0. 이 글에 대해서
- 멀티스레드 환경에서의 동시성 문제와 전통적 동기화 기법의 한계를 간단히 짚은 뒤,
- “스레드 간 공유하지 않는다”는 아이디어로 문제를 해결하는 ThreadLocal의 개념과 원리를 살펴봅니다.
- 자바의
ThreadLocalMap구조와 스레드 풀 재사용 시 라이프사이클 관리(메모리 누수 방지)도 다룹니다. - Spring Security와 계층형 로깅(Log Tracer) 사례를 통해 ThreadLocal의 실제 활용법을 예시로 보여줍니다.
- ThreadLocal 사용 시 주의사항과 향후 대안까지 간략히 살펴보며 마무리합니다.
1. ThreadLocal, 알아보자
Threadlocal이란?
한마디로 ThreadLocal은 “전역 변수처럼 보이지만, 실제로는 스레드마다 따로따로 값을 가지는 특별한 저장소”이다.
일반적인 전역 변수나 static 필드는 모든 스레드가 같은 값을 읽고 쓰게 되지만, ThreadLocal에 담긴 값은 A 스레드에서 꺼낸 값과 B 스레드에서 꺼낸 값이 전혀 다를 수 있다.
이게 무슨 말일까? 다음과 같은 그림을 살펴보자.
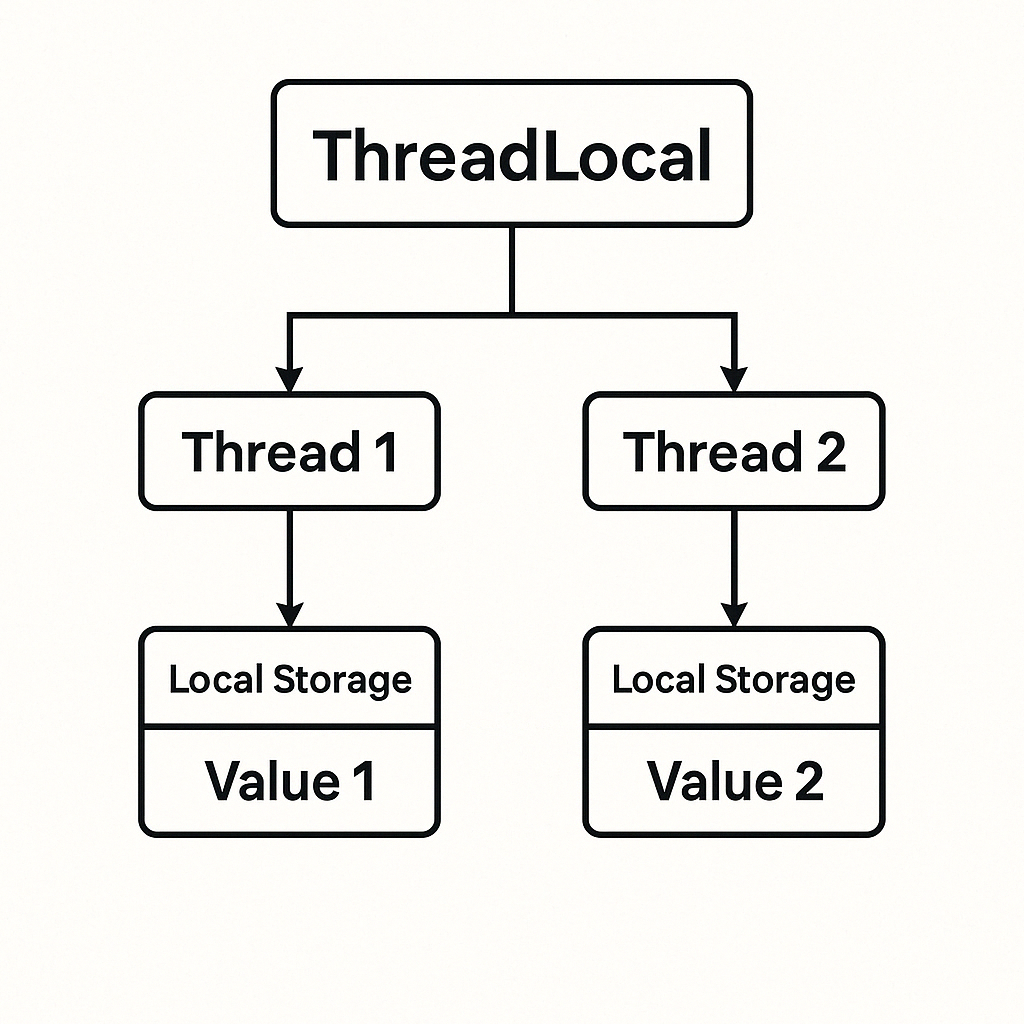
- 최상단의 ThreadLocal 박스는 “공유하지만 스레드별로 따로 저장되는 키” 역할을 한다.
- 화살표를 따라 내려가면, 각각 Thread 1과 Thread 2가 있고,
- 각 스레드 밑에는 별도의 Local Storage(스레드 전용 저장소)가 존재하여
- Thread 1은
Value 1을, - Thread 2는
Value 2를
이렇게 독립적으로 보관한다.
- Thread 1은
- 즉, 하나의 ThreadLocal 키를 정의하기만 하면,
- 각 스레드는 자신만의 Local Storage에 값을 저장(set)하고,
- 꺼내올 때(get)도 자기 스레드 전용 공간에서만 조회하니,
서로 간섭 없이 100% 독립적인 데이터 관리가 가능하다!
그렇다면 이 ThreadLocal이 필요한 이유는 무엇일까?
이를 이해하기 위해서는 멀티 스레딩 기반의 동작과 동기화 이슈에 대해 생각해보아야 한다.
멀티스레드가 나타난 이유
프로그램이 단일 스레드로 동작한다면, 한 번에 하나의 작업만 처리할 수 있다. 이는 CPU 코어가 여러 개인 시대에 비효율적일 뿐 아니라, 동시 접속이 많은 서버 환경에서 병목을 유발한다. 그래서 대부분의 서버 애플리케이션은 멀티스레드(또는 이벤트 루프, 비동기 I/O 등)를 통해 동시에 여러 요청을 처리한다.
이 글에서 초점을 맞추는 멀티스레드 환경은 “서블릿 기반 웹 서버”처럼 스레드를 풀에서 꺼내서 요청을 처리하고, 응답 후 스레드를 반환하는 전형적인 모델을 예로 들 수 있다. 이 상황에서 개발자가 흔히 부딪히는 문제는 “여러 스레드가 공유하는 객체를 어떻게 안전하게 다룰 것인가”이다.
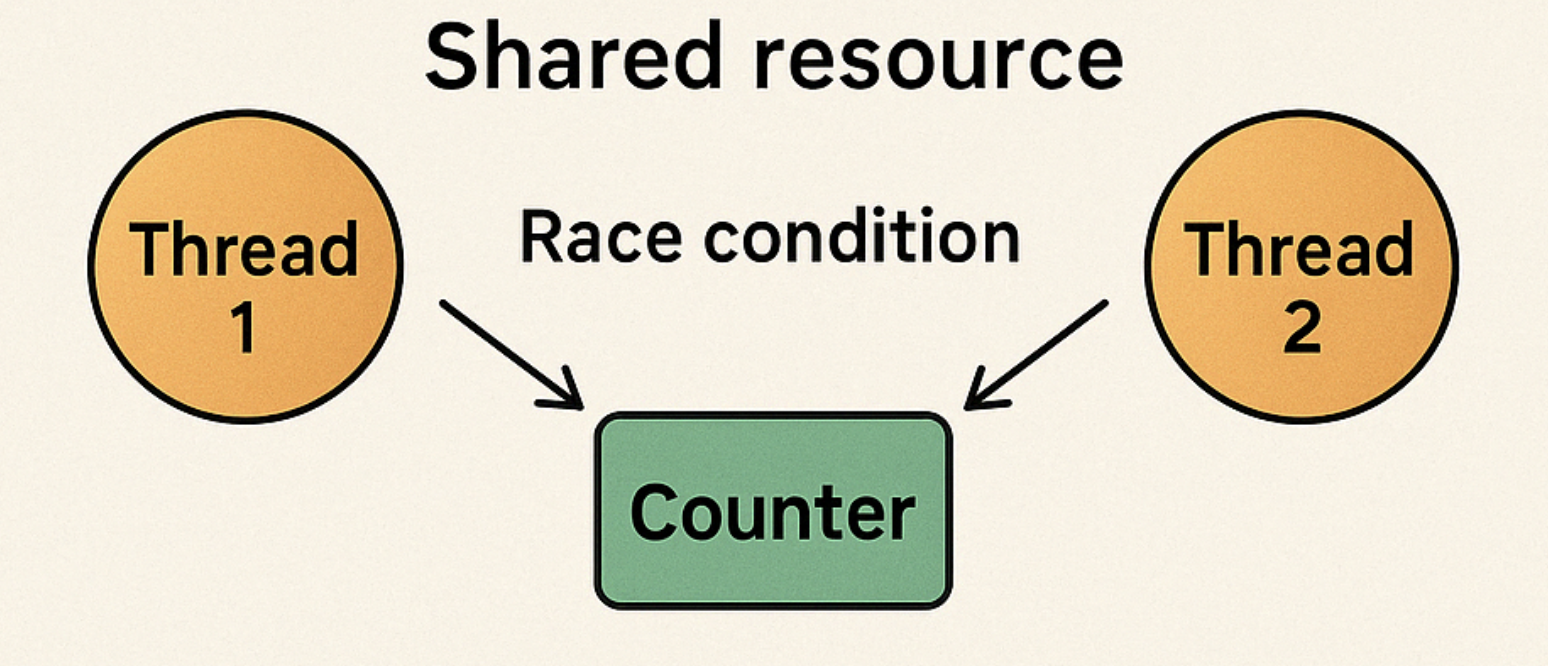
공유 자원, 뭐가 문제일까?
