- 저자
- 이성욱, 백은빈
- 출판
- 위키북스
- 출판일
- 2021.09.08
읽으면서 중요하다고 생각하거나 기억하고 싶은 부분을 기록하였습니다.
MySQL 엔진은 클라이언트로부터의 접속 및 쿼리 요청을 처리하는 커넥션 핸들러와 SQL 파서 및 전처리기, 쿼리의 최적화된 실행을 위한 옵티마이저가 중심을 이룬다.
- 78p
쿼리 캐시
MySql 서버에서 쿼리 캐시는 빠른 응답을 필요로 하는 웹 기반의 응용 프로그램에서 매우 중요한 역할을 담당했다. 쿼리 캐시는 SQL는 실행 결과를 메모리에 캐시하고, 동일 SQL 쿼리가 실행되면 테이블을 읽지 않고 즉시 결과를 반환하기 때문에 매우 빠른 성능을 보였다. 하지만 쿼리 캐시는 테이블의 데이터가 변경되면 캐시에 저장도니 결과 중에서 변경된 테이블과 관련된 것것들을 모두 삭제 해야 했다. 이는 심각한 동시 처리 성능 저하를 유발한다. 또한 MySQL 서버가 발전하면서 성능이 개선되는 과정에서 쿼리 캐시는 계속된 동시 처리 성능 저하와 많은 버그의 원인이 되기도 했다.
결국 MySQL 8.0으로 올라오면서 쿼리 캐시는 MySQL 서버의 기능에서 완전히 제거되고, 관련된 시스템 변수도 모두 제거됐다. MySQL 서버의 쿼리 캐시 기능은 아주 독특한 환경(데이터 변경은 거의 없고 읽기만 하는 서비스)에서는 매우 훌륭한 기능이었지만 이런 요건을 가진 서비스는 흔치 않다. 실제 쿼리 캐시 기능이 큰 도움이 됐던 서비스는 거의 없었다. 이 같은 이유로 MySQL 서버에서 쿼리 캐시를 제거한 것은 좋은 선택이라고 생각한다.
- 93p
프라이머리 키에 의한 클러스터링
InnoDB의 모든 테이블은 기본적으로 프라이머리 키를 기준으로 클러스터링되어 저장된다. 즉, 프라이머리 키 값의 순서대로 디스크에 저장된다는 뜻이며, 모든 세컨더리 인덱스는 레코드의 주소 대신 프라이머리 키의 값을 논리적인 주소로 사용한다. 프라이머리 키가 클러스터링 인덱스이기 때문에 프라이머리 키를 이용한 레인지 스캔은 상당히 빨리 처리될 수 있다. 결과적으로 쿼리의 실행 계획에서 프라이머리 키는 기본적으로 다른 보조 인덱스에 비해 비중이 높게 설정(쿼리의 실행 계획에서 다른 보조 인덱스보다 프라이머리 키가 선택될 확률이 높음)된다.
- 99p
MVCC(Multi Version Concurrency Control)
일반적으로 레코드 레벨의 트랜잭션을 지원하는 DBMS가 제공하는 기능이며, MVCC의 가장 큰 목적은 잠금을 사용하지 않는 일관된 읽기를 제공하는 데 있다. InnoDB는 언두 로그(Undo log)를 이용해 이 기능을 구현한다. 여기서 멀티 버전이라 함은 하나의 레코드에 대해 여러 개의 버전이 동시에 관리된다는 의미다. 이해를 위해 격리 수준(Isolation level)이 READ_COMMITTED인 MySQL 서버에서 InnoDB 스토리지 엔진을 사용하는 테이블의 데이터 변경을 어떻게 처리하는지 그림으로 한 번 살펴보자.
우선 다음과 같은 테이블에 한 건의 레코드를 INSERT 한 다음 UPDATE해서 발생하는 변경 작업 및 절차를 확인해 보자.
CREATE TABLE member (
m_id INT NOT NULL,
m_name VARCHAR(20) NOT NULL,
m_area VARCHAR(100) NOT NULL,
PRMARY KEY (m_id),
INDEX ix_area (m_area)
);
mysql> INSER INTO member (m_id, m_name, m_area) VALUES(12, '홍길동', '서울');
mysql> commit;
INSERT 문이 실행되면 데이터베이스의 상태는 다음과 같은 상태로 바뀔 것이다.
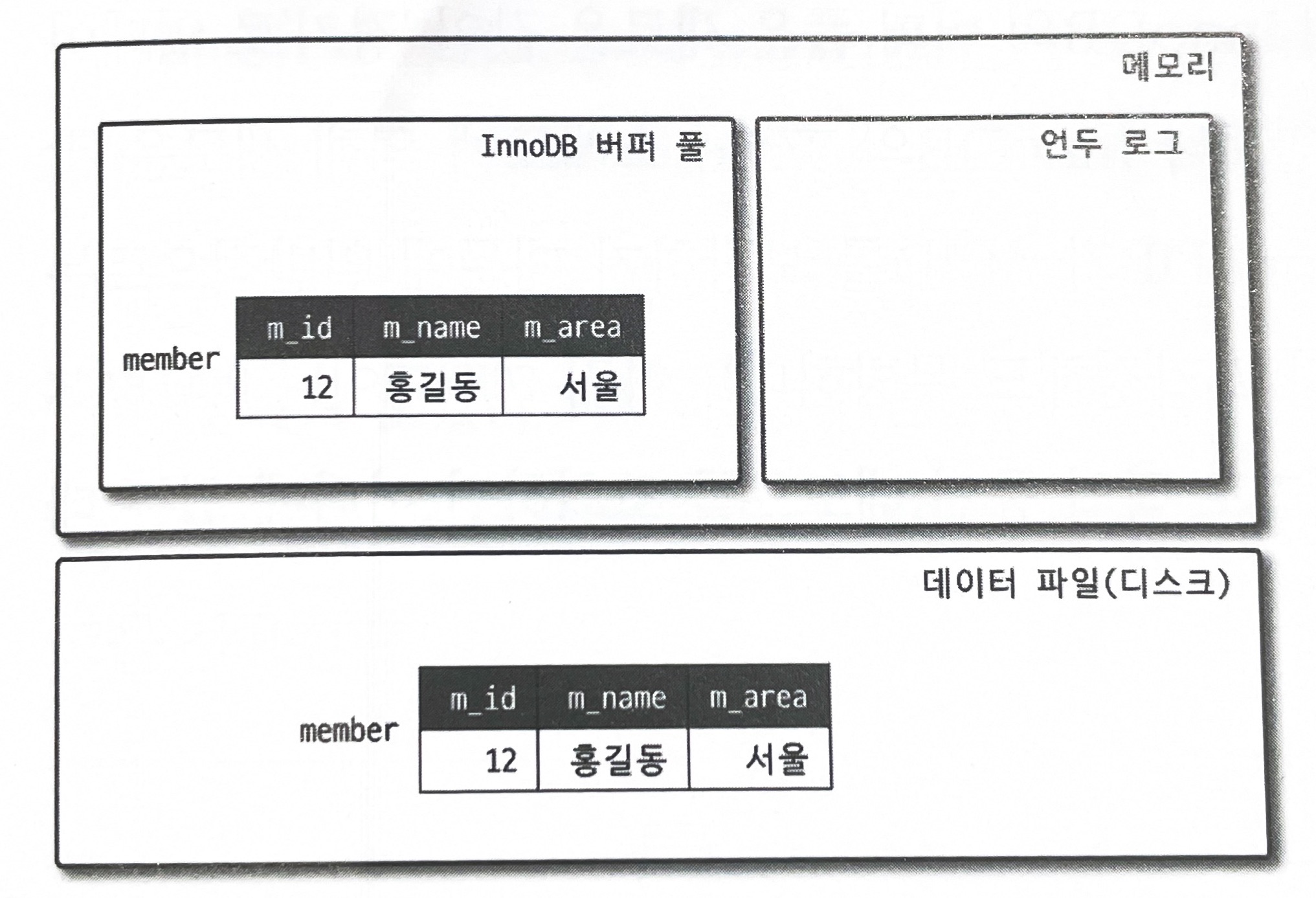
그림 4.11은 MEMBER 테이블에 UPDATE 문장이 실행될 때의 처리 절차를 그림으로 보여준다.
mysql> UPDATE member SET m_area='경기' WHERE m_id=12;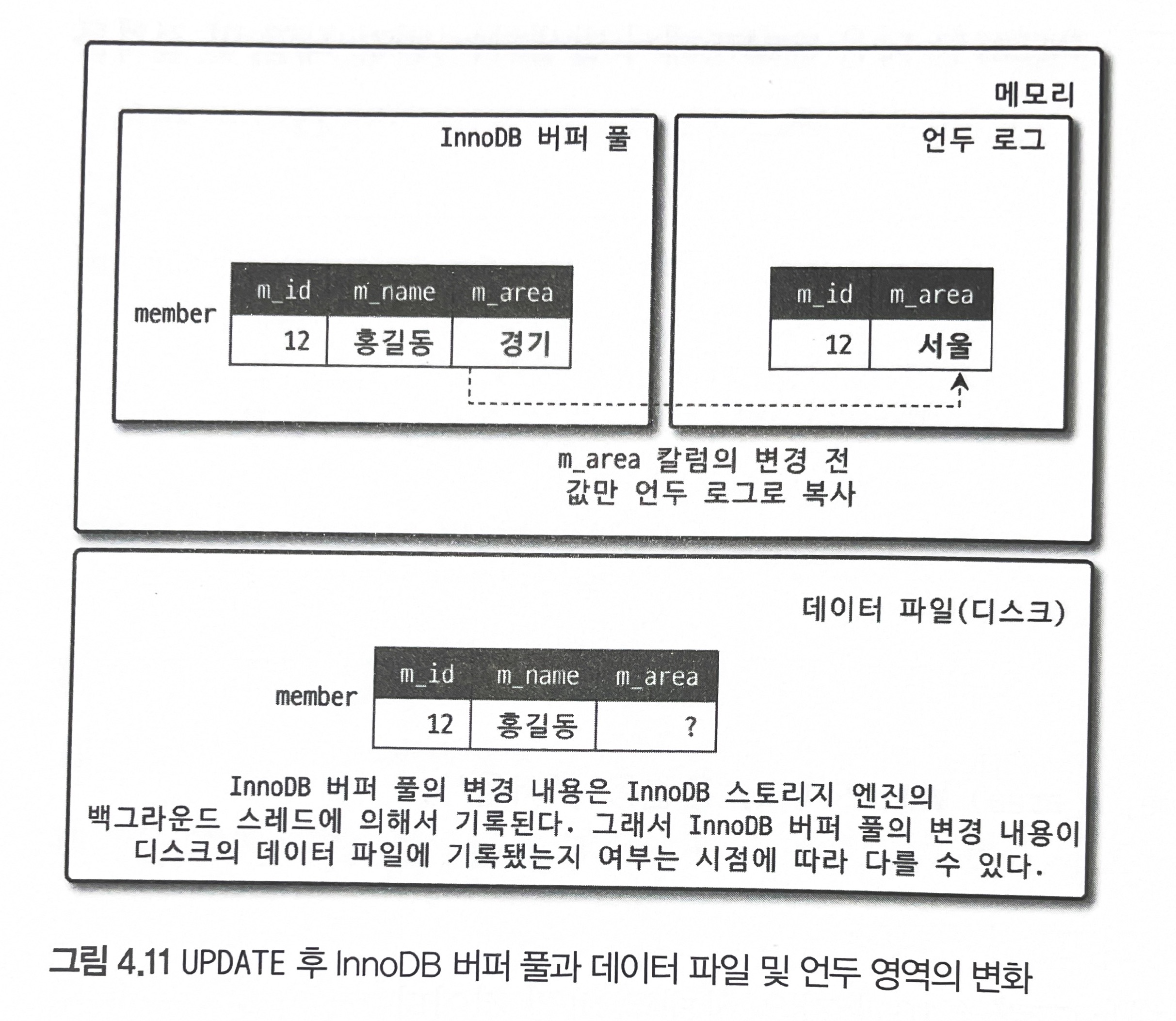
UPDATE 문장이 실행되면 커밋 실행 여부와 관계없이 InnoDB의 버퍼 풀은 새로운 값인 '경기'로 업데이트된다. 그리고 디스크의 데이터 파일에는 체크포인트나 InnoDB의 Write 스레드에 의해 새로운 값으로 업데이트돼 있을 수도 있고 아닐 수도 있다(InnoDB가 ACID를 보장하기 때문에 일반적으로 InnoDB의 버퍼 풀과 데이터 파일은 동일한 상태라고 가정해도 무방하다). 아직 COMMIT이나 ROLLBACK이 되지 않은 상태에서 다른 사용자가 다음 같은 쿼리로 작업 중인 레코드를 조회하면 어디에 있는 데이터를 조회할까?
mysql> SELECT * FROM member WHERE m_id =12;
이 질문의 답은 MySQL 서버의 시스템 변수(transaction_isolation)에 설정된 격리 수준(Isolation level)에 따라 다르다는 것이다. 격리 수준이 READ_UNCOMMITED인 경우에는 InnoDB 버퍼 풀이 현재 가지고 있는 변경된 데이터를 읽어서 반환한다. 즉, 데이터가 커밋됐든 아니든 변경된 상태의 데이터를 반환한다. 그렇지 않고 READ_COMMITED나 그 이상의 격리 수준(REPEATABLE_READ, SERIALIZABLE)인 경우에는 아직 커밋되지 않았기 때문에 InnoDB 버퍼 풀이나 데이터 파일에 있는 내용 대신 변경되기 이전의 내용을 보관하고 있는 언두 영역의 데이터를 반환한다. 이러한 과정을 DBMS에서는 MVCC라고 표현한다. 즉, 하나의 레코드(회원 번호가 12인 레코드)에 대해 2개의 버전이 유지되고, 필요에 따라 데이터가 보여지는지 여러 가지 상황에 따라 달라지는 구조다. 여기서는 한 개의 데이터만 가지고 설명했지만 관리해야 하는 예전 버전의 데이터는 무한히 많아질 수 있다(트랜잭션이 길어지면 언두에서 관리하는 예전 데이터가 삭제되지 못하고 오랫동안 관리돼야 하며, 자연히 언두 영역이 저장되는 시스템 테이블스페이스의 공간이 많이 늘어나는 상황이 발생할 수도 있다).
