0. 배경
사내 프로젝트 진행중에 여러 서비스 간의 통신 과정에서 동시성 이슈가 발생했습니다. 특별히 이슈가 발생한 부분은 카우치베이스와의 상호작용이 일어나는 부분이었습니다. 해당 서비스의 오너는 아니었지만 본 프로젝트를 진행하면서 연관성 높은 서비스를 함께 개발했고 문제가 발생하고 해결하는 과정에서 많은 부분을 기여했습니다. 본 글에서는 카우치베이스를 사용할 때 발생한 동시성 이슈를 소개합니다. 더불어 이를 제어하기 위해 카우치베이스에서 제공하는 CAS 오퍼레이션을 사용한 방식과 그 과정에서 발생한 트러블 슈팅에 대한 회고를 다룹니다. 글에서 사용한 코드나 명칭은 컨셉용으로 대체하였음을 밝힙니다.
- 시스템 아키텍처는 MSA 분산환경 구조입니다.
- 메시지큐로 카프카를 사용하며 최종일관성 정책을 사용합니다.
- 배포 환경은 운영 환경과 스테이지 환경으로 이중화되어 있고, 운영 환경에서 서버 인스턴스는 사중화되어 있습니다.
- 카우치베이스 7.1 버전을 사용합니다.
1. 문제
