0. 이 글의 탄생 배경
이 글은 〈이벤트 드리븐 트러블슈팅〉 시리즈의 첫 번째 포스팅입니다.
결제팀 백엔드 엔지니어로 일하면서 비동기 방식으로 결제 이벤트를 처리하다 보면 재밌는 이슈를 자주 만나게 되는데요. 이번 글에서는 모바일 결제 파이프라인 + 카프카 조합에서 흔히 발생하는 타이밍 불일치 이슈를 중심으로, 문제 원인과 다양한 해결 전략을 살펴보겠습니다.
본문에 등장하는 아키텍처·컴포넌트·코드 그리고 일부 도메인 프로세스들은 실제 사내 구현과는 다르게 익명화·재구성한 가공 사례들입니다.
이번 편이 다룰 핵심 이슈
외부 결제사(e.g., Google Play) 반영 지연으로
비동기 결제 프로세스 과정에서
‘NOT_CONSUMED 상태의 영수증’ 오류가 다수 발생해
API·로그 폭주와 알람 노이즈가 커지는 문제
이번 편이 다룰 핵심 포인트
- 모바일 SDK → 검증 서버 → 카프카 → 컨슈머 → 비즈니스 처리 서버 ... || 구글 API로 구축된 결제 이벤트 파이프라인.
- 컨슈머가 “구독권 발행” 직전에 다시 영수증을 검증해야 하는 이유.
- 구글 API의 최종적 일관성 지연 때문에 생기는
NOT_CONSUMED예외 뜯어보기. - 불필요한 재시도·로그 폭주를 줄이기 위한 여러 가지 대응 전략과 해결책들 (현실 반영 100%).
1. 문제 상황: 구글 결제 API 지연과 서비스 영향
1.1 시스템 아키텍처
먼저 우리가 다룰 시스템의 아키텍처를 간략히 살펴보겠습니다.
flowchart LR
%% ─────────── Nodes ───────────
UA["사용자<br/>(모바일 앱)"]
PG["결제<br/>중개 서버"]
RV["결제<br/>검증 서버"]
K((카프카<br/>Topic))
G["Google Play<br/>Developer API"]
CX["컨슈머<br/>(이벤트 처리)"]
MS["메인 서비스 API"]
%% ─────────── Edges ───────────
UA -->|① 결제 요청| PG
PG -->|② 검증 요청| RV
RV -->|③ 결제 이벤트 발행| K
RV -->|④ 검증 결과 응답| PG
PG -->|⑤ consume 요청| G
K -->|⑥ 이벤트 소비| CX
CX -->|⑦ 영수증 검증| G
CX -->|⑧ 구독권 발행| MS
%% ─────────── Styles ───────────
classDef client fill:#FFF3BF,stroke:#E0CD94,stroke-width:2px,color:#222;
classDef service fill:#FFD5E5,stroke:#E4ADC6,stroke-width:2px,color:#222;
classDef infra fill:#C8FBDC,stroke:#9ADAA5,stroke-width:2px,color:#222;
classDef backend fill:#D6E4FF,stroke:#9BB3E4,stroke-width:2px,color:#222;
classDef external fill:#E4D7FF,stroke:#BBA8FF,stroke-width:2px,color:#222;
class UA client;
class PG,RV,CX service;
class K infra;
class MS backend;
class G external;
%% (optional) 기본 링크 스타일
linkStyle default stroke:#666,stroke-width:2px;
이러한 구조에서, 결제 흐름은 다음과 같이 이루어집니다.
- 사용자가 모바일 앱에서 상품을 구매하면 결제 정보가 결제 중개 서버에 전달됩니다.
- 결제 중개 서버는 이 정보를 결제 검증 서버에 전달합니다.
- 결제 검증 서버는 카프카에 결제 이벤트를 발행합니다.
- 그런 뒤 결제 중개 서버로 응답합니다.
- 결제 중개 서버는 정상 응답을 받으면 구글 결제 API에 영수증 소진을 요청합니다.
- 스텝 4,5가 진행되는 거의 비슷한 시각, 컨슈머는 스텝 3에서 발행된 이벤트를 받아 영수증을 검증한 후, 적절한 서비스 로직(예: 콘텐츠 구매 처리)을 실행합니다.
- 이 과정에서 구글 결제 API를 호출하여 영수증의 소비 여부를 확인합니다.
조금 더 디테일한 아키텍처로 그려보면 다음과 같습니다.
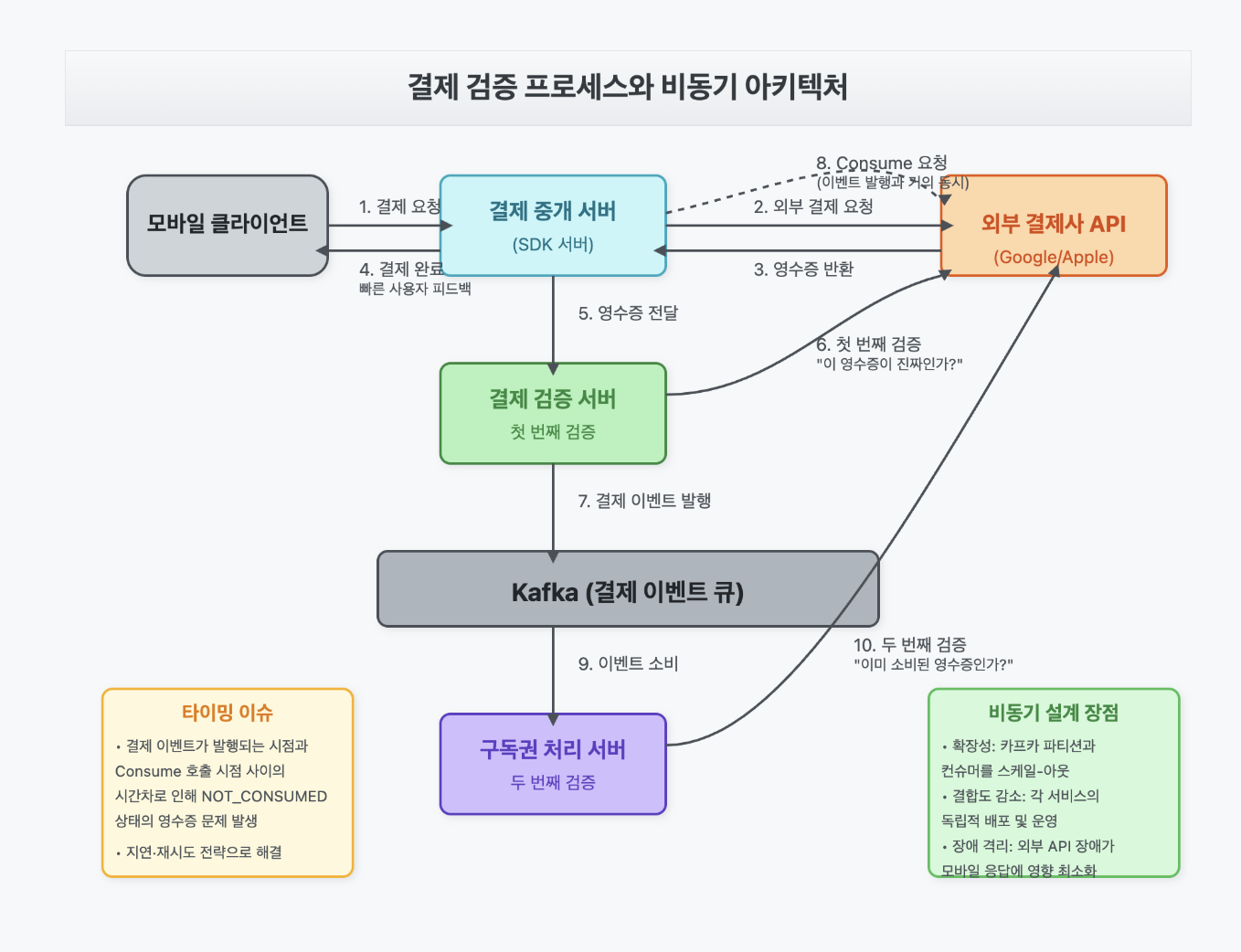
1.2 문제 정의
위 순서를 다시 살펴보면, 결제 검증 서버가 이벤트를 발행하는 시점(3번)과 결제 중개 서버가 구글 결제 API에 영수증 소진을 요청하는 시점(5번) 그리고 컨슈머가 이벤트를 소비하여 영수증을 검증하는 시점(6~7번)이 거의 동시에 이루어지고 있음을 알 수 있습니다.