지금까지 UPDATE 쿼리가 실행되면 InnoDB 버퍼 풀은 즉시 새로운 데이터로 변경되고 기존 데이터는 언두영역으로 복사되는 과정까지 살펴봤는데, 이 상태에서 COMMIT 명령을 실행하면 InnoDB는 더 이상의 변경 작업 없이 지금의 상태를 영구적인 데이터로 만들어 버린다. 하지만 롤백을 실행하면 InnoDB는 언두 영역에 있는 백업된 데이터를 InnoDB 버퍼 풀로 다시 복구하고, 언두 영역의 내용을 삭제해버린다. 커밋이 된다고 언두 영역의 데이터가 항상 바로 삭제되는 것은 아니다. 이 언두 영역을 필요로 하는 트랜잭션이 더는 없을 때 비로소 삭제된다.
- 101~102p
잠금 없는 일관된 읽기
InnoDB 스토리지 엔진은 MVCC 기술을 이용해 잠금을 걸지 않고 읽기 작업을 수행한다. 잠금을 걸지 않기 때문에 InnoDB에서 읽기 작업은 다른 트랜잭션이 가지고 있는 잠금을 기다리지 않고, 읽기 작업이 가능하다. 격리 수준이 SERIALIZABLE이 아닌 READ_UNCOMMITTED나 READ_UNCOMITTED나 READ_UNCOMITTED, REPEATABLE_READ 수준인 경우 INSERT와 연결되지 않은 순수한 읽기 작업은 다른 트랜잭션의 변경 작업과 관계없이 항상 잠금을 대기하지 않고 바로 실행된다.
특정 사용자가 레코드를 변경하고 아직 커밋을 수행하지 않았다 하더라도 이 변경 트랜잭션이 다른 사용자의 SELECT 작업을 방해하지 않는다. 이를 '잠금 없는 일관된 읽기'라고 표현하며, InnoDB에서는 변경되기 전의 데이터를 읽기 위해 언두 로그를 사용한다.
- 103p
자동 데드락 감지
일반적인 서비스에서는 데드락 감지 스레드가 트랜잭션의 잠금 목록을 검사해서 데드락을 찾아내는 작업은 크게 부담되지 않는다. 하지만 동시 처리 스레드가 매우 많아지거나 각 트랜잭션이 가진 잠금의 개수가 많아지면 데드락 감지 스레드가 느려진다. 데드락 감지 스레드는 잠금 목록을 검사해야 하기 때문에 잠금 상태가 변경되지 않도록 잠금 목록이 저장된 리스트에 새로운 잠금을 걸고 데드락 스레드를 찾게 된다. 데드락 감지 스레드가 느려지면 서비스 쿼리를 처리 중인 스레드는 더는 작업을 진행하지 못하고 대기하면서 서비스에 악영향을 미치게 된다. 이렇게 동시 처리 스레드가 매우 많은 경우 데드락 감지 스레드는 더 많은 CPU 자원을 소모할 수도 있다.
- 104p
구글에서는 프라이머리 키 기반의 조회 및 변경이 아주 높은 빈도로 실행되는 서비스가 많았는데, 이런 서비스는 매우 많은 트랜잭션을 동시에 실행하기 때문에 데드락 감지 스레드가 상당히 성능을 저하시킨다는 것을 알아냈다. 그리고 MySql 서버의 소스크도를 변경해 데드락 감지 스레드를 활성화 또는 비활성화할 수 있게 변경해서 사용했다.
- 105p
InnoDB 버퍼 풀
InnoDB 스토리지 엔진에서 가장 핵심적인 부분으로, 디스크의 데이터 파일이나 인덱스 정보를 메모리에 캐시해 두는 공간이다.
- 108p
InnoDB 버퍼 풀은 내부적으로 128MB 청크 단위로 쪼개어 관리되는데, 이는 버퍼 풀의 크기를 줄이거나 늘리기 위한 단위 크기로 사용된다. 그래서 버퍼 풀의 크기를 줄이거나 늘릴 때는 128MB 단위로 처리된다.
- 109p
버퍼 풀의 페이지 크기 조각을 관리하기 위해 InnoDB 스토리지 엔진은 크게 LRU 리스트와 플러시 리스트, 그리고 프리 리스트라는 3 개의 자료 구조를 관리한다.
- 109p
LRU 리스트를 관리하는 목적은 디스크로부터 한 번 읽어온 페이지를 최대한 오랫동안 InnoDB 버퍼 풀의 메모리에 유지해서 디스크 읽기를 최소화하는 것이다. InnoDB 스토리지 엔진에서 데이터를 찾는 과정은 대략 다음과 같다.
- 필요한 레코드가 저장된 데이터 페이지가 버퍼 풀에 있는지 검사
A. InnoDB 어댑티브 해시 인덱스를 이용해 페이지를 검색
B. 해당 테이블의 인덱스(B-Tree)를 이용해 버퍼 풀에서 페이지를 검색
C. 버퍼 풀에서 이미 데이터 페이지가 있었다면 해당 페이지의 포인터를 MRU 방향으로 승급 - 디스크에서 필요한 데이터 페이지를 버퍼 풀에 적재하고, 적재된 페이지에 대한 포인터를 LRU 헤더 부분에 추가
- 버퍼 풀의 LRU 헤더 부분에 적재된 데이터 페이지가 실제로 읽히면 MRU 헤더 부분으로 이동(Read Ahead)와 같이 대량 읽기의 경우 디스크의 데이터 페이지가 버퍼 풀로 적재는 되지만 실제 쿼리에서 사용되지는 않을 수도 있으며, 이런 경우에는 MRU로 이동되지 않음
- 버퍼 풀에 상주하는 데이터 페이지는 사용자 쿼리가 얼마나 최근에 접근했었는지에 따라 나이(Age)가 부여되며, 버퍼 풀에 상주하는 동안 쿼리에서 오랫동안 사용되지 않으면 데이터 페이지에 부여된 나이가 오래되고 결국 해당 페이지는 버퍼 풀에서 제거된다. 버퍼 풀의 데이터 페이지가 쿼리에 의해 사용되면 나이가 초기화되어 다시 젊어지고 MRU의 헤더 부분으로 옮겨진다.
- 필요한 데이터가 자주 접근됐다면 해당 페이지의 인덱스 키를 어댑티브 해시 인덱스에 추가

- 110p
언두 로그
InnoDB 스토리지 엔진은 트랜잭션과 격리 수준을 보장하기 위해 DML로 변경되기 이전 버전의 데이터를 별도로 백업한다. 이렇게 백업된 데이터를 언두 로그(Undo Log)라고 한다. 언두 로그가 어떻게 사용되는지 간단히 한번 살펴보자.
트랜잭션 보장
트랜잭션이 롤백되면 트랜잭션 도중 변경된 데이터를 변경 전 데이터로 복구해야 하는데, 이때 언두 로그에 백업해 둔 이전 버전의 데이터를 이용해 복구한다.
격리 수준 보장
특정 커넥션에서 데이터를 변경하는 도중에 다른 커넥션에서 데이터를 조회하면 트랜잭션 격리 수준에 맞게 변경 중인 레코드를 읽지 않고 언두 로그에 백업해둔 데이터를 읽어서 반환하기도 한다.
- 122p
MySQL 8.0 에서는 언두 로그를 돌아가면서 순차적으로 사용해 디스크 공간을 줄이는 것도 가능하며, 때로는 MySQL 서버가 필요한 시점에 사용 공간을 자동으로 줄여 주기도 한다.
-124p
체인지 버퍼
RDBMS에서 레코드가 INSERT되거나 UPDATE될 때는 데이터 파일을 변경하는 작업뿐 아니라 해당 테이블에 포함된 인덱스를 업데이트하는 작업도 필요하다. 그런데 인덱스를 업데이트하는 작업은 랜덤하게 디스크를 읽는 작업이 필요하므로 테이블에 인덱스가 많다면 이 작업은 상당히 많은 자원을 소모하게 된다. 그래서 InnoDB는 변경해야 할 인덱스 페이지가 버퍼 풀에 있으면 바로 업데이트를 수행하지만 그렇지 않고 디스크로부터 읽어와저 업데이트해야 한다면 이를 즉시 실행하지 않고 임시 공간에 저장해 두고 바로 사용자에게 결과를 반환하는 형태로 성능을 향상시키게 되는데, 이때 사용하는 임시 메모리 공간을 쳬인지 버퍼(Change Buffer)라고 한다.
사용자에게 결과를 전달하기 전에 반드시 중복 여부를 쳬크해야 하는 유니크 인덱스는 쳬인지 버퍼를 사용할 수 없다. 쳬인지 버퍼에 임시로 저장된 인덱스 레코드 조각은 이후 백그라운드 스레드에 의해 병합되는데, 이 스레드를 쳬인지 버퍼 머지 스레드(Merge thread)라고 한다. MySQL 5.5 이전 버전 까지는 INSERT 작업에 대해서만 이러한 버퍼링이 가능(그래서 MySQL 5.5 이전 버전까지는 이 버퍼를 인서트 버퍼라고 함)했는데, MySQL 5.5부터 조금찍 개선되면서 MySQL 8.0에서는 INSERT, DELETE, UPDATE로 인해 키를 추가하거나 삭제하는 작업에 대해서도 버퍼링이 될 수 있게 개선됐다.
- 129p
리두 로그
리두 로그는 트랜잭션의 4가지 요소인 ACID 중에서 D(Durable)에 해당하는 영속성과 가장 밀접하게 연관돼 있다. 리두 로그는 하드웨어나 소프트웨어 등 여러 가지 문제점으로 인해 MySQL 서버가 비정상적으로 종료됐을 때 데이터 파일에 기록되지 못한 데이터를 잃지 않게 해주는 안전장치다.
MySQL 서버를 포함한 대부분 데이터베이스 서버는 데이터 변경 내용을 로그로 먼저 기록한다. 거의 모든 DBMS에서 데이터 파일은 쓰기보다 읽기 성능을 고려한 자료 구조를 가지고 있기 때문에 데이터 파일 쓰기는 디스크의 랜덤 액세스가 필요하다. 그래서 변경된 데이터를 데이터 파일에 기록하려면 상대적으로 큰 비용이 필요하다. 이로 인한 성능 저하를 막기 위해 데이터베이스 서버는 쓰기 비용이 낮은 자료 구조를 가진 리두 로그를 가지고 있으며, 비정상 종료가 발생하면 리두 로그의 내용을 이용해 데이터 파일을 다시 서버가 종료되기 직전의 상태로 복구한다. 데이터베이스 서버는 ACID도 중요하지만 성능도 중요하기 때문에 데이터 파일 뿐만 아니라 리두 로그를 버퍼링할 수 있는 InnoDB 버퍼 풀이나 리두 로그를 버퍼링할 수 있는 로그 버퍼와 같은 자료 구조도 가지고 있다.
MySQL 서버가 비정상 종료되는 경우 InnoDB 스토리지 엔진의 데이터 파일은 다음과 같은 두 가지 종류의 일관되지 않은 데이터를 가질 수 있다.
- 커밋됐지만 데이터 파일에 기록되지 않은 데이터
- 롤백됐지만 데이터 파일에 이미 기록된 데이터
1번의 경우 리두 로그에 저장된 데이터를 데이터 파일에 다시 복사하기만 하면 된다. 하지만 2번의 경우에는 리두 로그로는 해결할 수 없는데, 이때는 변경되기 전 데이터를 가진 언두 로그의 내용을 가져와 데이터 파일에 복사하면 된다. 그렇다고 해서 2번의 경우 리두 로그가 전혀 필요하지 않은 것은 아니다. 최소한 그 변경이 커밋됐는지, 롤백됐는지, 아니면 트랜잭션의 실행 중간 상태였는지를 확인하기 위해서라도 리두 로그가 필요하다.
데이터베이스 서버에서 리두 로그는 트랜잭션이 커밋되면 즉시 디스크로 기록되도록 시스템 변수를 설정하는 것을 권장한다. 그리고 당연히 그렇게 돼야만 서버가 비정상적으로 종료됐을 때 직전까지의 트랜잭션 커밋 내용이 리두 로그에 기록될 수 있고, 그 리두 로그를 이용해 장애 직전 시점까지의 복구가 가능해진다. 하지만 이처럼 트랜잭션이 커밋될 때마다 리두 로그를 디스크에 기록하는 작업은 많은 부하를 유발한다. 그래서 InnoDB 스토리지 엔진에서 리두 로그를 어느 주기로 디스크에 동기화할지를 결정하는 innodb_flush_log_at_trx_commit 시스템 변수를 제공한다. innodb_flush_log_at_trx_commit 시스템 변수는 다음과 같은 값을 가질 수 있다.
- 0: 1초에 한 번씩 리두 로그를 디스크로 기록하고 동기화를 실행한다. 그래서 서버가 비정상 종료되면 최대 1초 동안의 트랜잭션은 커밋됐다고 하더라도 해당 트랜잭션에서 변경한 데이터는 사라질 수 있다.
- 1: 매번 트랜잭션이 커밋될 때마다 디스크로 기록되고 동기화까지 수행된다. 그래서 트랜잭션이 일단 커밋되면 해당 트랜잭션에서 변경한 데이터는 사라진다.
- 2: 매번 트랜잭션이 커밋될 때마다 디스크로 기록은 되지만 실질적인 동기화는 1초에 한 번씩 실행된다. 일단 트랜잭션이 커밋되면 변경 내용이 운영체제의 메모리 버퍼에 기록되는 것이 보장ㄹ된다. 그래서 MySQL 서버가 비정상 종료됐더라도 운영체제가 정상적으로 작동한다면 해당 트랜잭션의 데이터는 사라지지 않는다. MySQL 서버와 운영체제 모두가 비정상적으로 종료되면 최근 1초 동안의 트랜잭션 데이터는 사라질 수도 있다.
- 130~132p
어댑티브 해시 인덱스
일반적으로 '인덱스'라고 하면 이는 테이블에 사용자가 생성해둔 B-Tree 인덱스를 의미한다. 인덱스가 사용하는 알고리즘이 B-Tree는 아니더라도, 사용자가 직접 테이블에 생성해둔 인덱스가 우리가 일반적으로 알고 있는 인덱스일 것이다. 하지만 여기서 언급하는 '어댑티브 해시 인덱스(Adaptive Hash Index)'는 사용자가 수동으로 생성하는 인덱스가 아니라 innoDB 스토리지 엔진에서 사용자가 자주 요청하는 데이터에 대해 자동으로 생성하는 인덱스이며, 사용자는 innodb_adaptive_hash_index 시스템 변수를 이용해서 어댑티브 해시 인덱스 기능을 활성화하거나 비활성화할 수 있다.