공유 자원(Shared Resource) 이란, 여러 스레드가 동시에 읽고/쓰는 어떤 데이터나 객체를 의미한다. 예컨대:
- 전역(static) 변수
- 싱글턴(Singleton)으로 관리되는 빈(Bean) 내부 필드
- 캐시(Cache), 상태(Stateful)한 컬렉션(Collection)
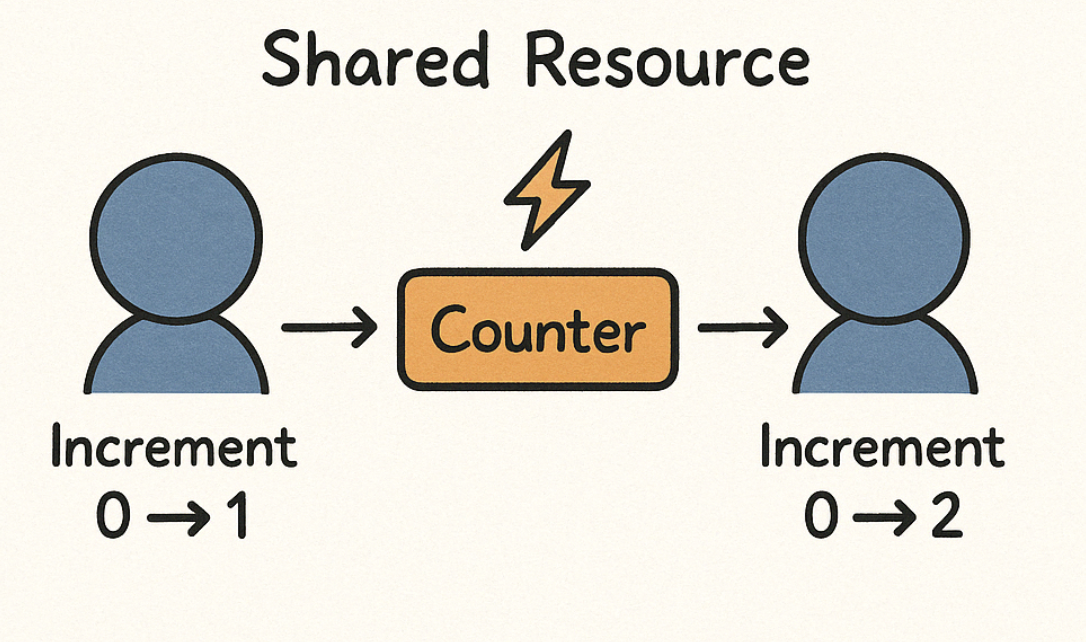
이들이 스레드 안전(Thread-Safe)하게 구성되지 않으면, 동일한 시점에 여러 스레드가 접근하여 예기치 못한 결과를 초래할 수 있다. 이를 레이스 컨디션(Race Condition)이라 부른다. 예를 들어, 0에서 시작된 전역 카운터(counter)를 각 스레드가 동시에 증가시키면, 1씩 올려야 할 값이 제대로 반영되지 않고 0→2처럼 스킵되거나, 심지어 -1 같은 이상한 값이 찍힐 수도 있다.
전통적 해법: 동기화(Synchronization)
멀티스레드 프로그래밍은 필수불가결하다. 하지만 그 나름대로의 문제를 갖는다. 이에 대한 해결책으로 컴퓨터 사이언스는 동기화라는 해법으로 해결하고 있다.
전통적 해법은 “임계 구역(Critical Section)”을 만들어, 해당 구역에 들어가기 전에는 Lock을 획득하고, 빠져나올 때 Lock을 해제하는 방식이다. Java에서는 synchronized 키워드나 ReentrantLock, 더 나아가 CAS(Compare And Swap)와 같은 저수준 기법을 활용할 수도 있다.
https://upcurvewave.tistory.com/649
자바에서 동시성 문제를 다루는 n가지 방법들(feat. 주식 매수)
이 글에 대해서 자바에서 동시성 문제를 다루는 n가지 방법을 소개합니다. 동시성 이슈가 많이 발생하면서도 중요하기도 한 주식 거래 시스템을 예로 들어, 매수와 매도 상황에서 발생할 수 있
upcurvewave.tistory.com
하지만 이러한 방식 역시도 한계점을 갖고 있는데...
- 성능 저하
모든 스레드가 동시에 접근하려고 하면, Lock을 획득하기 위해 대기 시간이 생기고, 병렬성(Parallelism)이 크게 떨어질 수 있다. - 데드락(Deadlock)
두 스레드가 서로 다른 자원에 대해 Lock을 기다리는 교착 상태가 생길 수 있다. - 설계 복잡도
공유 자원이 많을수록 잠금 범위를 세밀하게 관리해야 하며, Lock이 여러 단계로 얽히면 디버깅이 매우 어려워진다.
결국, 공유 자원을 많이 둘수록 멀티스레드 설계가 복잡해지는 문제가 있다.
(몰른 그 한계도 극복하며 잘 쓸 수 있다.)
공유 자원을 “없애는” 접근
시선을 바꿔서, “여러 스레드가 자원을 공유하지 않는다면?”이라는 관점으로 접근해볼 수도 있지 않을까?
- 각 스레드에 독립적인 복사본을 할당해, 그 스레드가 해당 자원에 단독으로 접근하게 한다.
- 혹은 불변 객체(Immutable)로 만들어 어떤 스레드도 변경하지 못하게 한다.
이렇게 하면 동기화나 락에 대한 복잡한 고민이 크게 줄어든다. 이 지점이 ThreadLocal이 등장하는 지점이다.
Java의 케이스를 다시 예로 들면, 자바에서는 ThreadLocal을 객체로 다루는데, “스레드별 독립된 복사본”을 유지하기 위해 만들어진 도구로서 사용된다. 스레드마다 (CPU 코어마다가 아니라) Thread 객체와 연결된 전용 저장소를 두고, 전역 변수처럼 접근하되, 실제론 스레드 간에 서로 다른 값을 가질 수 있도록 하는 것이다.

ThreadLocal이 동시성 해결에 기여하는 방식
- 스레드 격리(Thread Confinement)
ThreadLocal은 “하나의 전역 변수”에 대해서, 스레드별로 서로 다른 인스턴스를 할당해준다. 즉, 코드상으론 전역처럼 보여도, 실제로는 각 스레드가 자신의 복사본을 보관해 레이스 컨디션이 발생하지 않는다. - 설계 단순화
공유 자원마다 Lock을 걸고 풀어야 하는 수고 없이, 각자 자기만의 사본을 쓴다는 컨셉으로 동시성 문제를 크게 단순화할 수 있다.
물론 좋은 점만 있는 것은 아니다.
ThreadLocal을 남용하면, 어디서 어떻게 값이 설정되고 언제 해제되어야 하는지 추적하기 어려운 “비가시적 전역 상태(Global State)”를 만든다는 비판이 있다.
ThreadLocal의 값은 코드의 여러 위치에서 암묵적으로 접근 가능하므로 어디서 값이 변경되는지 파악하기 어렵기 때문이다. 전역적으로 접근 가능하지만 실제로는 스레드별로 달라진다. 따라서 값이 어떻게 설정되고 언제 사라지는지 코드상에서 명확히 보이지 않게 되는 것이다. 이러한 비가시성은 복잡한 시스템에서 디버깅과 장애 대응을 어렵게 만든다.
또한 스레드를 재사용하는 풀(Thread Pool) 환경에서는, 요청이 끝난 뒤 ThreadLocal 값을 지우지 않으면 메모리 누수나 데이터 오염이 생길 수 있다. 예를 들어, ThreadLocal 값을 지우지 않으면 다음 요청에서 이전 요청의 사용자 정보를 잘못 참조할 수 있다. 이전 요청에서 로그인한 사용자의 인증 정보를 지우지 않으면 다른 사용자에게 잘못된 인증 정보를 제공하는 보안 사고가 발생할 수 있다.
ThreadLocal은 “공유하지 않는” 방법
정리하자면, 멀티스레드 프로그래밍에서 공유 자원을 안전하게 다루는 건 매우 중요하고 어렵다. 전통적으로는 락(Lock)을 사용하지만, 자원이 많을수록 복잡도가 상승한다. 반면, ThreadLocal은 “애초에 스레드 간 공유 자체를 없앤다”는 아이디어로, 동시성 문제를 획기적으로 줄여주는 기법이다.
그렇다면 구체적으로 Java 언어를 예시로, 이제 이 추상 모델을 어떻게 활용하고 있는지 살펴보자.
자바에서는 ThreadLocalMap을 활용해 이 구조를 구체화하고 있다.
2. 자바 ThreadLocal의 핵심 컨셉
JDK ThreadLocal<T> 클래스
ThreadLocal<T>는 자바에서 제공하는 한정(Generic) 클래스로, 각 스레드가 독립된 T 타입의 객체를 보유할 수 있도록 도와준다. 이를 통해 동일한 코드(정적 static 같은 위치)에서 ThreadLocal에 접근하더라도, 스레드별로 전혀 다른 데이터를 얻을 수 있게 된다.