- 결제 검증 서버 → 카프카 발행 (3)
+ 결제 검증 서버 → 결제 중개 서버 응답 (4)
→ 곧바로 결제 중개 서버 → 구글 API 소진 요청 (5)
→ 거의 같은 시각에 컨슈머 → 구글 API 검증 (7)
이때 구글 결제 API 측에서 영수증 소진 처리를 아직 완료하지 않은 상태에서, 컨슈머가 먼저 영수증 검증을 시도하면 “NOT_CONSUMED 상태의 영수증” 에러가 발생하게 됩니다.
즉,
- (거의 동시) 결제 중개 서버는 구글에
consumeAPI 요청 - (거의 동시) 컨슈머는 결제 이벤트를 받아 “영수증이 이미 소진되었는지?”를 확인
- 구글은 내부 반영에 약간의 지연이 있을 수 있음
- 컨슈머가 호출한 시점에는 여전히 NOT_CONSUMED 응답 (consumptionState=0)
- 결국 재시도가 발생하거나 에러 로그가 남음
[ 예시 타임라인 ]
10:43:51.000 - 결제 검증 서버가 카프카에 결제 이벤트 발행 (스텝 3)
10:43:51.001 - 결제 검증 서버가 결제 중개 서버로 응답 (스텝 4)
10:43:51.005 - 결제 중개 서버가 구글 결제 API에 영수증 소진(consume) 요청 (스텝 5)
10:43:51.006 - 컨슈머가 카프카 이벤트를 수신 (스텝 6)
10:43:51.010 - 컨슈머가 구글 결제 API로 영수증 검증 호출 (스텝 7)
10:43:51.011 - 구글 결제 API → 아직 영수증 소진 처리가 완료되지 않아 NOT_CONSUMED 응답
10:43:51.012 - 컨슈머에서 “NOT_CONSUMED 상태의 영수증” 예외 발생, 재시도 대기
10:43:51.639 - 구글 결제 API가 결제 중개 서버의 consume 요청을 처리 완료 (실제 소진 상태 반영)
10:43:51.640 - 컨슈머가 재시도 로직 발동 → 다시 구글 결제 API 검증 호출
10:43:51.641 - 구글 결제 API → 이번에는 CONSUMED 응답
10:43:51.642 - 정상 응답 수신, 구독권 발행 로직 수행
위 타임라인을 보면 핵심 문제는 동시 처리라는 것을 알 수 있죠.
카프카 이벤트 발행과 구글 API 영수증 소진이 순차적이 아니라 거의 동시에 진행되는 과정에서, 컨슈머가 이벤트를 너무 빨리 처리하여 결제 중개 서버가 영수증 소진을 완료하기 전에 검증을 시도하게 되는 것이죠.
결제 중개 서버의 소진 요청이 완료되기까지 약 630밀리초(10:43:51.005 ~ 10:43:51.639)가 소요되는데, 컨슈머는 이벤트 발행 직후 수 밀리초만에 구글 API를 호출하므로 소진 처리가 반영되지 않은 상태를 받게 됩니다.
궁금증 1: 구글 API가 응답을 빠르게 주면 되는 거 아닌가? 구글 API가 문제인건가?
결론부터 말하자면, 분산 환경에서의 ‘비동기 파이프라인의 순서 경합(race condition)’ 문제이며,
구글만의 결함이라기보다는 Google Play Billing이 채택한 최종적 일관성(eventual consistency) 모델의 특성입니다.
구글 공식 문서에서도 “소비(consume) 요청은 정상적으로 처리됐더라도, 모든 시스템 노드에 해당 상태가 반영되기까지 시간이 걸릴 수 있다”는 취지의 설명이 있습니다.
예컨데 Android 개발자 문서에서는 “구매 직후에 consumeAsync를 호출하고, 성공 콜백을 받은 다음 사용자에게 아이템을 지급하라”고 권장합니다. 이때 바로 콜백이 오지 않거나, 검증 시점에 아직 미소비 상태로 남아있을 수 있다는 점을 암묵적으로 가정하고 있습니다.
또 다른 문구를 살펴 보면,
“As consumption requests can occasionally fail, you must check your secure backend server to ensure that each purchase token hasn’t been used so your app doesn’t grant entitlement multiple times for the same purchase.”
“소비 요청(consume)이나 구매 확인(acknowledge)은 때때로 실패할 수 있으므로, 보안 백엔드에서 각 구매 토큰이 이미 사용(소비)된 상태인지 반복 확인해야 한다”는 가이드입니다.
“We recommend using exponential backoff for Play Billing Library operations that happen in the background… acknowledging new purchases… doesn’t need to happen in real time if an error occurs.”
