코드 변경 없이, 로드 밸런서 설정 변경만으로 구현이 가능합니다.
- 빠른 효과: 즉각적으로 특정 사용자에 대한 처리 일관성을 보장할 수 있습니다.
- 고려할 점
- Stateless 원칙 위배: Stateless 아키텍처의 가장 큰 장점인 '어떤 서버든 요청을 처리할 수 있다'는 원칙을 일부 포기하는 것입니다.
- 트래픽 불균형: 특정 인스턴스에 세션이 몰릴 경우 서버 간 부하가 불균일해질 수 있습니다.
- 장애 대응의 복잡성: 특정 인스턴스에 장애가 발생하면, 해당 인스턴스에 '고정'되어 있던 모든 사용자의 세션이 끊어지는 문제가 발생할 수 있습니다.
대안 3: 데이터 하위 호환성(Backward Compatibility) 강화 검토
마지막으로 검토한 것은 코드 레벨에서 방어적으로 대응하는, 데이터 하위 호환성을 강화하는 방식입니다.
- 핵심 아이디어?
신규 버전 코드가 구버전 데이터(신규 필드가 없는)를 만나더라도, 이를 '예외'가 아닌 '예상 가능한 상황'으로 간주하고 정상적으로 처리할 수 있도록 설계하는 것입니다. - 이 문제가 어떻게 해결되는가?
이번 이슈에 국한해서 본다면, 복구 로직(RestoreService)을 다음과 같이 수정하는 것을 생각해볼 수 있습니다.PurchaseRecovery테이블에서 읽어온 데이터에gatewayTxId가 없다면, 이를null로 처리하고 끝내는 것이 아니라, 메인Purchase테이블을 한번 더 조회하여 데이터를 채워 넣는 방어적인 코드를 추가하는 방식입니다.
// 예시: 하위 호환성이 강화된 복구 로직의 의사코드
public RestoredData restore(String orderId) {
PurchaseRecovery recoveryData = purchaseRecoveryRepository.findById(orderId);
// ✅ 방어적 코드 추가
if (recoveryData.getGatewayTxId() == null) {
// recovery 데이터에 id가 없다면, 메인 테이블을 조회하여 데이터를 보강
Purchase mainPurchase = purchaseRepository.findById(orderId);
recoveryData.setGatewayTxId(mainPurchase.getGatewayTxId());
}
eventStream.publish(new RestoreEvent(recoveryData));
return recoveryData.toRestoredData();
}- 장점
- 견고한 애플리케이션: 애플리케이션 자체가 다양한 데이터 버전에 대응할 수 있도록 견고해집니다.
- 배포 전략의 유연성: 애플리케이션이 하위 호환성을 보장하므로, 향후 배포 전략을 선택할 때 제약이 줄어듭니다.
- 고려할 점
- 코드 복잡도 증가: 하위 호환성을 위한 분기 및 예외 처리 로직이 늘어나 코드가 복잡해집니다.
- 성능 이슈: 데이터 보강을 위한 추가적인 DB 조회 등이 발생하여 시스템의 지연 시간(Latency)이 늘어날 수 있습니다.
결론: 정답은 없지만, 성장은 있었다
검토해본 대안들은 각각 명확한 장점과 트레이드오프를 가지고 있습니다. 어떤 기술이 이 상황에 대한 유일한 '정답(Silver Bullet)'이라고 말하기는 어려울 것 같아요. 기능 플래그는 가장 안전하지만 복잡하고, 고정 세션은 간단하지만 유연성을 해치며, 하위 호환성은 견고하지만 코드를 복잡하게 만듭니다.
5. 마무리하며: 이번 이슈가 남긴 것들
하나의 필드를 추가하는, 비교적 표준적인 기능 개발이 시작이었습니다. 안정성을 최우선으로 고려하여 업계 표준으로 통용되는 Canary 배포 전략을 택하고 있구요. 하지만 이 과정에서 QA팀에 의해 미묘하지만 치명적인 데이터 정합성 문제가 발견된 상황이었습니다.
결론적으로, 이 문제는 엄밀한 의미에서 버그는 아니었어요. 신/구 버전의 코드가 공존하는 '배포 중간 상태' 와, 최초 생성된 데이터를 이후의 과정에서 그대로 신뢰하는 '애플리케이션의 로직적 특성' 이 복합적으로 작용하여 발생한, 시스템 레벨의 문제였습니다.
이 분석 과정을 통해 얻게 된 몇 가지 핵심적인 교훈을 정리하며 글을 마무리하고자 합니다.
1. 배포 전략은 애플리케이션 설계의 일부다.
Stateless 아키텍처는 '모든 인스턴스가 동일하다'는 암묵적인 전제 위에서 동작합니다. 하지만 Canary 배포는 이 전제를 의도적으로, 그리고 일시적으로 무너뜨립니다.
이번 경험을 통해 배포 전략은 더 이상 인프라팀의 영역이 아니라, 애플리케이션 로직을 설계하는 단계에서부터 반드시 함께 고려되어야 할 핵심적인 요소임을 깨달았어요. 특히 데이터의 상태를 변경하는 로직은, 그것이 어떤 배포 전략 위에서 실행될지에 따라 전혀 다른 결과를 낳을 수 있습니다.
2. 스냅샷 데이터는 생성 시점의 맥락에 의존한다.
PurchaseRecovery 테이블의 데이터는 '구매 시점의 스냅샷'입니다. 문제는 이 스냅샷을 후속 로직이 아무런 의심 없이 '신뢰'한 것에서 비롯되죠.
데이터는 그것이 생성될 때의 코드 버전, 즉 '맥락'에 강하게 의존합니다. 따라서 버전이 다른 코드에서 과거의 데이터를 조회하여 사용할 때는, 이 데이터가 완전하다는 보장이 없음을 인지해야 합니다. 필요하다면 데이터를 사용하는 시점에서 다시 한번 유효성을 검증하거나 보강하는 방어적 로직을 고려해볼 필요가 있겠습니다.
3. Canary 환경에서의 QA는 최고의 통합 테스트다.
이 문제는 개발 환경이나 단일 버전으로 구성된 스테이징 환경에서는 절대 발견할 수 없습니다. 오직 신/구 버전이 혼재하며 실제 운영 트래픽을 처리하는 Canary 환경이었기에 수면 위로 드러날 수 있는 것입니다.
이는 실제 운영 환경에서 Canary 단계에서의 QA가 단순히 신규 기능의 동작을 확인하는 것을 넘어, 예상치 못한 버전 간의 상호작용까지 검증할 수 있는 최고의 '통합 테스트'임을 증명합니다. '해피 패스'를 넘어 복잡한 엣지 케이스를 검증하는 QA 프로세스의 중요성을 다시 한번 확인했습니다.
어쩌면 복잡한 분산 시스템에서 '완벽한 안정성'이란 달성하기 어려운 목표일지도 모릅니다. 그렇기에 시스템의 이상 신호를 조기에 감지하는 프로세스를 갖추고, 문제가 발생하면 근본 원인을 끝까지 추적하는 엔지니어링 과정이 필요합니다.