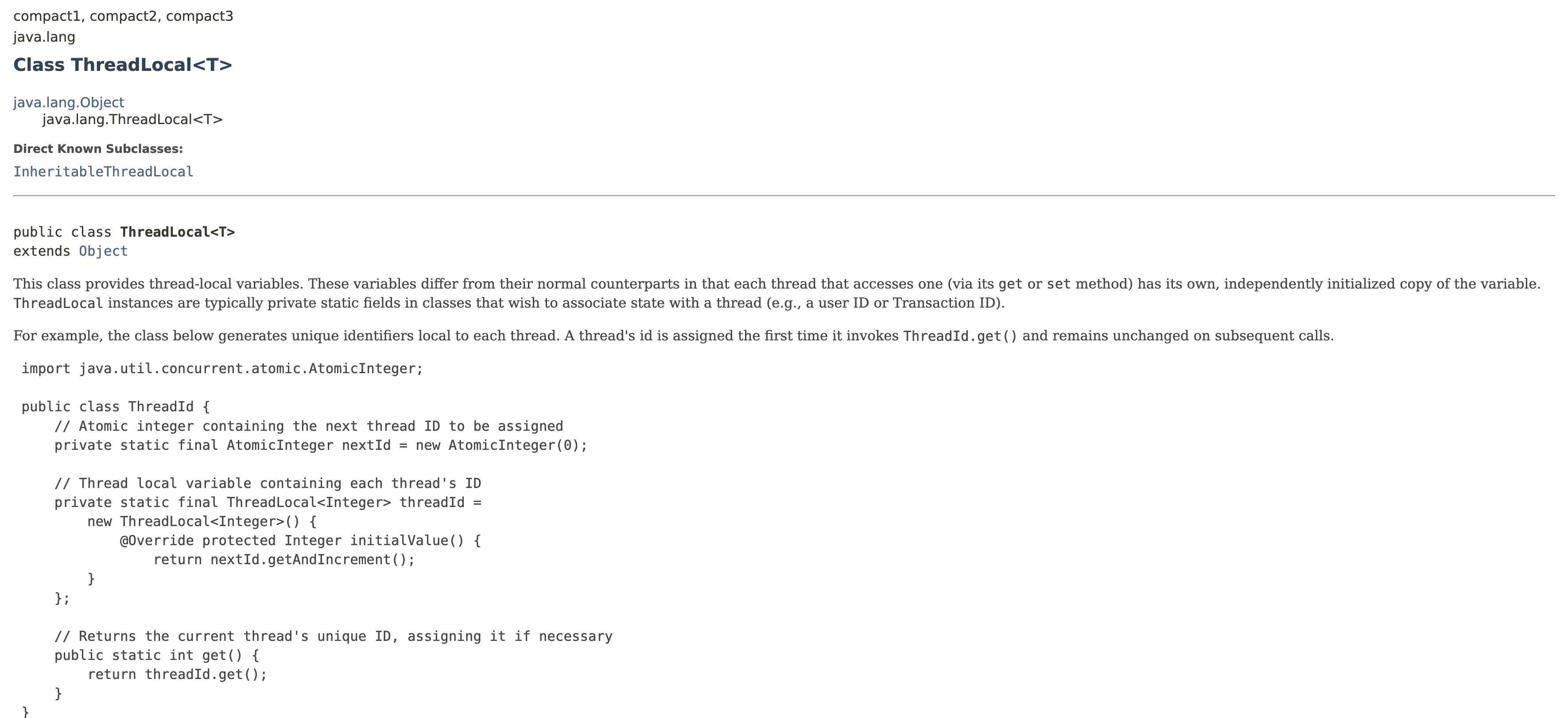
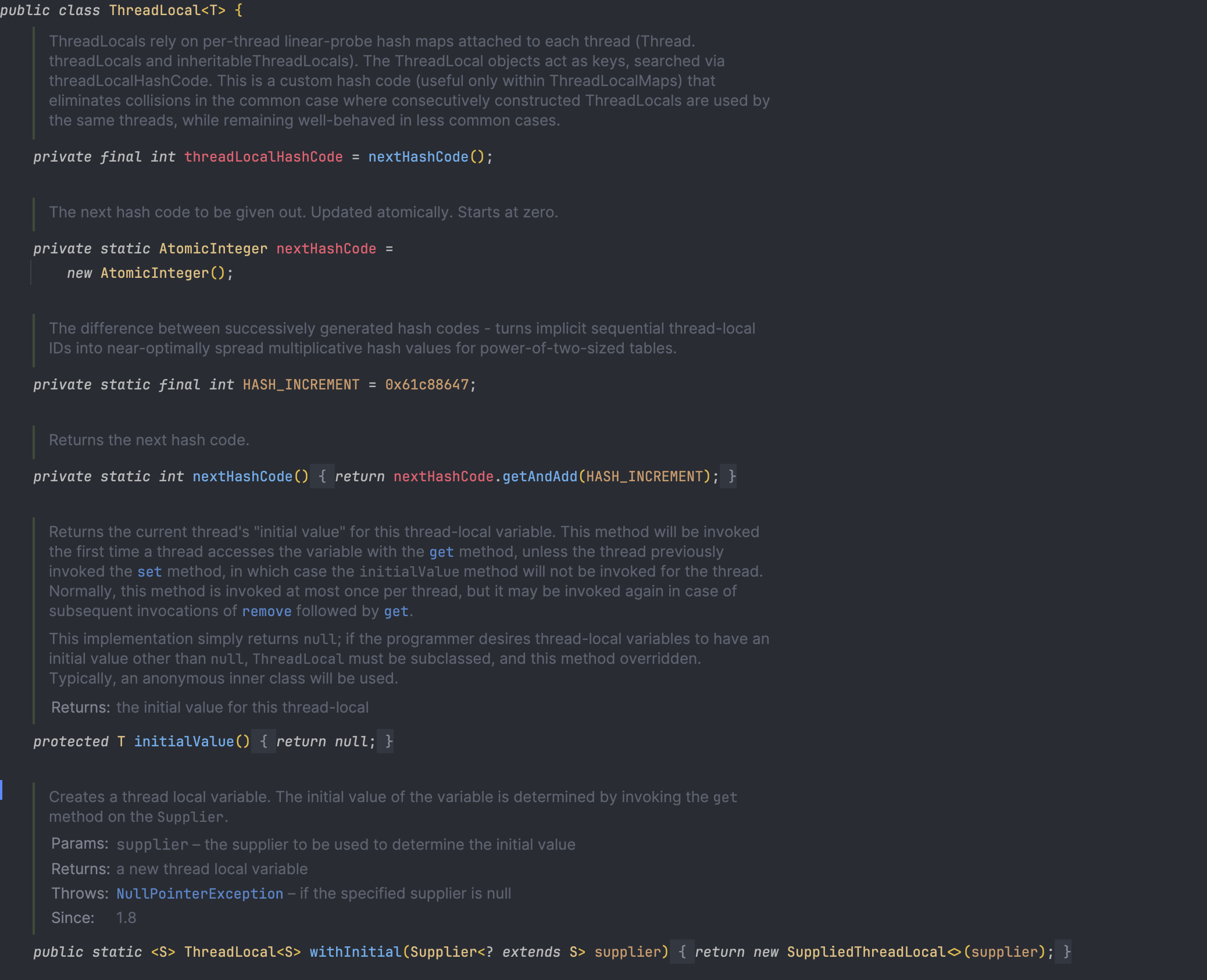
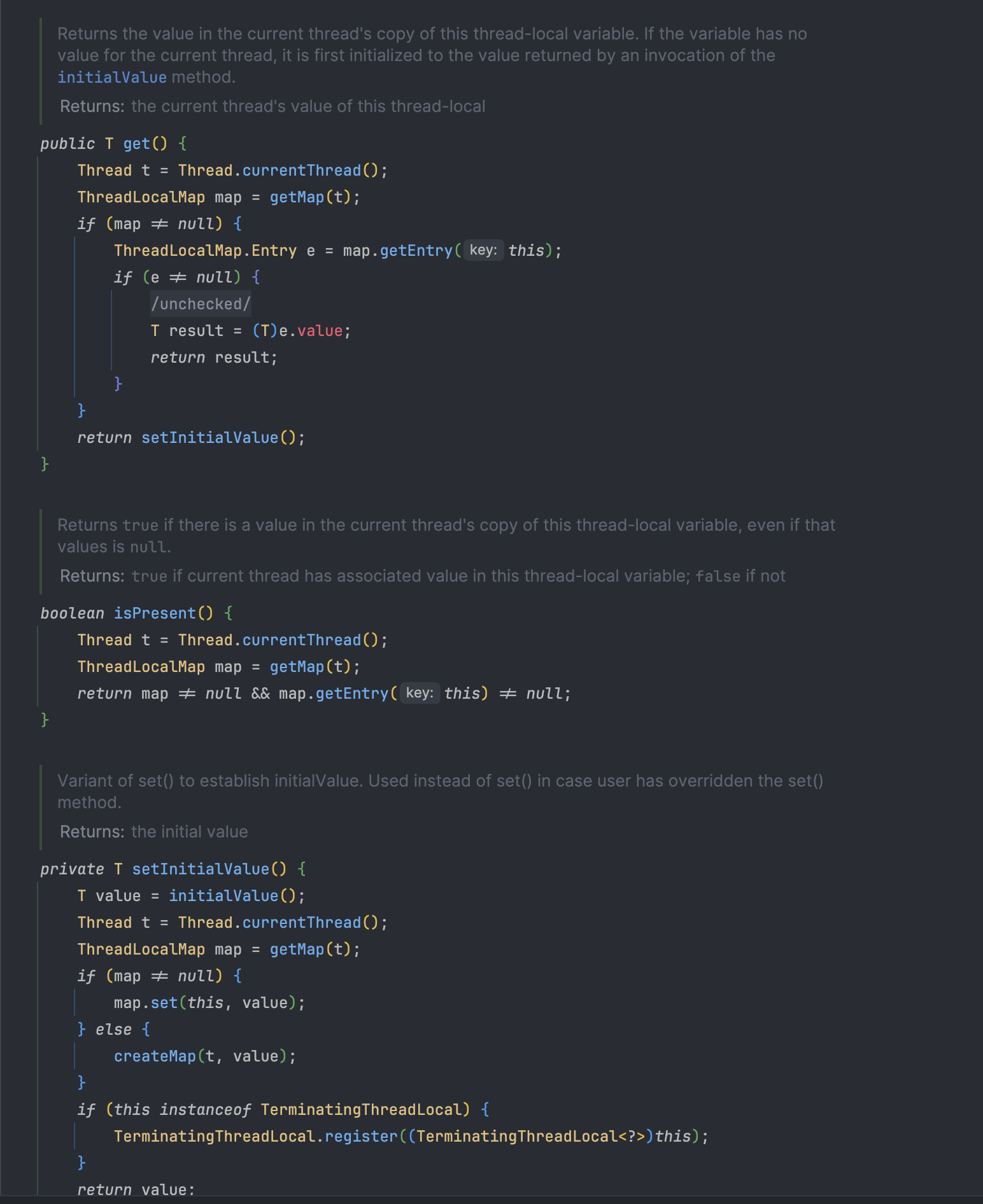
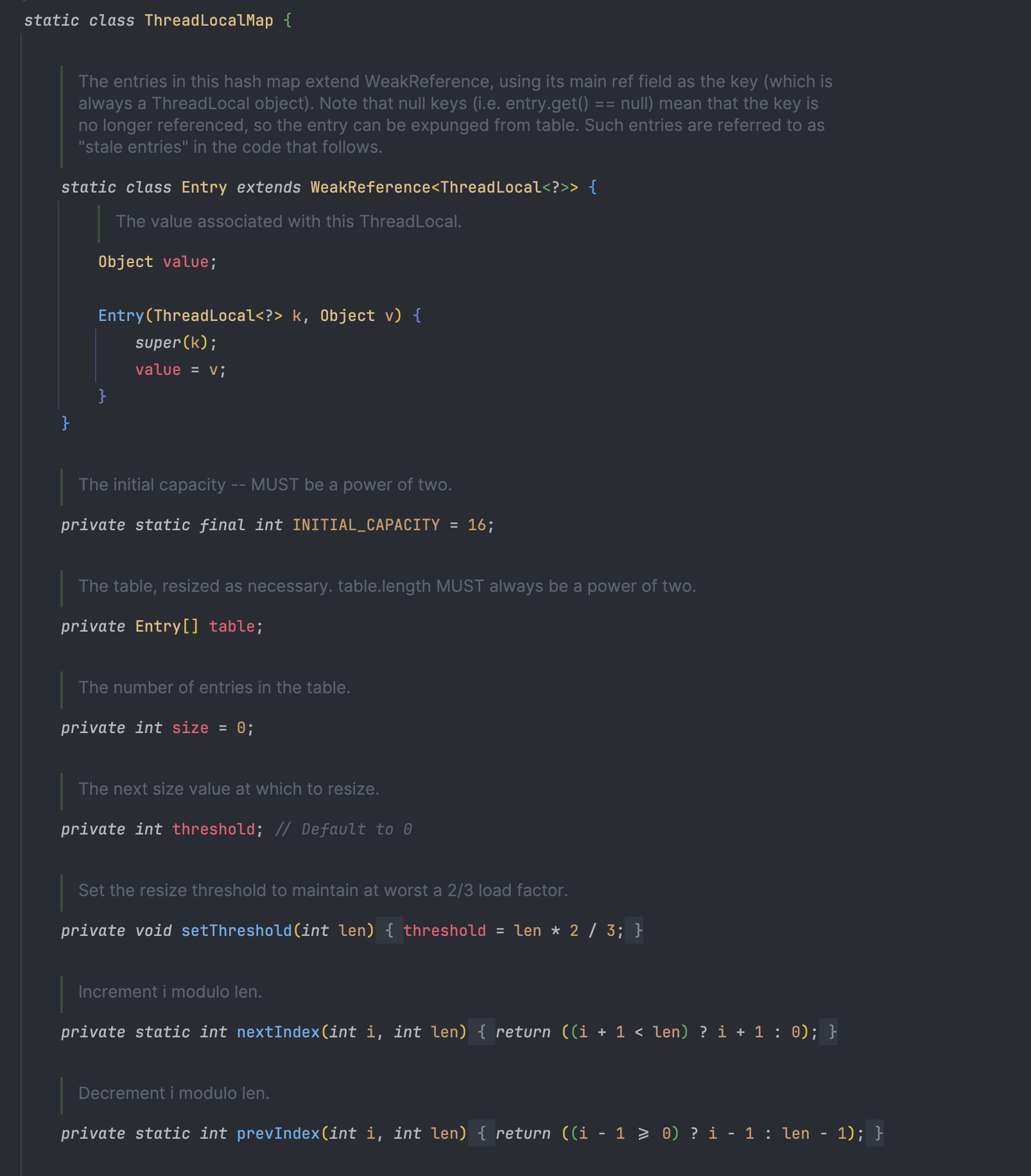
- 주요 메서드
get(): 현재 스레드의 ThreadLocalMap에서 할당된 값을 반환한다. 값이 없으면 보통 null을 리턴하지만,withInitial()을 통해 초기화 로직을 제공하면 자동으로 초기값을 생성하여 넣어준다.set(T value): 현재 스레드의 ThreadLocalMap에value를 저장한다.remove(): 현재 스레드에서 이 ThreadLocal에 해당하는 값을 삭제한다. (내부적으로ThreadLocalMap.remove(this)호출)withInitial(Supplier<? extends T> supplier): ThreadLocal 인스턴스 생성 시 초기화 로직을 람다로 받는 정적 메서드.new ThreadLocal<T>() { protected T initialValue() {...} }형태를 간소화한 것이다.
