이 글의 탄생 배경
'테코테코'라는 이름으로 9개월째 코딩 테스트 및 알고리즘 스터디를 꾸준히 이어오고 있습니다. 이번 주, 저희 스터디는 드디어 '정렬' 파트에 들어섰는데요. 그 첫 순서로 버블 정렬과 삽입 정렬을 다루게 되었습니다.
버블 정렬과 삽입 정렬은 제일 간단한 정렬입니다. 이들의 작동 메커니즘과 시간 복잡도, 그리고 쓸모에 대해서 이야기했습니다. 스터디원들 모두가 동의하는 사실이 있었습니다. 바로 이 두 정렬은 시간 복잡도가 $O(n^2)$으로, 가장 느리고 비효율적인 알고리즘이라는 것이었습니다.
'느리니까 쓸모없다.' 정말 이 한마디로 모든 것이 설명될까요?
이 글은 바로 그 질문에서부터 시작되었습니다. 이론적인 효율성만으로는 설명되지 않는 알고리즘의 숨겨진 가치와 '맥락'의 중요성을 탐구해 본 기록입니다.
"느린 정렬"은 정말 항상 느릴까?
"버블 정렬? 삽입 정렬? 그거 $O(n^2)$이라 느려서 잘 안 쓰잖아요."
아마 전공자나 개발자라면 한 번쯤은 들어봤을 법한, 혹은 직접 해봤을 법한 이야기입니다. 알고리즘 수업 첫 시간에 배우는 이 정렬 방식들은 '이론적으로 비효율적인' 알고리즘의 대표 주자로 꼽히곤 하죠. 시간 복잡도라는 흔한 척도 앞에서, 이들은 더 빠른 $O(n \log n)$의 퀵 정렬이나 병합 정렬에 밀려 '연습용' 혹은 '교육용'이라는 꼬리표가 붙기 일쑤입니다.
사실상 백엔드 개발 실무에서 "버블 정렬"을 직접 구현해서 쓰는 일은 당연히 거의 없을 겁니다. Java와 같은 언어 수준에서 이미 듀얼 피봇 퀵 정렬(Dual-Pivot Quicksort) 등 고도로 최적화된 정렬 알고리즘을 풍부하게 지원해 주니까요.
그런데 '느리다'는 한 마디로 이 알고리즘들의 모든 것을 설명할 수 있을까요? 교과서에서는 대부분 "무작위로 뒤섞인 n개의 데이터"를 가정하고, 최악의 경우를 대비해 안전한 선택을 하라고 가르칩니다. 하지만 현실의 데이터는 전혀 그렇지 않을 때가 많습니다. 백엔드 개발자들이 실제로 다루는 데이터는 대체로 다음과 같을 텐데요.
- 시간 순으로 차곡차곡 쌓이는 로그 파일들
- 이미 카테고리별로 어느 정도 분류된 상품 목록
- 새로 추가된 몇 개의 항목이 섞인 기존의 정렬된 리스트
이런 '현실적인' 데이터 앞에서도 과연 삽입 정렬은 무력하기만 할까요?
이런 작은 의문에서 이번 실험은 시작되었습니다. 실제 성능에는 Big-O 표기법만으로는 절대 알 수 없는 더 많은 요소들이 관여할 것입니다. 메모리 접근 패턴과 캐시 효율성, CPU의 분기 예측 성공률, 심지어 비교(comparison)와 교환(swap) 연산의 실제 비용 차이까지도 말이죠.
과연 어떤 데이터에서 이 '느린' 정렬 알고리즘들이 반전의 매력을 보여줄 수 있을지, 그리고 '빠른' 알고리즘은 어떤 조건에서 발목을 잡힐 수 있는지 직접 눈으로 확인해 보겠습니다.
버블 정렬 vs 삽입 정렬 : 알고리즘 한눈에 훑어보기
본격적인 실험 결과 분석에 앞서, 오늘 비교의 주인공인 버블 정렬(Bubble Sort)과 삽입 정렬(Insertion Sort)의 기본적인 작동 원리와 특징을 간략하게 짚어보겠습니다.
두 알고리즘에 대한 보다 상세한 내용은 글은 아래를 참고해주세요.
버블 정렬 (Bubble Sort) - 아이디어, 작동 원리, 성능 및 시간 복잡도, 특징, 자바 구현 코드
버블 정렬 비교 기반 알고리즘 중 가장 기초가 되는 버블 정렬에 대해 살펴본다. 아이디어 오름차순 정렬이라고 할 때, 모든 인접한 두 값을 비교하여 왼쪽의 값이 더 큰 경우 자리를 하나씩 바
upcurvewave.tistory.com
핵심 동작 원리
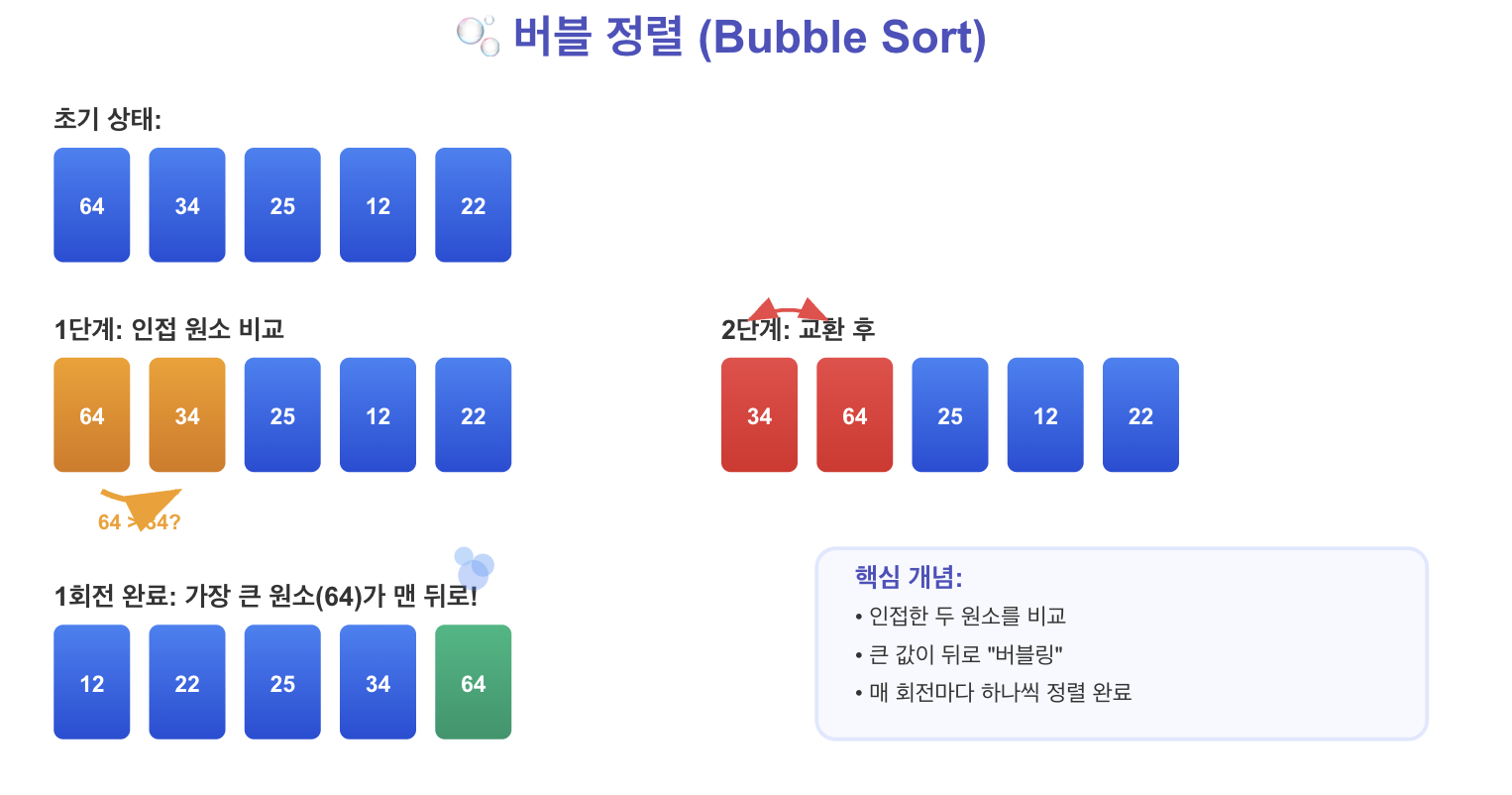
1. 버블 정렬 (Bubble Sort)
마치 거품이 수면 위로 떠오르는 것처럼, 인접한 두 원소를 비교하여 순서가 맞지 않으면 교환(swap)하는 과정을 반복합니다. 이 과정을 한 번 거칠 때마다 가장 큰 (혹은 가장 작은) 원소가 배열의 맨 뒤 (혹은 맨 앞)로 '밀려나는' 형태를 띱니다. 이러한 비교 및 교환 과정을 배열의 모든 원소에 대해 반복하면 결국 배열이 정렬됩니다.