구글은 백그라운드에서 일어나는 결제 라이브러리 작업(예: acknowledge/consume 등)에 대해 지수 백오프(exponential backoff) 같은 재시도 정책을 권장하고 있습니다.
정리하자면, 구글 API가 전혀 문제 없다고 단정할 수는 없지만, 이 현상은 분산 시스템에서 필연적으로 생길 수 있는 일시적 상태 불일치에 가깝습니다. 구글도 이를 오류가 아닌 정상 시나리오로 보고 있으며, 지연∙재시도∙상태 확인 로직 등으로 대응할 것을 가이드하고 있습니다.
따라서 “구글이 빨라지면 해결된다”기보다는, 우리 쪽에서 이를 전제로 재시도/폴링/지연 메커니즘을 마련하는 것이 현실적인 접근이라 할 수 있습니다.
궁금증 2: 정말 문제일까?
???: “한 번 더 호출하면 되긴 해”
이렇게 생각해보죠.
피크 타임 기준 분당 약 1 만 건 결제 중 3 %(≈ 300 건)가
NOT_CONSUMED 오류로 1 – 3 회 재시도됩니다.
→ 분당 최대 900 회의 추가 API 호출·ERROR 로그가 발생하며,
모니터링 알람 노이즈가 급증합니다.
즉, 체감상 분당 수천 번의 불필요 호출 + 다양한 모니터링 지표가 오염되어 실질적인 운영 비용이 무시할 수 없을 정도로 커진다는 점이 골치 아픈 지점입니다.
c.f. Google Play Billing 연동 API
이 글에서 언급되는 소비(Consume) 요청과 영수증 검증은 주로 Google Play Developer API(또는 Play Billing Library)로 처리됩니다.
아래와 같은 엔드포인트가 대표적이고, 보다 자세한 설명은 Google Play Developer API v3 공식 문서에서 확인할 수 있습니다.
주요 엔드포인트
엔드포인트 설명 HTTP 메서드 & 요청 예시
| purchases.products.get | 영수증(결제 정보) 검증 | http GET https://androidpublisher.googleapis.com/androidpublisher/v3/applications/{packageName}/purchases/products/{productId}/tokens/{token} |
| purchases.products.consume | 소비(Consume) 요청 | http POST https://androidpublisher.googleapis.com/androidpublisher/v3/applications/{packageName}/purchases/products/{productId}/tokens/{token}:consume |
purchases.products.get
- 용도: 영수증의 purchaseState(결제 상태) 및 consumptionState(소비 여부) 확인
- 응답 예시 필드
- purchaseState
- consumptionState
purchases.products.consume
- 용도: 아이템을 소비(Consume) 처리
- 성공 시 결과: 해당 영수증의 consumptionState가 1 (CONSUMED) 로 업데이트
NOT_CONSUMED (consumptionState = 0)
→ 글에서 언급하는 “NOT_CONSUMED 상태의 영수증”이 바로 이 경우를 뜻합니다.
2. 왜 이런 구조가 필요한가?
“컨슈머가 이벤트를 받았으면 바로 구독권을 발행하면 되지 않나?”
비동기식 결제 프로세스를 처음 접하면, “컨슈머가 이벤트를 받은 뒤 바로 구독권을 발행해도 되지 않을까?”라는 의문이 들 수 있습니다.
하지만 실제로는 구글(또는 기타 결제사)와의 영수증 검증이 필수적이고, 이를 안정적으로 대량 처리하기 위해서는 카프카 기반의 비동기 아키텍처가 요구됩니다. 아래는 구체적인 이유들입니다.
2.1 결제 신뢰성과 보안
결제를 수행하는 모바일 클라이언트만 믿고 구독권을 바로 발행하기에는 다양한 보안∙신뢰 이슈가 존재합니다. 결제 완료 화면을 봤다고 해서 실제로 결제가 확정된 것은 아닐 수 있고, 환불 또는 취소 상황이 뒤늦게 발생할 수도 있기 때문입니다.
따라서 서버-서버 간 외부 결제사 API를 통해 최종 결제 상태를 재검증하는 과정이 꼭 필요합니다.
▸ 모바일 클라이언트만으로는 불충분
- 클라이언트가 임의로 요청을 변조하거나, 통신 과정에서 결제 데이터가 조작될 가능성을 완전히 배제할 수 없습니다.
- 결제 직후 “결제 성공” 화면이 뜬다고 해서, 실제로 취소·환불이 이뤄지지 않는다는 보장은 없습니다.
▸ 서버-서버 검증 필요성
- 부정 결제 차단: 모바일-단 영수증은 손쉽게 조작될 수 있습니다. 서버-to-서버로 외부 결제사 API를 호출해 최종 결제 상태를 재검증해야만 “위조 영수증 → 구독권 발행” 사고를 막을 수 있습니다.
- 환불·취소 대응: 결제 직후엔 ‘성공’이었지만, 몇 분 뒤 사용자 취소·카드 한도 초과 등으로 자동 환불이 이루어질 수 있습니다. 두 번째 검증 단계가 있으면 “이미 취소된 주문인데 구독권이 발급됨” 상황을 예방합니다.
▸ 결제 시점과 소비(Consume) 시점 분리
- 사용자가 결제 버튼을 누른 시점에선 결제가 “진행 중” 상태일 뿐, 결제사(구글/애플 등)에서 최종적으로 소비 처리를 완료해야만 확정 결제가 됩니다.
- 이 두 시점이 정확히 일치하지 않기 때문에, 외부 결제사에 최종 확인을 거쳐야만 영수증이 정상적으로 “소진(Consumed)” 상태인지 판별할 수 있습니다.
2.2 멱등성과 데이터 정합성
- 같은 이벤트가 두 번 소비되더라도 구독권이 중복 발행되면 안 됩니다.
- 영수증 ID·주문 ID·사용자 ID를 컨슈머 단계에서 한 번 더 매칭해 중복 지급을 차단합니다.
- 이렇게 하면 _Exactly-once_가 완벽히 보장되지 않는 카프카 환경에서도 멱등한 결과를 얻을 수 있습니다.
2.3 비동기 설계의 장점
| 관점 | 이득 |
|---|---|
| 확장성 | 결제량이 급증해도 카프카 파티션과 컨슈머 수를 스케일-아웃해 버틸 수 있습니다. |
| 결합도 감소 | 결제 로직과 구독권 발행 로직을 큐로 분리해 각 서비스를 독립 배포·점검할 수 있습니다. |
| 장애 격리 | 외부 결제사 API가 느려져도 컨슈머만 지연되고, 모바일 결제 트랜잭션 자체는 즉시 응답할 수 있습니다. |
2.4 타이밍 이슈에 대비한 ‘이중 검증’
- 첫 번째 검증(Purchase 단계): “이 영수증이 진짜인가?”