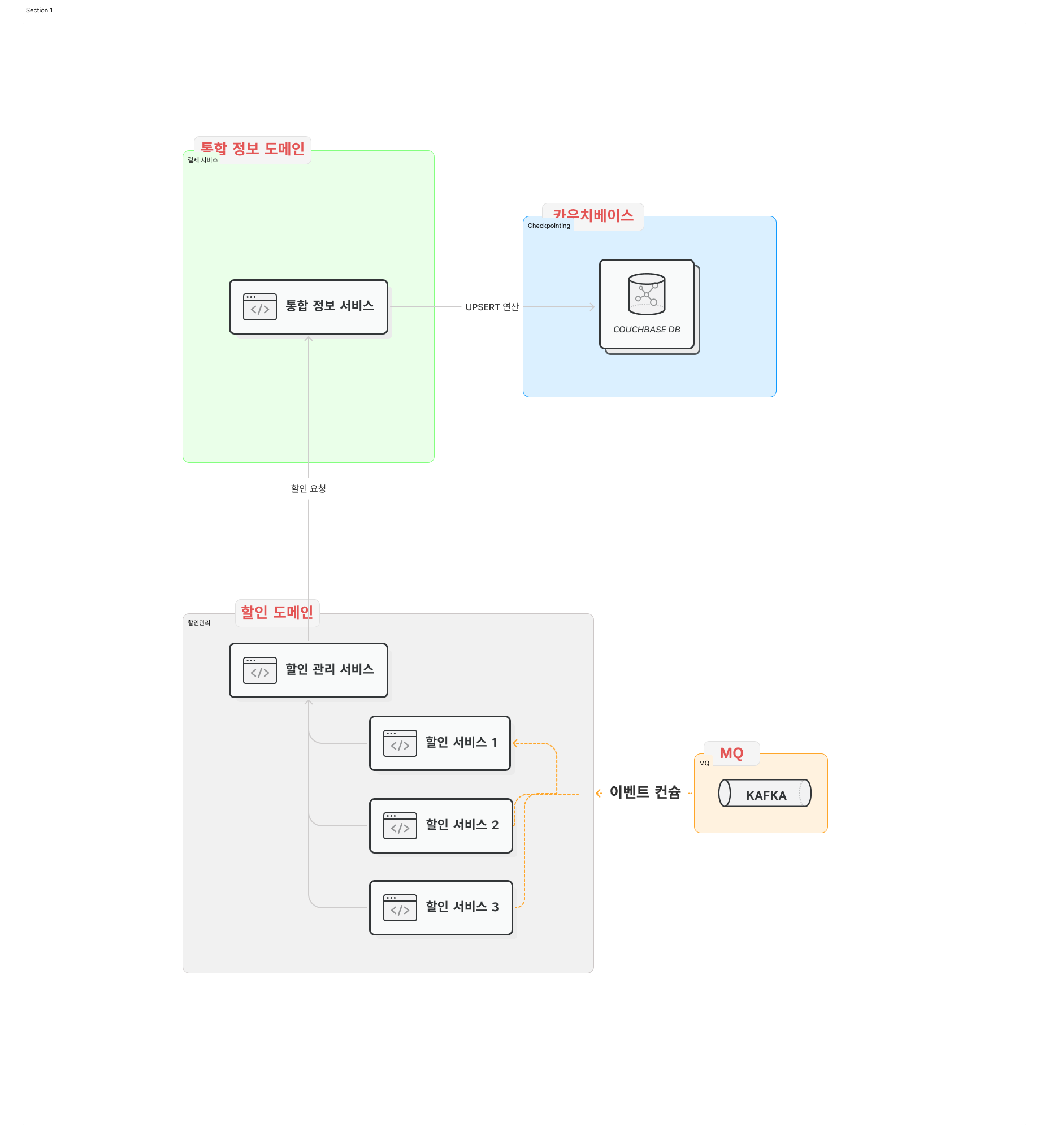
아키텍처 및 구조
아키텍처 구성을 이해하는 것이 필요하다. 세 가지 주요 컴포넌트가 있다. 할인 서비스, 할인 관리 서비스, 통합 정보 서비스이다.
- 할인 서비스: 여러 개의 할인 서비스가 존재한다. 할인 서비스는 카프카로부터 메시지를 컨슘하고 조건에 따라 할인 관리 서비스로 요청을 보낸다.
- 할인 관리 서비스: 할인 서비스로부터의 요청을 처리한다. 적절한 가공을 거친 후 통합 정보 서비스로 이관한다.
- 통합 정보 서비스: 할인 관리 서비스로부터 받은 정보를 처리하여 카우치베이스에 업서트(upsert)한다.
이 과정에서 할인 서비스가 카프카 컨슈밍을 하는 구간을 제외하고 모든 구간은 Rest 통신으로 동기 통신을 한다.
다음과 같다.
카우치베이스가 upsert 하는 부분을 좀 더 자세히 들여다보면 다음과 같다.
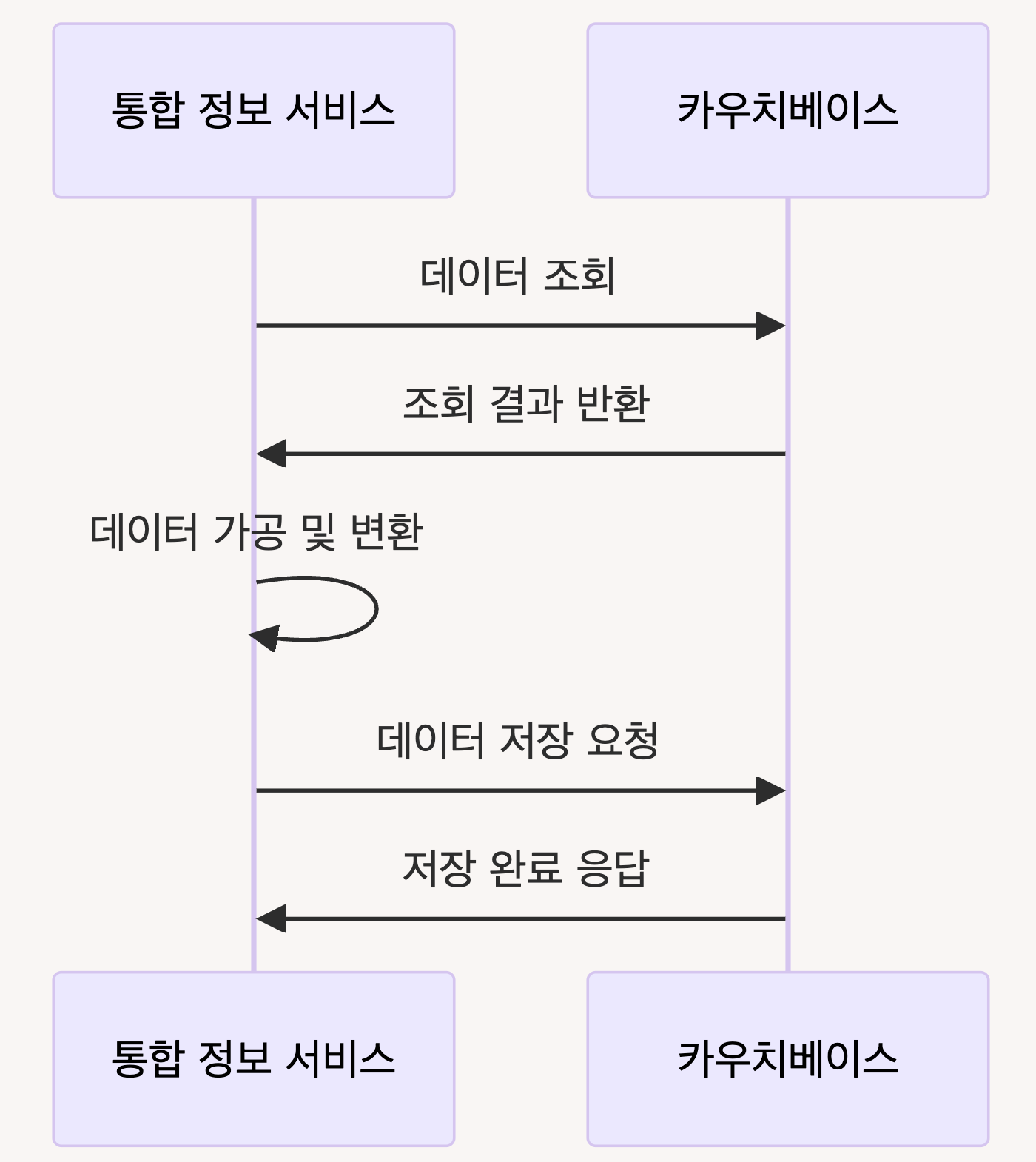