간단 요약:
- 비교 대상: 인접한 두 원소
- 동작: 순서가 틀리면 교환
- 특징: 매 반복마다 가장 크거나 작은 원소가 제 위치로 이동
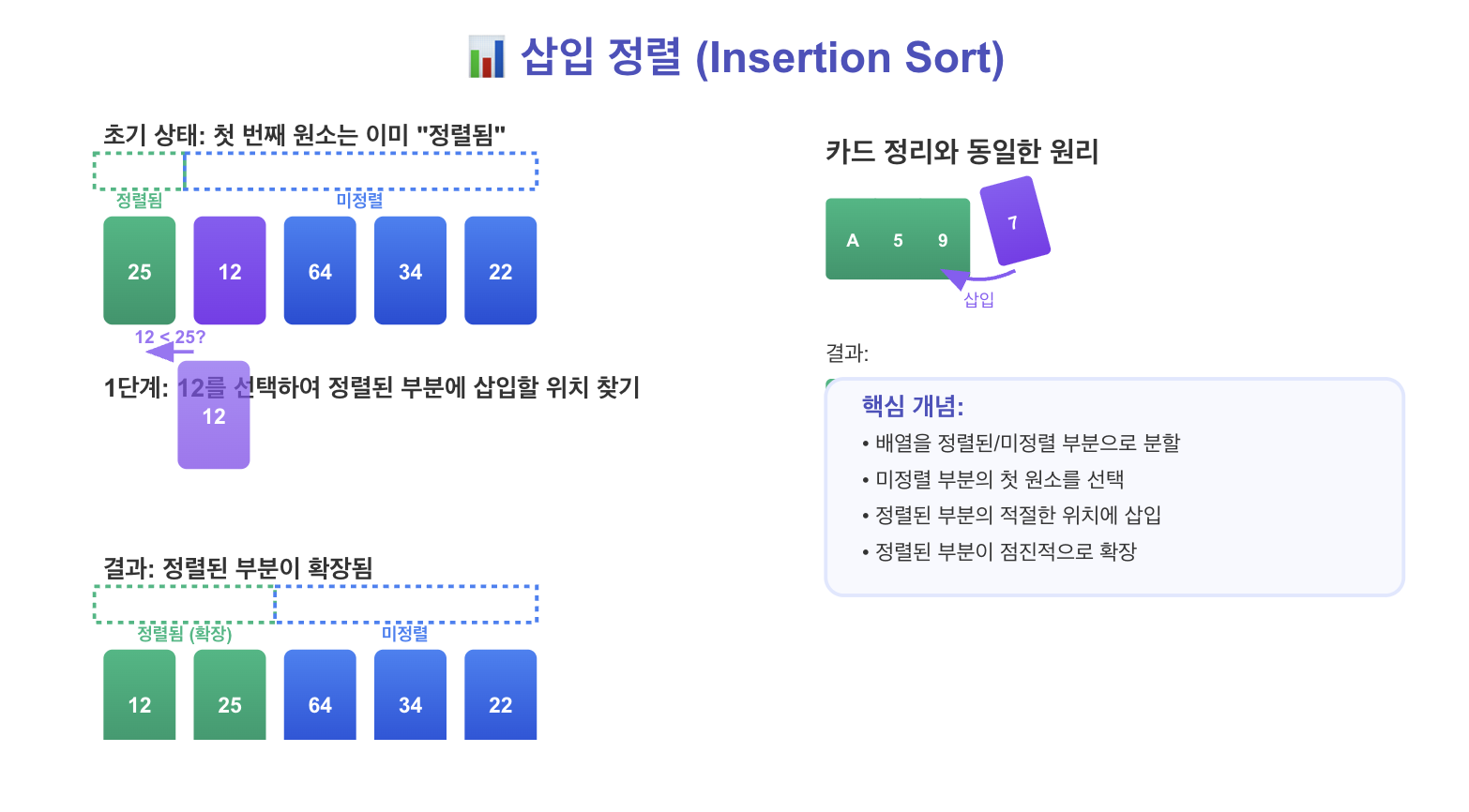
2. 삽입 정렬 (Insertion Sort)
배열을 정렬된 부분과 정렬되지 않은 부분으로 나눕니다. 정렬되지 않은 부분의 첫 번째 원소를 꺼내어 정렬된 부분의 적절한 위치에 '삽입'하는 과정을 반복합니다. 마치 카드를 정리할 때, 새로운 카드를 이미 정렬된 카드들 사이의 올바른 위치에 끼워 넣는 것과 유사합니다.
간단 요약:
- 비교 대상: 정렬된 부분의 원소들과 정렬되지 않은 부분의 첫 번째 원소
- 동작: 정렬된 부분의 적절한 위치에 삽입
- 특징: 각 단계를 거칠수록 정렬된 부분의 크기가 증가
정렬이 되는 과정을 아래에서 직접 살펴보세요!
버블 정렬∙삽입 정렬 시각화
동작 원리: 배열을 정렬된 부분과 미정렬 부분으로 나누고, 미정렬 부분의 첫 번째 원소를 정렬된 부분의 적절한 위치에 삽입합니다. 시간 복잡도: O(n²)
renechoi.github.io
위의 시각화를 보면, 두 알고리즘의 차이를 명확히 볼 수 있습니다.
버블 정렬은 인접한 원소들을 계속 비교하면서 큰 값들이 뒤로 '버블링'되는 모습을, 삽입 정렬은 정렬된 부분이 점진적으로 확장되면서 새로운 원소가 적절한 위치에 '삽입'되는 모습을 보여줍니다.
최악·평균·최선 시간 복잡도 비교
두 알고리즘의 이론적인 시간 복잡도는 다음과 같습니다.
| 알고리즘 | 최악 시간 복잡도 | 평균 시간 복잡도 | 최선 시간 복잡도 |
|---|---|---|---|
| 버블 정렬 | O(n²) | O(n²) | O(n) |
| 삽입 정렬 | O(n²) | O(n) | O(n) |
| 퀵 정렬 | O(n²) | $O(n \log n)$ | $O(n \log n)$ |
숫자만 보면 퀵 정렬의 압승처럼 보입니다.
하지만 여기서 주목해야 할 건 "최선의 경우" 입니다.
눈에 띄는 점은 버블 정렬은 입력 데이터의 상태와 관계없이 항상 O(n²)의 시간 복잡도를 가지는 반면, 삽입 정렬은 이미 정렬된 입력에 대해서는 O(n)이라는 매우 효율적인 성능을 보인다는 것입니다. 이는 앞으로 진행될 실험 결과에서 중요한 포인트가 될 것입니다.
‘입력 친화도(Input Sensitivity)’란 무엇인가
"최선은 O(n), 최악은 O(n²)"
앞서 삽입 정렬의 시간 복잡도를 이야기하며 위와 같이 언급했습니다. 이것이 바로 이번 글의 핵심 주제인 '입력 친화도(Input Sensitivity)'를 가장 잘 보여주는 대목입니다. 입력 친화도란, 알고리즘의 성능이 입력 데이터의 초기 상태나 패턴에 따라 얼마나 크게 달라지는지를 나타내는 개념입니다.
모든 알고리즘이 입력 데이터에 똑같이 반응하는 것은 아닙니다. 어떤 알고리즘은 데이터가 어떻게 생겼든 거의 일정한 성능을 내는 반면, 버블 정렬이나 삽입 정렬처럼 데이터의 초기 정렬 상태에 따라 성능이 천국과 지옥을 오가는 알고리즘도 있습니다.
이러한 입력 친화도를 결정하는 주요 데이터 패턴들을 살펴보겠습니다.
1. 이미 거의 정렬된 데이터 (Nearly Sorted Data)
이 시나리오는 버블 정렬과 삽입 정렬이 '느린 정렬'이라는 오명을 벗는 가장 극적인 순간입니다.
- 삽입 정렬: 새로운 원소를 정렬된 부분에 삽입할 때, 이미 거의 정렬되어 있다면 비교를 몇 번 하지 않고 바로 자신의 자리를 찾게 됩니다. 모든 원소가 제자리에서 한두 칸만 이동하면 되는 상황이므로, 전체 과정은 $O(n)$에 가까운 매우 빠른 속도를 보입니다.
- 버블 정렬: 최적화된 버블 정렬(어떤 패스에서 한 번도 교환이 일어나지 않으면 종료하는 방식) 역시 한 번의 순회만으로 정렬이 완료되었음을 감지하고 $O(n)$만에 작업을 마칠 수 있습니다.
- 퀵 정렬: 역설적으로 이 경우 성능이 저하될 수 있습니다. 만약 피벗을 항상 맨 앞이나 맨 뒤 원소로 선택하는 단순한 방식을 쓴다면, 분할이
1 : (n-1)비율로 극도로 불균형하게 일어나 최악의 경우인 $O(n^2)$에 가까워질 수 있습니다.