- 두 번째 검증(Consumer 단계): “이미 소비돼서 재사용 불가 상태인가?”
- 두 단계를 분리해 놓으면 Google API의 eventual consistency 지연으로 한쪽이 실패해도 다른 단계에서 보완할 여지가 생깁니다.
2.5 현실적인 절충
- 즉시성을 100 % 지키려면 동기 consume까지 끝낸 뒤 카프카에 발행하는 구조가 가장 깔끔합니다.
- 하지만 그렇게 하면 결제 API 지연·장애 전파 위험이 급증하고, 모바일 사용자는 결제 완료 화면을 늦게 보게 됩니다.
- 따라서 현재 구조처럼 “검증 → 이벤트 발행 → (소진 처리) → 재검증” 순서를 택해 사용자 체감 딜레이와 시스템 안전성 사이에서 균형을 맞춘 것입니다.
그런데,
같은 서버에서 consume-까지 한 번에 처리하면 되는 거 아님?
과 같은 의문이 들 수 있습니다.
서버가 둘로 분리돼 있기 때문입니다.
- Consume 요청을 담당하는 서버
- 보통 결제 중개 서버가 담당합니다.
- 이 서버는 모바일 클라이언트와 직접 소통하며, 결제 완료 여부를 사용자에게 빠르게 안내해야 합니다.
- 클라이언트 환경이나 UI/UX에 특화된 로직을 가지고 있어, ‘SDK 역할’을 겸하고 있는 경우도 많습니다.
- Purchase 트랜잭션 검증 서버
- 구글, 애플, 기타 여러 마켓의 영수증 검증 로직을 통합적으로 처리합니다.
- 결제 데이터를 정형화하고, 정상/취소/중복 여부 등을 판별한 뒤 다음 트랜잭션 진행을 위한 이벤트를 발행합니다(카프카에 결제 이벤트 생성).
- 다양한 외부 결제 채널을 동시에 다룰 수 있도록 설계되어, 일반적인 결제 검증 로직과 내부 결제 정책 적용이 주 역할입니다.
결국, 소비(Consume) 요청은 사용자와 밀접하게 연결된 결제 중개 서버(일반적으로 말하는 SDK 서버)가 수행하지만, 정식 결제 이벤트 발행은 별도의 검증 서버가 맡는 식으로 역할이 분리되어 있습니다.
이로 인해 구글에 consume을 요청하는 타이밍과 카프카 이벤트 발행 후 컨슈머가 검증하는 타이밍이 거의 동시에 진행될 수밖에 없고, 바로 그 지점에서 ‘NOT_CONSUMED 상태의 영수증’ 이슈가 발생하게 됩니다.
그렇다 해도, 이러한 분산된 구조를 통해
- 사용자에게는 빠른 결제 완료 피드백을 주면서도,
- 다양한 결제 마켓을 안정적으로 확장∙운영하고,
- 동시 트래픽을 효율적으로 처리하며,
- 에러나 취소 흐름도 각 서버에서 잘 관리하도록
하는 장점들이 존재하지만, 동시에,
- 중개 서버가
consume()을 호출하는 순간 - 검증 서버는 이미 “결제 성공” 이벤트를 카프카에 발행하고 있음
→ 컨슈머가 이벤트를 너무 빨리 읽을 때의 정합성 문제가 발생하는 것이죠.
따라서 “검증 → 이벤트 발행 → (뒤늦은) consume → 재검증”이라는 다소 우회적인 순서를 두고, 컨슈머 쪽에서 지연·재시도 전략을 넣어 UX(빠른 응답)와 안정성(재검증) 사이에서 현실적인 균형을 찾아야 하는 상황인 것입니다.
3. 가능한 해결책들 그리고 트레이드오프
어떻게 해결할 수 있을까요?
4가지 대표적인 접근 방법을 소개하려고 합니다.
- Step 1 ― 지연 처리(Delay) 도입 → 가장 원초적이지만 효과가 즉각적
- Step 2 ― 재시도 메커니즘 & 지수 백오프 → 고정 재시도를 똑똑하게 조정
- Step 3 ― 비동기 큐 / 스케줄러 활용 → 지연과 재시도를 아예 별도 워커에 위임
- Step 4 ― 로그 관리·모니터링 개선 → “소음”을 줄이고 리소스를 효율적으로 사용
먼저 Step 1 지연 처리부터 살펴보겠습니다.
3-1. 지연 처리(Delay) 도입 – “조금만 늦춰도 달라진다”
아이디어 · 컨슈머가 이벤트를 받자마자 구글 API를 두드리지 말고 N 초 만큼 기다린 뒤 검증한다.
목표 · 결제 중개 서버의 consume() 요청이 구글 내부에 반영될 시간을 벌어 NOT_CONSUMED 확률을 낮춘다.
슈도 코드는 다음과 같습니다.
function handleKafkaEvent(event):
if 마켓이 GOOGLE_PLAY라면:
delayMs = 2000 # ← 설정값 (2초)
log.info("Delay {}ms before verify: {}", delayMs, event.paymentId)
sleep(delayMs) # 스레드 블로킹 방식
verifyAndPublish(event) # 영수증 검증 → 구독권 발행핵심 – 구현이 초간단. 단순히 Thread.sleep()(또는 TimeUnit.SECONDS.sleep(2) 등)만 추가하면 끝.
장점은 너무 명확합니다.
| 항목 | 내용 |
|---|---|
| 즉시 효과 | 지연 값(예: 2-3 초)만으로도 NOT_CONSUMED 오류가 대폭 감소한다. |
| 낮은 진입 장벽 | 새로운 인프라·라이브러리 없이도 몇 줄 코드로 적용 가능. |
| 모니터링 간단 | ‘지연 전/후’ 오류 건수 비교로 효과를 빠르게 확인할 수 있다. |
대신 단점도 분명하죠.
지연 처리는 정말 손쉽지만, 카프카 컨슈머 스레드를 강제로 멈춘다는 사실을 잊어서는 안 됩니다.
컨슈머가 sleep(2초)에 갇혀 있는 동안엔 같은 파티션의 다음 메시지를 읽을 수 없기 때문에 오프셋이 뒤로 밀리며 소비 속도가 급격히 떨어집니다. 트래픽이 평소보다 조금만 늘어도 Consumer Lag 그래프가 계단식으로 치솟고, 파티션마다 “Uncommitted offset”이 쌓여 처리량 저하 → 지연 악화 → 또다시 Lag 증가라는 악순환이 발생합니다.
또 다른 문제는 “고정 값의 아쉬움”입니다.