통합 정보 서비스가 카우치베이스에 데이터를 업서트하는 구체적인 단계를 보자. 통합 정보 서비스는 먼저 카우치베이스에서 데이터를 조회한다. 조회된 데이터를 가공하고 변환하여 최종적으로 업서트 요청을 보낸다. 카우치베이스는 업서트 작업을 완료하고 응답을 반환한다.
이제 본격적으로 문제 섹션으로 넘어가보자. 그 전에 한번 생각해보자. 여기까지의 상황에서 어떤 문제가 예상될까?
문제의 발생
카프카 컨슈밍부분부터 생각해보자. 메시지 큐에 tps가 늘어나고 할인 서비스의 처리량이 높아진 상황이다. 이에 따라 할인 관리 서비스로 보내는 요청도 늘어난다. 하나의 메시지에 대해 복수의 요청이 다발적으로 전송된다.
즉 n개의 동시적 요청이 할인 관리 서비스를 통과하여 통합 정보 서비스에 꽂히게 된다. 어떻게 될까?
upsert 연산에서 race 컨디션이 발생하게 된다.
시나리오 1: 동시적 요청 발생
- 두 개의 할인 서비스가 동시에 동일한 사용자에 대한 할인 정보를 통합 정보 서비스로 보낸다.
- 통합 정보 서비스는 이 두 개의 요청을 거의 동시에 처리하게 된다.