2. 역순으로 정렬된 데이터 (Reversely Sorted Data)
이것은 버블 정렬과 삽입 정렬에게는 최악의 시나리오입니다.
- 삽입 정렬: 각 원소는 정렬된 부분의 맨 앞으로 이동해야 하므로, 매번 정렬된 부분의 모든 원소와 비교하고 자리를 옮겨야 합니다. 이는 최대 비교와 최대 이동을 유발하여 $O(n^2)$의 성능을 그대로 보여줍니다.
- 버블 정렬: 모든 원소 쌍이 순서가 뒤바뀌어 있으므로, 모든 비교에서 교환이 발생합니다. 각 원소가 자신의 최종 위치까지 한 칸씩 이동해야 하므로, 이 역시 전형적인 $O(n^2)$의 성능을 보입니다.
이처럼 알고리즘의 성능은 단순히 '평균'이나 '최악'이라는 한 가지 척도로만 평가할 수 없습니다. 우리가 다루려는 데이터가 어떤 패턴을 가질 가능성이 높은지 예측할 수 있다면, '느리다'고 알려진 알고리즘이 오히려 가장 현명한 선택이 될 수도 있는 것이죠.
직접 돌려 본 실험 세팅
이제 실제로 테스트를 돌려보겠습니다.
먼저 테스트 환경은 다음과 같습니다.
1. 테스트 환경
일관된 환경을 만들고자 실험 중에는 불필요한 백그라운드 프로세스를 최소화하여 측정 오차를 줄이려 노력했습니다.
- 하드웨어: MacBook Pro (14-inch, 2021)
- 프로세서: Apple M1 Pro
- 메모리: 16GB
- 개발 도구(IDE): IntelliJ IDEA 2024.1 (Ultimate Edition)
- 언어(JDK): Amazon Corretto JDK 17
2. 테스트 데이터
알고리즘의 '입력 친화도'를 극명하게 확인하기 위해, 이전 장에서 정의했던 4가지 종류의 데이터셋을 자바 코드로 생성했습니다.성능 차이를 더 명확하게 보기 위해 데이터의 크기를 50,000개, 30,000개, 10,000개 각각의 다른 테스트 스위트를 기획했습니다.
- 정렬된 데이터 (Sorted Data):
[0, 1, 2, ..., 49999]- 삽입 정렬의 '최선'($O(n)$)의 경우를 확인하기 위한 데이터셋입니다.
- 역정렬된 데이터 (Reverse-Sorted Data):
[49999, 49998, ..., 0]- 삽입/버블 정렬의 '최악'($O(n^2)$)의 경우를 확인하기 위한 데이터셋입니다.
- 난수 데이터 (Random Data): 0부터 49999까지의 숫자가 무작위로 섞인 배열
- 가장 일반적인 '평균' 상황에서의 성능을 비교하기 위한 데이터셋입니다.
- 부분 정렬 데이터 (Partially Sorted Data): 정렬된 데이터에서 10%의 원소만 무작위로 위치를 바꾼 배열
- "거의 정렬되었지만 완벽하지는 않은" 현실적인 데이터에 대한 반응을 확인하기 위한 데이터셋입니다.
3. 테스트 설계 및 측정 코드
정확한 성능 측정을 위해, 특히 Java 환경의 특성을 고려하여 다음과 같이 테스트를 설계했습니다.
핵심 고려사항: JVM 워밍업 (Warm-up)
Java는 코드를 실행하는 시점에 JIT(Just-In-Time) 컴파일러가 바이트코드를 네이티브 코드로 최적화합니다. 이 때문에 메서드의 첫 몇 번 실행은 최적화 과정 때문에 실제 성능보다 느리게 측정될 수 있습니다. 이 오차를 없애고 순수하게 '최적화된 코드'의 성능을 측정하기 위해, 본격적인 측정 전에 충분한 횟수의 워밍업(Warm-up)을 진행하는 것은 필수입니다.
측정 전략 및 코드
- 구현 언어 및 프레임워크: Java, JUnit 5
- 측정 로직:
- 각 테스트 케이스마다 5회의 워밍업을 먼저 실행합니다.
- 이후 10회의 본 측정을 진행하여 실행 시간을 기록합니다.
- 10회 측정값의 산술 평균을 최종 결과로 사용합니다.
- 시간 측정에는
ms단위보다 정밀한System.nanoTime()을 사용합니다. - 매 측정마다 원본 데이터가 훼손되지 않도록 배열의 복사본(
Arrays.copyOf)을 사용해 정렬을 수행합니다.
1) Sorter 인터페이스
public interface Sorter {
void sort(int[] arr);
}
2) 삽입 정렬 구현체
package template.live;
public class InsertionSort implements Sorter {
@Override
public void sort(int[] arr) {
for (int i = 1; i < arr.length; i++) {
int key = arr[i];
int j = i - 1;
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = key;
}
}
}
3) 버블 정렬 구현체
package template.live;
public class BubbleSort implements Sorter {
@Override
public void sort(int[] arr) {
int n = arr.length;
for (int i = 0; i < n - 1; i++) {
// 최적화: 만약 한 패스에서 교환이 한 번도 일어나지 않았다면,
// 배열은 이미 정렬된 상태이므로 루프를 중단합니다.
boolean swapped = false;
for (int j = 0; j < n - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
swap(arr, j, j + 1);
swapped = true;
}
}
if (!swapped) {
break;
}
}
}
private void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
4) 퀵 정렬 구현체
package template.live;
public class QuickSortWithMedianOfThree implements Sorter {
@Override
public void sort(int[] arr) {
if (arr == null || arr.length <= 1) {
return;
}
quickSortRecursive(arr, 0, arr.length - 1);
}
private void quickSortRecursive(int[] arr, int low, int high) {
// 데이터가 충분히 클 때만 Median-of-Three 사용
if (high - low > 2) {
int pivot = medianOfThree(arr, low, high);
// 파티셔닝 (Hoare partition scheme)
int i = low, j = high - 1;
while (true) {
while (arr[++i] < pivot) ;
while (j > low && arr[--j] > pivot) ;
if (i >= j) break;
swap(arr, i, j);
}
// 피봇을 최종 위치로 이동
swap(arr, i, high - 1);
// 분할된 영역에 대해 재귀 호출
quickSortRecursive(arr, low, i - 1);
quickSortRecursive(arr, i + 1, high);
} else {
// 작은 배열은 단순하게 처리 (또는 삽입 정렬로 전환 가능)
manualSort(arr, low, high);
}
}
private int medianOfThree(int[] arr, int low, int high) {
int center = (low + high) / 2;
if (arr[low] > arr[center]) swap(arr, low, center);
if (arr[low] > arr[high]) swap(arr, low, high);
if (arr[center] > arr[high]) swap(arr, center, high);
swap(arr, center, high - 1);
return arr[high - 1];
}
// 배열 크기가 3 이하일 때 수동으로 정렬하는 헬퍼 메서드
private void manualSort(int[] arr, int low, int high) {
int size = high - low + 1;
if (size <= 1) return;
if (size == 2) {
if (arr[low] > arr[high]) swap(arr, low, high);
return;
}
if (size == 3) {
if (arr[low] > arr[center(low, high)]) swap(arr, low, center(low, high));
if (arr[low] > arr[high]) swap(arr, low, high);
if (arr[center(low, high)] > arr[high]) swap(arr, center(low, high), high);
}
}
private int center(int low, int high) {
return (low + high) / 2;
}
private void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
5) JUnit 5 테스트 클래스 구조
N=10,000, N=30,000, N=50,000 세 가지 데이터 크기에 대해 각 알고리즘과 데이터셋 조합으로 테스트를 실행했습니다.
모든 시간은 10회 측정의 평균값이며 단위는 밀리초(ms)입니다.
StackOverflowError가 발생하여 테스트가 실패한 경우는 실패(StackOverflow)로 표기했습니다.
[종합 벤치마크 결과 (단위: ms)]
| 알고리즘 | 데이터 타입 | N = 10,000 | N = 30,000 | N = 50,000 |
|---|---|---|---|---|
| InsertionSort | Sorted | 0.102 | 0.111 | 0.195 |
| Partially Sorted | 1.931 | 43.322 | 47.339 | |
| Random | 7.979 | 190.170 | 211.620 | |
| Reversed | 15.732 | 381.082 | 410.787 | |
| BubbleSort | Sorted | 0.075 | 0.096 | 0.167 |
| Partially Sorted | 30.453 | 373.763 | 1018.467 | |
| Random | 66.236 | 1169.393 | 3746.129 | |
| Reversed | 120.773 | 1065.864 | 3088.378 | |
| QuickSort (기본) | Sorted | 11.838 | 실패(StackOverflow) | 실패(StackOverflow) |
| Partially Sorted | 0.475 | 1.326 | 2.190 | |
| Random | 0.554 | 1.822 | 3.325 | |
| Reversed | 27.157 | 실패(StackOverflow) | 실패(StackOverflow) | |
| QuickSort(Median) | Sorted | 0.392 | 1.083 | 0.568 |
| Partially Sorted | 0.229 | 0.813 | 1.435 | |
| Random | 1.046 | 2.546 | 3.459 | |
| Reversed | 0.628 | 2.086 | 2.753 |
5. 결과 해석: 숫자 뒤에 숨겨진 드라마
단순한 숫자 테이블처럼 보이지만, 여기에는 알고리즘의 성격과 한계, 그리고 개선의 효과가 담긴 한 편의 드라마가 있습니다. 몇 가지 핵심적인 포인트를 중심으로 결과를 해석해 보겠습니다.