어떤 결제는 100 ms 만에 consume 반영이 끝나는데 우리는 무조건 2 초를 기다립니다. 반대로 구글 내부 지연이 길어지면 2 초로는 부족해 여전히 NOT_CONSUMED 예외가 터집니다. 즉, 짧게 잡으면 오류가 남고, 길게 잡으면 시스템 활용도가 떨어지는 딜레마가 존재합니다.
마지막으로, 지연을 넣어도 완벽한 해결은 아니다라는 점입니다. 구글 Play Billing 쪽 반영이 4-5 초 이상 걸리는 드문 케이스에선 여전히 첫 호출이 실패하고 재시도가 필요합니다. 결국 _딜레이_만으로는 ‘언젠가는 재시도해야 한다’는 본질을 없애지 못합니다.
그러면 언제쓸 수 있을까요?
- PoC 단계 – “일단 오류 폭주를 줄여야 한다” 는 급한 불.
- 트래픽이 크지 않은 서비스 – 컨슈머 스레드 몇 개만 블로킹해도 여유가 있을 때.
- 리소스가 제한된 팀 – 인프라를 늘릴 여력보다 “빨리 납득할 만한 수치 개선”이 필요한 경우 (?!).
말 그대로 지연 처리는 ‘첫 단추’를 꿰는 방법일 수 있지만, 근본적으로 너무 결함이 많은 해결책입니다.
다음 단계에서는 재시도 메커니즘을 지수 백오프로 개선해, 불필요한 대기 시간을 줄이고 동시에 에러도 줄이는 방식을 살펴보겠습니다.
3-2. 재시도 메커니즘 개선 – 고정 ↔ 지수 백오프
앞서 살펴본 지연 처리 방식은 간단하고 즉각적인 효과가 있지만, 모든 이벤트에 똑같이 대기 시간을 적용한다는 한계가 있습니다. 지연 시간이 너무 짧으면 NOT_CONSUMED 오류가 여전히 발생하고, 너무 길면 전체 처리 속도가 느려지며 자원 낭비가 심해집니다. 또한 구글 결제 API 쪽 지연이 변동적이라는 점을 고려하면, 고정된 지연은 최적화가 까다롭습니다.
이에 대한 보다 유연한 대안이 재시도 메커니즘입니다.
아이디어 · “무조건 2초 뒤 한 번 더” 대신, 실패 횟수에 따라 간격을 늘려 API를 두드린다.
목표 · 불필요한 동시 호출·로그를 줄이고, 그래도 안 되면 일정 시점에 DLQ(Dead-Letter Queue) 로 넘긴다.
(1) 기존 고정 지연(Fixed Delay) 재시도
가장 많이 쓰는 패턴은 “N 초 간격 × M 회” 입니다.
maxAttempts = 3 # 총 3번
delayMs = 2000 # 2초 고정
for attempt in 1..maxAttempts:
try:
verifyReceipt()
break # 성공 → 루프 탈출
except NotConsumedError:
if attempt == maxAttempts:
pushToDLQ(event) # 복구용 큐로 이동
else:
sleep(delayMs) # 2초 후 재시도
지연을 미리 예측하는 것이 아니라 동적으로 재시도를 함으로써 불필요한 전체 대기 시간을 줄일 수 있죠. 첫 1–2 초 사이에 영수증이 CONSUMED로 바뀌는 케이스가 대부분이라면, 실제로는 1 회 재시도로 끝나는 경우가 많아 전체 지연이 길지 않을 수도 있으니까요.
‘언젠가 되겠지’와 같은 상황을 일정 횟수(또는 일정 시간)까지는 유연하게 수용하면서 “적당히 실패를 무시하고, 적당히 빨리 재시도”라는 심플한 해법입니다.
그러나 어떤 문제가 있을까요? 어느 시점에 컨슈머 스레드가 동시에 같은 영수증을 재시도하면 API 폭주 → ERROR 폭주 → Consumer Lag 폭주, 삼박자가 한꺼번에 밀려옵니다. 지연을 너무 짧게 잡으면 여전히 NOT_CONSUMED, 너무 길게 잡으면 평상시에도 2 초씩 낭비합니다.
예를 들어, 재시도 간격이 모두 1초씩 동일하다면,
- 일부 케이스는 1초면 충분하지만
- 어떤 케이스는 1초로는 부족해 또 실패하고, 결국 총 2~3초 지연이 누적됨
결국 “고정 지연”만으로는 타이밍 분포가 넓은 실제 트래픽을 다 커버하지 못합니다.
(2) 개선안 – 지수 백오프(Exponential Backoff)
그래서 이를 개선하는 방법이 지수 백오프(Exponential Backoff)입니다. 이 방식은 재시도 간격을 2¹·2²·2³… 식으로 키워 주파수를 자연스럽게 쪼개 줍니다.
실패할수록 천천히, 성공하면 즉시.
baseDelayMs = 200 # 최초 200 ms
factor = 2 # 2배씩 증가
maxDelayMs = 3000 # 최대 3초
maxAttempts = 5
for attempt in 1..maxAttempts:
try:
verifyReceipt()
break
except NotConsumedError:
if attempt == maxAttempts:
pushToDLQ(event)
else:
wait = min(baseDelayMs * factor^(attempt-1), maxDelayMs)
jitter = random(0, wait * 0.2) # 20% 지터
sleep(wait + jitter)
| 시나리오 | 평균 호출 수 | 호출 간격 패턴 |
|---|---|---|
| Fixed(2 s × 3) | 3 회 | 0 s → 2 s → 4 s |
| Backoff(0.2 s → 0.4 s → 0.8 s …) | ≈ 2 회 (소진이 500-800 ms 내 반영되는 케이스 대부분) | 0 s → 0.2 s → 0.4 s … |
통계적으로 단순 리트라이 방식에서 평균 3 회의 재요청이 발생했을 때 이를 1.7 회까지 줄일 수 있어, API 트래픽 ∼40 % 감소 시킬 수 있겠구요. ERROR 로그도 같은 비율로 줄것입니다.
비동기 프로세스에서 정합성을 보정하는 해결책으로 실제로 실무에서도 꽤 많이 쓰이는 해결책입니다. 구글 측 문서에서도 “Play Billing 관련 작업은 지수 백오프를 쓰라”고 가이드하고 있구요.
실패할 때만 대기하므로, 성공 이벤트는 즉시 처리 - 짧은 대기로 해결되는 경우가 많아, 불필요 대기 최소화를 시킬 수 있고, 또한 Retry 횟수·백오프 커스텀으로 다양한 정책 적용 가능합니다.

그런데 이게 정말 최선일까요?