ThreadLocalMap: 스레드마다 독립된 저장소
ThreadLocal이 어떻게 “스레드별 값”을 구분해 저장하느냐를 이해하려면, 내부 구조인 ThreadLocalMap을 알아야 한다.

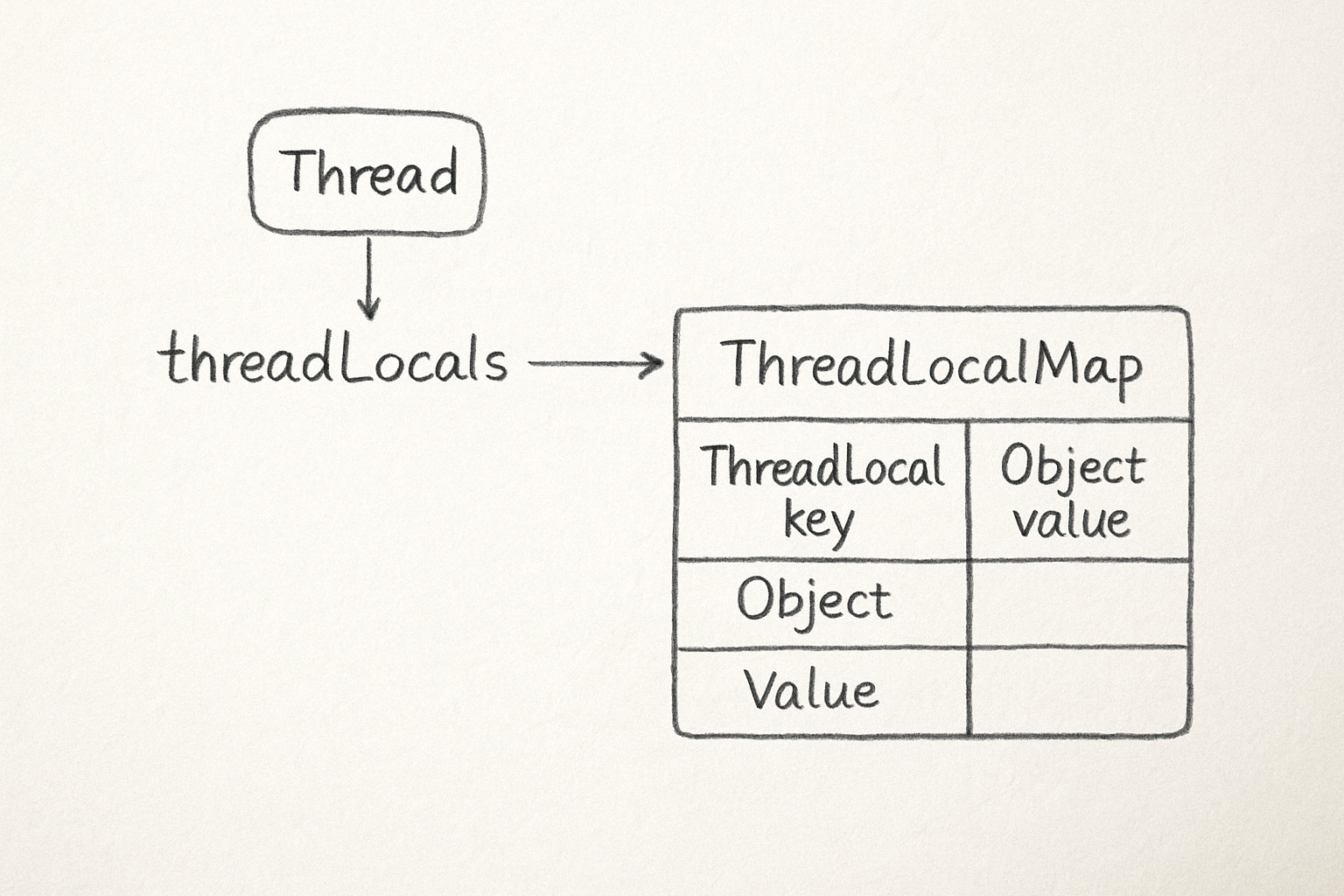
- 자바에서 각
Thread객체는 자신의 ThreadLocalMap 인스턴스를 하나씩 갖고 있다.
class Thread { ThreadLocal.ThreadLocalMap threadLocals = null; ... } - 우리가
myThreadLocal.set(value)라고 하면, 결국 현재 스레드의threadLocals맵 안에myThreadLocal(키) →value(값) 가 저장된다. 따라서 스레드 A에서get()한 값과 스레드 B에서get()한 값은, 서로 다른 Map에서 찾게 되므로 충돌이 없다. ThreadLocalMap은 해시 테이블과 유사한 구조를 가지며, 키로ThreadLocal인스턴스를 사용한다.ThreadLocalMap.Entry라는 전용 내부 클래스를 갖고, 각 엔트리에 (ThreadLocal key, Object value) 쌍을 저장한다.