해석 1: 이론의 증명, StackOverflowError의 실제 발생
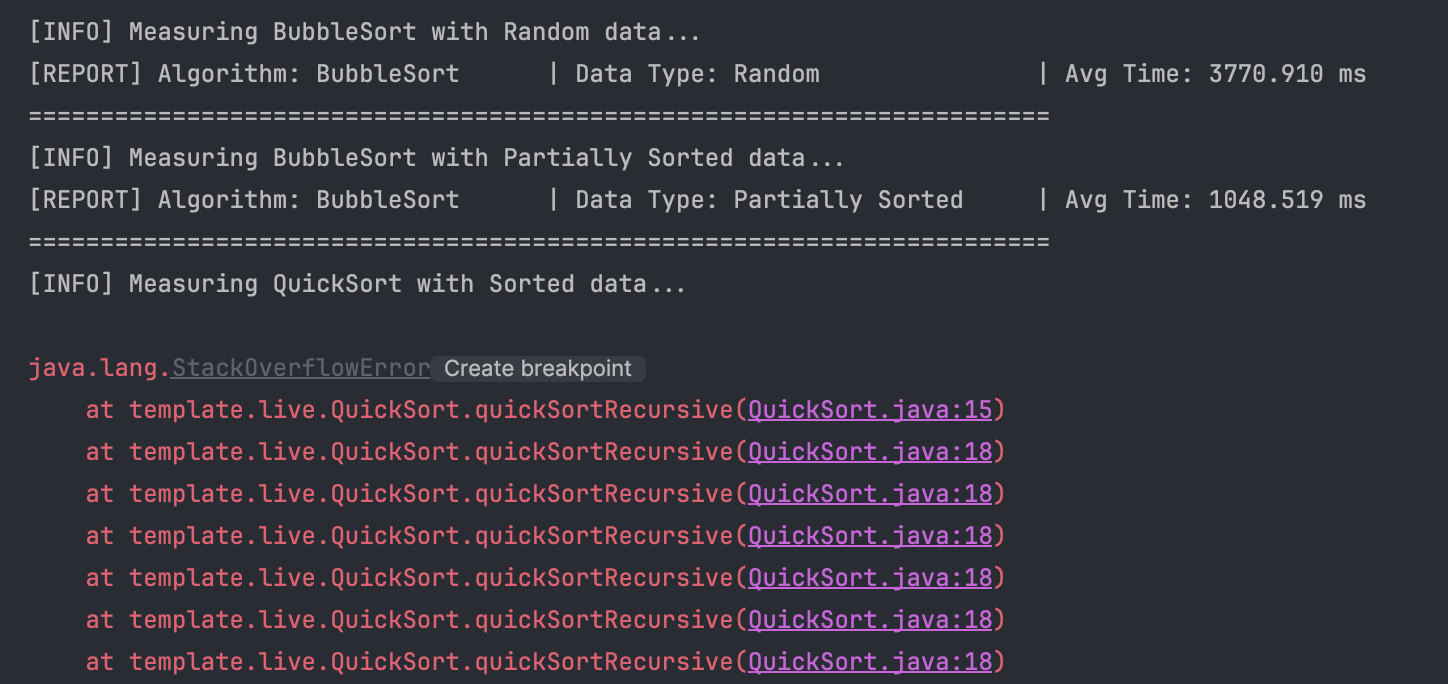
가장 극적인 결과는 기본 QuickSort에서 나왔습니다.
- 현상: 데이터가 3만, 5만 개일 때 '정렬된' 그리고 '역정렬된' 배열에서
StackOverflowError가 발생하며 프로그램이 비정상적으로 종료되었습니다. - 원인: 이는 우리가 이전에 예측했던 퀵 정렬의 최악의 경우($O(n^2)$)가 실제로 발생했음을 의미합니다. 단순한 피봇 선택 전략(마지막 요소 선택)은 정렬된 데이터에 대해 재귀 호출 깊이를 데이터 크기($N$)만큼 늘어나게 만들었고, 결국 JVM의 호출 스택 메모리 한계를 초과해버린 것입니다.
- 시사점: 흥미롭게도 데이터가 1만 개일 때는 에러 없이 통과는 했습니다. 이는 스택의 한계에 도달하지 않았기 때문이죠. 하지만 성능을 보세요. '역정렬된' 데이터(27.157ms)는 '난수' 데이터(0.554ms)보다 약 50배나 느렸습니다. 에러가 나지 않았을 뿐, 이미 성능은 처참하게 무너져 있었습니다. 이는 최악의 경우가 단순한 이론이 아닌, 실제 시스템을 마비시킬 수 있는 실존하는 위협임을 명확히 보여줍니다.

해석 2: "최선"의 시나리오에서는 $O(n^2)$ 정렬이 더 빠르다
'정렬된 데이터' 케이스는 상식을 뒤엎는 결과를 보여주었습니다.
- 현상: 모든 데이터 크기에서, 최적화된
BubbleSort(0.075ms)가 가장 빨랐고, 그 뒤를InsertionSort(0.102ms)가 이었습니다.QuickSort(Median)(0.392ms)은 이들보다 3~5배가량 느렸습니다. - 원인:
BubbleSort는 한 번의 순회($O(n)$)만으로 교환이 없음을 확인하고 즉시 종료합니다.InsertionSort역시 매번 한 번의 비교만으로 제자리를 찾습니다. 반면QuickSort(Median)는 최선의 경우에도 피봇 선택, 파티셔닝 등 상대적으로 '무거운' 연산을 수행해야 합니다. 이 오버헤드가 단순 비교/교환 비용보다 커져서 나타난 역전 현상입니다. - 시사점: "무조건 퀵 정렬이 빠르다"는 명제는 틀렸습니다. 데이터가 이미 정렬되어 있다는 강력한 사전 정보가 있다면, 오히려 가장 단순한 정렬이 가장 효율적일 수 있다는 사실을 보여줍니다.

해석 3: $O(n^2)$의 무서움, 데이터가 커질수록 드러나는 차이
'난수'와 '역정렬' 데이터에서 BubbleSort와 InsertionSort의 성능 저하를 주목해 보세요.
- 현상:
BubbleSort의 '난수' 데이터 처리 시간은 1만(66ms) -> 3만(1169ms) -> 5만(3746ms)으로 폭발적으로 증가했습니다. 데이터가 3배가 될 때 시간은 약 17배, 5배가 될 때 시간은 약 56배로 늘어나며 $n^2$의 특성을 명확히 보여줍니다. - 원인: 이는 알고리즘의 시간 복잡도가 실제 실행 시간에 얼마나 치명적인 영향을 미치는지 보여주는 직접적인 증거입니다.
- 시사점: 작은 데이터(N=100)에서는 $O(n^2)$과 $O(n \log n)$의 차이를 체감하기 어렵습니다. 하지만 데이터가 수만 건 단위로 커지는 순간, 이 차이는 '조금 느린 것'이 아니라 '사용 가능한가, 불가능한가'의 문제로 바뀝니다.

최종 결론: 구원투수 QuickSort(Median)과 "최고"가 아닌 "최적"의 선택
QuickSort(Median)의 위력:StackOverflowError를 유발했던 최악의 데이터들을 아무 문제 없이, 심지어 '난수' 데이터와 거의 비슷한 속도로 처리했습니다. 이는 알고리즘의 작은 개선(피봇 선택 전략 변경)이 어떻게 안정성과 성능을 극적으로 향상시키는지 보여주는 최고의 사례입니다.- 만능 해결책은 없다:
QuickSort(Median)는 대부분의 상황에서 가장 빠르고 안정적인 '최고의 범용 알고리즘'이었습니다. 하지만 '이미 정렬된' 데이터에서는BubbleSort에게 1위 자리를 내주었죠.
여기까지의 실험을 통해 '상황에 맞는 최적의 알고리즘은 따로 있다'는 처음의 가설은 명확하게 증명된 것 같습니다. 그런데 결과를 유심히 살펴보면 좀 특이한 부분이 있습니다.
어, 그런데 이상하다? 삽입 정렬이 왜 버블 정렬보다 더 빠르지? 시간 복잡도는 같은데...