Race Condition 다이어그램
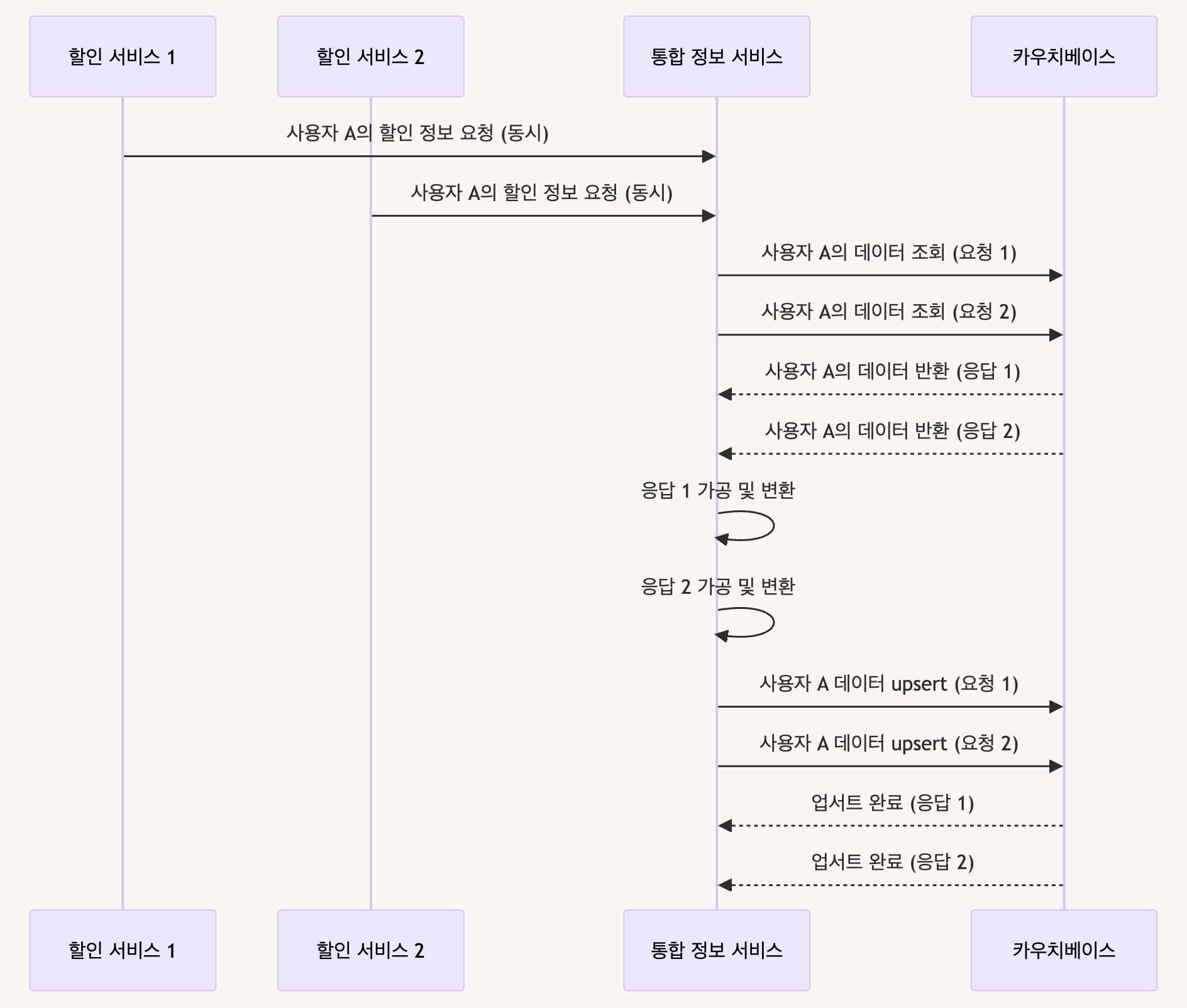
문제 발생
위의 다이어그램에서 보면 할인 서비스 1과 할인 서비스 2가 동시에 사용자 A의 데이터를 통합 정보 서비스로 보냈다. 통합 정보 서비스는 거의 동시에 카우치베이스에 데이터 조회 요청을 보냈고, 카우치베이스는 동일한 데이터를 반환했다. 그 결과 두 개의 upsert 요청이 거의 동시에 이루어졌으며, 이로 인해 race condition이 발생했다.
무엇이 문제일까?
정상적인 케이스랑 비교해보자.