사실 여전히 해결되지 않은 문제가 하나 남아 있습니다. 바로 컨슈머 스레드 블로킹 이슈입니다. 지수 백오프가 재시도 간격을 좀 더 똑똑하게 조정해주더라도, 재시도 중에는 컨슈머 스레드가 sleep()으로 멈춰 있다는 사실이 바뀌지 않습니다.
만약 카프카를 수동 커밋 모드로 사용하면서, 정상 응답이 모두 온 뒤에 오프셋을 커밋하는 구조라면 어떨까요? 지수 백오프된 재시도가 완전히 끝나야만 오프셋이 커밋될 것이고, 그동안 스레드는 계속 sleep() 상태입니다. 즉, 파티션 자체가 잠긴 것처럼 멈춰 있게 되는 셈이죠.
이렇게 되면 다른 메시지들을 처리하지 못해 전반적인 처리량이 급격히 떨어질 수 있습니다.
아래 그림처럼, offset=100을 처리하다가 검증 실패 → 재시도하는 동안 101, 102… 이후 메시지는 대기열에 묶여 Lag이 쌓이게 됩니다.
┌───── Kafka Partition P0 ─────┐
│ offset 100 │ 101 │ 102 … │
└────▲────────┴─────┴──────────┘
│ poll() & process(100) ←─┐ ← verify 실패
│ │
│ retry #1 (0.2 s) │ ← 스레드 블로킹
│ retry #2 (0.4 s) │
│ retry #3 (0.8 s) │
│ retry #4 (1.6 s) │
│ retry #5 (3.0 s) │
│ │
└─ commit offset 101 ─────┘ ← 4.0 s 뒤에야 커밋- Lag 증가 – 4 초 동안
101, 102…메시지는 대기열에 잔류 - Throughput 저하 – 파티션 수가 N, 컨슈머 스레드가 N 이라면 전체 소비량이 그대로 N 배 느려짐
“그렇다면 이벤트를 받자마자 오프셋을 커밋하면 되지 않나?”라고 생각할 수도 있지만, 그러면 실패 시 로그/데이터를 어떻게 처리할지 문제가 생깁니다. 이미 커밋된 이벤트는 재부팅 후 재처리가 곤란하고, DLQ(Dead Letter Queue)로 옮기기도 쉽지 않습니다. 일괄 커밋 구조라면 다른 메시지까지 한꺼번에 커밋되는 리스크가 있죠.
| 시나리오 | 장점 | 새로 생기는 위험 |
|---|---|---|
| 선커밋 | Lag 0, 소비량 유지 | · 검증 끝나기 전에 프로세스가 다운되면 영구 유실 · 성공 여부를 DLQ나 DB가 대신 추적해야 함 |
| 후커밋 | 멱등성 보장 (성공 후만 커밋) | Lag·Throughput 문제 |
결국 “커밋 시점 ↔ 재시도 시점”을 완전히 분리하지 않는 한, 지수 백오프만으로는 트래픽 ↔ 처리량 두 마리 토끼를 동시에 잡기 어렵습니다.
Inbox/Outbox 그리고 DLQ의 필요성
이런 한계를 좀 더 우아하게 해결하기 위해, Inbox/Outbox나 지연 큐(Delayed Queue) 등을 활용하는 방법도 있습니다. 즉, 재시도 로직을 아예 별도 데이터 스토어나 워크플로우 시스템으로 분리해서 운영하는 것입니다. (자세한 아키텍처 고도화 방안은 뒤 섹션에서 살펴봅니다.)
예를 들어, 인박스(Inbox) 패턴에서는 컨슈머가 카프카에서 읽은 이벤트를 DB에 빠르게 저장하고, 워커(Worker)가 그 DB를 폴링하며 지수 백오프 재시도를 진행합니다. 이 경우 컨슈머 스레드는 ‘읽기 & 저장’에만 집중하여 Lag가 쌓이지 않고, 검증 로직은 비동기로 처리되므로 멱등성·DLQ 운영도 유연해집니다.
flowchart LR
%% ───────── Nodes ─────────
A((Kafka Topic))
C[Consumer]
D[(Inbox DB)]
W[[Verification Worker]]
G[[Google Play API]]
DLQ[(DLQ)]
%% ───────── Edges ─────────
A -->|① poll| C
C -->|② write| D
C -->|③ commit offset| A
D -->|④ poll| W
W -->|⑤ verify| G
W -->|✔ success| D
W -->|✖ max-retry → DLQ| DLQ
%% ───────── Styles ────────
classDef source fill:#C8FBDC,stroke:#9ADAA5,stroke-width:2px,color:#222;
classDef consumer fill:#FFD5E5,stroke:#E4ADC6,stroke-width:2px,color:#222;
classDef store fill:#D6E4FF,stroke:#9BB3E4,stroke-width:2px,color:#222;
classDef worker fill:#FFF3BF,stroke:#E0CD94,stroke-width:2px,color:#222;
classDef external fill:#E4D7FF,stroke:#BBA8FF,stroke-width:2px,color:#222;
class A source;
class C consumer;
class D,DLQ store;
class W worker;
class G external;
linkStyle default stroke:#666,stroke-width:2px
즉, 카프카 컨슈머는 이벤트를 빠르게 Persistence한 후 Ack(오프셋 커밋) 하고 반환해버리고, 실제 검증 + 재시도 로직은 배치나 스케줄러 워커가 비동기로 진행하는 구조입니다. 이렇게 하면,
- 컨슈머 스레드가 블로킹되지 않고
- 재시도 로직은 DB나 별도 큐에서 유연한 백오프, DLQ 처리 등을 구현 가능
반대로 Outbox 패턴은 반대 방향(프로듀서 측)에서 “이벤트 + 비즈 트랜잭션”을 원자적으로 남겨 카프카로 전파하는 방식입니다.
구체적인 구현 관점에서는 RDB + CDC(Change Data Capture)로 Outbox 이벤트를 Kafka로 내보내거나, 다른 MQ 혹은 다른 토픽을 이용한 2차 큐를 두기도 합니다.
어떤 방식을 택하든 핵심은 “검증 · 재시도 · 실패 격리” 책임을 카프카 컨슈머 바깥으로 이동시켜,
- 메시지 소비 속도는 유지하면서
- 유실 없이 멱등성·백오프·DLQ를 전담 워커/큐로 깔끔하게 운영한다는 점입니다.
결론적으로, 이처럼 컨슈머 내부에서 “sleep + retry”를 강행하기보다는, 별도 단계로 재시도를 이관하면 카프카 Lag 문제를 완화하고 확장성도 늘릴 수 있습니다.
- 지수 백오프만으로도 호출·로그를 ~40 % 줄일 수 있다.