벤치마크 결과를 보면 한 가지 흥미로운 패턴이 보입니다. 두 알고리즘 모두 최악의 성능($O(n^2)$)을 보이는 '역정렬된 데이터'에서조차, 삽입 정렬(5만개 기준 약 410ms)이 버블 정렬(약 3088ms)보다 7배 이상 빠릅니다.
시간 복잡도가 같은데 왜 이런 차이가 발생하는 걸까요? 그 비밀은 Big-O 표기법이 숨기고 있는 실제 연산의 세부 구조에 있습니다.
1. 데이터 이동(쓰기) 비용의 근본적인 차이
가장 결정적인 이유는 데이터를 움직이는 방식에 있습니다.
- 버블 정렬은 두 원소의 자리를 바꾸기 위해 swap 연산을 사용합니다. swap은 내부적으로 3번의 쓰기 작업을 필요로 합니다.
// swap(a, b)
temp = a; // 1번 쓰기
a = b; // 2번 쓰기
b = temp; // 3번 쓰기- 삽입 정렬은 적절한 위치를 찾을 때까지 원소들을 뒤로 한 칸씩 '이동(shift)'시킵니다. 이 이동은 1번의 쓰기 작업으로 끝납니다.
// shift
arr[j + 1] = arr[j]; // 1번 쓰기
역정렬된 배열을 생각해보죠. 가장 앞에 있는 작은 숫자를 맨 뒤로 보내기 위해, 버블 정렬은 이 숫자를 수많은 다른 숫자들과 반복적으로 '교환'합니다. 반면 삽입 정렬은 각 숫자를 자신의 최종 위치까지 한 번의 '이동' 시퀀스로 옮겨 놓습니다. 이 과정에서 발생하는 총 쓰기 횟수의 차이가 성능의 큰 차이를 만들어냅니다.
예를 들어 다음과 같은 배열 [5, 4, 3, 2, 1]을 오름차순으로 정렬한다고 가정해봅시다.
🫧 버블 정렬의 데이터 이동:
초기: [5, 4, 3, 2, 1]
1회전: 5를 맨 뒤로 보내기
[4, 5, 3, 2, 1] → [4, 3, 5, 2, 1] → [4, 3, 2, 5, 1] → [4, 3, 2, 1, 5]
교환 횟수: 4번 (각 교환마다 3번의 할당 연산 = 12번 할당)
2회전: 4를 뒤에서 두 번째로 보내기
[3, 4, 2, 1, 5] → [3, 2, 4, 1, 5] → [3, 2, 1, 4, 5]
교환 횟수: 3번 (9번 할당)
3회전: 3을 세 번째 자리로
[2, 3, 1, 4, 5] → [2, 1, 3, 4, 5]
교환 횟수: 2번 (6번 할당)
4회전: 2를 두 번째 자리로
[1, 2, 3, 4, 5]
교환 횟수: 1번 (3번 할당)
총 교환: 10번 → 총 할당: 30번
📊 삽입 정렬의 데이터 이동:
초기: [5, 4, 3, 2, 1]
1단계: 4를 정렬된 부분 [5]에 삽입
[5, 4, 3, 2, 1] → [4, 5, 3, 2, 1]
이동: 5를 오른쪽으로 1칸 → 1번 할당
2단계: 3을 정렬된 부분 [4, 5]에 삽입
[4, 5, 3, 2, 1] → [3, 4, 5, 2, 1]
이동: 4,5를 오른쪽으로 각각 1칸 → 2번 할당
3단계: 2를 정렬된 부분 [3, 4, 5]에 삽입
[3, 4, 5, 2, 1] → [2, 3, 4, 5, 1]
이동: 3,4,5를 오른쪽으로 각각 1칸 → 3번 할당
4단계: 1을 정렬된 부분 [2, 3, 4, 5]에 삽입
[2, 3, 4, 5, 1] → [1, 2, 3, 4, 5]
이동: 2,3,4,5를 오른쪽으로 각각 1칸 → 4번 할당
총 할당: 10번
결과: 같은 작업인데 버블 정렬은 30번, 삽입 정렬은 10번의 할당 연산! 3배 차이가 발생합니다.
이를 수학적으로 일반화하면:
버블 정렬:
- 총 교환 횟수: $\frac{n(n-1)}{2}$
- 총 할당 횟수: $3 \times \frac{n(n-1)}{2} = \frac{3n(n-1)}{2}$
삽입 정렬:
- 총 이동 횟수: $\frac{n(n-1)}{2}$ (교환 횟수와 동일)
- 총 할당 횟수: $\frac{n(n-1)}{2}$ (이동 1회 = 할당 1회)
→ 버블 정렬이 삽입 정렬보다 정확히 3배 많은 메모리 할당을 수행
하지만 잠깐, 이론상 3배 차이인데 실제로는 7배 차이가 났습니다. 나머지 차이는 어디서 올까요?
2. 추가 성능 차이 요인들
a) 분기 예측(Branch Prediction) 효율성
현대 CPU는 조건문의 결과를 미리 예측해서 성능을 향상시킵니다. 하지만 예측이 틀리면 파이프라인을 다시 시작해야 하는 페널티가 발생합니다.
// 버블 정렬: 매번 조건 검사 후 분기
if (arr[j] > arr[j + 1]) {
swap(arr, j, j + 1); // 조건에 따라 실행되거나 안 되거나
}
// 삽입 정렬: 더 예측 가능한 패턴
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j]; // 연속적으로 실행되는 경향
j--;
}
b) 메모리 접근 패턴과 캐시 효율성
- 삽입 정렬: 정렬된 부분을 뒤에서부터 앞으로 순차적으로 접근 (캐시 친화적)
- 버블 정렬: 인접한 원소들을 무작위로 교환하여 캐시 미스 증가 가능성
c) 루프 구조의 차이
- 삽입 정렬: 내부 while 루프가 조건을 만족하지 않으면 즉시 종료
- 버블 정렬: 고정된 이중 for 루프 구조로 인한 불필요한 반복
3. 실제 연산 횟수 측정으로 검증해보기
이론을 실제로 검증해보기 위해 연산 횟수를 직접 측정하는 테스트를 만들어서 아래와 같은 결과가 나왔네요.
// --- 5. 연산 횟수 측정 테스트 ---
@Test
@Order(17)
@DisplayName("연산 횟수 측정 - 버블 정렬 vs 삽입 정렬 (역정렬 데이터)")
void measureOperationCounts_ReversedData() {
int[] testData = TestUtils.createReversedData(1000); // 작은 크기로 테스트
System.out.println("\n=== 연산 횟수 측정 (N=1000, 역정렬 데이터) ===");
// 버블 정렬 연산 횟수 측정
BubbleSortWithCounter bubbleSort = new BubbleSortWithCounter();
int[] bubbleData = Arrays.copyOf(testData, testData.length);
bubbleSort.sort(bubbleData);
System.out.printf("🫧 버블 정렬:\n");
System.out.printf(" - 비교 횟수: %,d\n", bubbleSort.getComparisonCount());
System.out.printf(" - 교환 횟수: %,d\n", bubbleSort.getSwapCount());
System.out.printf(" - 할당 횟수: %,d (교환 × 3)\n", bubbleSort.getSwapCount() * 3);
// 삽입 정렬 연산 횟수 측정
InsertionSortWithCounter insertionSort = new InsertionSortWithCounter();
int[] insertionData = Arrays.copyOf(testData, testData.length);
insertionSort.sort(insertionData);
System.out.printf("📊 삽입 정렬:\n");
System.out.printf(" - 비교 횟수: %,d\n", insertionSort.getComparisonCount());
System.out.printf(" - 이동 횟수: %,d\n", insertionSort.getMoveCount());
System.out.printf(" - 할당 횟수: %,d (이동 × 1)\n", insertionSort.getMoveCount());
// 비율 계산
double assignmentRatio = (double)(bubbleSort.getSwapCount() * 3) / insertionSort.getMoveCount();
System.out.printf("\n📈 할당 연산 비율: %.1f:1 (버블:삽입)\n", assignmentRatio);
// 이론값과 비교
int n = testData.length;
int theoreticalOperations = n * (n - 1) / 2;
System.out.printf("\n🔍 이론값 검증:\n");
System.out.printf(" - 이론적 교환/이동 횟수: %,d\n", theoreticalOperations);
System.out.printf(" - 실제 버블 교환 횟수: %,d (차이: %+d)\n",
bubbleSort.getSwapCount(), bubbleSort.getSwapCount() - theoreticalOperations);
System.out.printf(" - 실제 삽입 이동 횟수: %,d (차이: %+d)\n",
insertionSort.getMoveCount(), insertionSort.getMoveCount() - theoreticalOperations);
}
@Test
@Order(18)
@DisplayName("연산 횟수 측정 - 다양한 데이터 크기별 비교")
void measureOperationCounts_VariousSizes() {
int[] sizes = {100, 500, 1000, 2000};
System.out.println("\n=== 데이터 크기별 할당 연산 비율 ===");
System.out.printf("%-8s | %-12s | %-12s | %-8s\n", "크기", "버블(할당)", "삽입(할당)", "비율");
System.out.println("---------|--------------|--------------|----------");
for (int size : sizes) {
int[] testData = TestUtils.createReversedData(size);
// 버블 정렬
BubbleSortWithCounter bubbleSort = new BubbleSortWithCounter();
bubbleSort.sort(Arrays.copyOf(testData, testData.length));
long bubbleAssignments = bubbleSort.getSwapCount() * 3L;
// 삽입 정렬
InsertionSortWithCounter insertionSort = new InsertionSortWithCounter();
insertionSort.sort(Arrays.copyOf(testData, testData.length));
long insertionAssignments = insertionSort.getMoveCount();
double ratio = (double)bubbleAssignments / insertionAssignments;
System.out.printf("%-8d | %,12d | %,12d | %.1f:1\n",
size, bubbleAssignments, insertionAssignments, ratio);
}
}
결과
// 첫 번째 테스트
=== 연산 횟수 측정 (N=1000, 역정렬 데이터) ===
🫧 버블 정렬:
- 비교 횟수: 499,500
- 교환 횟수: 499,500
- 할당 횟수: 1,498,500 (교환 × 3)
📊 삽입 정렬:
- 비교 횟수: 499,500
- 이동 횟수: 499,500
- 할당 횟수: 499,500 (이동 × 1)
📈 할당 연산 비율: 3.0:1 (버블:삽입)
🔍 이론값 검증:
- 이론적 교환/이동 횟수: 499,500
- 실제 버블 교환 횟수: 499,500 (차이: +0)
- 실제 삽입 이동 횟수: 499,500 (차이: +0)// 두 번째 테스트
=======================================================================
=== 데이터 크기별 할당 연산 비율 ===
크기 | 버블(할당) | 삽입(할당) | 비율
---------|--------------|--------------|----------
100 | 14,850 | 4,950 | 3.0:1
500 | 374,250 | 124,750 | 3.0:1
1000 | 1,498,500 | 499,500 | 3.0:1
2000 | 5,997,000 | 1,999,000 | 3.0:1
📊 측정 결과 분석
가장 먼저 눈에 띄는 것은 이론값과 실제 측정값의 완벽한 일치입니다.