Thread와 ThreadLocal을 간단히 실험해볼 수 있는 간단한 예시 코드다.
public class ThreadLocalSimpleExample {
// ThreadLocal에 Integer를 저장하고, 초기값을 0으로 설정
private static ThreadLocal<Integer> threadLocalCount = ThreadLocal.withInitial(() -> 0);
public static void main(String[] args) {
// Runnable로 스레드에서 실행할 로직을 정의
Runnable task = () -> {
// 현재 스레드 이름 확인
String threadName = Thread.currentThread().getName();
for (int i = 0; i < 3; i++) {
// 1) ThreadLocal에서 값 가져오기
Integer count = threadLocalCount.get();
// 2) 값 수정 후 다시 저장
threadLocalCount.set(count + 1);
System.out.printf("[%s] 현재 ThreadLocal 값: %d%n", threadName, threadLocalCount.get());
}
// 스레드 작업이 끝난 후, 필요하다면 remove()로 제거
threadLocalCount.remove();
};
// 두 개의 스레드를 생성하고 각각 task를 실행
Thread threadA = new Thread(task, "Thread-A");
Thread threadB = new Thread(task, "Thread-B");
threadA.start();
threadB.start();
}
}
어떤 상황일까? 먼저, threadLocalCount는 ThreadLocal.withInitial(...) 메서드를 통해 초기값을 0으로 지정된다. 그렇기 때문에 각 스레드가 get()을 처음 호출할 때 0을 반환하고, 이후 set()을 통해 증가시킨 값을 스레드마다 독립적으로 유지한다.
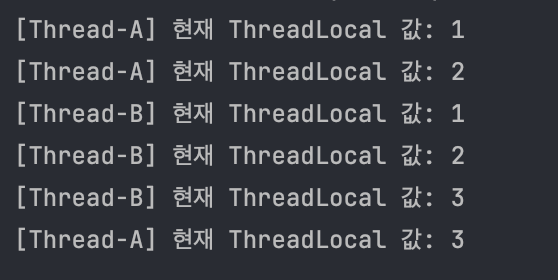
위 코드를 실행해보면, 예시와 비슷하게 다음과 같은 결과가 나타난다.
[Thread-A] 현재 ThreadLocal 값: 1
[Thread-B] 현재 ThreadLocal 값: 1
[Thread-B] 현재 ThreadLocal 값: 2
[Thread-B] 현재 ThreadLocal 값: 3
[Thread-A] 현재 ThreadLocal 값: 2
[Thread-A] 현재 ThreadLocal 값: 3
스레드 간에 동시에 실행되면서 출력을 찍기 때문에, 각 문장의 순서는 실행 시점마다 달라질 수 있다(스케줄링이나 CPU 할당 시점 등에 따라 다름).
예를 들어 다음과 같다.
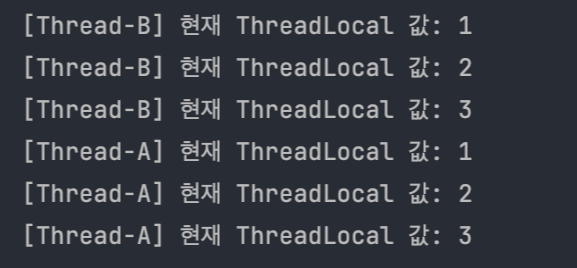
하지만 Thread-A와 Thread-B 의 시퀀스 증가 패턴 자체는 항상 일정하다.
Thread-A는 1→2→3 순으로 증가하고, Thread-B는 별도로 1→2→3 순으로 값을 바꾼다. 즉, Thread-A 값이 증가해도 Thread-B의 값에 직접적인 영향을 주지 않는다는 것이다.
두 스레드가 동시에 동작하므로 실제 로그에서는 A와 B의 출력 순서가 섞여 있지만, 각각의 최종값은 동일하게 3이 된다.
이를 통해 알 수 있듯이, ThreadLocal은 “각 스레드가 독립적으로 데이터를 저장하고 접근”할 수 있게 해준다. 만약 이 예시에서 static int count 같은 정적 변수를 사용했다면, 한 스레드가 값을 바꾸면 다른 스레드도 동일한 값에 접근하게 되어 충돌(값이 덮어씌워지는 등)이 발생했을 것이다. 그러나 ThreadLocal을 사용함으로써, 그런 문제 없이 스레드마다 독립적으로 카운팅 로직을 수행할 수 있게 된다.
중요: ThreadLocalMap은 Thread 객체 내부에 존재하므로, 스레드가 GC될 때 함께 사라진다. 그러나, 스레드 풀처럼 스레드를 재사용하는 경우는 스레드가 계속 살아있을 수 있기 때문에, ThreadLocal값도 지속적으로 남아 있을 수 있다. 이를 제대로 관리하지 않으면 메모리 누수가 일어날 수 있다. (이는 뒤에서 자세히 다룰 예정)
데이터는 어디에 숨어 있을까?
그런데 여기서 한 가지 궁금한 게 생긴다. 그렇다면 이 ThreadLocal 이 저장되는 장소는 어디일까?
“스택이 아닌 힙”에 존재하는 ThreadLocalMap
직관적으로 생각해보았을 때, “ThreadLocal = 스택에 값이 저장된다”라고 생각하기 쉽다.
왜냐하면 공유자원이기는 한데, 쓰레드 별로 할당받고 관리되는 개념이라면, 일종의 abstract class처럼 본판은 힙 메모리에 저장되고, 각 함수의 메모리를 저장하는 스택별로 복사본으로서의 "ThreadLocal" 을 갖는다고 생각하기 쉽기 때문이다.
그러나 자바 스레드 스택은 ‘메서드 호출 프레임, 지역 변수, 연산 스택’을 담는 영역으로, 우리가 임의로 객체를 보관하거나 조작할 수 있는 구조가 아니다. 실제로 ThreadLocal의 값은 힙 영역에 생성된 Thread 객체 내부의 필드(ThreadLocalMap)에 보관된다.
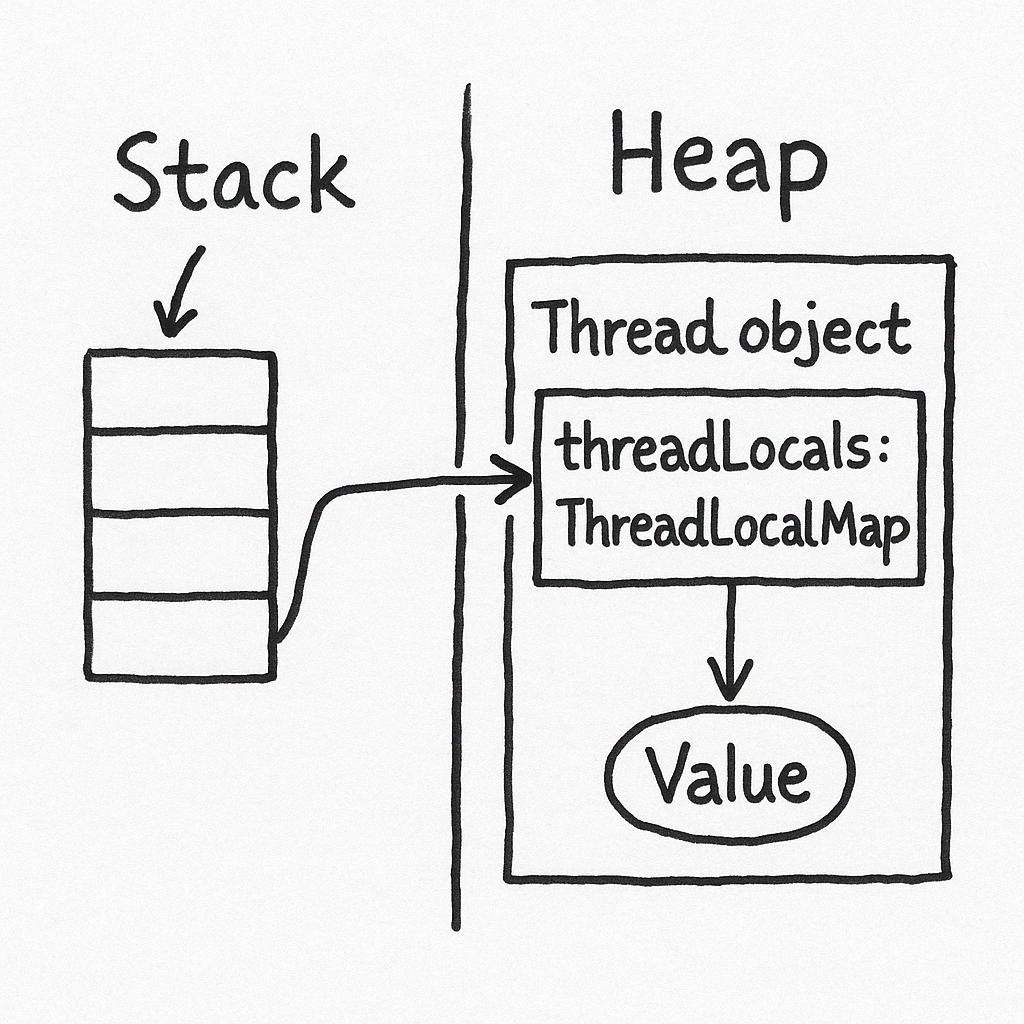
- 스택(stack)은 함수 호출/리턴 시점에 따라 할당/해제되는 특수 메모리 영역이므로, 그 안에 임의의 객체(
T타입 등)를 저장하기는 적절치 않다. - 자바의
Thread인스턴스는 일반 클래스처럼 힙(Heap)에 생성되고, 이 Thread 인스턴스 안에threadLocals맵이 존재한다. ThreadLocalMap역시 결국 힙에 자리 잡고 있으므로, ThreadLocal 값들은 “(현재 스레드) Thread 객체의 필드 - ThreadLocalMap” 을 거쳐 참조된다.
