1. 배치 프로그램 왜 사용하고 언제 사용할까
배치란 정해진 시간에 일괄적으로 작업을 처리하는 것을 의미한다. 대체로 대용량 데이터를 다룬다. 서비스를 운영하는 관점에서 주기적으로 작업을 처리하려면 배치 프로그램을 사용해야 한다.
데이터 처리
- 필요한 데이터를 모아서 처리해야 할 때
- ETL 작업 (Extract-Transform-Load)
- 데이터 모델을 만들 때 (연관 상품을 추천하기) -> 헤비한 데이터 처리
- 마케팅 참고를 위한 데이터 지표 집계
서비스
- 일부러 지연시켜 처리할 때 (주문한 상품을 바로 배송하지 않고 일정 시간 뒤 보낼 때)
- 메시지, 이메일, 푸시 등의 발송
- 데이터 마이그레이션
- 실패한 트랜잭션 처리
- 쿠폰, 포인트 소진 처리
- 월말 월초 특정 데이터 생성(월별 거래 명세서)
기타
- 자원을 효율적으로 사용 (트래픽이 적은 시간대에 서버 리소스 활용)
그렇다면 Spring Batch를 쓰는 이유는 무엇일까?
스프링 배치란 ?

-> 가볍고 다양한 기능을 가진 배치 프레임 워크
-> 견고한 배치 어플리케이션이 가능하다.
-> 기업 시스템의 매일 운영에 필수적인 수준
-> 스프링으로 작성된 코드를 재활용할 수 있다. 기존 스프링 프로젝트와의 호환성이 높다.
-> 다양한 기능: 로깅/추적, 트랜잭션 관리, 작업 처리 통계, 재시작, 건너뛰기 등
-> 멀티 코어 또는 멀티 서버에서 처리를 분산하는 기능 제공
2. Spring Batch 아키텍처
먼저 스프링 배치의 도메인 언어를 살펴보자.

- JobLauncher는 Job을 실행시키는 컴포넌트
- Job은 배치 작업. JobRepository는 Job 실행과 Job, Step을 저장
- Step은 배치 작업의 단계.
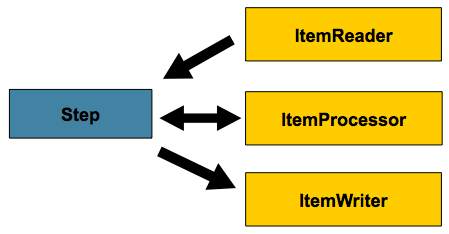
- ItemReader, ItemProcessor, ItemWriter는 데이터를 읽고 처리하고 쓰는 구성
-> Step이 각각 하나씩만을 보유하도록 하고 있다.
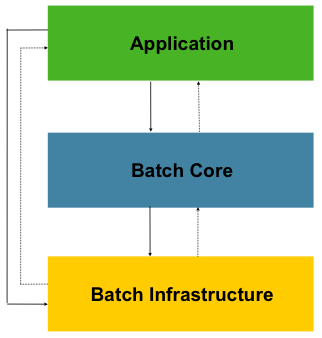
먼저 Aplication Layer는 사용자 코드로 구성된다. 비즈니스와 서비스 로직을 주로 의미하며, Core와 Infrastrucer를 이용해 배치의 기능을 만든다.
Core Layer는 배치 작업을 시작하고 제어하는데 필수적인 클래스다. Job, Step 등으로 구성되어 있다.
Infrastructure Layer는 외부와의 상호작용을 담당한다. ItemReader, ItemWriter, RetryTemplate으로 구성되어 있다.
Job
Job은 말 그대로 일을 의미한다. 전체 배치 프로세스를 캡슐화한 도메인이다.
Job을 통해 Step의 순서를 정의하여 실질적으로 수행되는 작업의 단계를 정의한다.
이때 작업을 수행하는데 필요한 파라미터를 받는다.

위의 그림을 보면 EndOfDay라는 잡이 생성되었을 때, 파라미터로 date를 받고 이를 인스턴스화한다. 해당 인스턴스는 실질적으로 Job이 수행하는 객체이며, 이를 Execution을 통해 실행한다.
간단한 코드 예시는 다음과 같다.
다음과 같이 Bean으로 생성이 되며 시작하는 Job과 이후의 Step으로서의 다른 Job들을 구성해줄 수 있다.
@Bean
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.start(playerLoad())
.next(gameLoad())
.next(playerSummarization())
.build();
}
Step
작업 처리의 단위를 Step이라고 한다. 실질적으로 각각의 단계를 처리하는 것을 Step이라고 한다.
Chunk 기반 스텝과 Tasklet 스텝으로 나뉜다.
대용량의 데이터를 많이 다루기 때문에 Chunk 기반의 스텝을 많이 쓰게 된다.
Chunk 기반의 스텝은 다음과 같은 시퀀스를 갖고 진행된다.