B-Tree 인덱스에서 특정 값을 찾는 과정은 매우 빠르게 처리된다고 많은 사람이 생각한다. 하지만 결국 빠르냐 느리냐의 기준은 상대적인 것이며, 데이터베이스 서버가 얼마나 많은 일을 하느냐에 따라 B-Tree 인덱스에서 값을 찾는 과정이 느려질 수도 있고 빨라질 수도 있다. B-Tree 인덱스에서 특정 값을 찾기 위해서는 B-Tree의 루트 노드를 거쳐서 브랜치 노드, 그리고 최종적으로 리프 노드까지 찾아가야 원하는 레코드를 읽을 수 있다. 적당한 사양의 컴퓨터에서 이런 작업을 동시에 몇천 개의 스레드로 실행하면 컴퓨터의 CPU는 엄청난 스케줄링을 하게 되고 자연히 쿼리의 성능은 떨어진다.
어댑티브 해시 인덱스는 이러한 B-Tree 검색 시간을 줄여주기 위해 도입된 기능이다. InnoDb 스토리지 엔진은 자주 읽히는 데이터 페이지의 키 값을 이용해 해시 인덱스를 만들고, 필요할 때마다 어댑티브 해시 인덱스를 검색해서 레코드가 저장된 데이터 페이지를 즉시 찾아갈 수 있다. B-Tree를 루트 노드부터 리프 노드까지 찾아가는 비용이 없어지고 그만큼 CPU는 적은 일을 하지만 쿼리의 성능은 빨라진다. 그와 동시에 컴퓨터는 더 많은 쿼리를 동시에 처리할 수 있게 된다.
해시 인덱스는 '인덱스 키 값'과 해당 인덱스 키 값이 저장된 '데이터 페이지 주소'의 쌍으로 관리되는데, 인덱스 키 값은 'B-Tree 인덱스의 고유번호(Id)와 B-Tree 인덱스의 실제 키 값' 조합으로 생성된다. 어댑티브 해시 인덱스의 키 값에 'B-Tree 인덱스의 고유번호'가 포함되는 이유는 InnoDB 스토리지 엔진에서 어댑티브 해시 인덱스는 하나만 존재하기 때문이다. 즉, 모든 B-Tree 인덱스에 대한 어댑티브 해시 인덱스가 하나의 해시 인덱스에 저장되며, 특정 키 값이 어느 인덱스에 속한 것인지도 구분해야 하기 때문이다. 그리고 '데이터 페이지 주소'는 실제 키 값이 저장된 데이터 페이지의 메모리 주소를 가지는데, 이는 InnoDB 버퍼 풀에 로딩된 페이지의 주소를 의미한다. 그래서 어댑티브 해시 인덱스는 버퍼 풀에 올려진 데이터 페이지에 대해서만 관리되고, 버퍼 풀에서 해당 데이터 페이지가 없어지면 어댑티브 해시 인덱스에서도 해당 페이지의 정보는 사라진다.
- 137~138p
어댑티브 해시 인덱스를 활성화한 후 쿼리의 처리량은 2배 가까이 늘어났음에도 불구하고 CPU 사용률은 오히려 떨어진 것을 볼 수 있다. 물론 B-Tree의 루트 노드부터 검색이 많이 줄면서 InnoDB 내부 잠금(세마포어)의 횟수도 획기적으로 줄어든다.
- 138p
어댑티브 해시 인덱스가 성능 향상에 크게 도움이 되지 않는 경우는 다음과 같다.
- 디스크 읽기가 많은 경우
- 특정 패턴의 쿼리가 많은 경우(조인이나 like 패턴 검색)
- 매우 큰 데이터를 가진 테이블의 레코드를 폭넓게 읽는 경우
그리고 다음과 같은 경우에는 성능 향상에 많은 도움이 된다.
- 디스크의 데이터가 InnoDB 버퍼 풀 크기와 비슷한 경우 (디스크 읽기가 많지 않은 경우)
- 동등 조건 검색(동등 비교와 In 연산자)이 많은 경우
- 쿼리가 데이터 중에서 일부 데이터에만 집중되는 경우
- - 139p
한 가지 확실한 것은 어댑티브 해시 인덱스는 데이터 페이지를 메모리 (버퍼 풀) 내에서 접근하는 것을 더 빠르게 만드는 기능이기 때문에 데이터 페이지를 디스크에서 읽어오는 경우가 빈번한 데이터베이스 서버에서는 아무런 도움이 되지 않는다는 점이다.
- 139p
트랜잭션과 잠금
잠금은 동시성을 제어하기 위한 기능이고 트랜잭션은 데이터의 정합성을 보장하기 위한 기능이다.
- 155p
트랜잭션
트랜잭션은 하나의 논리적인 작업 셋에 하나의 쿼리가 있든 두 개 이상의 쿼리가 있든 관계없이 논리적인 작업 셋 자체가 100% 적용되거나 아무것도 적용되지 않아야 함을 보장해주는 것이다.
- 155p
MySQL 엔진의 잠금
MySQL에서 사용되는 잠금은 크게 스토리지 엔진 레벨과 MySQL 엔진 레벨로 나눌 수 있다. MySQL 엔진은 MySQL 서버에서 스토리지 엔진을 제외한 나머지 부분으로 이해하면 되는데, MySQL 엔진 레벨의 잠금은 모든 스토리지 엔진에 영향을 미치지만, 스토리지 엔진 레벨의 잠금은 스토리지 엔진 간 상호 영향을 미치지는 않는다. MySQL 엔진에서는 테이블 데이터 동기화를 위한 테이블 락 이외에도 테이블의 구조를 잠그는 메타데이터 락 그리고 사용자의 필요에 맞게 사용할 수 있는 네임드 락이라는 잠금 기능도 제공한다.
- 160p
글로벌 락
글로벌 락(GLOBAL LOCK)은 FLUSH TABLES WITH READ LOCK 명령으로 획득할 수 있으며, MySQL에서 제공하는 잠금 가운데 가장 범위가 크다. 일단 한 세션에서 글로벌 락을 획득하면 다른 세션에서 SELECT를 제외한 대부분의 DDL 문장이나 DML 문장을 실행하는 경우 글로벌 락이 해제될 때까지 해당 문장이 대기 상태로 남는다. 글로벌 락이 영향을 미치는 범위는 MySQL 서버 전체이며, 작업 대상 테이블이나 데이터베이스가 다르더라도 동일하게 영향을 미친다.
- 161p
테이블 락
테이블 락(Table Lock)은 개별 테이블 단위로 설정되는 잠금이며, 명시적 또는 묵시적으로 특정 테이블의 락을 획득할 수 있다. 명시적으로는 "LOCK TABLES table_name [READ | WRITE]" 명령으로 특정 테이블의 락을 획득할 수 있다. 테이블 락은 MyISAM 뿐만 아니라 InnoDB 스토리지 엔진을 사용하는 테이블도 동일하게 설정할 수 있다. 명시적으로 획득한 잠근은 UNLOCK TABLES 명령으로 잠금을 반납할 수 있다. 명시적인 테이블 락도 특별한 상황이 아니면 애플리케이션에서 사용할 필요가 거의 없다. 명시적으로 테이블을 잠그는 작업은 글로벌 락과 동일학레 온라인 작업에 상당한 영향을 미치기 때문이다.
InnoDB 테이블의 경우 스토리지 엔진 차원에서 레코드 기반의 잠금을 제공하기 때무넹 단순 데이터 변경 쿼리로 인해 묵시적인 테이블 락이 설정되지는 않는다. 더 정확히는 InnoDB 테이블에도 테이블 락이 설정되지만 대부분의 데이터 변경(DML) 쿼리에서는 무시되고 스키마를 변경하는 쿼리(DDL)의 경우에만 영향을 미친다.
- 162~163p
네임드 락
네임드락(Named Lock)은 GET_LOCK() 함수를 이용해 임의의 문자열에 대해 잠금을 설정할 수 있다. 이 잠금의 특징은 대상이 테이블이나 레코드 또는 AUTO_INCREMENT와 같은 데이터베이스 객체가 아니라는 것이다. 네임드 락은 단순히 사용자가 지정한 문자열에 대해 획득하고 반납(해제)하는 잠금이다. 네임드 락은 자주 사용되지는 않는다. 예를 들어, 데이터베이스 서버 1대에 5대의 웹 서버가 접속해서 서비스하는 상황에서 5대의 웹 서버가 어떤 정보를 동기화해야 하는 요건처럼 여러 클라이언트가 상호 동기화를 처리해야 할 때 네임드 락을 이용하면 쉽게 해결할 수 있다.
- 163p
네임드 락의 경우 많은 레코드에 대해서 복잡한 요건으로 레코드를 변경하는 트랜잭션에 유용하게 사용할 수 있다. 배치 프로그램처럼 한꺼번에 레코드를 변경하는 쿼리는 자주 데드락의 원인이 되곤 한다. 각 프로그램의 실행 시간을 분산하거나 프로그램의 코드를 수정해서 데드락을 최소화할 수는 있지만, 이는 간단한 방법이 아니며 완전한 해결책이 될 수도 없다. 이러한 경우에 동일 데이털르 변경하거나 참조하는 프로그램끼리 분류해서 네임드락을 걸고 쿼리를 실행하면 아주 간단히 해결할 수 있다.
- 163p
메타데이터 락
메타데이터 락은 데이터베이스 객체의 이름이나 구조를 변경하는 경우에 획득하는 잠금이다. 메타데이터 락은 명시적으로 획득하거나 해제할 수 있는 것이 아니고 "RENAME TABLE tab_a to tab_b" 같이 테이블의 이름을 변경하는 경우 자동으로 획득하는 잠금이다.
- 164p
InnoDB 스토리지 엔진 잠금
최근 버전에서는 InnoDB의 트랜잭션과 잠금, 그리고 잠금 대기 중인 트랜잭션의 목록을 조회할 수 있는 방법이 도입됐다. MySQL 서버의 information_schema 데이터베이스에 존재하는 INNODB_TRX, INNODB_LOCKS, INNODB_LOCK_WAITS라는 테이블을 조인해서 조회하면 현재 어떤 트랜잭션이 어떤 잠금을 대기하고 있고 해당 잠금을 어느 트랜잭션이 가지고 있는지 확인할 수 있으며, 또한 장시간 잠금을 가지고 있는 클라이언트를 찾아서 종료시킬 수도 있다.
- 167p
InnoDB 스토리지 엔진은 레코드 기반의 잠금 기능을 제공하며, 잠금 정보가 상당히 작은 공간으로 관리되기 때문에 레코드 락이 페이지 락으로, 또는 테이블 락으로 레벨업되는 경우(락 에스컬레이션)는 없다. 일반 상용 DBMS와는 조금 다르게 InnoDB 스토리지 엔진에서는 레코드 락뿐 아니라 레코드와 레코드 사이의 간격을 잠그는 갭(GAP)락 이라는 것이 존재하는데, 그림은 InnoDB 스토리지 엔진의 레코드 락과 레코드 간의 간격을 잠그는 갭락을 보여준다.

- 167p
레코드 락
레코드 자체만을 잠그는 것을 레코드락이라고 하며 다른 상용 DBMS의 레코드 락과 동일한 역할을 한다. 한 가지 중요한 차이는 InnoDB 스토리지 엔진은 레코드 자체가 아니라 인덱스의 레코드를 잠근다는 점이다. 인덱스가 하나도 없는 테이블이더라도 내부적으로 자동 생성된 클러스터 인덱스를 이용해 잠금을 설정한다. 많은 사용자가 간과하는 부분이지만 레코드 자체를 잠그느냐, 아니면 인덱스를 잠그느냐는 상당히 크고 중요한 차이를 만들어 낸다.
- 168p
갭 락
다른 DBMS와의 또 다른 차이가 바로 갭 락이다. 갭 락은 레코드 자체가 아니라 레코드와 바로 인접한 레코드 사이의 간격만을 잠그는 것을 의미한다. 갭 락의 역할은 레코드와 레코드 사이의 간격에 새로운 레코드가 생성(insert)되는 것을 제어하는 것이다. 갭 락은 그 자체보다는 이어서 설명할 넥스트 키 락의 일부로 자주 사용된다.
넥스트 키 락
레코드 락과 갭 락을 합쳐 놓은 형태의 잠금을 넥스트 키 락이라고 한다. STATEMENT 포맷의 바이너리 로그를 사용하는 MySQL 서버에서는 REPEATABLE READ 격리 수준을 사용해야 한다. 또한 innodb_locks_unsafe_for_binlog 시스템 변수가 비활성화되면(0으로 설정되면) 변경을 위해 검색하는 레코드에는 넥스트 키 락 방식으로 잠금이 걸린다. InnoDB의 갭 락이나 넥스트 키 락은 바이너리 로그에 기록되는 쿼리가 레플리카 서버에서 실행될 때 소스 서버에서 만들어낸 결과와 동일한 결과를 만들어내도록 보장하는 것이 주목적이다. 그런데 의외로 넥스트 키 락과 갭 락으로 인해 데드락이 발생하거나 다른 트랜잭션을 기다리게 만드는 일이 자주 발생한다. 가능하다면 바이너리 로그 포맷을 ROW 형태로 바꿔서 넥스트 키 락이나 갭 락을 줄이는 것이 좋다.
자동 증가 락
MySQL 에서는 자동 증가하는 숫자 값을 추출(채번)하기 위해 AUTO_INCREMENT라는 칼럼 속성을 제공한다. AUTO_INCREMENT 칼럼이 사용된 테이블에 동시에 여러 레코드가 INSERT 되는 경우, 저장되는 각 레코드는 중복되지 않고 저장된 순서대로 증가하는 일련번호 값을 가져야 한다. InnoDB 스토리지 엔진에서는 이를 위해 내부적으로 AUTO_INCREMENT 락(Auto increment lock)이라고 하는 테이블 수준의 잠금을 사용한다.
AUTO_INCREMENT 락은 INSERT와 REPLACE 쿼리 문장과 같은 새로운 레코드를 저장하는 쿼리에서만 필요하며, UPDATE나 DELETE 등의 쿼리에서는 걸리지 않는다. InnoDB의 다른 잠금과는 달리 AUTO_INCREMENT 락은 트랜잭션과 관계없이 INSERT나 REPLACE 문장에서 AUTO_INCREMENT 값을 가져오는 순간만 락이 걸렸다가 즉시 해제된다. AUTO_INCREMENT 락은 테이블에 단 하나만 존재하기 때무넹 두 개의 INSERT 쿼리가 동시에 실행되는 경우 하나의 쿼리가 AUTO_INCREMENT 락을 걸면 나머지 쿼리는 AUTO_INCREMENT 락을 기다려야 한다.