그렇다면 다른 언어는 다를까? 몇가지 다른 언어를 리서치해보았다.
Go 언어에서는 컨텍스트(Context) 객체를 통해 요청마다 별도의 상태를 명시적으로 관리한다. 파이썬의 threading.local도 유사한 개념으로 스레드 전용 데이터를 제공하지만, 자바처럼 구조화된 ThreadLocalMap 대신 좀 더 간단한 방식으로 구현되어 있다. C#은 ThreadStatic 특성을 통해 스레드 전용 정적 필드를 지원한다.
이들 모두 언어마다 구체적인 저장 구조는 다르지만, “스레드별 데이터 독립 관리”라는 개념은 비슷하게 유지된다.
Thread 객체와 가비지 컬렉션의 관계
가비지 컬렉션(GC) 관점에서, ThreadLocal 값을 가진 스레드가 종료(dead)되면, 스레드 객체도 힙에서 GC 대상이 된다. 이 때 threadLocals도 함께 수거된다. 결과적으로, 스레드가 끝났다면 ThreadLocal 데이터도 자연스럽게 정리된다.
다만, 스레드 풀(예: Tomcat/Jetty 웹 서버의 worker thread)에서는 스레드가 한 번 종료되지 않고, 다음 요청을 위해 재사용된다. 이 경우, 이전 요청에서 설정했던 ThreadLocal 값이 남아있을 수 있다. 요청이 끝나도 스레드는 살아있으므로, ThreadLocalMap도 유지될 수 있기 때문이다.
이 때문에 ThreadLocal 사용 시 반드시 remove()를 호출하거나, 프레임워크 레벨에서 적절히 초기화해야, 다음 요청에서 잘못된 데이터를 참조하는 문제나 메모리 누수를 방지할 수 있다.
어디서 사용될까?
이제 이 ThreadLocal 이 실제 사용되는 사례를 생각해보고자 한다.
두가지 대표적인 케이스가 있다.
1) 스프링 시큐리티의 컨텍스트
예: Spring Security의 SecurityContextHolder
요청 스레드별로 Authentication(인증·권한 정보)을 저장해 두고, 어느 계층에서든 쉽게 꺼내 쓸 수 있다.
2) 트랜잭션 ID, 트레이싱
예: 로깅 시 스레드별로 UUID를 부여해 식별
동일한 스레드에서 일어나는 호출 흐름을 한데 묶어, 로깅에 활용하면 디버깅이 편리해진다. 계층형 로깅, 트랜잭션 추적 등 다양한 시나리오에서 쓰일 수 있다.
이어지는 섹션에서 Spring Security 내부 구현과 Log Tracer에서 사용되는 사례를 자세히 다뤄보자.
3. 스프링 시큐리티에서 ThreadLocal을 사용하는 방법
3.1 스프링 시큐리티에서 인증 정보를 전역으로 다루는 이유
웹 애플리케이션을 개발하다 보면, “지금 로그인한 사용자 정보(인증·권한)를 서비스 계층이나 DAO 계층 등에서 쉽게 알고 싶다”는 니즈가 생긴다. 이를 모든 계층에 파라미터로 넘겨주기엔 불편하고, static 전역 변수에 두자니 동시성 문제가 걱정된다.
Spring Security는 이러한 문제를 해결하기 위해, “요청 스레드마다 독립적인 보안 정보(Authentication)를 전역처럼 접근할 수 있게 해주자”는 아이디어를 채택했다. 이때 핵심 구현이 바로 ThreadLocal이다. 구체적으로는, SecurityContextHolder라는 클래스가 ThreadLocal을 통해 SecurityContext(인증 정보를 담은 컨텍스트)를 관리한다.

3.2 SecurityContextHolder와 기본 ThreadLocal 전략
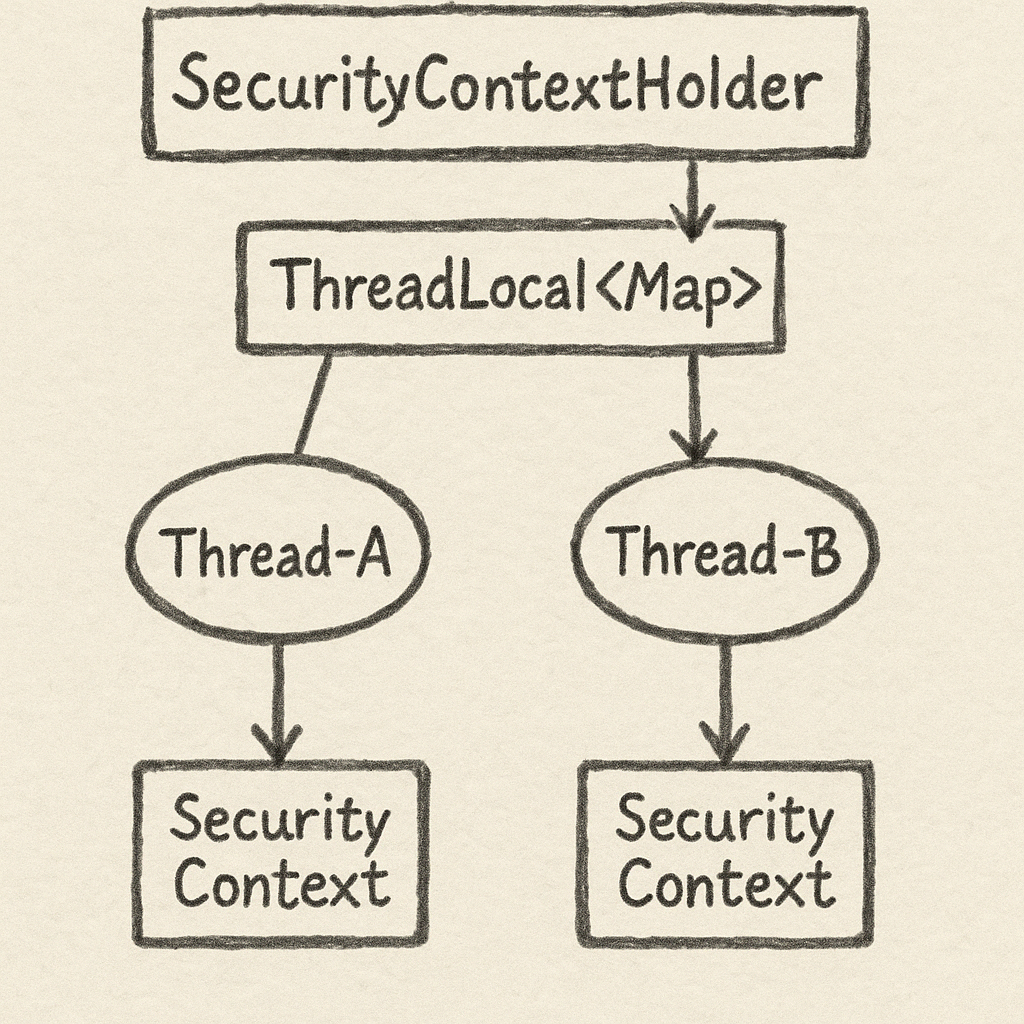
스프링 시큐리티에는 다음과 같은 구조가 있다.
1. SecurityContextHolder 클래스
- 정적(static) 메서드로 getContext(), setContext(), clearContext() 등을 제공.
- 내부적으로
SecurityContextHolderStrategy인터페이스를 사용해 “SecurityContext를 어디에 저장할지” 결정함.
2. ThreadLocalSecurityContextHolderStrategy (기본 전략)
SecurityContextHolderStrategy의 구현체. 이름 그대로, ThreadLocal을 사용하여 현재 스레드에만 해당하는SecurityContext를 저장한다.- 즉,
SecurityContextHolder.getContext()호출 시 → 현재 스레드의 ThreadLocal에서 SecurityContext를 가져옴(없으면 새로 생성). SecurityContextHolder.clearContext()호출 시 → ThreadLocal 값을 remove()하여, 다음 요청에 오염되지 않도록 보장.
3. 요청 스레드 - SecurityContext의 대응
- 서블릿 환경에서는 기본적으로 “요청 당 하나의 스레드”가 배정된다 (스레드 풀 재사용이 있지만, 한 번의 요청 처리 중엔 해당 스레드가 고정).