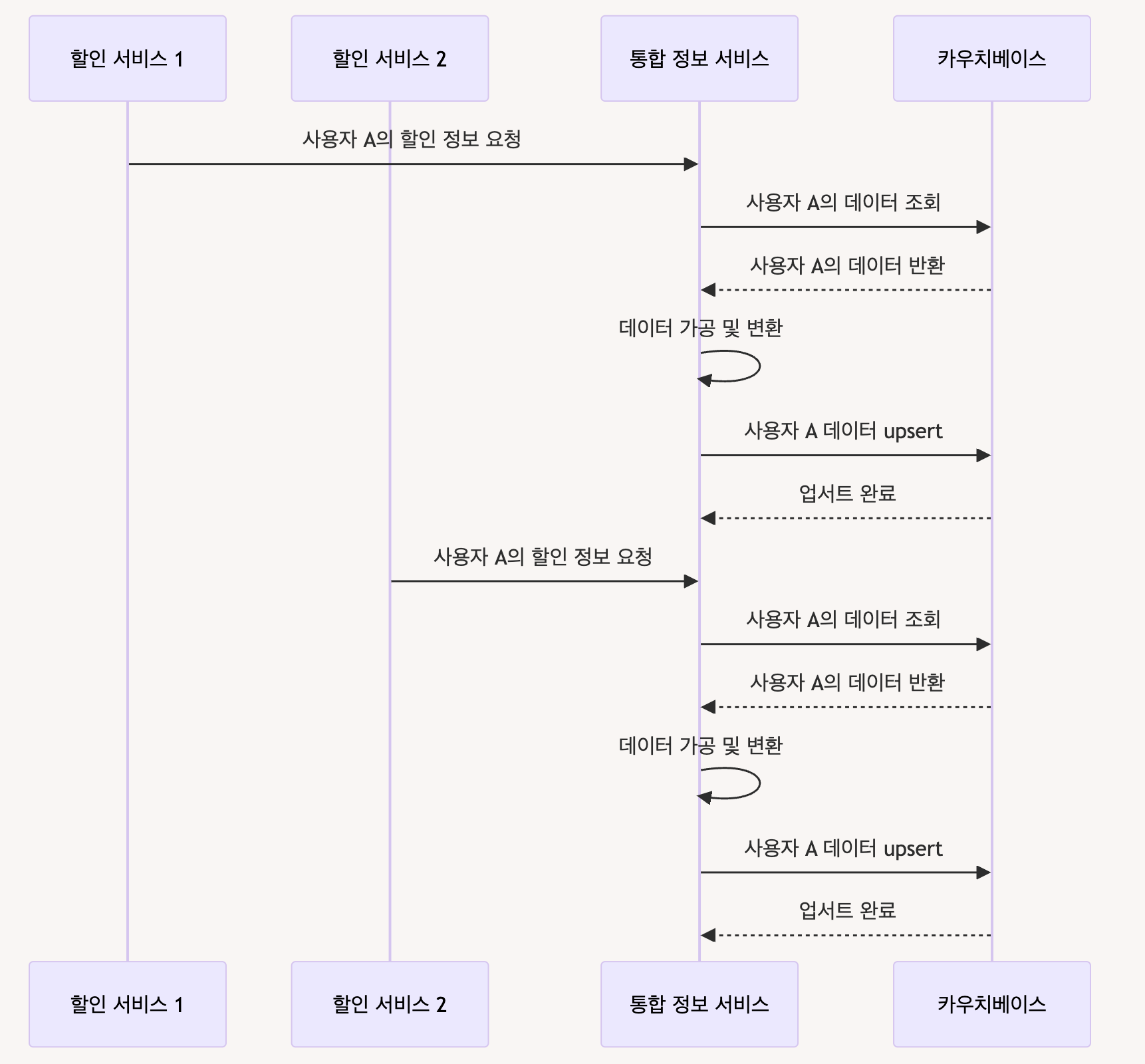
정상 케이스에서는 하나의 요청이 하나의 요청이 완료된 후 다음 요청이 처리된다
문제의 케이스에서 문제가 되는 부분은 하나는 덮어씌워진다는 것이다. 즉, 하나의 정보는 사라지는 lost update 현상이 발생한다.
해결방안 탐구: 3가지 방안
문제의 핵심은 동시성으로 인해 발생하는 race condition과 데이터 일관성 문제이다. 이를 해결하기 위한 다음과 같은 세 가지 방안을 생각해볼 수 있다.
1. 트랜잭션 사용
첫 번째는 트랜잭션을 사용하는 것이다.