인덱스와 잠금
InnoDB의 잠금은 레코드를 잠그는 것이 아니라 인덱스를 잠그는 방식으로 처리된다. 즉, 변경해야 할 레코드를 찾기 위해 검색한 인덱스의 레코드를 모두 락을 걸어야 한다.
mysql> UPDATE employes SET hire_date=NOW() WHERE first_name='Georgi' AND last_name ='Klassen';
UPDATE 문장이 실행되면 1건의 레코드가 업데이트 될 것이다. 하지만 이 1건의 업데이트를 위해 몇 개의 레코드에 락을 걸어야 할까? 이 UPDATE 문장의 조건에서 인덱스를 이용할 수 있는 조건은 first_name'Georgi'이며 last_name 칼럼은 인덱스에 없기 때문에 first_name='Georgi'인 레코드 253건의 레코드가 모두 잠긴다.
- 171p
MySQL의 격리 수준
READ UNCOMMITTED
READ UNCOMMITTED 격리 수준에서는 그림 5.3과 같이 각 트랜잭션에서의 변경 내용이 COMMIT이나 ROLLBACK 여부에 상관없이 다른 트랜잭션에서 보인다.
- 177p
READ COMMITTED
READ COMMITTED는 오라클 DBMS에서 기본으로 사용되는 격리 수준이며, 온라인 서비스에서 가장 많이 선택되는 격리 수준이다. 이 레벨에서는 위에서 언급한 더티 리드 같은 현상은 발생하지 않는다. 어떤 트랜잭션에서 데이터를 변경했더라도 COMMIT이 완료된 데이터만 다른 트랜잭션에서 조회할 수 있기 때문이다.
- 178p
READ COMMITTED 격리 수준에서도 "NON-REPEATABLE READ"라는 부정합의 문제가 있다. 그림 5.5는 "NON-REPEPEATABLE READ"가 왜 발생하고 어떤 문제를 만들어낼 수 있는지 보여준다.

그림 5.5에서 처음 사용자 B가 BEGIN 명령으로 트랜잭션을 시작하고 first_name이 "Toto"인 사용자를 검색했는데, 일치하는 결과가 없었다. 하지만 사용자 A가 사원 번호가 500000인 사원의 이름을 "Toto"로 변경하고 커밋을 실행한 후, 사용자 B가 똑같은 SELECT 쿼리로 다시 조회하면 이번에는 결과가 1건 조회된다. 이는 별다른 문제가 없어 보이지만, 사실 사용자 B가 하나의 트랜잭션 내에서 똑같은 SELECT 쿼리를 실행했을 때는 항상 같은 결과를 가져와야 한다는 "REPEATABLE READ" 정합성에 어긋나는 것이다.
- 179p
이러한 부정합 현상은 일반적인 웹 프로그램에서는 크게 문제되지 않을 수 있지만 하나의 트랜잭션에서 동일 데이터를 여러 번 읽고 변경하는 작업이 금전적인 처리와 연결되면 문제가 될 수도 있다. 예를 들어, 다른 트랜잭션에서 입금과 출금 처리가 계속 진행될 때 다른 트랜잭션에서 온르 입금된 금액의 총합을 조회한다고 가정해보자. 그런데 "REPEATBALE READ"가 보장되지 않기 때문에 총합을 계산하는 SELECT 쿼리는 실행될 때마다 다른 결과를 가져올 것이다. 중요한 것은 사용 중인 트랜잭션의 격리 수준에 의해 실행하는 SQL 문장이 어떤 결과를 가져오게 되는지를 정확히 예측할 수 있어야 한다는 것이다.
- 180p
REPEATABLE READ
REPEATABLE READ는 MySQL의 InnoDB 스토리지 엔진에서 기본으로 사용되는 격리 수준이다. 바이너리 로그를 가진 MySQL 서버에서는 최소 REPEATABLE READ 격리 수준 이상을 사용해야 한다. 이 격리 수준에서는 READ COMMITTED 격리 수준에서 발생하는 "NON_REPEATABLE READ" 부정합이 발생하지 않는다. InnoDB 스토리지 엔진은 트랜잭션이 ROLLBACK 될 가능성에 대비해 변경되기 전 레코드를 언두(Undo) 공간에 백업해두고 실제 레코드 값을 변경한다.

사용자 A의 트랜잭션 번호는 12였으며 사용자 B의 트랜잭션 번호는 10이었다. 이때 사용자 A는 사원의 이름을 "Toto"로 변경하고 커밋을 수행했다. 그런데 A 트랜잭션이 변경을 수행하고 커밋을 했지만, 사용자 B가 emp_no=500000인 사원을 A 트랜잭션의 변경 전후 각각 한 번씩 SELECT했는데 결과는 항상 "Lara"라는 값을 가져온다. 사용자 B가 Begin 명령으로 트랜잭션을 시작하면서 10번이라는 트랜잭션 번호를 부여받았는데, 그때부터 사용자 B의 10번 트랜잭션 안에서 실행되는 모든 SELECT 쿼리는 트랜잭션 번호가 10(자신의 트랜잭션 번호)보다작은 트랜잭션 번호에서 변경한 것만 보게 된다.
- 181~182p
REPEATABLE READ 격리 수준에서도 다음과 같은 부정합이 발생할 수 있다. 그림 5.7에서는 사용자 A가 employess 테이블에 INSERT를 실행하는 도중에 사용자 B가 SELECT ... FOR UPDATE 쿼리로 employees 테이블을 조회했을 때 어떤 결과를 가져오는지 보여준다.

사용자 B는 BEGIN 명령으로 트랜잭션을 시작한 후 SELECT를 수행한다. 그러므로 그림 5.6의 REPEATABLE READ에서 배운 것처럼 두 번의 쿼리 결과는 똑같아야 한다. 하지만 그림 5.7에서 사용자 B가 실행하는 두 번의 SELECT ... FOR UPDATE 쿼리 결과는 서로 다르다. 이렇게 다른 트랜잭션에서 수행한 변경 작업에 의해 레코드가 보였다 안 보였다 하는 현상을 PHANTOM READ라고 한다. SELECT ... FOR UPDATE 쿼리는 SELECT 하는 레코드에 쓰기 잠금을 걸어야 하는데, 언두 레코드에는 잠금을 걸 수 업다. 그래서 SELECT ... FOR UPDATE 나 SELECT ... LOCK IN SHARE MODE로 조회되는 레코드는 언두 영역의 변경 전 데이터를 가져오는 것이 아니라 현재 레코드의 값을 가져오게 되는 것이다.
- 182~183p
SERIALIZABLE
트랜잭션의 격리 수준이 SERIALIZABLE로 설정되면 읽기 작업도 공유 잠금(읽기 잠금)을 획득해야만 하며, 동시에 다른 트랜잭션은 그러한 레코드를 변경하지 못하게 된다. 즉, 한 트랜잭션에서 읽고 쓰는 레코드를 다른 트랜잭션에서는 절대 접근할 수 없는 것이다.
- 183p
MySQL 서버의 데이터 암호화
MySQL 서버의 암호화 기능은 그림 7.1에서와 같이 데이터베이스 서버와 디스크 사이의 데이터 읽고 쓰기 지점에서 암호화 또는 복호화를 수행한다. 그래서 MySQL 서버에서 디스크 입출력 이외의 부분에서는 암호화 처리가 전혀 필요치 않다. 즉, MySQL 서버(InnoDB 스토리지 엔진)의 I/O 레이어에서만 데이터의 암호화 및 복호화 과정이 실행되는 것이다.

MySQL 서버에서 사용자의 쿼리를 처리하는 과정에서 테이블의 데이터가 암호화돼 있는지 여부를 식별할 필요가 없으며, 암호화된 테이블도 그렇지 않은 테이블과 동일한 처리 과정을 거친다. 데이터 암호화 기능이 활성화돼 있다고 하더라도 MySQL 내부와 사용자 입장에서는 아무런 차이가 없기 때문에 이러한 암호화 방식을 가리쳐 TDE(Transparent Data Encryption)이라고 한다.
- 196p
암호화와 성능
MySQL 서버의 암호화는 TDE 방식이기 때문에 디스크로부터 한 번 읽은 데이터 페이지는 복호화되어 InnoDB 버퍼 풀에 적재된다. 그래서 데이터 페이지가 한 번 메모리에 적재되면 암호화되지 않은 테이블과 동일한 성능을 보인다. 하지만 쿼리가 InnoDB 버퍼 풀에 존재하지 않는 데이터 페이지를 읽어야 하는 경우에는 복호화 과정을 거치기 때문에 복호화 시간 동안 쿼리 처리가 지연될 것이다. 그리고 암호화된 테이블이 변경되면 다시 디스크로 동기화될 때 암호화돼야 하기 때문에 디스크에 저장할 때도 추가로 시간이 더 걸린다. 하지만 데이터 페이지 저장은 사용자의 쿼리를 처리하는 스레다가 아닌 MySQL 서버의 백그라운드 스레드가 수행하기 때문에 실제 사용자 쿼리가 지연되는 것은 아니다. SELECT 뿐만 아니라 UPDATE, DELETE 명령 또한 변경하고자 하는 레코드를 InnoDB 버퍼 풀로 읽어와야 하기 때문에 새롭게 디스크에서 읽어야 하는 데이터 페이지의 개수에 따라서 그만큼의 복호화 지연이 발생한다.
- 198~199p
어느 정도 오차는 있겠지만 암호화된 테이블의 경우 읽기는 3~5배 정도 느리며, 쓰기의 경우에는 5~6배 정도 느린 것을 확인할 수 있다.
- 199p
랜덤 I/O와 순차 I/O
랜덤 I/O라는 표현은 하드 디스크 드라이브의 플래터(원판)를 돌려서 읽어야 할 데이터가 저장된 위치로 디스크 헤더를 이동시킨 다음 데이터를 읽는 것을 의미하는데, 사실 순차 I/O 또한 이 작업 과정은 같다. 그렇다면 랜덤 I/O와 순차 I/O는 어ㄸ너 차이가 있을까?

- 216p
순차 I/O는 3개의 페이지(3x16KB)를 디스크에 기록하기 위해 1 번 시스템 콜을 요청했지만, 랜덤 I/O는 3개의 페이지를 디스크에 기록하기 위해 3번 시스템 콜을 요청했다. 즉 디스크에 기록해야 할 위치를 찾기 위해 순차 I/O는 디스크의 헤더를 1번 움직였고, 랜덤 I/O는 디스크 헤드를 3번 움직였다. 디스크에 데이터를 쓰고 읽는 데 걸리는 시간은 디스크 헤더를 움직여서 읽고 쓸 위치로 옮기는 단계에서 결정된다. 결국 그림 8.3의 경우 순차 I/O는 랜덤 I/O보다 거의 3배 정도 빠르다고 볼 수 있다. 즉, 디스크의 성능은 디스크 헤더의 위치 이동 없이 얼마나 많은 데이터를 한 번에 기록하느냐에 의해 결정된다고 볼 수 있다. 그래서 여러 번 쓰기 또는 읽기를 요청하는 랜덤 I/O 작업이 작업 부하가 훨씬 더 크다. 데이터베이스 대부분의 작업은 이러한 작은 데이터를 빈번히 읽고 쓰기 때문에 MySQL 서버에서는 그룹 커밋이나 바이너리 로그 버퍼 또는 InnoDB 로그 버퍼 등의 기능이 내장돼 있다.
- 217p
일반적으로 쿼리를 튜닝하는 것은 랜덤 I/O 자체를 줄여주는 것이 목적이라고 할 수 있다. 여기서 랜던 I/O를 줄인다는 것은 쿼리를 처리하는 데 꼭 필요한 데이터만 읽도록 쿼리를 개선하는 것을 의미한다.
- 217p
참고> 인덱스 레인지 스캔은 데이터를 읽기 위해 주로 랜덤 I/O를 사용하며, 풀 테이블 스캔은 순차 I/O를 사용한다. 그래서 큰 테이블의 레코드 대부분을 읽는 작업에서는 인덱스를 사용하지 않고 풀 테이블 스캔을 사용하도록 유도할 때도 있다. 이는 순차 I/O가 랜덤 I/O보다 훨씬 빨리 많은 레코드를 읽어올 수 있기 때문인데, 이런 형태는 OLTP 성격의 웹 서비스보다는 데이터 웨어하우스나 통계 작업에서 자주 사용된다.
- 217p
인덱스란?
프로그래밍 언어의 자료 구조로 인덱스와 데이터 파일을 비교해 가면서 살펴보자. 프로그래밍 언어별로 각 자료 구조의 이름이 조금씩 다르긴 하지만 SortedList와 ArrayList라는 자료 구조는 익숙할 정도로 많이 들어봤을 것이다. SortedList는 DBMS 의 인덱스와 같은 자료 구조이며, ArrayList는 데이터 파일과 같은 자료 구조를 사용한다. SortedLjst 는 저장되는 값을 항상 정렬된 상태로 유지하는 자료 구조이며, ArrayList는 값을 지장되는 순서 그대 로 유지하는 자료 구조다. DBMS의 인덱스도 SortedList와 마찬가지로 저장되는 칼럼의 값을 이용해 항상 정렬된 상태를 유지한다. 데이터 파일은 ArrayList와 같이 저장된 순서대로 별도의 정렬 없이 그대로 저장해 둔다.
그러면 이제 SortedList의 장단점을 통해 인덱스의 장단점을 살펴보자. SortedList 자료 구조는 데이 터가 저장될 때마다 항상 값을 정렬해야 하므로 저장하는 과정이 복잡하고 느리지만, 이미 정렬돼 있어 서 아주 빨리 원하는 값을 찾아올 수 있다. DBMS의 인덱스도 인덱스가 많은 테이블은 당연히 INSERT 나 UPDATE, DELETE 문장의 처리가 느려진다. 하지만 이미 정렬된 "찾아보기"용 표(인덱스)를 가지고 있 기 때문에 SELECT 문장은 매우 빠르게 처리할 수 있다.
결론적으로 DBMS에서 인덱스는 데이터의 저장(INSERT, UPDATE, DELETE) 성능을 희생하고 그 대신 데이터의 읽기 속도를 높이는 기능이다. 여기서도 알 수 있듯이 테이블의 인덱스를 하나 더 추가할지 말지는 데이터의 저장 속도를 어디까지 희생할 수 있는지, 읽기 속도를 얼마나 더 빠르게 만들어야 하느냐에 따라 결정해야 한다. SELECT 쿼리 문장의 WHERE 조건절에 사용되는 칼럼이라고 해서 전부 인덱스로 생성하면 데이터 저장 성능이 떨어지고 인덱스의 크기가 비대해져 오히려 역효과만 불러올 수 있다.
- 218p
프라이머리 키는 이미 잘 아는 것처럼 그 레코드를 대표하는 칼럼의 값으로 만들어진 인덱스를 의미한다. 이 칼럼(때로는 칼롬의 조합)은 테이블에서 해당 레코드를 식별할 수 있는 기준값이 되기 때문에 우리는 이를 식별자라고도 부른다. 프라이머리 키는 NULL 값을 허용하지 않으며 중복을 허용하지 않는 것이 특징이다.