- 하지만 컨슈머 스레드가 blocking되는 한 Lag 폭발을 완전히 막을 수는 없다.
- 커밋 타이밍을 앞당기면 유실 위험이 생기고, 이를 안전하게 다루려면 Inbox/Outbox + 워커 분리 같은 설계가 필요하다.
물론 이런 아키텍처 변경은 DB 테이블 관리, 별도 프로세스 구현, 모니터링 등 복잡도가 크게 늘어나는 단점이 있습니다. 결제 검증처럼 매우 중요한 도메인이라면 그만큼 투자 가치가 있지만, 모든 서비스에 적용하기엔 부담스러울 수 있습니다.
결론적으로, 컨슈머 내부에서 sleep + retry를 고집하기보다는 “재시도”를 다른 단계로 이관하는 편이 Lag 문제를 완화하고 시스템 확장성도 높이는 길입니다.
다음 섹션에서 소개할 비동기 큐 / 스케줄러 활용 방법은 이 아이디어를 더 확장한 형태입니다.
“딜레이나 재시도를 아예 별도 작업자에게 맡기면 어떨까?” 하는 접근이죠. 이제 조금 더 구체적인 구현 사례를 살펴보겠습니다.
3.3 비동기 큐·스케줄러 활용 ─ 재시도를 “컨슈머 밖”으로
“지연과 재시도를 메인 플로우에서 빼자.”
앞서 살펴본 방식들(단순 지연 처리, 지수 백오프)에서 근본적으로 아쉬운 점은, 카프카 컨슈머 스레드가 재시도 과정에 발이 묶일 수 있다는 것입니다. 그렇다면, 재시도 로직을 아예 컨슈머 바깥으로 분리해보면 어떨까요?
핵심 아이디어는 다음과 같습니다:
- 카프카 컨슈머는 메시지를 수신하되, 영수증 검증을 바로 진행하지 않고, 별도의 “지연 큐”나 “스케줄러”에게 이 임무를 넘긴다.
- 컨슈머는 즉시 커밋(또는 빠른 시점에 커밋)해 카프카 Lag을 최소화한다.
- 지연/재시도 로직은 큐 혹은 스케줄러가 전담하여, 원하는 시점(수 초 뒤, 수 분 뒤 등) 또는 백오프 규칙대로 실행한다.
- 최종 영수증 검증이 성공/실패로 끝나면, 결과만 컨슈머 혹은 다른 서비스로 통보한다.
Kafka Topic
▼ (fast)
┌─────────────────┐
│ Consumer │ ① 이벤트만 Inbox 테이블로 INSERT
└─────────────────┘
▲ commit offset 즉시
│
└──────┐
│ Poll ┌────────────────────┐
└──────────────▶│ Verification Worker │
└────────────────────┘
│ ② 지연·재시도·백오프
▼
구글 API / DLQ앞에서 살펴본 Inbox 패턴을 활용한 것입니다.
어떤 장점이 있을까요 ?
컨슈머-내 재시도 방식은 스레드가 sleep() 에 묶여 있는 동안 새 메시지를 못 읽습니다.
예를 들어 verify 200 ms + 재시도 2 회(400 ms) = 1 초/건이면 1 스레드가 고작 1 TPS밖에 못 냅니다. 16 파티션-16 스레드로 돌려도 약 30 TPS가 한계이니, 트래픽이 폭주하면 Kafka Lag가 눈덩이처럼 불어납니다.
반면 “읽고 INSERT 후 즉시 커밋” 구조에선 한 건을 처리하는 데 2 ms(INSERT 1 ms + 커밋 1 ms)면 충분합니다. 같은 하드웨어로 1 스레드 ≈ 500 TPS, 16 스레드면 약 8 000 TPS까지 선형 확장—두 자릿수였던 처리량이 세 자릿수로 뛰는 셈이죠.
- Kafka Lag 0에 수렴: 컨슈머가 블로킹을 없애자 대기 메시지가 사라집니다.
- 백오프 자유도 UP: 워커가
attempt수에 따라 200 ms→400 ms→800 ms처럼 얼마든지 늘려 설정할 수 있습니다. - 장애 격리: 컨슈머와 워커를 서로 다른 디플로이, 다른 스케일 팟으로 두면 한쪽 장애가 전파되지 않습니다.
- 운영 가시성: Outbox 테이블을 대시보드화하면 Pending·Retrying·Dead 현황을 한눈에 볼 수 있어 로그 grep 지옥에서 해방됩니다.
- API 보호: 워커 풀 크기만 조절하면 외부 결제사 호출 동시수를 딱 원하는 수준에 맞출 수 있습니다.

그런데 이 방식도 장점만 있지는 않죠.
가장 큰 단점은 무엇보다 복잡도가 급격히 상승한다는 것입니다. 그냥 편안하게 생각해보면 참 쉬운 해법 같은데요. 과연 그럴까요?
컨슈머 → Outbox INSERT → 워커 → DLQ(또는 성공 테이블)로 이어지는 별도 파이프라인을 하나 더 운영해야 하니, 코드·DB·모니터링 화면이 모두 늘어납니다. 워커가 장애로 중단되면 “카프카 Lag 0인데 실처리는 안 되는” 기이한 상태가 생기므로 헬스 체크·오토스케일·알람까지 챙겨야 합니다.
다음은 저장소·I/O 부담입니다. 초당 수천 TPS의 이벤트를 그대로 RDB에 INSERT 하면 인덱스 페이지가 빠르게 커집니다. 파티션 키를 잘못 잡으면 단일 PK 히트로 락 경합이 발생할 수도 있습니다. “로그 쓰듯 가볍게 적겠다”는 의도로 시작했는데, 어느 순간 DB 튜닝이 주업무가 될 수 있죠.
또 하나, 지연 허용치 문제입니다. 워커 폴링 주기(예: 1 초) + 첫 backoff(200 ms)만 해도 사용자 입장에서 1 초 넘어가면 “구독권이 왜 아직 안 열려?”라고 문의가 올 수 있습니다. UX 요구가 “결제 후 즉시 구독 시작”이라면, 워커 아키텍처만으로는 역부족이라 캐시 발급 → 사후 검증 같은 추가 설계를 얹어야 합니다.
마지막으로 데이터 생명주기 관리가 번거롭습니다. 성공·실패·DLQ 레코드를 언제 삭제할지, GDPR/개인정보 파기 정책과 충돌하지 않는지, 재처리 시나리오까지 정의해야 합니다. 단순히 “로그 레벨 바꿀 바에야 제대로 관리해보자”로 시작했지만, 운영 단계에서 규정·보안·감사 이슈가 한꺼번에 쏟아질 수 있습니다.