카우치베이스는 NoSQL 데이터베이스로, 일반적인 RDBMS에서 제공하는 트랜잭션 기능을 기본적으로 사용하지 않는다. 하지만 카우치베이스에서도 트랜잭션을 지원한다. 카우치베이스는 기본적으로 단일 연산에 대해서는 원자적 연산을 보장한다. 하지만 현재의 경우는 조회 후 업데이트라는 두 단위의 upsert 연산이다. 이를 하나의 논리적 단위어 취급하자는 것이다. RDBMS에서와 마찬가지로 트랜잭션의 동일한 개념이 적용된다. 즉, 여러 연산을 하나의 트랜잭션으로 묶어 원자적 연산을 보장할 수 있다.
현재 우리의 시스템에서는 트랜잭션을 사용하지 않는 결정을 내렸다. 만약 트랜잭션을 사용한다면 어떨까? 트랜잭션을 사용하면 다음과 같은 방식으로 문제를 해결할 수 있다.
- 데이터 조회, 가공, upsert 연산을 하나의 트랜잭션으로 묶는다.
- 트랜잭션 내에서 모든 연산이 성공적으로 완료되면 데이터베이스에 적용된다. 그렇지 않으면 롤백된다.
트랜잭션은 직접 구현할 수도 있겠지만 카우치베이스에서 Java SDK로 제공하는 트랜잭션을 사용할 수도 있다. 예제 코드를 살펴보자.
public class CouchbaseTransactionExample {
public static void main(String[] args) {
// 클러스터와 버킷에 연결
Cluster cluster = Cluster.connect //...
transactions.run(ctx -> {
// 트랜잭션 내에서 데이터 조회
var collection = // ...
// 데이터 가공
var content = // ...
// 데이터 upsert 연산
collection. //...
// 트랜잭션 완료
ctx.commit();
});
}
}이 예제에서 transactions.run 메서드를 사용하여 트랜잭션을 실행한다. 트랜잭션 내에서 데이터 조회, 가공, 그리고 upsert 연산을 수행하고, 모든 연산이 성공적으로 완료되면 ctx.commit()을 호출하여 트랜잭션을 완료한다. 만약 트랜잭션 내에서 오류가 발생하면 트랜잭션이 롤백된다.
카우치베이스 트랜잭션의 기본 격리 수준은 "스냅샷 격리"이다. 이는 MySQL의 Repeatable Read 격리 수준과 유사하다. 스냅샷 격리에서는 트랜잭션 내에서 읽은 데이터가 해당 트랜잭션 동안 변경되지 않음을 어떻게 보장할까? 각 트랜잭션이 시작할 때의 데이터 상태를 고정하여 동시성을 보장한다.
예를 들어 생각해보자. 두 개의 트랜잭션 T1과 T2가 있다고 가정하자. T1이 시작된 후 데이터를 읽고 업데이트를 시도하는 동안, T2가 시작되어 같은 데이터를 읽는다. 스냅샷 격리에서는 T1이 완료되기 전까지 T2는 T1의 변경 사항을 볼 수 없다. MySQL의 Repeatable Read 격리 수준과 유사한 부분이다. Repeatable Read 격리 수준은 트랜잭션이 시작된 시점의 데이터 상태를 유지하여 동일한 트랜잭션 내에서 같은 쿼리를 반복해서 실행하더라도 항상 같은 결과를 반환하도록 보장한다. 만약 T1이 먼저 커밋되면, T2의 커밋 시도는 실패하고, 트랜잭션을 다시 시도해야 한다.
물론 트랜잭션을 사용한다고 해서 동시성 이슈가 해결되지는 않는다. 다만 주요 연산을 하나의 연산으로 취급하여 원자성을 보장받을 수 있어 어찌됐든 충돌에 대한 방지는 가능하다. 차후 Retry 등의 로직은 별도 구현 사항이다.
2. 비관적 락 혹은 글로벌 락
두 번째 해결 방안은 락을 사용하는 방식이다.
트랜잭션의 개념에서 원자성을 보장하며, 순차적 기반으로 격리를 보장하는 메커니즘이 락과 유사할 수 있지만, 락을 사용한 접근법은 트랜잭션과 몇 가지 중요한 차이점이 있다. 트랜잭션은 주로 데이터의 일관성과 무결성을 보장하는 데 중점을 두는 반면, 비관적 락과 글로벌 락은 데이터 액세스를 제어하여 동시성 문제를 해결하는 데 집중한다.