- 이론적 예측: n(n-1)/2 = 1000×999/2 = 499,500회
- 실제 측정: 버블 정렬 교환 499,500회, 삽입 정렬 이동 499,500회 (차이: ±0)
이는 우리의 수학적 분석이 정확했음을 보여줍니다. 역정렬된 배열에서는 정말로 모든 원소 쌍이 한 번씩 처리되어야 하며, 두 알고리즘 모두 동일한 횟수의 기본 연산(교환 vs 이동)을 수행합니다.
하지만 메모리 할당 관점에서는 완전히 다른 이야기입니다:
- 버블 정렬: 1,498,500회 할당 (교환 499,500회 × 3)
- 삽입 정렬: 499,500회 할당 (이동 499,500회 × 1)
- 정확히 3:1 비율, 이론 예측과 완벽히 일치!
데이터 크기가 다른 경우에도 모든 경우에서 할당 연산 비율이 정확히 3:1을 유지했습니다. 이로써 앞서 말한 이론적 가정이 맞아떨어지는 것이 확인됩니다.
이제 실제 성능 차이를 단계별로 분해해볼 수 있겠습니다.
1단계: 할당 연산 차이 (3배)
- 측정 결과가 증명하듯, 버블 정렬은 삽입 정렬보다 정확히 3배 많은 메모리 할당을 수행
- 이것만으로도 상당한 성능 차이의 기반이 됨
2단계: 추가 오버헤드 (약 2.3배)
- 실제 벤치마크에서는 7배 차이가 발생 (7 ÷ 3 ≈ 2.3배 추가 오버헤드)
- 이 추가 차이는 다음 요인들로 설명됩니다:
총 성능 차이 = 할당 연산 차이(3배) × 추가 오버헤드(2.3배) ≈ 7배
그렇다면 이 추가 오버헤드는 무엇을 의미할까요?
4. 나머지 2.3배 차이의 정체: 마이크로벤치마킹으로 파헤치기
할당 연산만으로는 3배 차이밖에 설명되지 않습니다. 나머지 2.3배는 도대체 무엇일까요? 이를 규명하기 위해 더 세밀한 분석이 필요합니다.
a) 메모리 접근 패턴: 지역성(Locality)의 위력
현대 컴퓨터의 메모리 계층 구조를 생각해보면, 단순히 "할당 횟수"만이 성능을 결정하는 것은 아닙니다. 어떤 패턴으로 메모리에 접근하느냐가 훨씬 중요할 수 있습니다.
삽입 정렬의 메모리 접근 패턴:
// 연속된 메모리를 순차적으로 접근
for (int i = 1; i < arr.length; i++) {
int key = arr[i]; // arr[i] 읽기
int j = i - 1;
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j]; // arr[j] → arr[j+1] 순차적 이동
j--; // 바로 인접한 위치로 이동
}
arr[j + 1] = key; // 최종 삽입
}
이 패턴은 공간 지역성(Spatial Locality)이 매우 좋습니다. CPU가 arr[j]를 읽으면, 캐시 라인에 arr[j-1], arr[j+1] 등 인접한 데이터도 함께 로드됩니다. 다음 반복에서 arr[j-1]에 접근할 때는 이미 캐시에 있으므로 빠른 접근이 가능합니다.
버블 정렬의 메모리 접근 패턴:
// 교환으로 인한 상대적으로 복잡한 접근
for (int i = 0; i < n - 1; i++) {
for (int j = 0; j < n - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
// 3번의 메모리 접근이 발생
int temp = arr[j]; // arr[j] 읽기
arr[j] = arr[j + 1]; // arr[j+1] 읽기 + arr[j] 쓰기
arr[j + 1] = temp; // arr[j+1] 쓰기
}
}
}
swap 연산은 두 위치를 동시에 읽고 써야 하므로, 삽입 정렬의 순차적 이동보다 메모리 컨트롤러에 더 많은 부담을 줍니다.
b) CPU 파이프라인과 분기 예측: 예측 가능성의 차이
현대 CPU는 명령어를 미리 예측해서 파이프라인에 로드합니다. 하지만 예측이 틀리면 파이프라인을 비우고 다시 시작해야 하는 분기 예측 실패 페널티가 발생합니다.
삽입 정렬의 분기 패턴:
while (j >= 0 && arr[j] > key) { // 연속적으로 true가 될 가능성이 높음
arr[j + 1] = arr[j];
j--;
}
역정렬된 데이터에서는 arr[j] > key 조건이 연속적으로 true가 되는 경향이 있습니다. CPU의 분기 예측기는 이런 패턴을 잘 학습할 수 있어 예측 성공률이 높습니다.
버블 정렬의 분기 패턴:
if (arr[j] > arr[j + 1]) { // 상대적으로 불규칙적
swap(arr, j, j + 1);
}
비록 역정렬 데이터에서는 대부분 true가 되지만, 매 비교마다 조건 검사 → 함수 호출 → 복귀의 과정이 반복되어 파이프라인 효율성이 떨어질 수 있습니다.
c) 함수 호출 오버헤드: 인라이닝의 차이
삽입 정렬: 모든 연산이 메인 루프 안에서 인라인으로 실행 버블 정렬: swap() 함수를 반복적으로 호출
// 버블 정렬: 499,500번의 함수 호출
for (int j = 0; j < n - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
swap(arr, j, j + 1); // 함수 호출 오버헤드
}
}
// 삽입 정렬: 함수 호출 없음
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j]; // 인라인 실행
j--;
}
JVM이 swap() 메서드를 인라이닝해도, 여전히 스택 프레임 관리나 메서드 디스패치 등의 미세한 오버헤드가 누적될 수 있습니다.
d) 실제 CPU 사이클 분석: 마이크로아키텍처 관점
Intel이나 AMD 같은 현대 CPU에서는,
- L1 캐시 접근: 1-2 사이클
- L2 캐시 접근: 3-10 사이클
- L3 캐시 접근: 10-20 사이클
- 메인 메모리 접근: 100-300 사이클
- 분기 예측 실패 페널티: 10-20 사이클
만약 버블 정렬이 삽입 정렬보다 10% 더 많은 캐시 미스를 발생시킨다면:
추가 성능 저하 = (캐시 미스로 인한 대기 시간) × (미스 횟수 차이)
예를 들어, 499,500번의 연산 중 단 5%만 L3 캐시 미스를 발생시켜도:
- 약 25,000번의 추가 메모리 접근
- 각각 평균 100 사이클 추가 대기
- 총 2,500,000 사이클의 추가 오버헤드
이는 충분히 2배 이상의 성능 차이를 만들어낼 수 있습니다.
e) 결합된 효과: 작은 차이들의 누적
따라서 2.3배의 추가 오버헤드는 다음 요인들의 복합적 결과로 추정해볼 수 있을 것 같습니다.