프라이머리 키를 제외한 나머지 모든 인덱스는 세컨더리 인덱스로 분류한다. 유니크 인덱스는 프라이머리 키와 성격이 비슷하고 프라이머리 키를 대체해서 사용할 수도 있다고 해서 대체 키라고도 하는데, 별도로 분류하기도 하고 그냥 세컨더리 인덱스로 분류하기도 한다.
- 219p
데이터의 중복 허용 여부로 분류하면 유티크 인덱스와 유니크하지 않은 인덱스로 구분할 수 있다. 인덱스가 유니크한지 아닌지는 단순히 같은 값이 1개만 존재하는지 1개 이상 존재할 수 있는지를 의미하지만, 실제 DBMS의 쿼리를 실행해야 하는 옵티마이저에게는 상당히 중요한 문제가 된다. 유니크 인덱스에 대해 동등 조건(Equal, =)으로 검색한다는 것은 항상 1건의 레코드만 찾으면 더 찾지 않아도 된다는 것을 옵티마이저에게 알려주는 효과를 낸다. 그뿐만 아니라 유니크 인덱스로 인한 MySQL의 처리 방식의 변화나 차이점이 상당히 많다.
- 220p
B-Tree 인덱스
B-Tree는 칼럼의 원래 값을 변형시키지 않고 (물론 값의 앞부분만 잘라서 관리하기는 하지만) 인덱스 구조체 내에서는 항상 정렬된 상태로 유지한다.
- 220p
InnoDB 스토리지 엔진에서는 모든 세컨더리 인덱스 검색에서 데이터 레코드를 읽기 위해서는 반드시 프라이머리 키를 저장하고 있는 B-Tree를 다시 한번 검색해야 한다. 간단히 생각하면 이 작업으로 인해 InnoDB 스토리지 엔진을 사용하는 테이블은 성능이 떨어질 것처럼 보이지만 사실은 MyISAM 인덱스 구조와 InnoDB 인덱스 구조는 각각 장단점을 가지고 있다.
- 223p
테이블에 레코드를 추가하는 작업 비용을 1이라고 가정하면 해당 테이블의 인덱스에 키를 추가하는 작업 비용을 1.5 정도로 예측하는 것이다. 일반적으로 테이블에 인덱스가 3개(테이블의 모든 인덱스가 B-Tree라는 가정하에)가 있다면 이때 테이블에 인덱스가 하나도 없는 경우는 작업 비용이 1이고, 3개인 경우에는 5.5 정도의 비용(1.5 * 3 + 1) 정도로 예측한다.
- 224p
MyISAM이나 MEMORY 스토리지 엔진을 사용하는 테이블에서는 INSERT 문장이 실행되면 즉시 새로운 키 값을 B-Tree 인덱스에 변경한다. 하지만 InnoDB 스토리지 엔진은 이 작업을 조금 더 지능적으로 처리하는데, 필요하다면 인덱스 키 추가 작업을 지연시켜 나중에 처리할 수 있다. 하지만 프라이머리 키나 유니크 인덱스의 경우 중복 체크가 필요하기 때무넹 즉시 B-Tree에 추가하거나 삭제한다.
- 224p
인덱스 키 검색
INSERT, UPDATE, DELETE 작업을 할 때 인덱스 관리에 따르는 추가 비용을 감당하면서 인덱스를 구축하는 이유는 바로 빠른 검색을 위해서다. 인덱스를 검색하는 작업은 B-Tree의 루트 노드부터 시작해 브랜치 노드를 거쳐 최종 리프 노드까지 이동하면서 비교 작업을 수행하는데, 이 과정을 "트리 탐색"이라고 한다. 인덱스 트리 탐색은 SELECT에서만 사용하는 것이 아니라 UPDATE나 DELETE를 처리하기 위해 항상 해당 레코드를 먼저 검색해야 할 경우에도 사용된다. B-Tree 인덱스를 이용한 검색은 100% 일치 또는 값의 앞부분(Left-most part)만 일치하는 경우에 사용할 수 있다. 부등호 비교 조건에서도 인덱스를 활용할 수 있지만, 인덱스를 구성하는 키 값의 뒷부분만 검색하는 용도로는 인덱스를 사용할 수 없다. 또한 인덱스를 이용한 검색에서 중요한 사실은 인덱스의 키 값에 변형이 가해진 후 비교되는 경우에는 절대 B-Tree의 빠른 검색 기능을 사용할 수 없다는 것이다. 이미 변형된 값은 B-Tree 인덱스에 존재하는 값이 아니다. 따라서 함수나 연산을 수행한 결과로 정렬한다거나 검색하는 작업은 B-Tree의 장점을 이용할 수 없으므로 주의해야 한다.
- 225p
InnoDB 스토리지 엔진에서 인덱스는 더 특별한 의미가 있다. InnoDB 테이블에서 지원하는 레코드 잠금이나 넥스트 키락(갭락)이 검색을 수행한 인덱스를 잠근 후 테이블의 레코드를 잠그는 방식으로 구현돼 있다. 따라서 UPDATE나 DELETE 문장이 실행될 때 테이블에 적절히 사용할 수 없는 인덱스가 없으면 불필요하게 많은 레코드를 잠근다. 심지어 테이블의 모든 레코드를 잠글 수도 있다.
- 225p
인덱스 키 값의 크기
이진(Binary) 트리는 각 노드가 자식 노드를 2개만 가지는데, DBMS의 B-Tree가 이진 트리라면 인덱스 검색이 상당히 비효율적일 것이다. 그래서 B-Tree의 "B"가 이진트리의 약자는 아니라고 강조했던 것이다. 일반적으로 DBMS의 B-Tree는 자식 노드의 개수가 가변적인 구조다. 그러면 MySQL의 B-Tree는 자식 노드를 몇 개까지 가지는지 궁금할 것이다. 그것은 바로 인덱스의 페이지 크기와 키 값의 크기에 따라 결정된다. MySQL 5.7 버전부터는 InnoDB 스토리지 엔진의 페이지 크기를 innodb_page_size 시스템 변수를 이용해 4KB , 64KB 사이의 값을 선택할 수 있지만 기본값은 16KB다(이 책에서도 페이지의 기본 크기인 16KB를 기준으로 설명하겠다). 인덱스의 키가 16바이트 라고 가정하면 다음 그림과 같이 인덱스 페이지가 구성될 것이다. 그림 8.7에서 자식 노드 주소라는 것은 여러 가지 복합적인 정보가 담긴 영역이며, 페이지의 종류별로 대략 6바이트에서 12바이트까지 다양한 크기의 값을 가질 수 있다. 여기서는 편의상 자식 노드 주소 영역이 평균적으로·12바이트로 구성 된다고 가정하자.
그림 8.7의 경우 하나의 인덱스 페이지(16KB)에 몇 개의 키를 저장할 수 있을까? 계산해 보면 16*1024/(16+12) = 585개 저장할수 있다. 최종적으로 이 경우는 자식 노드를 585개를 가질 수 있는 B-Tree가 되는 것이다. 그러면 인덱스 크기가 두 배인 32바이트로 늘어났다고 가정하면 한 페이지에 인덱스 16*1024/(32+12) = 372개 저장할 수 있다. 여러분의 SELECT 쿼리가 레코드 500개를 읽어야 한다면 전자는 인덱스 페이지 한번으로 해결될 수도 있지만, 후자는 최소한 2번 이상 디스크로부터 읽어야 한다. 결국 인덱스를 구성하는 키 값의 크기가 커지면 디스크로부터 읽어야 하는 횟수가 늘어나고, 그만큼 느려진다는 것을 의미한다.
- 227p
읽어야 하는 레코드의 건수
인덱스를 통해 테이블의 레코드를 읽는 것은 인덱스를 거치지 않고 바로 테이블의 레코드를 읽는 것보다 높은 비용이 드는 작업이다. 테이블에 레코드가 100만 건이 저장돼 있는데, 그중에서 50만 건을 읽어야 하는 쿼리가 있다고 가정해 보자. 이 작업은 전체 테이블을 모두 읽어서 필요 없는 50만 건을 버리는 것이 효율적일지, 인덱스를 통해 필요한 50만 건만 읽어 오는 것이 효율적일지 판단해야 한다.
인덱스를 이용한 읽기의 손익 분기점이 얼마인지 판단할 필요가 있는데, 일반적인 DBMS의 옵티마이저에서는 인덱스를 통해 레코드 1건을 읽는 것이 테이블에서 직접 레코드 1건을 읽는 것보다 4~5배 정도 비용이 더 많이 드는 작업인 것으로 예측한다. 즉, 인덱스를 통해 읽어야 할 레코드의 건수가 전체 테이블 레코드의 20~25%를 넘어서면 인덱스를 이용하지 않고 테이블을 모두 직접 읽어서 필요한 레코드만 가려내는(필터링) 방식으로 처리하는 것이 효율적이다.
전체 100만 건의 레코드 가운데 50만 건을 읽어야 하는 작업은 인덱스의 손익 분기점인 20~25% 보다 훨씬 크기 때문에 MySQL 옵티마이저는 인덱스를 이용하지 않고 직접 테이블을 처음부터 끝까지 읽어서 처리할 것이다. 이렇게 많은 레코드(전체 레코드의 20~25% 이상)를 읽을 때는 강제로 인덱스를 사용하도록 힌트를 추가해도 성능상 얻을 수 있는 이점이 없다. 물론 이러한 작업은 MySQL의 옵티마이저가 기본적으로 힌트를 무시하고 테이블을 직접 읽는 방식으로 처리하겠지만 기본으로 알고 있어야 할 사항이다.
- 230p
인덱스 레인지 스캔
인덱스 레인지 스캔은 검색해야 할 인덱스의 범위가 결정됐을 때 사용하는 방식이다. 검색하려는 값의 수나 검색 결과 레코드 건수와 관계 없이 레인지 스캔이라고 표현한다.
231p
1. 인덱스에서 조건을 만족하는 값이 저장된 위치를 찾는다. 이 과정을 인덱스 탐색이라고 한다.
2. 1번에서 탐색된 위치부터 필요한 만큼 인덱스를 차례대로 쭉 읽는다. 이 과정을 인덱스 스캔(indext scan)이라고 한다. (1번과 2번 합쳐서 인덱스 스캔으로 통칭하기도 한다)
3. 2번에서 읽어 들인 인덱스 키와 레코드 주소를 이용해 레코드가 저장된 페이지를 가져오고, 최종 레코드를 읽어 온다.
쿼리가 필요로 하는 데이터에 따라 3번 과정은 필요하지 않을 수도 있는데, 이를 커버링 인덱스라고 한다. 커버링 인덱스로 처리되는 쿼리는 디스크의 레코드를 읽지 않아도 되기 때문에 랜덤 읽기가 상당히 줄어들고 성능은 그만큼 빨라진다.
- 233p
인덱스 풀 스캔
인덱스 레인지 스캔과 마찬가지로 인덱스를 사용하지만 인덱스 레인지 스캔과는 달리 인덱스의 처음부터 끝까지 모두 읽는 방식을 인덱스 풀 스캔이라고 한다. 대표적으로 쿼리의 조건절에 사용된 칼럼이 인덱스의 첫 번째 칼럼이 아닌 경우 인덱스 풀 스캔 방식이 사용된다. 예를 들어, 인덱스는 (A, B, C) 칼럼의 순서로 만들어져 있지만 쿼리의 조건절은 B 칼럼이나 C 칼럼으로 검색하는 경우다.
- 234p
루스 인덱스 스캔
루스 인덱스 스캔이란 말 그대로 느슨하게 또는 듬성듬성하게 인덱스를 읽는 것을 의미한다.
- 235p
루스 인덱스 스캔은 인덱스 레인지 스캔과 비슷하게 작동하지만 중간에 필요치 않은 인덱스 키 값은 무시(SKIP)하고 다음으로 넘어가는 형태로 처리한다.
- 236p
인덱스 스킵 스캔
MySQL 8.0 버전부터 도입된 인덱스 스킵 스캔을 활성화하고, 동일 쿼리의 실행 계획을 다시 확인해보자.
mysql> SET optimizer_switch='skip_scan=on';
mysql> EXPLAIN
SELECT gender, birth_date
FROM employess
WHERE birth_date >= '1965-02-01';
이번에는 쿼리의 실행 계획에서 type 칼럽의 값이 "range"로 표시됐는데, 이는 인덱스엑서 꼭 필요한 부분만 읽었다는 것을 의미한다. 그리고 실행 계획의 Extra 칼럼에 "Using index for skip scan"이라는 문구가 표시됐는데, 이는 ix_gender_birthdate 인덱스에 대해 인덱스 스킵 스캔을 활용해 데이터를 조회했다는 것을 의미한다. MySQL 옵티마이저는 우선 gender 칼럼에서 유니크한 값을 모두 조회해서 주어진 쿼리에 gender 칼럼의 조건을 추가해서 쿼리를 다시 실행하는 형태로 처리한다. 다음의 그림 8.12는 인덱스 스킵 스캔이 어떻게 처리되는지를 보여준다.

- 238p
인덱스 스캔 방향
first_name 칼럼을 역순으로 정렬하는 요건만 있다면 다음 2개 인덱스 중에서 어떤 것을 선택하는 것이 좋을까? 아니면 두 인덱스 모두 동일한 성능을 보일까?
mysql> CREATE INDEX ix_firstname asc ON employees (first_name ASC);
mysql> CREATE INDEX ix_firstname desc ON employees (first_name DESC);
- 243~244p
역순 정렬 쿼리가 정순 정렬 쿼리보다 28.9% 더 시간이 걸리는 것을 확인할 수 있다. 하나의 인덱스를 정순으로 읽느냐 또는 역순으로 읽느냐에 따라 이런 차이가 발생한다는 것은 이해하기 어려울 수 있다. MySQL 서버의 InnoDB 스토리지 엔진에서 정순 스캔과 역순 스캔은 페이지 간의 양방향 연결 고리를 통해 전진하느냐 후진 하느냐의 차이만 있지만, 실제 내부적으로는 InnoDB에서 인덱스 역순 스캔이 정순 스캔에 비해 느릴 수밖에 없는 다음의 두 가지 이유가 있다.
- 페이지 잠금이 인덱스 정순 스캔에 적합한 구조
- 페이지 내에서 인덱스 레코드가 단방향으로만 연결된 구조
- 245~246p
비교 조건의 종류와 효율성
다중 칼럼 인덱스에서 각 칼럼의 순서와 그 칼럼에 사용된 조건이 동등 비교인지(=) 아니면 크다 또는 작다와 같은 범위 조건인지에 따라 각 인데스 칼럼의 활용 형태가 달라지며, 그 효율 또한 달라진다. 다음 예제를 한번 살펴보자.
mysql> SELECT * FROM dept_emp
WHERE dept_no ='d002' AND emp_no >= 10114;
이 쿼리를 위해 dept_emp 테이블에 각각 칼럼의 순서만 다른 두 가지 케이스로 인덱스를 생성했다고 가정하자. 위의 쿼리가 처리되는 동안 각 인덱스에 어떤 차이가 있었는지 살펴보자.