- 따라서 동일한 요청 내에서 코드가 어느 계층으로 가든
SecurityContextHolder.getContext()를 부르면, 동일한 인증 정보를 얻을 수 있다.
왜 ThreadLocal이 꼭 필요한가?
3가지 이유 때문이다.
- 파라미터 전달: 인증 정보를 매번 모든 메서드의 인자로 넘기지 않아도 됨
- 동시성 문제 해소: 여러 요청이 동시에 들어오더라도, ThreadLocal 덕분에 각 요청 스레드는 다른 SecurityContext를 사용
- 편의성: 스프링 시큐리티가 자동으로 ThreadLocal 정리(초기화/제거)까지 해주므로, 개발자는 편리하게 인증 정보를 활용 가능
3.3 요청 라이프사이클에서의 ThreadLocal 관리
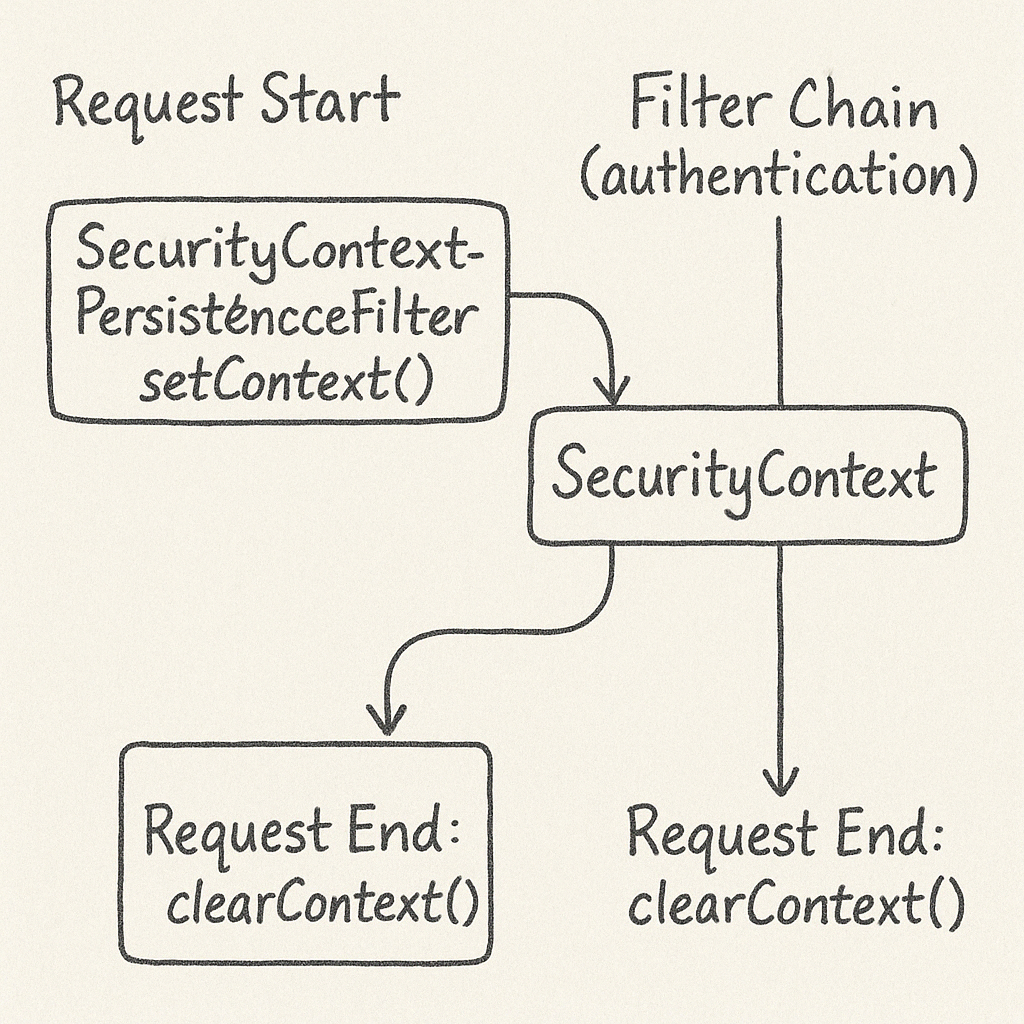
3.3.1 SecurityContextHolderFilter (Spring Security 6) 또는 SecurityContextPersistenceFilter (이전 버전)
Spring Security는 필터 기반으로 동작한다. SecurityContextHolderFilter(또는 과거 SecurityContextPersistenceFilter)가 요청 시작 시 SecurityContextHolder.setContext(...)로 ThreadLocal을 초기화하고, 응답 후에는 SecurityContextHolder.clearContext()를 호출하여 정리한다.
1 요청 시작
SecurityContextRepository.loadContext()등을 통해, 기존 세션 등에 저장된 인증 정보를 불러오거나, 없으면 빈(SecurityContext) 생성SecurityContextHolder.setContext(...);→ ThreadLocal에 삽입
2. 체인 실행 중
- 인증 로직(폼 로그인, JWT 등)이 성공하면
SecurityContextHolder.getContext().setAuthentication(auth)식으로 스레드 전용 인증 정보 세팅
3. 요청 종료
- 필터가
SecurityContextHolder.getContext()로 최종 컨텍스트를 얻어 세션에 저장할지 결정 SecurityContextHolder.clearContext()를 호출해 ThreadLocal remove() → 스레드 풀 재사용 시, 오염 방지
3.3.2 자동 정리(초기화/제거)의 중요성
ThreadLocal은 수동으로 remove() 해주지 않으면, 같은 스레드가 다음 요청을 처리할 때 이전 인증 정보가 남아 보안 사고가 날 수 있다. Spring Security는 이를 필터 체인으로 자동 관리해줘서, 개발자가 직접 ThreadLocal 정리에 신경 쓸 필요가 없다.
다음과 같은 식이다.
- 필터 체인의 시작(
SecurityContextHolderFilter)에서 ThreadLocal에 SecurityContext를 초기화하여 인증 처리를 시작한다. - 모든 요청 처리가 끝나면 필터 체인의 끝에서 반드시
clearContext()를 호출하여 ThreadLocal의 SecurityContext를 정리(remove)한다. - 따라서 개발자가 별도 정리 코드를 작성할 필요 없이 요청이 끝날 때마다 항상 ThreadLocal이 자동 초기화된다.
3.4 다른 전략과 확장 (Inheritable, Global, Reactive)
Spring Security는 다양성을 고려해, SecurityContextHolderStrategy를 교체할 수 있는 확장 지점도 제공한다.
1. InheritableThreadLocalSecurityContextHolderStrategy
- 자식 스레드 생성 시, 부모 스레드의 컨텍스트를 복사(InheritableThreadLocal).
- @Async 등에서 “부모 스레드의 인증 정보”를 활용해야 하는 경우 쓸 수 있으나, 스레드 풀 재활용 시 주의가 필요.
2. GlobalSecurityContextHolderStrategy
- 애플리케이션 전체가 하나의 SecurityContext를 공유.
- 웹 환경에선 거의 쓰이지 않지만, 데스크톱 앱처럼 “사용자 1명”인 경우엔 간단하게 사용할 수 있음.
3. 리액티브(WebFlux) 환경
- WebFlux에서는 하나의 요청이 여러 스레드로 나뉘거나, 한 스레드가 여러 요청을 다룰 수 있으므로 ThreadLocal 전제가 깨진다.
- 따라서
ReactiveSecurityContextHolder와 ReactorContext를 통해 “논블로킹 환경”에서도 인증 정보를 추적할 수 있도록 별도 메커니즘이 제공된다.
정리해보면, 스프링 시큐리티는 멀티스레드 기반 서블릿 환경에서 ThreadLocal을 사용해, “전역처럼 보이면서도 요청마다/스레드마다 분리된 보안 컨텍스트”를 제공해주는 게 핵심이다.
동시성 문제나 context 정리와 같은 번거로운 작업에 개발자가 신경쓰지 않고도 인증에 필요한 UseCase만 쓸 수 있도록 도와준다.
4. Log Tracer 구현에서 Thread Local 사용하기
또 다른 예시 중 하나는 Log Trace 기능에서 사용되는 케이스이다.
여기서 다루는 Log Tracer는 김영한님이 AOP 강의에서 구현하신 Log Tracer를 디벨롭한 것이다.
4.1 계층형 로깅(Tracing)이 필요한 이유
당연하겠지만, 로그의 특성상 단순히 “메서드가 호출됨” 정도의 정보만으로는 호출 흐름을 파악하기 어렵다. 예를 들어:
- Controller → Service → Repository 순으로 메서드가 중첩 호출되는 상황
- 하나의 HTTP 요청 안에서, 여러 메서드가 재귀적으로 불리거나 추가 로직을 거치는 경우
- 특정 트랜잭션(또는 요청) ID를 기준으로 로그를 묶어 보고 싶은 경우
이런 시나리오에서 “계층형 로깅” 또는 “트랜잭션 ID 트레이싱”을 하면, 로그를 조금만 봐도 “이 메서드가 어디서부터 호출되었고, 어떤 로직이 예외를 일으켰는지” 등을 한눈에 파악할 수 있다. 바로 이때 ThreadLocal이 유용하게 쓰인다.