결국, 큐·스케줄러 방식은 “Throughput이 중요하고, 재시도·멱등성을 확실히 보장해야 하며, 이를 위해 복잡도를 감당할 준비가 된” 팀에게 어울립니다. 작은 서비스라면 단순 지연이나 지수 백오프만으로도 충분하고, 대규모 결제 시스템이라면 Outbox + 워커 구조가 장기적으로 더 저렴할 수 있습니다.
그래서 이제 마지막 방법입니다.
3.4 단순 로그 관리 개선
이쯤에서 다시 한 번, 문제의 본질을 돌아볼 필요가 있습니다. 사실 많은 경우 “NOT_CONSUMED 상태의 영수증” 오류는 수 초 안에 재시도하면 해결되는 정상 동작에 가깝습니다. 그럼에도 불구하고 이 오류가 쏟아져 나오며 로그·알람 폭주를 일으켜, 실제 장애와 구분하기 어려워지는 것이 골치 아픈 포인트였던 것이구요.
그렇다면 아예 이 오류를 ‘치명적 에러’ 수준으로 기록하지 않는 것도 하나의 방법입니다. 예를 들어,
NOT_CONSUMED가 떴을 때 INFO나 DEBUG 레벨로만 찍고, 재시도 후에도 실패할 때에만 ERROR 레벨로 로그를 남긴다.- 모니터링·알람 시스템에서 특정 예외(예:
NotConsumedException)는 별도 통계로만 관리하고, 일괄 재시도 후에도 실패가 반복되는 비율이 일정 기준을 넘으면 그때서야 알람을 발송한다.
이처럼 불필요한 소음(Noise)을 줄이고, “진짜로 처리 불가한” 문제만 에러로 취급하는 것입니다. 이렇게 로그와 알람 정책을 미세 조정함으로써,
- 운영 비용: ‘24시간 알람 대기’ 업무 부담을 크게 덜고
- 오류 로그 분석: 실제 심각한 장애와 단순 지연 오류를 명확히 구분
이 방식을 적용하면, 사실상 시스템 내부에서의 “소진 지연”은 기술적 해결 없이도 어느 정도 수용이 가능합니다.
또 하나 추가할 수 있는 방안은 로그 샘플링을 통해 특정 오류 로그만 일정 비율로 남기는 것입니다. 예를 들어 Spring Boot나 Logback 설정을 통해 NotConsumedException 로그를 DEBUG 레벨로 전환하고, 필요한 경우 샘플링 비율을 지정할 수도 있습니다.
logging.level.my.payment.NotConsumedError=DEBUG
logging.pattern.level=%5p
logging.filter.sample.rate=0.1 # 예: 10%만 로그로 남김- 샘플링 비율을 10%로 두면,
NotConsumedError가 대량 발생해도 일부만 기록됩니다. - “정상적으로 해결되는 지연 케이스”는 대체로 무시하고, 특정 구간에 ‘오류 폭주’가 있는지 정도만 파악하기 좋습니다.
- 다만 디버깅이 필요할 때 충분한 로그 확보가 어려울 수 있으므로, 운영 상황에 맞춰 동적으로 샘플링 비율을 조정하는 게 바람직합니다.
실제 사용자 경험에 큰 악영향을 주지 않는다면, 로그 레벨 및 모니터링 기준만 슬기롭게 조정해도 운영 피로도를 크게 낮출 수 있습니다. 예컨대 결제 성공 직후 구독권이 1~2초쯤 늦어지더라도, 사용자 UX 측면에서 괜찮다면 충분히 “눈감아줄” 수 있겠죠.
이처럼 간단한 로그·알람 정책 수정만으로도, 때로는 복잡한 시스템 변경보다 훨씬 큰 운영 편익을 얻을 수 있습니다.
기술적으로 ‘완벽’하더라도 팀 규모·우선순위·ROI가 맞지 않으면 오히려 부담만 늘어날 수 있습니다.
“적당히, 그러나 똑똑하게” 문제를 줄이는 것도 실무에서 매우 중요한 전략입니다.
4. 결론
모바일-결제 → 카프카 → 구독권 발행이라는 비동기 파이프라인에서 발생가능한 구글 결제 API 지연으로 인한 이슈 를 살펴보았습니다.
이 문제는 분산 시스템에서 흔히 벌어지는 타이밍 불일치 이슈의 전형적인 사례입니다. 사실 큰 장애라기보다는, “시간이 조금만 지나면 해결될” 정상 범위 내 지연이 대부분이죠. 그럼에도 불구하고 불필요한 오류 로그나 재시도 로직으로 인해 운영 효율이 떨어지고, 간혹는 진짜 장애와 혼동해 시간을 허비하게 만듭니다.
본 글에서는 그 대처 방안으로,
- 지연 처리(Delay) 도입
- 재시도(Retry) 메커니즘과 지수 백오프
- 비동기 큐·스케줄러 활용
- 단순 로그 관리·모니터링 개선
등 4가지 접근 방법을 소개했습니다. 각 방법마다 장단점과 적용 시나리오가 다르며, 실제 현업에서는 조합하여 사용하는 사례가 많을 것 같네요!
때로는 가장 단순한 해법만으로도 충분할 수 있고, 인프라와 리소스가 넉넉하다면 대규모 트래픽을 감당하는 확실한 아키텍처를 구축해 장기적 확장성과 안정성을 보장할 수도 있을 것입니다.

Refrenece
- https://developers.google.com/android-publisher/api-ref/rest/v3/purchases.products/consume
- https://developers.google.com/android-publisher/api-ref/rest/v3/purchases.products/get
- https://developer.android.com/google/play/billing/integrate
- https://kafka.apache.org/documentation
'이슈와해결' 카테고리의 다른 글
| 멀티 인스턴스 환경에서 살아남기 Ep. 1: Canary 배포와 데이터 정합성 (2) | 2025.08.16 |
|---|---|
| 이벤트 드리븐 트러블슈팅 Ep. 2: 사라진 혜택, 중복된 포인트? Kafka 메시지 처리, 어디까지 믿어야 할까 (1) | 2025.06.01 |
| [시스템 디자인 챌린지 - 문제 요구 사항] MAU 2천만 대형 블로그 플랫폼에서 1백만 명 유저가 어느 날 자정, 동시 예약을 걸었다면? (16,667 TPS 쓰기 요청을 감당해보자) (5) | 2025.05.01 |
| 대기열 기반 예약 시스템에서 MSA와 EDA를 이용해 느슨한 결합 추구하기 (0) | 2024.08.11 |
| 대기열 시스템 다양한 설계 방법 탐구 (feat. 레디스와 카프카를 이용한 O(1) 최적화) (2) | 2024.08.10 |