- 케이스 A: INDEX (dept_no, emp_no)
- 케이스 B: INDEX (emp_no, dept_no)
케이스A 인덱스는 "dept.no='d002' AND emp_no>='10144'인 레코드를 찾고, 그 이후에는 dept_no가 'd002' 가 아닐 때까지 인덱스를 그냥 쭉 읽기만 하면 된다. 이 경우에는 읽은 레코드가 모두 사용자가 원하는 결과임을 알 수 있다. 즉, 조건을 만족하는 레코드가 5건이라고 할 때, 5건의 레코드를 찾는 데 꼭 필요한 5번의 비교 작업만 수행한 것이므로 상당히 효율적인 인덱스를 이용한 것이다. 하지만 케이스 B 인덱스는 우선 "emp_no>=1O144 AND dept_no='d002'인 레코드를 찾고, 그 이후 모든 레코드에 대해 dept_ no가 'd002'인지 비교하는 과정을 거쳐야 한다. 그림 8.17은 두 인덱스의 검색 과정을 보여준다.
이처럼 인덱스를 통해 읽은 레코드가 나머지 조건에 맞는지 비교하면서 취사선택하는 작업을 ‘필터링’ 이라고도 한다. 케이스 B 인덱스에서는 최종적으로 dept_no = 'd002' 조건을 만족(필터링)하는 레코드 ' 5건을 가져온다. 즉, 이 경우에는 5건의 레코드를 찾기 위해 7번의 비교 과정을 거친 것이다. 왜 이런 현상이 발생했을까? 그 이유는 그림 8.13 ‘다중 칼럼 인덱스’에서 설명한 다중 칼럼 인덱스의 정렬 방식 (인덱스의 N번째 키 값은 N-1번째 키 값에 대해서 다시 정렬됨) 때문이다. 케이스 A 인덱스에서 2번째 칼럼인 emp_no는 비교 작업의 범위를 좁히는 데 도움을 준다. 하지만 케이스 B 인덱스에서 2번째 칼럼인 dept_no는 비교 작업의 범위를 좁히는 데 아무런 도움을 주지 못하고, 단지 쿼리의 조건에 맞는지 검사하는 용도로만 사용됐다.
공식적인 명칭은 아니지만 케이스 A 인덱스의 두 조건과 같이 작업의 범위를 결정하는 조건을 '작업 범위 결정 조건'이라 하고, 케이스 B 인덱스의 dept_no='d002' 조건과 같이 비교 작업의 범위를 줄이지 못하고 단순히 거름종이 역할만 하는 조건을 '필터링 조건' 또는 체크 조건'이라고 표현한다. 결국, 케이스 A 인덱스에서 dept_no 칼럼과 emp_no 칼럼은 모두 '작업 범위 결정 조건'에 해당하지만, 케이스 B 인덱스에서는 emp_no 칼럼만 '작업 범위 결정 조건'이고 dept_no 칼럼은 '필터링 조건'으로 사용된 것이다. 작업 범위를 결정하는 조건은 많으면 많을수록 쿼리의 처리 성능을 높이지만 체크 조건은 많다고 해서 쿼리의 처리 성능을 높이지는 못한다. 오히려 쿼리 실행을 더 느리게 만들 때가 많다.
- 247~249p
가용성과 효율성 판단
기본적으로 B-Tree 인덱스의 특성상 다음 조건에서는 사용할 수 없다. 여기서 사용할 수 없다는 것은 작업 범위 결정 조건으로 사용할 수 없다는 것을 의미하며, 경우에 따라서는 체크 조건으로 인덱스를 사용할 수는 있다.
- NOT-EQUAL로 비교된 경우
- LIE '%??' (앞부분이 아닌 뒷부분 일치) 형태로 문자열 패턴이 비교된 경우
- 스토어드 함수나 다른 연산자로 인덱스 칼럼이 변형된 후 비교된 경우
- NOT-DETERMINISTIC 속성의 스토어드 함수가 비교 조건에 사용된 경우
- 데이터 타입이 서로 다른 비교(인덱스 칼럼의 타입을 변환해야 비교가 가능한 경우)
- 문자열 데이터 타입의 콜레이션이 다른 경우
다른 일반적인 DBMS에서는 NULL 값이 인덱스에 저장되지 않지만 MYSQL에서는 NULL 값도 인덱스에 저장된다. 다음과 같은 WHERE 조건도 작업 범위 결정 조건으로 인덱스를 사용한다.
mysql> ... WHERe column IS NULL ..
다중 칼럼으로 만들어진 인덱스는 어떤 조건에서 사용될 수 있고, 어떤 경우에 절대 사용할 수 없는지 살펴보자. 다음과 같은 인덱스가 있다고 가정해보자.
INDEX ix_test (column_1, column_2, column_3, ..., column_n)
- 작업 범위 결정 조건으로 인덱스를 사용하지 못하는 경우
- 작업 범위 결정 조건으로 인덱스를 사용하는 경우(i는 2보다 크고 n보다 작은 임의의 값을 의미)
- 251~252p
클러스터링 인덱스
클러스터링 인덱스는 테이블의 프라이머리 키에 대해서만 적용되는 내용이다. 즉 프라이머리 키 값이 비슷한 레코드끼리 묶어서 저장하는 것을 클러스터링 인덱스라고 표현한다. 여기서 중요한 것은 프라이머리 키 값에 의해 레코드의 저장 위치가 결정된다는 것이다. 또한 프라이머리 키 값이 변경된다면 그 레코드의 물리적인 저장 위치가 바뀌어야 한다는 것을 의미하기도 한다. 프라이머리 키 값으로 클러스터링된 테이블은 프라이머리 키 값 자체에 대한 의존도가 상당히 크기 때문에 신중히 프라이머리 키를 결정해야 한다.
클러스터링 인덱스는 프라이머리 키 값에 의해 레코드의 저장 위치가 결정되므로 사실 인덱스 알고리즘이라기보다 테이블 레코드의 저장 방식이라고 볼 수 있다. 그래서 "클러스터링 인덱스"와 "클러스터링 테이블"은 동의어로 사용되기도 한다. 또한 클러스터링의 기준이 되는 프라이머리 키는 클러스터링 키라고도 표현한다. 일반적으로 InnoDB와 같이 항상 클러트서링 인덱스로 저장되는 테이블은 프라이머리 키 기반의 검색이 매우 빠르며, 대신 레코드의 저장이나 프라이머리 키의 변경이 상대적으로 느리다.
- 271p
주의> 일반적으로 B-Tree 인덱스도 인덱스 키 값으로 이미 정렬되어 저장된다. 이 또한 어떻게 보면 인덱스의 키 값으로 클러스터링된 것으로 생각할 수 있다. 하지만 이러한 일반적인 B-Tree 인덱스를 클러스터링 인덱스라고 부르지는 않는다. 테이블의 레코드가 프라이머리 키 값으로 정렬되어 젖아된 경우만 "클러스터링 인덱스" 또는 "클러스터링 테이블"이라고 한다.
- 271p
클러스터링 인덱스의 장점과 단점
MyISAM과 같은 클러스터링되지 않은 일반 프라이머리 키와 클러스터링 인덱스를 비교했을 때의 상대적인 장단점을 정리해 보자.
| 장점 | - 프라이머리 키로 검색할 때 처리 성능이 매우 빠름 - 테이블의 모든 세컨더리 인덱스가 프라이머리 키를 가지고 있기 때문에 인덱스만으로 처리도리 수 있는 경우가 많음(이를 커버링 인덱스라고도 한다) |
| 단점 | - 테이블의 모든 세컨더리 인덱스가 클러스터링 키를 갖기 때문에 클러스터링 키 값의 크기가 클 경우 전체적으로 인덱스의 크기가 커짐 - 세컨더리 인덱스를 통해 검색할 때 프라이머리 키로 다시 한번 검색해야 하므로 처리 성능이 느림 - INSERT 할 때 프라이머리 키에 의해 레코드의 저장 위치가 결정되기 때문에 처리 성능이 느림 - 프라이머리 키를 변경할 때 레코드를 DELETE 하고 INSERT 하는 작업이 필요하기 때문에 처리 성능이 느림 |
간단히 클러스터링 인덱스의 장단점을 살펴봤는데, 대부분 클러스터링 인덱스의 장점은 빠른 읽기이며, 단점은 느린 쓰기라는 것을 알 수 있다. 일반적으로 웹 서비스와 같은 온라인 트랜잭션 환경에서는 쓰기와 읽기의 비율이 2:8 또는 1:9 정도이기 때문에 조금 느린 쓰기를 감수하고 읽기를 빠르게 유지하는 것은 매우 중요하다.
- 274~275p
클러스터링 테이블 사용 시 주의 사항
- 클러스터링 인덱스 키의 크기
- 프라이머리 키는 AUTO-INCREMENT 보다는 업무적인 칼럼으로 생성
- 프라이머리 키는 반드시 명시할 것
- AUTO-INCREMENT 칼럼을 인조 식별자로 사용할 경우
- 275~276p
유니크 인덱스
유니크는 사실 인덱스라기보다는 제약 조건에 가깝다고 볼 수 있다. 말 그대로 테이블이나 인덱스에 같은 값이 2개 이상 저장될 수 없음을 의미하는데, MySQL에서는 인덱스 없이 유니크 제약만 설정할 방법이 없다. 유니크 인덱스에서 NULL도 저장될 수 있는데, NULL은 특정 값이 아니므로 2개 이상 저장될 수 있다. MySQL에서 프라이머리 키는 기본적으로 NULL을 허용하지 않는 유니크 속성이 자동으로 부여된다. MyISAM이나 MEMORY 테이블에서 프라이머리 키는 사실 NULL이 허용되지 않는 유니크 인덱스와 같지만 InnoDB 테이블의 프라이머리 키는 클러스터링 키의 역할도 하므로 유니크 인덱스와 근본적으로 다르다.
- 277p
인덱스 읽기
많은 사람이 유니크 인덱스가 빠르다고 생각한다. 하지만 이것은 사실이 아니다. 어떤 책에서는 유니크 인덱스는 1건만 읽으면 되지만 유니크하지 않은 세컨더리 인덱스에서는 레코드를 한 건 더 읽어야하므로 느리다고 이야기한다. 하지만 유니크하지 않은 세컨더리 인덱스에서 한 번 더 해야 하는 작업은 디스크 읽기가 아니라 CPU에서 칼럼값을 비교하는 작업이기 때문에 이는 성능상 영향이 거의 없다고 볼 수 있다.
- 277p
인덱스 쓰기
새로운 레코드가 INSERT 되거나 인덱스 칼럼의 값이 변경되는 경우에는 인덱스 쓰기 작업이 필요하다. 그런데 유니크 인덱스의 키 값을 쓸 때는 중복된 값이 있는지 없는지 체크하는 과정이 한 단계 더 필요하다. 그래서 유니크하지 않은 세컨더리 인덱스의 쓰기보다 느리다. 그런데 MySQL에서는 유니크 인덱스에서 중복된 값을 체크할 때는 읽기 잠금을 사용하고, 쓰기를 할 때는 쓰기 잠금을 사용하는데 이 과정에서 데드락이 아주 빈번히 발생한다. 또한 InnoDB 스토리지 엔진에는 인덱스 키의 저장을 버퍼링하기 위해 체인지 버퍼가 사용된다. 그래서 인덱스의 저장이나 변경 작업이 상당히 빨리 처리되지만, 안타깝게도 유니크 인덱스는 반드시 중복 체크를 해야 하므로 작업 자체를 버퍼링하지 못한다. 이 때문에 유니크 인덱스는 일반 세컨더리 인덱스보다 변경 작업이 더 느리게 작동한다.
- 278p
유니크 인덱스 사용 시 주의사항
꼭 필요한 경우라면 유니크 인덱스를 생성하는 것은 당연하다. 하지만 더 성능이 좋아질 것으로 생각하고 불필요하게 유니크 인덱스를 생성하지는 않는 것이 좋다. 그리고 하나의 테이블에서 같은 칼럼에 유니크 인덱스와 일반 인덱스를 각각 중복해서 생성해 둔 경우가 가끔 있는데, MySQL의 유니크 인덱스는 일반 다른 인덱스와 같은 역할을 하므로 중복해서 인덱스를 생성할 필요는 ㅇ벗다. 즉, 다음과 같은 테이블에서 이미 nick_name이라는 칼럼에 대해서는 유니크 인덱스인 ux_nickname이 있기 때문에 ix_nickname 인덱스는 필요하지 않다. 이미 유니크 인덱스도 일반 세컨더리 인덱스와 같은 역할을 동일하게 수행할 수 있으므로 다음과 같이 세컨더리 인덱스를 중복으로 만들어 줄 필요는 없다.
mysql> CREATE TABLE tb_unique (
id INTEGER NOT NULL,
nick_name VARCHAR(100),
PRIMARY KEY (id),
UNIQUE INDEX ux_nickname (nick_name),
INDEX ix_nickname (nick_name)
);
그리고 가끔 똑같은 칼럼에 대해 프라이머리 키와 유니크 인덱스를 동일하게 생성한 경우도 있는데, 이 또한 불필요한 중복이므로 주의하자.
- 278~279p
외래키
InnoDB의 외래키 관리에는 중요한 두 가지 특징이 있다.
- 테이블의 변경(쓰기 잠금)이 발생하는 경우에만 잠금 경합(잠금 대기)이 발생한다.
- 외래키와 연관되지 않은 칼럼의 변경은 최대한 잠금 경합(잠금 대기)을 발생시키지 않는다.
-> 자식 테이블의 변경이 대기하는 경우
-> 부모 테이블의 변경 작업이 대기하는 경우
- 280~281p
옵티마이저와 힌트
쿼리 실행 절차
1. 사용자로부터 요청된 SQL 문장을 잘게 쪼개서 MySQL 서버가 이해할 수 있는 수준으로 분리(파스 트리)한다.
2. SQL의 파싱 정보를 확인하면서 어떤 테이블로부터 읽고 어떤 인덱스를 이용해 테이블을 읽을지 선택한다.
3. 두 번째 단계에서 결정된 테이블의 읽기 순서나 선택된 인덱스를 이용해 스토리지 엔진으로부터 데이터를 가져온다.