4.2 ThreadLocal을 이용한 Log Tracer 개념
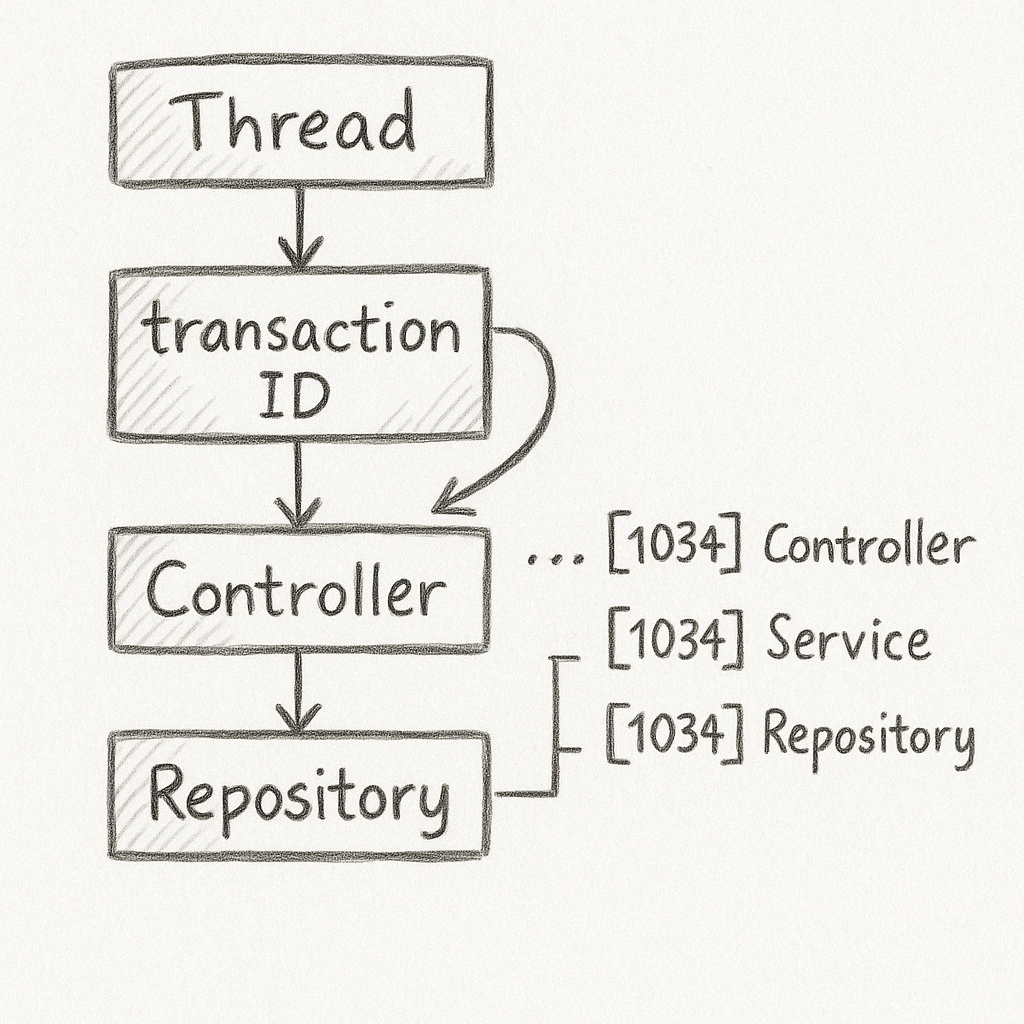
4.2.1 스레드별 Trace ID, 호출 레벨(Level) 관리
보통 하나의 요청(=하나의 스레드)이 시작될 때 UUID 등을 생성해 “Trace ID”로 삼고, 이를 ThreadLocal에 보관한다. 이후 계층이 깊어질수록(메서드 A→B→C) level 값을 1씩 증가시켜, 로그에서 “| |-->” 같은 들여쓰기를 표현할 수 있다.
1. Trace ID:
- “현재 요청 흐름”을 식별하기 위한 고유 값.
- 스레드별로 하나씩만 존재한다. (ThreadLocal 형태 등)
2. Level:
- 호출 계층을 나타내는 정수 값. 0이면 최상위, 1이면 한 단계 들어간 상태.
- ThreadLocal에 저장하거나, Trace ID 객체에 함께 저장해둔다.
3. 메서드 시작(begin) / 종료(end) 시 로그:
begin(): Trace ID와 Level을 확인 후, “-->” 접두사와 들여쓰기로 메서드 시작 로그를 남긴다.end(): Level을 확인해 “<--”로 마무리 로그를 남기고, level을 감소시키거나(혹은 ThreadLocal에서 제거) 한다.- Level이 0이 되면(=최상위 호출 종료) ThreadLocal을
remove()하여 다음 요청에 오염되지 않도록 한다.
4.2.2 예외 처리(Exceptions)
예외가 발생했을 때도 ThreadLocal을 이용하면,
- 동일 스레드에서 예외 로그를 한 번만 남기거나,
- 트랜잭션 내 예외가 어디서 발생했는지(계층 어느 레벨?)를 표시,
등을 손쉽게 구현할 수 있다.
4.3 코드 예시: ThreadLocal 기반 Tracer
간단한 Log Tracer 예시 구조를 살펴보자.
public class ThreadLocalLogTracer {
private ThreadLocal<TraceInfo> traceHolder = new ThreadLocal<>();
public void begin(String message) {
TraceInfo traceInfo = traceHolder.get();
if (traceInfo == null) {
// 최상위 계층 → 새 TraceInfo 생성
traceInfo = new TraceInfo(UUID.randomUUID().toString(), 0);
} else {
// 이미 있으면 level +1
traceInfo = traceInfo.createNextLevel();
}
traceHolder.set(traceInfo);
// 로그 찍기
log.info("[{}] {}{}", traceInfo.getTraceId(), prefix("BEGIN", traceInfo.getLevel()), message);
}
public void end(String message) {
TraceInfo traceInfo = traceHolder.get();
long endTime = System.currentTimeMillis();
// 로그 찍기
log.info("[{}] {}{}", traceInfo.getTraceId(), prefix("END", traceInfo.getLevel()), message);
// 레벨 감소 or 제거
if (traceInfo.getLevel() == 0) {
traceHolder.remove(); // 최상위 레벨이면 ThreadLocal clear
} else {
traceHolder.set(traceInfo.createPrevLevel());
}
}
// 예외 로그, prefix() 등 유틸 메서드는 생략
}
1. TraceInfo
traceId+level를 가지고,createNextLevel()등 메서드로 레벨 증감 가능.
2. ThreadLocal<TraceInfo> traceHolder
- 현재 스레드에서 유일한
TraceInfo를 조회/저장. - 최상위 레벨이 끝나면 remove()로 값을 없애, 스레드 풀 재사용 시 이전 TraceInfo가 남아있지3않게 함.
이때, 보통 Spring AOP(@Around) 등으로 컨트롤러/서비스/리포지토리 메서드에 일괄 적용한다. “메서드 진입 시 begin(), 종료 시 end()”를 자동으로 호출함으로서 관심사를 분리하는 것이다. 이렇게 하면 코드에 로깅 로직을 흩뿌리지 않고도, 계층형 로그를 일관되게 남길 수 있다.
4.4 활용 시 주의사항
마찬가지로 주의사항이 있다.
1. ThreadLocal 정리
- 최상위 레벨이 끝났다고 판단되면 반드시
remove()를 호출해야, 스레드 풀 재활용 시 이전 트랜잭션 ID가 남아있지 않는다.
2. 비동기 작업
- @Async나 WebFlux 환경에서는 스레드가 고정되지 않을 수 있어, ThreadLocal 로깅이 끊기거나 섞일 위험이 있다. 별도 처리(DelegatingCallable, Reactor Context 등)를 고려해야 한다.
3. 로그량 증가
- 계층별로 로그가 많이 찍힐 수 있으므로, 개발/운영 환경에서 적절한 로그 레벨 조정이 필요할 수 있다.
5. 결론 및 마무리
확실히, “서블릿-스레드 1:1” 모델을 사용하는 경우 ThreadLocal은 강력하고 실용적인 선택지를 줄 수 있다.
현재까지의 자바 서버 개발 흐름에서, ThreadLocal은 근 20년간 안정된 패턴으로 자리잡아 온듯 하다. Spring Security, Hibernate, Logback MDC 등 다양한 프레임워크가 ThreadLocal을 적극 활용해, 개발자에게 “자동화된 동시성 안전”을 제공하고 있다.
하지만 자바 21 이후 가상 스레드(Virtual Threads) 등장이나 ScopedValue 같은 대안의 추가로, 미래에는 ThreadLocal 기반 설계가 조금씩 바뀔 가능성이 열려 있다고 한다.
핵심 정리
- ThreadLocal = 스레드별 독립 데이터 저장
- 필수 조건: 올바른 라이프사이클 관리(remove!)
- 서블릿 기반: 매우 편리 / 리액티브: 대안 필요
- 한눈에 전역 상태를 다루되, 오남용 시 디버깅·메모리 누수 문제가 심각

레퍼런스
- https://docs.oracle.com/javase/8/docs/api/java/lang/ThreadLocal.html#:~:text=%2A%20
'Q&A' 카테고리의 다른 글
| 충돌 없는 완벽한 해싱이 존재한다고 ? (퍼펙트 해싱 개념 및 사례, 최적화 방법에 대해서) (4) | 2024.11.02 |
|---|---|
| 로깅 추적을 위한 AOP 적용과 이후 성능 차이 그리고 why ?! (0) | 2023.12.14 |
| 컴퓨터는 실제로 배열의 데이터에 index로 접근할까? (1) | 2023.11.24 |
| 왜 int, String 배열은 스트림(Stream)으로 쉽게 변환되는데 char 배열은 안 되는 것일까?! (자바 캐릭터 배열 스트림으로 변환하기) (0) | 2023.06.24 |