- 메모리 지역성 차이: 약 1.3-1.5배
- 분기 예측 및 파이프라인 효율성: 약 1.2-1.3배
- 함수 호출 오버헤드: 약 1.1-1.2배
총 추가 오버헤드 = 1.4 × 1.25 × 1.15 ≈ 2.0-2.5배
💡 최종 결론: 미시적 관점에서 본 알고리즘 성능
이 분석을 통해 우리는 알고리즘 성능이 단순히 Big-O로 결정되지 않는다는 것을 확인했습니다.
이론적 차이 (3배):
- 할당 연산 횟수: 1,498,500 vs 499,500
실제 차이 (7배):
- 메모리 접근 패턴
- CPU 파이프라인 효율성
- 캐시 지역성
- 분기 예측 성공률
- 함수 호출 오버헤드
즉, 같은 O(n²) 알고리즘이라도 마이크로아키텍처 수준의 최적화에 따라 성능이 크게 달라질 수 있습니다. 같은 O(n²)라도 실제 상수 계수와 구현 세부사항에 따라 성능은 크게 달라질 수 있습니다. Big-O가 모든 것을 말해주지 않는다는 것을 보여주는 좋은 사례인 것 같습니다.
결국 삽입 정렬이 버블 정렬보다 빠른 이유는,
- 3배 적은 메모리 할당 (측정으로 증명)
- 하드웨어 친화적인 실행 패턴 (마이크로아키텍처 최적화)
이 두 요소가 결합되어 7배의 성능 차이를 만들어내는 것입니다.
이처럼 같은 O(n²)라도 실제 상수 계수와 구현 세부사항에 따라 성능은 크게 달라질 수 있습니다. Big-O가 모든 것을 말해주지 않는다는 것을 보여주는 완벽한 사례입니다.
이렇게 본다면, 우리가 찾아야 할 것은 세상에 존재하지 않는 '가장 빠른 하나의 알고리즘'이 아니라, "내가 마주한 데이터와 상황에 맞는 최적의 알고리즘" 이 아닐까 하는 생각이 듭니다. 그리고 그 최적의 선택을 하기 위해서는, 이처럼 직접 부딪히고 측정하며 이론 뒤에 숨은 진짜 특성을 이해하려는 노력이 필요하구요.
실무 시나리오에 대입해 보기
실험실에서 얻은 인사이트는 실제 필드에서 사용될 때 비로소 가치를 갖습니다.
앞선 실험 결과를 바탕으로 실제 개발 중에 마주할 법한 구체적인 시나리오 세 가지에 어떤 정렬 알고리즘이 적합할지 살펴보겠습니다.
"이미 어느 정도 정렬된 로그 파일"
가장 먼저 생각해볼 수 있는 건 로그 파일 처리 상황입니다.
웹 서버 로그를 생각해봅시다. 대부분은 시간 순으로 쌓이지만, 가끔 네트워크 지연이나 로드밸런서의 영향으로 순서가 살짝 뒤바뀌는 경우가 있죠. 전체적으로는 90% 이상이 정렬된 상태인데, 몇 개의 라인만 위치가 바뀐 상황 말입니다.
[2025-06-28 00:51:01] INFO: User 'alpha' logged in.
[2025-06-28 00:51:02] INFO: User 'bravo' logged in.
[2025-06-28 00:51:05] INFO: User 'delta' logged in.
[2025-06-28 00:51:03] WARN: User 'charlie' login failed. <-- 이 라인만 순서가 다름
[2025-06-28 00:51:06] INFO: User 'echo' logged in.
이런 케이스에서는 실험 결과대로 삽입 정렬이 최선의 선택이 될 수 있습니다. 특히 로그 파일이 메모리에 모두 올라갈 수 있는 크기라면 더욱 그렇죠.
"실시간 들어오는 데이터 스트림"
또 다른 흥미로운 케이스는 실시간 데이터 스트림입니다.
예를 들어, 실시간으로 들어오는 주식 거래 데이터를 가격 순으로 정렬해서 보여줘야 하는 상황을 생각해보세요. 기존에 이미 정렬된 리스트가 있고, 새로운 데이터가 하나씩 추가되는 형태죠.
// 현재 정렬된 주식 가격 리스트
[10100, 10250, 10300, 10500]
// 새로운 거래 데이터 '10280' 발생
[10100, 10250, -> [10280] <- , 10300, 10500] // 적절한 위치에 삽입
// 최종 리스트
[10100, 10250, 10280, 10300, 10500]
이때는 삽입 정렬의 아이디어가 정말 빛을 발합니다. 새로 들어온 데이터를 적절한 위치에 삽입하기만 하면 되니까, 전체를 다시 정렬할 필요가 없거든요. O(n)의 시간으로 해결 가능합니다.
반면 퀵 정렬 같은 방식을 사용한다면? 새 데이터가 하나 들어올 때마다 전체를 다시 정렬해야 하니까 O(n log n)의 비용이 들겠죠. 데이터가 자주 들어오는 환경에서는 이 차이가 치명적일 수 있습니다.
실제로 많은 실시간 시스템들이 이런 방식을 채택하고 있는 것으로 알고 있는데요. 가장 대표적인 예가 바로 데이터베이스의 인덱스(Index)가 아닐까 합니다. 특히 B-Tree 구조를 사용하는 인덱스는 새로운 데이터가 INSERT될 때, 전체 인덱스를 재정렬하는 것이 아니라 새로운 키 값을 트리의 적절한 위치에 '삽입'하여 정렬된 상태를 유지합니다. 매번 전체를 정렬한다면 데이터베이스의 쓰기 성능은 지금과 비교할 수 없을 정도로 느려질 것입니다.
정렬된 상태를 유지하면서 새로운 요소를 삽입하는 것이 매번 전체를 재정렬하는 것보다 훨씬 효율적이거든요.
"대용량 배치 정렬"
반대로 대용량 배치 정렬 상황도 생각해봤습니다.
매일 밤 수백만 건의 거래 데이터를 정렬해서 리포트를 생성하는 작업이라고 해보죠. 이 데이터는 완전히 무작위로 섞여 있고, 메모리 사용량이나 안정성보다는 순수한 처리 속도가 가장 중요한 상황입니다.
이런 케이스에서는 당연히 퀵 정렬(또는 그 변형)이 최선이겠죠. 대용량 데이터에서 O(n log n)과 O(n²)의 차이는 정말 극명하거든요.
하지만 여기서도 주의할 점이 있어요. 만약 입력 데이터에 어떤 패턴이 있다면? 예를 들어 날짜별로 어느 정도 정렬되어 있다든지, 특정 범위의 값들이 몰려 있다든지 하는 특성이 있다면, 순수한 퀵 정렬보다는 하이브리드 방식이 더 나을 수 있습니다. 이 하이브리드 방식에 대해서는 글 하단에서 간략히 좀 더 소개해보겠습니다.
예상 밖의 발견: 메모리 제약 환경
한가지 추가로 고려해볼 포인트가 있습니다. 메모리가 극도로 제한된 환경에서의 정렬입니다.
임베디드 시스템이나 IoT 디바이스처럼 메모리가 매우 적은 환경에서는 퀵 정렬의 재귀 호출 스택도 부담이 될 수 있을 것 같은데요. 앞서 살펴본 StackOverFlow의 문제와 같은 상황이 예시입니다. 이런 상황에서는 오히려 버블 정렬이나 삽입 정렬의 단순함이 장점이 될 수 있을 것입니다.
물론 성능은 느리겠지만, 메모리 사용량이 일정하고 예측 가능하다는 점에서 더 안정적일 수 있습니다. 특히 데이터 크기가 작은 경우라면 성능 차이도 크지 않고요.
이런 경험들을 통해 깨달은 건, "맥락(context)이 알고리즘 선택의 핵심"이라는 점입니다. 데이터의 특성, 시스템의 제약사항, 성능 요구사항 등을 종합적으로 고려해야 최적의 선택을 할 수 있을 것입니다.
정렬 알고리즘 선택 체크리스트
"그럼 언제 어떤 알고리즘을 써야 할까요?"
실용적인 가이드라인이 필요하다는 생각이 듭니다. 나름대로 체크리스트를 만들어봤습니다.
입력 데이터 패턴은 예측 가능한가?
가장 먼저 확인해야 할 것은 데이터의 특성입니다.
✅ 이미 대부분 정렬되어 있거나 부분적으로만 섞인 경우
→ 삽입 정렬을 강력 추천합니다. 실험에서 보았듯이 O(n)에 가까운 성능을 보이거든요.