Chunk 기반으로 하나의 트랜잭션에서 데이터를 처리하는 것을 의미한다.
위의 그림을 보면 실행 부터 아이템을 write 하는 것 까지 하나의 트랜잭션으로 진행한다.
commitInterval 만큼 데이터를 읽고 트랜잭션을 경계 내에서 chunkSize 만큼 write 한다. 다음과 같은 슈도 코드를 살펴보자.
List items = new Arraylist();
for(int i = 0; i < commitInterval; i++){
Object item = itemReader.read();
if (item != null) {
items.add(item);
}
}
List processedItems = new Arraylist();
for(Object item: items){
Object processedItem = itemProcessor.process(item);
if (processedItem != null) {
processedItems.add(processedItem);
}
}
itemWriter.write(processedItems);
- chunkSize : 한 트랜잭션에서 쓸 아이템의 개수
- commitInterval: reader가 한 번에 읽을 아이템의 개수
- chunkSize >= commitInterval 하지만 보통 같게 맞춰서 사용하는 것이 좋다.
읽을 아이템을 담을 배열을 선언하고, for 반복문을 통해 순차적으로 itemReader를 통해 읽고 더 읽을 아이템이 없을 때까지 읽어 담는다.
이 과정이 ItemReader가 읽는 과정이다. 이후 processedItems 배열이 선언되고, 읽은 아이템에 대해서 각각 처리를 한다.
최종적으로 처리된 items를 리스트 전체를 write 한다.
이와 같이 모든 작업이 하나의 트랜잭션 내에서 진행된다.
다음은 예제 코드이다.
/**
* Note the JobRepository is typically autowired in and not needed to be explicitly
* configured
*/
@Bean
public Job sampleJob(JobRepository jobRepository, Step sampleStep) {
return new JobBuilder("sampleJob", jobRepository)
.start(sampleStep)
.build();
}
/**
* Note the TransactionManager is typically autowired in and not needed to be explicitly
* configured
*/
@Bean
public Step sampleStep(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("sampleStep", jobRepository)
.<String, String>chunk(10, transactionManager)
.reader(itemReader())
.writer(itemWriter())
.build();
}
sampleJob은 sampleStep을 실행하도록 한다. 이때 sampleStep은 Chunk 단위에서 스텝을 관리하는 transactionManager를 바탕으로 생성하며, reader와 writer를 설정해준다.
여기서는 Process가 없는데, 이렇게 간단한 조작만 있다면 굳이 Process를 별도로 구현하지 않을 수도 있다.
한편 Tasklet 스텝은 이와 같은 과정을 한 번에 퉁쳐서 진행하는 과정이라고 보면 된다.
@Bean
public Step step1(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("step1", jobRepository)
.tasklet(myTasklet(), transactionManager)
.build();
}
Tasklet 구현체를 설정하고, 내부에 단순한 읽기, 쓰기, 처리 로직을 모두 넣는다. 반복 상태를 설정할 수 있다.
구현체 예제 코드는 다음과 같다.
public class FileDeletingTasklet implements Tasklet, InitializingBean {
private Resource directory;
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
File dir = directory.getFile();
Assert.state(dir.isDirectory());
File[] files = dir.listFiles();
for (int i = 0; i < files.length; i++) {
boolean deleted = files[i].delete();
if (!deleted) {
throw new UnexpectedJobExecutionException("Could not delete file " +
files[i].getPath());
}
}
return RepeatStatus.FINISHED;
}
public void setDirectoryResource(Resource directory) {
this.directory = directory;
}
public void afterPropertiesSet() throws Exception {
Assert.state(directory != null, "directory must be set");
}
}
위와 같이 Tasklet 내부에 모든 로직을 담는다. 이후 모든 것이 끝나면 RepeatStatus를 FINISHED로 설정해주는 것이 일반적이다.
스키마 구조
스키마 구조는 메타 데이터 스키마를 의미한다. 배치를 실행하고 관리하기 위한 메타데이터를 저장한다. 이를 MySql 등의 데이터베이스를 구축해서 활용한다. 즉, 배치가 진행되는 과정에서 만들어지는 데이터를 기록화하여 남기는 것이라고 보면 된다.
예를 들어 다음과 같은 그림을 보자.

- StepExecution: 배치 작업의 각 단계(step)의 실행 정보를 저장.
- JobInstance: 배치 작업의 인스턴스 정보를 저장.
- JobExecution: 배치 작업의 실행 정보를 저장.
- ExecutionConxtext.Step: 각 단계의 실행 컨텍스트 정보를 저장.
- JobExecution: 배치 작업 실행에 대한 실행 컨텍스트 정보를 저장.
- JobParameters: 배치 작업 실행에 필요한 파라미터 정보를 저장.
- ExecutionContext.Job: 배치 작업 실행에 대한 실행 컨텍스트 정보를 저장.
메타 데이터 스키마는 다음과 같이 활용할 수 있다.
- Spring Batch Framework 초기화시 설정 값으로 필요
- Job의 이력, 파라미터, 결과 등 조회
- 별도의 로그를 남겨 사용하는 경우가 많으므로 조회할 일이 많지는 않음
참고 자료
- Spring Batch Reference Doc: https://docs.spring.io/spring-batch/docs/current/reference/html/
- 패스트캠퍼스: 한 번에 끝내는 Spring 완.전.판 초격차 패키지 Online.
'Lecture' 카테고리의 다른 글
| 스프링 배치 Validator, listener, FlatFileItemReader 및 Writer를 사용하여 간단한 text 변환 작업을 구현해보자 (0) | 2023.07.12 |
|---|---|
| Spring Batch 프로젝트 환경 구성, 데이터 읽고 처리하고 쓰기, Batch 테스트 코드 (0) | 2023.07.12 |
| 선착순 이벤트 시스템에서 발생가능한 동시성 문제와 해결 방안 탐구(redis, kafka) (0) | 2023.07.11 |
| 동시성 이슈 사례와 해결 방안 탐구 (Synchronized, database, redis) (0) | 2023.07.11 |
| 자바 코드 리팩토링: 스프링 AplicationEventPublisher를 이용해 시스템 강결합을 해결해보자 (1) | 2023.07.09 |