- 283p
옵티마이저의 종류
- 규칙 기반 최적화는 기본적으로 대상 테이블의 레코드 건수나 선택도 등을 고려하지 않고 옵티마이저에 내장된 우선순위에 따라 실행 계획을 수립하는 방식을 의미한다. 이 방식에서는 통계 정보(테이블의 레코드 건수나 칼럼값의 분포도)를 조사하지 않고 실행 계획이 수립되기 때문에 같은 쿼리에 대해서는 거의 항상 같은 실행 방법을 만들어 낸다. 하지만 사용자의 데이터는 분포도가 매우 다양하기 때문에 규칙 기반의 최적화는 이미 오래전부터 많은 DBMS에서 거의 사용되지 않는다.
- 비용 기반 최적화는 쿼리를 처리하기 위한 여러 가지 가능한 방법을 만들고, 각 단위 작업의 비용(부하) 정보와 대상 테이블의 예측된 통계 정보를 이용해 실행 계획별 비용을 산출한다. 이렇게 산출된 실행 방법별로 비용이 최소로 소요되는 처리 방식을 선택해 최종적으로 쿼리를 실행한다.
- 284p
풀 테이블 스캔과 풀 인덱스 스캔
MySQL 옵티마이저는 다음과 같은 조건이 일치할 때 주로 풀 테이블 스캔을 선택한다.
- 테이블의 레코드 건수가 너무 작아서 인덱스를 통해 읽는 것보다 풀 테이블 스캔을 하는 편이 더 빠른 경우(일반적으로 테이블이 페이지 1개로 구성된 경우)
- WHERE 절이나 ON 절에 인덱스를 이용할 수 있는 적절한 조건이 없는 경우
- 인덱스 레인지 스캔을 사용할 수 있는 쿼리라고 하더라도 옵티마이저가 판단한 조건 일치 레코드 건수가 너무 많은 경우(인덱스의 B-Tree를 샘플링해서 조사한 통계 정보 기준)
- 285p
InnoDB 스토리지 엔진은 특정 테이블의 연속된 데이터 페이지가 읽히면 백그라운드 스레드에 의해 리드 어헤드(Read ahead) 작업이 자동으로 시작된다. 리드 어헤드란 어떤 영역의 데이터가 앞으로 필요해지리라는 것을 예측해서 요청이 오기 전에 미리 디스크에서 읽어 InnoDB의 버퍼 풀에 가져다 두는 것을 의미한다. 즉, 풀 테이블 스캔이 실행되면 처음 몇 개의 데이터 페이지는 포그라운드 스레드가 페이지 읽기를 실행하지만 특정 시점부터는 읽기 작업을 백그라운드 스레드로 넘긴다. 백그라운드 스레드가 읽기를 넘겨받는 시점부터는 한 번에 4개 또는 8개씩의 페이지를 읽으면서 계속 그 수를 증가시킨다. 이때 한번에 최대 64개의 데이터 페이지까지 읽어서 버퍼 풀에 저장해 둔다. 포그라운드 스레드는 미리 버퍼 풀에 준비된 데이터를 가져다 사용하기만 하면 되므로 쿼리가 상당히 빨리 처리되는 것이다.
MySQL 서버에서는 innodb_read_ahead_threshold 시스테 변수를 이용해 InnoDB 스토리지 엔진이 언제 리드 어헤드를 시작할지 임계값을 설정할 수 있다. 포그라운드 스레드에 의해 innodb_read_ahead_threshold 시스템 변수에 설정된 개수만큼의 연속된 데이터 페이지가 읽히면 InnoDB 스토리지 엔진은 백그라운드 스레드를 이용해 대량으로 그 다음 페이지들을 읽어서 버퍼 풀로 적재한다. 일반적으로 디폴트 설정만으로도 충분하지만 데이터 웨어하우스용으로 MySQL을 사용한다면 이 옵션을 더 낮은 값으로 설정해서 더 빨리 리드 어헤드가 시작되게 유도하는 것도 좋은 방법이다.
리드 어헤드는 풀 테이블 스캔에서만 사용되는 것이 아니라 풀 인덱스 스캔에서도 동일하게 사용된다. 풀 테이블 스캔이 테이블을 처음부터 끝까지 스캔하는 것을 의미하듯이, 풀 인덱스 스캔은 인덱스를 처음부터 끝까지 스캔하는 것을 의미한다. 예를 들어, 다음과 같은 쿼리르 한번 생각해보자.
mysql> SELECT COUNT(*) FROM employees;
이 쿼리는 아무런 조건 없이 employees 테이블의 레코드 건수를 조회하고 있으므로 당연히 풀 테이블 스캔을 할 것처럼 보인다. 하지만 실제 실행 계획은 풀 테입르 스캔보다는 풀 인덱스 스캔을 하게 될 가능성이 높다. MySQL 서버는 앞의 예제와 같이 단순히 레코드의 건수만 필요로 하는 쿼리라면 용량이 작은 인덱스를 선택하는 것이 디스크 읽기 횟수를 줄일 수 있기 때문이다. 일반적으로 인덱스는 테이블의 2~3개 칼럼만으로 구성되기 때문에 테이블 자체보다는 용량이 작아서 훨씬 빠른 처리가 가능하다. 하지만 다음과 같이 레코드에만 칼럼이 필요한 쿼리의 경우에는 풀 인덱스 스캔을 활용하지 못하고 풀 테이블 스캔을 한다.
mysql> SELECT * FROM employees;
- 285~286p
ORDER BY 처리 (Using filesort)
정렬을 처리하는 방법은 인덱스를 이용하는 방법과 쿼리가 실행될 때 "Filesort"라는 별도의 처리를 이용하는 방법으로 나눌 수 있다.
| 장점 | 단점 | |
| 인덱스 이용 | INSERT, UPDATE, DELETE 쿼리가 실행될 때 이미 인덱스가 정렬돼 있어서 순서대로 읽기만 하면 되므로 매우 빠르다 | INSERT, UPDATE, DELETE 작업 시 부가적인 인덱스 추가/삭제 작업이 필요하므로 느리다. 인덱스 때문에 디스크 공간이 더 많이 필요하다. 인덱스의 개수가 늘어날수록 InnoDB의 버퍼 풀을 위한 메모리가 많이 필요하다. |
| Filesort 이용 | 인덱스를 생성하지 않아도 되므로 인덱스를 이용할 때의 단점이 장점으로 바뀐다. 정렬해야 할 레코드가 ㅁ낳지 않으면 메모리에서 Filesort가 처리되므로 충분히 빠르다. |
정렬 작업이 쿼리 실행 시 처리되므로 레코드 대상 건수가 많아질수록 쿼리의 응답 속도가 느리다. |
소트 버퍼
MySQL은 정렬을 수행하기 위해 별도의 메모리 공간을 할당받아서 사용하는데, 이 메모리 공간을 소트 버퍼(Sort buffer)라고 한다.
- 289p
정렬해야 할 레코드의 건수가 소트 버퍼로 할당된 공간보다 크다면 어떨까? 이때 MySQL은 정렬해야 할 레코드를 여러 조각으로 나눠서 처리하는데, 이 과정에서 임시 저장을 위해 디스크를 사용한다.
메모리의 소트 버퍼에서 정렬을 수행하고, 그 결과를 임시로 디스크에 기록해 둔다. 그리고 다음 레코드를 가져와서 다시 정렬해서 반복적으로 임시 저장한다. 이처럼 각 버퍼 크기만큼 정렬된 레코드를 다시 병합하면서 정렬을 수행해야 한다. 이 병합 작업을 멀티 머지라고 표현하며, 수행된 멀티 머지 횟수는 Sort_merge_passers 라는 상태 변수에 누적해서 집계된다.
이 작업들이 모두 디스크의 쓰기와 읽기를 유발하며, 레코드 건수가 많을수록 이 반복 작업의 횟수가 많아진다. 소트 버퍼를 크게 설정하면 디스크를 사용하지 않아서 더 빨라질 것으로 생각할 수도 있지만, 실제 벤치마크 결과로는 큰 차이를 보이진 않았다.
- 289p
정렬 처리 방법
쿼리에 ORDER BY 가 사용되면 반드시 다음 3가지 처리 방법 중 하나로 정렬이 처리된다. 일반적으로 아래쪽에 있는 정렬 방법으로 갈수록 처리 속도는 떨어진다.
| 정렬 처리 방법 | 실행 계획의 Extra 칼럼 내용 |
| 인덱스를 사용한 정렬 | 별도 표기 없음 |
| 조인에서 드라이빙 테이블만 정렬 | "Using filesort" 메시지가 표시됨 |
| 조인에서 조인 결과를 임시 테이블로 저장 후 정렬 | "Using temporary; Using filesort" 메시지가 표시됨 |
먼저 옵티마이저는 정렬 처리를 위해 인덱스를 이용할 수 있을지 검토할 것이다. 인덱스를 이용할 수 있다면 별도의 "Filesort" 과정 없이 인덱스를 순서대로 읽어서 결과를 반환한다. 하지만 인덱스를 사용할 수 없다면 WHERE 조건에 일치하는 레코드를 검색해 정렬 버퍼에 저장하면서 정렬을 처리(Filesort)할 것이다. 이때 MySQL 옵티마이저는 정렬 대상 레코드를 최소화하기 위해 다음 2가지 방법 중 하나를 선택한다.
- 조인의 드라이빙 테이블만 정렬한 다음 조인을 수행
- 조인이 끝나고 일치하는 레코드를 모두 가져온 후 정렬을 수행
- 295p
ORDER BY의 3가지 처리 방법 가운데 인덱스를 사용한 정렬 방식만 스트리밍 형태의 처리이며, 나머지는 모두 버퍼링된 후에 정렬된다. 즉 인덱스를 사용한 정렬 방식은 LIMIT을 제한된 건수만큼만 읽으면서 바로바로 클라이언트로 결과를 전송해줄 수 있다. 하지만 인덱스를 사용하지 못하는 경우의 처리는 필요한 모든 레코드를 디스크로부터 읽어서 정렬한 후에야 비로소 LIMIT으로 제한된 건수만큼 잘라서 클라이언트로 전송해줄 수 있음을 의미한다.
- 303p
Group By 처리
GROUP BY 또한 ORDER BY와 같이 쿼리가 스트리밍된 처리를 할 수 없게 하는 처리 중 하나다. GROUP BY 절이 있는 쿼리에서는 HAVING 절을 사용할 수 있는데, HAVING 절은 GROUP BY 결과에 대해 필터링 역할을 수행한다. GROUP BY에 사용된 조건은 인덱스를 사용해서 처리될 수 없으므로 HAVING 절을 튜닝하려고 인덱스를 생성하거나 다른 방법을 고민할 필요는 없다.
- 305p
실행 계획
실행 계획 분석
id 칼럼
실행 계획에서 가장 왼쪽에 표시되는 id 칼럼은 단위 SELECT 쿼리별로 부여되는 식별자 값이다.
- 417p
select_type 칼럼
각 단위 SELECT 쿼리가 어떤 타입의 쿼리인지 표시되는 칼럼이다. select_type 칼럼에 표시될 수 있는 값은 다음과 같다.
SIMPLE
UNION이나 서브쿼리를 사용하지 않는 단순한 SELECT 쿼리인 경우 해당 쿼리 문장의 select_type은 SIMPLE로 표시된다.
PRIMARY
UNION이나 서브쿼리를 갖는 SELECT 쿼리의 실행 계획에서 가장 바깥쪽(Outer)에 있는 단위 쿼리는 select_type이 PRIMARY로 표시된다. SIMPLE과 마찬가지로 select_type이 PRMARY인 단위 SELECT 쿼리는 하나만 존재하며, 쿼리의 제일 바깥쪽에 있는 SELECT 단위 쿼리가 PRIMARY로 표시된다.
UNION
Union으로 결합하는 단위 SELECT 쿼리 가운데 첫 번째를 제외한 두 번째 이후 단위 SELECT 쿼리의 select_type은 UNION으로 표시된다.
DEPENDENT UNION
UNION이나 UNION ALL로 결합된 쿼리가 외부 쿼리에 의해 영향을 받는 것을 의미한다.
UNION RESULT
UNION RESULT는 UNION 결과를 담아두는 테이블을 의미한다. MySQL 8.0 이전 버전에서는 UNION ALL이나 UNION 쿼리는 모두 UNION의 결과를 임시 테이블로 생성했는데, 8.0 버전부터는 UNION ALL의 경우 임시 테이블을 사용하지 않도록 기능이 개선됐다.
SUBQUERY
select_type의 SUBQUERY는 FROM 절 이외에서 사용되는 서브쿼리만을 의미한다.
DEPENDENT SUBQUERY
서브쿼리가 바깥쪽 SELECT 쿼리에서 정의된 칼럼을 사용하는 경우
DERIVED
단위 SELECT 쿼리의 실행 결과로 메모리나 디스크에 임시 테이블을 생성하는 것을 의미한다. select_type이 DERIVED인 경우에 생성되는 임시 테이블을 파생 테이블이라고도 한다.
DEPENDENT DERIVED
해당 테이블이 래터럴 조인으로 사용된 것을 의미한다.
UNCACHEABLE SUBQUERY
서브쿼리에 포함된 요소에 의해 캐시 자체가 불가능할 수가 있는데, 그럴 경우
UNCACHEABLE UNION
UNION과 UNCACHEABLE이 두 개 키워드의 속성이 혼합된 select_type
MATERIALIZED
주로 FROM 절이나 IN 형태의 쿼리에 사용된 서브쿼리의 최적화를 위해 사용된다.
- 419 ~ 428p
table 칼럼
MySQL 서버의 실행 계획은 단위 SELECT 쿼리 기준이 아니라 테이블 기준으로 표시된다. 테이블의 이름에 별칭이 부여된 경우에는 별칭이 표시된다.
partitions 칼럼
쿼리의 실행 계획을 통해서 어느 파티션을 읽는지 확인할 수 있어야 쿼리의 튜닝이 가능할 것이다. 위의 쿼리와 같이 파티션을 참조하는 쿼리의 경우 옵티마이저가 쿼리 처리를 위해 필요한 파티션들의 목록만 모아서 실행 계획의 partitions 칼럼에 표시해준다. 위의 쿼리는 p1996_2000과 p2001_2005 파티션만 접근했다는 것을 다음 실행 계획에서 알 수 있다.
1 SIMPLE employees_2 p1996_2000,p2001_2005 ALL 21743
이 실행 계획에서 한 가지 재미있는 부분은 type 칼럼의 값이 ALL이라는 것이다. 이는 풀 테이블 스캔으로 쿼리가 처리된다는 것을 의미하는데, 어떻게 풀 테이블 스캔으로 테이블의 일부만 읽을 수 있는 것일까? 그 이유는 MySQL을 포함한 대부분의 RDBMS에서 지원하는 파티션은 물리적으로 개별 테이블처럼 별도의 저장 공간을 가지기 때문이다. 이 쿼리의 경우 employees_2 테이블의 모든 파티션이 아니라 p1996_2000 파티션과 p2001_2005 파티션만 풀 스캔을 실행하게 된다.