비관적 락(Pessimistic Lock) 또는 글로벌 락(Global Lock)
비관적 락은 데이터베이스 차원에서의 락이다. 리소스가 충돌할 가능성을 미리 염려하여 트랜잭션이 리소스를 접근할 때마다 락을 걸어 다른 트랜잭션이 접근하지 못하게 하는 방식이다. 글로벌 락은 레디스와 같은 분산환경 저장소를 이용한 락으로 경합하는 요청에 대해 전체 어플리케이션 수준에서 락을 거는 개념이다.
비관적 락을 사용한 접근
카우치베이스는 getAndLock 연산을 제공하여 비관적 락을 구현할 수 있다. 데이터를 읽고 나서 해당 데이터에 락을 거는 방식을 예시로 살펴보자.
public class CouchbasePessimisticLockExample {
public static void main(String[] args) {
// 데이터 조회 및 락
var doc = collection.getAndLock("user::A", Duration.ofSeconds(30));
var content = doc.contentAsObject();
// 데이터 가공
content.put("discount", "new discount value");
// 데이터 upsert 연산
collection.replace(doc, content);
}
}getAndLock 메서드를 사용하여 데이터를 조회하고 동시에 락을 걸 수 있다. 락을 건 동안 다른 트랜잭션은 이 데이터를 수정할 수 없다.
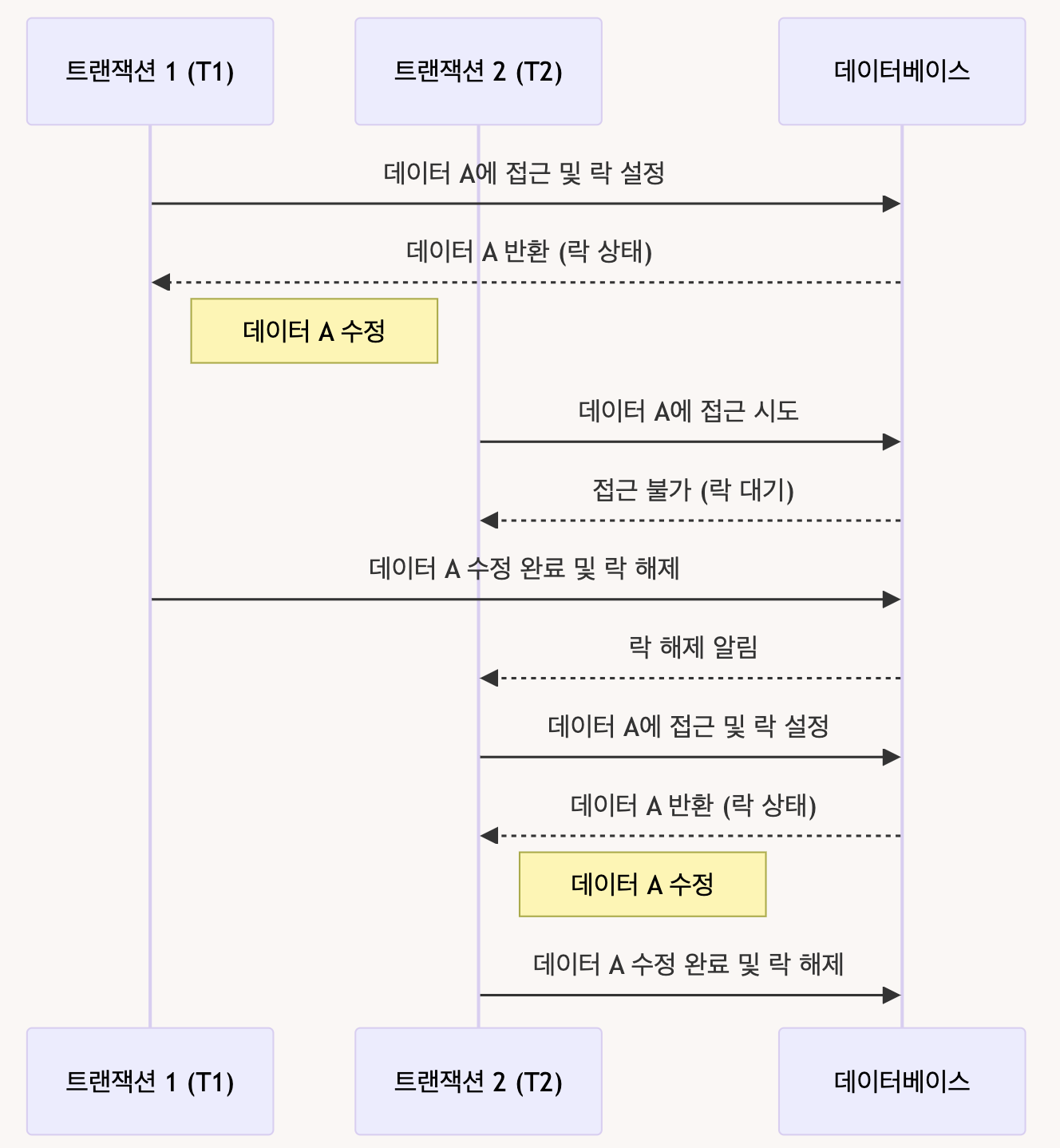
비관적 락을 사용하여 동시성 문제를 해결하는 방법을 간단한 예시를 살펴보자. 아래 다이어그램은 두 개의 트랜잭션(T1, T2)이 동일한 리소스에 접근하려고 할 때, 비관적 락이 작동하는 방식이다.
예시 상황
- T1 트랜잭션이 시작되어 데이터 A에 접근하고 락을 건다.
- T1이 데이터 A를 수정하는 동안, T2 트랜잭션이 데이터 A에 접근을 시도하지만 락 때문에 대기 상태에 들어간다.
- T1이 데이터 A의 수정을 완료하고 락을 해제한다.