✅ 완전히 무작위이거나 패턴을 예측할 수 없는 경우
→ 퀵 정렬(또는 그 변형)이 가장 안전한 선택입니다. 평균적으로 최고 성능을 보장하니까요.
✅ 역순이거나 특정 패턴이 있어서 퀵 정렬이 불리할 것 같은 경우
→ 하이브리드 정렬(예: Introsort)을 고려해보세요. 최악의 경우를 회피하는 안전장치가 있거든요.
✅ 실시간으로 하나씩 추가되는 경우
→ 삽입 정렬 기반의 접근법이 최적입니다. 매번 전체를 재정렬할 필요가 없어요.
개인적으로는 실무에서 "완전 무작위" 데이터보다는 "어떤 형태로든 패턴이 있는" 데이터를 더 자주 만나는 듯 합니다. 그래서 데이터 특성을 먼저 파악하는 게 정말 중요하다고 생각합니다.
구현 복잡도와 디버깅 부담은?
두 번째로 고려할 점은 구현과 유지보수의 부담입니다.
간단하고 확실한 구현이 필요한 경우
- 삽입 정렬: 몇 줄로 끝나고, 버그 숨을 곳이 거의 없음
- 버블 정렬: 교육용이나 프로토타입에서는 나쁘지 않음
성능과 안정성을 모두 원하는 경우
- 표준 라이브러리 사용: 대부분의 언어에서 잘 최적화된 정렬 함수 제공
- 직접 구현보다는 검증된 라이브러리가 안전함
99%의 경우에는 표준 라이브러리로 충분할 것입니다. 하지만 알고리즘의 동작 원리를 이해하고 있으면, 문제가 생겼을 때 원인을 빠르게 파악할 수 있어서 도움이 많이 됩니다.
안정성(Stable) 여부가 중요한가?
세 번째는 정렬의 안정성입니다. 같은 값을 가진 원소들의 상대적 순서가 유지되어야 하는지 말이에요.
안정성이 중요한 경우:
- 삽입 정렬: 자연스럽게 안정 정렬
- 버블 정렬: 구현 방식에 따라 안정하게 만들 수 있음
- 병합 정렬: 안정 정렬의 대표주자
안정성이 중요하지 않은 경우:
- 퀵 정렬: 일반적으로 불안정하지만 빠름
- 힙 정렬: 불안정하지만 최악의 경우에도 O(n log n) 보장
실무에서는 생각보다 안정성이 중요한 케이스가 많을 텐데요. 예를 들어, 사용자 목록을 등급별로 정렬한 다음 이름순으로 다시 정렬하는 경우, 같은 등급 내에서는 이름순이 유지되어야 하는 케이스 등이 있을 것입니다.
추가 메모리를 얼마나 쓸 수 있는가?
마지막으로 메모리 제약사항을 확인해야 합니다.
메모리가 매우 제한적인 환경:
- 삽입 정렬, 버블 정렬: O(1) 추가 메모리
- 선택 정렬: 역시 O(1), 하지만 성능은 항상 O(n²)
메Mㅔ모리 여유가 있는 환경:
- 병합 정렬: O(n) 추가 메모리 필요하지만 안정적인 O(n log n)
- 퀵 정렬: 평균 O(log n) 스택 메모리, 최악 O(n)
임베디드 시스템이나 메모리가 귀한 환경에서 일할 때는 이 부분이 정말 중요해요. 아무리 빠른 알고리즘이라도 메모리를 초과하면 아예 돌아가지 않으니까요.
다 나름의 '최고의 순간'을 갖고 있다
이 모든 실험과 분석을 마치고 나니, 처음에 가졌던 단순한 의문이 얼마나 복잡한 문제였는지 새삼 깨닫게 되었습니다. "어떤 정렬이 가장 좋을까?"라는 질문은 사실 단 하나의 정답이 없는 질문이었습니다.
장단점의 균형 잡기
결국 또 다시 트레이드오프입니다.
빠른 성능을 원하면 복잡도를 감수해야 하고, 단순함을 원하면 어느 정도의 성능 타협이 필요합니다. 메모리를 절약하려면 시간을 더 쓸 수도 있고, 안정성을 보장하려면 추가 비용이 들 수도 있습니다.
이 실험을 진행하며 가장 인상 깊었던 건, 각 알고리즘이 모두 나름의 '최고의 순간'을 가지고 있다는 점이었습니다.
- 삽입 정렬: 부분적으로 정렬된 데이터에서는 정말 빛남
- 버블 정렬: 교육용이나 메모리 제약이 극심한 환경에서는 여전히 유용
- 퀵 정렬: 무작위 데이터에서는 압도적 성능
결국 '최적'이라는 건 절대적인 기준이 아니라 상황에 따른 상대적인 개념인 것입니다.
하이브리드(dual-pivot quicksort + insertion) 전략 소개
현실에서 가장 널리 사용되는 해답은 바로 하이브리드 접근법입니다. 이 방식은 간단히만 소개해볼게요.
가장 대표적인 예가 Java의 Arrays.sort()입니다. 내부를 뜯어보면 배열 타입별로 경로가 갈립니다.
- Primitive 배열(int[], double[] …)
평균 속도를 최우선으로 하는 unstable Dual-Pivot QuickSort(DPQS)가 기본입니다. 재귀 과정에서 구간 길이가 약 286개보다 작아지면 더 이상 파티셔닝을 하지 않고, 47개 미만이면 최종적으로 삽입 정렬로 마무리해 호출 스택과 분기 오버헤드를 줄입니다. - Reference 배열(Integer[], String[], 사용자 정의 객체 …)
값이 같아도 서로 다른 객체일 수 있어 stable 특성이 필요합니다. 이때 호출되는 것이 TimSort로, 이미 정렬돼 있는 run을 찾아 길이가 minRun≈32보다 짧으면 삽입 정렬로 run을 확장한 뒤 병합(Merge) 단계로 넘어갑니다. 덕분에 거의 정렬된 데이터에서는 실제 비교·이동 횟수가 O(n) 수준까지 내려갑니다.
Dual-Pivot QS 는 평균이 가장 빠르고, TimSort는 같은 키의 순서를 유지해야 하는 객체 배열에서 쓰입니다. 두 경로 모두 작은 구간은 삽입 정렬로 마무리해 재귀·분기 오버헤드를 줄입니다.
이런 방식으로 각 알고리즘의 장점만을 취하는 거죠. 큰 데이터에서는 퀵 정렬의 효율성을, 작은 데이터에서는 삽입 정렬의 단순함과 빠른 처리를, 최악의 경우에는 힙 정렬의 안정성을 활용하는 겁니다.
이번 실험을 통해 가장 큰 수확은 "모든 도구에는 존재 이유가 있다"는 깨달음입니다. 느리다고 무시했던 알고리즘들도, 적절한 상황에서는 최고의 성능을 보일 수 있다는 사실 말입니다. 또한, 숫자는 거짓말하지 않지만 맥락 없는 숫자는 오해를 불러일으킬 수 있다는 점이었습니다.
"O(n²)는 느리다"는 말 자체는 틀리지 않습니다. 하지만 그 뒤에 숨어 있는 조건들을 간과하면 안될 것입니다. "무작위로 뒤섞인 대용량 데이터에서는 O(n²)가 느리다"가 정확한 표현일 테니까요.
마찬가지로 "퀵 정렬이 가장 빠르다"는 말도 "평균적으로는" 또는 "무작위 데이터에서는"이라는 조건이 붙어야 완전한 문장이 됩니다.
이런 조건들을 놓치면, 실무에서 "분명히 빠르다고 했는데 왜 이렇게 느리지?" 같은 당황스러운 상황을 마주할 수도 있을 듯 합니다.
처음 버블 정렬과 삽입 정렬을 배웠을 때는 "이런 걸 왜 배우나?" 싶었는데, 이제는 그 모든 알고리즘들이 각자의 사연과 존재 이유를 가지고 있다는 걸 알게 되었습니다.
"당연하다고 생각했던 것들에 대한 건전한 의심"을 계속 가져야 하는 이유가 아닐까 싶습니다.
'알고리즘' 카테고리의 다른 글
| O(n²) 너머 ②: 제자리 정렬의 해답, 힙 정렬(Heap Sort) (3) | 2025.07.24 |
|---|---|
| O(n²)의 벽을 넘어서기 위한 관문, 병합 정렬 (2) | 2025.07.11 |
| 같은 시간 복잡도인데 왜 DFS가 BFS 보다 느릴까? - 스택, 힙, 캐시로 파헤치는 알고리즘의 실제 성능 (BOJ 21736) (2) | 2025.06.07 |
| 백트래킹 개념, 유망 함수와 가지치기, 예시 문제로 이해하기 (0) | 2025.05.25 |
| 집합, 유니온 파인드 알고리즘, 개념과 구현 + 최적화 + 활용 예시까지 (시간 복잡도와 재귀 호출 스택 디테일 포함) (1) | 2025.05.04 |