- 433p
type 칼럼
쿼리의 실행 계획에서 type 이후의 칼럼은 MySQL 서버가 각 테이블의 레코드를 어떤 방식으로 읽었는지를 나타낸다. 여기서 방식이라 함은 인덱스를 사용해 레코드를 읽었는지, 아니면 테이블을 처음부터 끝까지 읽는 풀 테이블 스캔으로 레코드를 읽었는지 등을 의미한다. 일반적으로 쿼리를 튜닝할 때 인덱스를 효율적으로 사용하는지 확인하는 것이 중요하므로 실행 계획에서 type 칼럼은 반드시 체크해야 할 중요한 정보다.
MySQL 매뉴얼에서는 type 칼럼을 "조인 타입"으로 소개한다. 또한 MySQL에서는 하나의 테이블로부터 레코드를 읽는 작업도 조인처럼 처리한다. 그래서 SELECT 쿼리의 테이블 개수에 관계없이 실행 계획의 type 칼럼을 "조인 타입"이라고 명시하고 있다. 하지만 type 칼럼의 값은 조인과 직접 연관 지어 생각하지 말고, 각 테이블의 접근 방법(Access type)으로 해석하면 된다.
실행 계획의 type 칼럼에 표시될 수 있는 값은 현재 많이 사용되는 대부분의 버전에서 거의 차이 없이 다음과 같이 표시된다.
- system
- const
- eq_ref
- ref
- fulltext
- req_or_null
- unique_subquery
- index_subquery
- range
- index_mergew
- index
- ALL
위의 12개 접근 방법 중에서 하단의 ALL을 제외한 나머지는 모두 인덱스를 사용하는 접근 방법이다.
- 434~435p
system
레코드가 1건만 존재하는 테이블 또는 한 건도 존재하지 않는 테이블을 참조하는 형태의 접근 방법을 system이라고 한다. 이 접근 방법은 InnoDB 스토리지 엔진을 사용하는 테이블에서는 나타나지 않고 MyISAM이나 MEMORY 테이블에서만 사용되는 접근 방법이다.
- 435p
const
테이블의 레코드 건수와 관계없이 쿼리가 프라이머리 키나 유니크 키 칼럼을 이용하는 WHERE 조건절을 가지고 있으며, 반드시 1건을 반환하는 쿼리의 처리 방식을 const라고 한다. 다른 DBMS에서는 이를 유니크 인덱스 스캔이라고도 표현한다.
- 436p
참고> const인 실행 계획은 MySQL의 옵티마이저가 쿼리를 최적화하는 단계에서 쿼리를 먼저 실행해서 통째로 상수화한다. 그래서 실행 계획의 type 칼럼의 값이 "상수"로 표시되는 것이다.
- 437p
eq_ref
eq_ref 접근 방법은 여러 테이블이 조인되는 쿼리의 실행 계획에서만 표시된다. 조인에서 처음 읽은 테이블의 칼럼값을, 그 다음 읽어야 할 테이블의 프라이머리 키나 유니크 키 칼럼의 검색 조건에 사용할 때를 가리켜 eq_ref라고 한다. 이때 두 번째 이후에 읽는 테이블의 type 칼럼에 eq_ref가 표시된다. 또한 두 번째 이후에 읽히는 테이블을 유니크 키로 검색할 때 그 유니크 인덱스는 NOT NULL 이어야 하며, 다중 칼럼으로 만들어진 프라이머리 키나 유니크 인덱스라면 인덱스의 모든 칼럼이 비교 조건에 사용돼야만 eq_ref 접근 방법이 사용될 수 있다. 즉, 조인에서 두 번째 이후에 읽는 테이블에서 반드시 1건만 존재한다는 보장이 있어야 사용할 수 있는 접근 방법이다.
- 438p
ref
ref 접근 방법은 eq_ref와는 달리 조인의 순서와 관계없이 사용되며, 또한 프라이머리 키나 유니크 키 등의 제약 조건도 없다. 인덱스의 종류와 관계없이 동등 조건으로 검색할 때는 ref 접근 방법이 사용된다. ref 타입은 반환되는 레코드가 반드시 1건이라는 보장이 없으므로 const나 eq_ref보다는 빠르지 않다. 하지만 동등한 조건으로만 비교되므로 매우 빠른 레코드 조회 방법의 하나다.
- 439p
지금까지 배운 실행 계획의 type에 대해 간단히 비교하면서 다시 한번 정리해보자.
- const: 조인의 순서와 관계없이 프라이머리 키나 유니크 키의 모든 칼럼에 대해 동등 조건으로 검색(반드시 1건의 레코드만 반환)
- eq_ref: 조인에서 첫 번째 읽은 테이블의 칼럼값을 이용해 두 번째 테입르을 프라이머리 키나 유니크 키로 동등 조건 검색(두 번째 테이블은 반드시 1 건의 레코드만 반환)
- ref: 조인의 순서와 인덱스의 종류에 관곙벗이 동등 조건으로 검색(1건의 레코드만 반환된다는 보장이 없어도 됨)
- 439p
세 가지 모두 매우 좋은 접근 방법으로 인덱스의 분포도가 나쁘지 않다면 성능상의 문제를 일으키지 않는 접근 방법이다. 쿼리를 튜닝할 때도 이 세 가지 접근 방법에 대해서는 크게 신경 쓰지 않고 넘어가도 무방하다.
- 440p
fulltext
fulltext 접근 방법은 MySQL 서버의 전문 검색 인덱스(full-text search)를 사용해 레코드를 읽는 접근 방법을 의미한다.
- 440p
ref_or_null
이 접근 방법은 ref 접근 방법과 같은데, NULL 비교가 추가된 형태다. 접근 방법의 이름 그대로 ref 방식 또는 NULL 비교 접근 방법을 의미한다.
- 442p
unique_subquery
WHERE 조건절에서 사용될 수 있는 IN 형태의 쿼리를 위한 접근 방법이다. unique_subquery의 의미 그대로 서브쿼리에서 중복되지 않는 유니크한 값만 반환할 때 이 접근 방법을 사용한다.
- 442p
index_subquery
IN 연산자의 특성상 IN 또는 IN 형태의 조건은 괄호 안에 있는 값의 목록에서 중복된 값이 먼저 제거돼야 한다. 서브쿼리 결과의 중복된 값을 인덱스를 이용해서 제거할 수 있을 때 index_subquery 접근 방법이 사용된다.
- 443p
range
range는 우리가 익히 알고 있는 인덱스 레인지 스캔 형태의 접근 방법이다. range는 인덱스를 하나의 값이 아니라 범위로 검색하는 경우를 의미하는데, 주로 "<, >, IS NULL, BETWEEN, IN, LIKE" 등의 연산자를 이용해 인덱스를 검색할 때 사용된다.
- 443p
index_merge
index_merge 접근 방법은 2개 이상의 인덱스를 이용해 각각의 검색 결과를 만들어낸 후, 그 결과를 병합해서 처리하는 방식이다.
- 444p
index
index 접근 방법은 인덱스를 처음부터 끝까지 읽는 인덱스 풀 스캔을 의미한다. range 접근 방법과 같이 효율적으로 인덱스의 필요한 부분만 읽는 것을 의미하는 것은 아니라는 점을 잊지 말자.
- 445p
ALL
테이블을 처음부터 끝까지 전부 읽어서 불필요한 레코드를 제거하고 반환한다.
- 446p
possible_keys 칼럼
possible_keys 칼럼에 있는 내용은 옵티마이저가 최적의 실행 계획을 만들기 위해 후보로 선정했던 접근 방법에서 사용되는 인덱스의 목록일 뿐이다. 즉, 말 그대로 "사용될 법했던 인덱스의 목록"인 것이다. 실제로 실행 계획을 보면 그 테이블의 모든 인덱스가 목록에 포함되어 나오는 경우가 허다하기에 쿼리를 튜닝하는 데 크게 도움이 되지 않는다.
- 448p
key 칼럼
key 칼럼에 표시되는 인덱스는 최종 선택된 실행 계획에서 사용하는 인덱스를 의미한다. 그러므로 쿼리를 튜닝할 때는 key 칼럼에 의도했던 인덱스가 표시되는지 확인하는 것이 중요하다.
- 448p
key_len 칼럼
쿼리를 처리하기 위해 다중 칼럼으로 구성된 인덱스에서 몇 개의 칼럼까지 사용했는지 우리에게 알려준다. 더 정확하게는 인덱스의 각 레코드에서 몇 바이트까지 사용했는지 알려주는 값이다. 그래서 다중 칼럼 인덱스뿐 아니라 단일 칼럼으로 만들어진 인덱스에서도 같은 지표를 제공한다.
- 449p
MySQL에서는 NOT NULL이 아닌 칼럼에서는 칼럼의 값이 NULL 인지 아닌지를 저장하기 위해 1 바이트를 추가로 더 사용한다.
- 451p
ref 칼럼
접근 방법이 ref면 참조 조건(equal 비교 조건)으로 어떤 값이 제공됐는지 보여준다.
- 451p
사용자가 명시적으로 값을 변환할 때뿐만 아니라 MySQL 서버가 내부적으로 값을 변환해야 할 때도 ref 칼럼에는 func가 출력된다. 문자집합이 일치하지 않는 두 문자열 칼럼을 조인한다거나 숫자 타입의 칼럼과 문자열 타입의 칼럼으로 조인할 때가 대표적인 예다. 가능하다면 MySQL 서버가 이런 변환을 하지 않아도 되게 조인 칼럼의 타입은 일치시키는 편이 좋다.
- 452p
rows 칼럼
대상 테이블에 얼마나 많은 레코드가 포함돼 있는지 또는 각 인덱스 값의 분포도가 어떤지를 통계 정보를 기준으로 조사해서 예측한다.
- 452p
filtered 칼럼
실행 계획에서 rows 칼럼의 값은 인덱스를 사용하는 조건에만 일치하는 레코드 건수를 예측한 것이다. 하지만 대부분 쿼리에서 WHERE 절에 사용되는 조건이 모두 인덱스를 사용할 수 있는 것은 아니다. 특히 조인이 사용되는 경우에는 WHERE 절에서 인덱스를 사용할 수 있는 조건도 중요하지만 인덱스를 사용하지 못하는 조건에 일치하는 레코드 건수를 파악하는 것도 매우 중요하다.
- 454p
Extra 칼럼
const row not found
쿼리의 실행 계획에서 const 접근 방법으로 테이블을 읽었지만 실제로 해당 테이블에 레코드가 1 건도 존재하지 않으면 Extra 칼럼에 이 내용이 표시된다.
- 456p
deleting all rows
테이블의 모든 레코드를 삭제하는 핸들러 기능을 한번 호출함으로써 처리됐다는 것을 의미한다.
- 456p
-> 8.0 버전 InnoDB에는 더 이상 표시되지 않음
Impossible HAVING
Impossible WHERE
LooseScan
No matching min/max row
- 457~ 460p
Using filesort
ORDER BY를 처리하기 위해 인덱스를 이용할 수도 있지만 적절한 인덱스를 사용하지 못할 때는 MySQL 서버가 조회된 레코드를 다시 한번 정렬해야 한다. ORDER BY 처리가 인덱스를 사용하지 못할 때만 실행 계획의 Extra 칼럼에 "Using filesort" 코멘트가 표시되며, 이는 조회된 레코드를 정렬용 메모리 버퍼에 복사해 퀵 소트 또는 힙 소트 알고리즘을 이용해 정렬을 수행하게 된다는 의미다. Using filesort 코멘트는 ORDER BY가 사용된 쿼리의 실행 계획에서만 나타날 수 있다.
- 475p
Using Index(커버링 인덱스)
데이터 파일을 전혀 읽지 않고 인덱스만 읽어서 쿼리를 모두 처리할 수 있을 때 extra 칼럼 "Using index"가 표시된다. 인덱스를 이용해 처리하는 쿼리에서 가장 큰 부하를 차지하는 부분은 인덱스 검색에서 일치하는 키 값들의 레코드를 읽기 위해 데이터 파일을 검색하는 작업이다. 최악의 경우에는 인덱스를 통해 검색된 결과 레코드 한 건 한 건마다 디스크를 한 번씩 읽어야 할 수도 있다.
- 476p
주의> Extra 칼럼에 표시되늰 "Using index"와 접근 방법(type)의 "index"를 혼동할 때가 자주 있는데, 사실 이 두가지는 성능상 반대되는 개념이라서 반드시 구분해서 이해해야 한다.
- 479p
Using where
이미 MySQL 서버의 아키텍처 부분에서 언급했듯이 MySQL 서버는 내부적으로 크게 MySQL 엔진과 스토리지 엔진이라는 두 개의 레이어로 나눠 볼 수 있다. 각 스토리지 엔진은 디스크나 메모리상에서 필요한 레코드를 읽거나 저장하는 역할을 하며, MySQL 엔진은 스토리지 엔진으로부터 받은 레코드를 가공 또는 연산하는 작업을 수행한다. MySQL 엔진 레이어에서 별도의 가공을 해서 필터링(여과) 작업을 처리한 경우에만 Extra 칼럼에 "Using where" 코멘트가 표시된다.

그림 10.12와 같이 각 스토리지 엔진에서 전체 200건의 레코드를 읽었는데, MySQL 엔진에서 별도의 필터링이나 가공 없이 그 데이터를 그대로 클라이언트로 전달하면 "Using where"가 표시되지 않는다.
- 489p
MySQL 8.0에서는 실행 계획에 filtered 칼럼이 같이 표시되므로 쉽게 성능상의 이슈가 있는지 없는지를 알아낼 수 있다. 이 실행 계획에서는 filtered 칼럼의 값이 50%인 것을 보면 옵티마이저는 100건 중에서 50건은 버려지고 최종 남은 50건이 반환될 것으로 예측했다는 것을 알 수 있다.
- 490p
'Book' 카테고리의 다른 글
| [독서 기록] 웹 개발자를 위한 대규모 서비스를 지탱하는 기술 (1) | 2024.04.14 |
|---|---|
| [독서 기록] 일류의 조건 (0) | 2024.04.13 |
| [독서기록] 클린 아키텍처 (0) | 2024.02.26 |
| [독서 기록] 가상 면접 사례로 배우는 대규모 시스템 설계 기초 (0) | 2024.02.09 |
| [독서 기록] 테스트 주도 개발로 배우는 객체지향 설계와 실천 (1) | 2024.02.09 |