- T2가 데이터 A에 접근하여 작업을 수행한다.
sequenceDiagram
participant T1 as 트랜잭션 1 (T1)
participant T2 as 트랜잭션 2 (T2)
participant DB as 데이터베이스
T1->>DB: 데이터 A에 접근 및 락 설정
DB-->>T1: 데이터 A 반환 (락 상태)
Note right of T1: 데이터 A 수정
T2->>DB: 데이터 A에 접근 시도
DB-->>T2: 접근 불가 (락 대기)
T1->>DB: 데이터 A 수정 완료 및 락 해제
DB-->>T2: 락 해제 알림
T2->>DB: 데이터 A에 접근 및 락 설정
DB-->>T2: 데이터 A 반환 (락 상태)
Note right of T2: 데이터 A 수정
T2->>DB: 데이터 A 수정 완료 및 락 해제비관적 락은 제일 간단하게 트랜잭션 간의 충돌을 피하고 데이터의 일관성을 유지하는 방법 중 하나이다. 어떻게 보면 제일 쉽지만 그만큼 비용도 비쌀 수 있다.
글로벌 락을 사용한 접근
글로벌 락은 분산 락을 통해 여러 인스턴스와 MSA 환경에서의 동시성 문제를 해결하는 방법이다. 글로벌 락은 분산 시스템에서 동시성을 제어하기 좋은 방식이라 사실 다른 구현에서도 많이 사용하고 있는 방식이다. DB 락보다 장점인 점은 락의 범위가 데이터베이스에 국한되지 않으며, 애플리케이션 레벨에서 보다 유연하게 사용할 수 있다는 것이다. 또한, 락이 걸린 상태에서도 다른 작업을 병행 처리할 수 있어 시스템 전체의 처리량에 미치는 영향이 적다.
지금과 같은 문제의 경우에도 현재 시스템 아키텍처가 MSA 분산환경이며 서버 인스턴스가 여러 개로 운영되고 있기 때문에, 명시적 락보다 Redis 인메모리 DB를 사용하는 분산 락이 더 적합할 수 있었다. 다만 우리의 경우 Redis는 Single Point of Failure(SPOF)라는 점을 고려해야 했다.
글로벌 락 구현 예시
글로벌 락을 구현하기 위해 Redis의 분산 락을 사용한다. 현재 팀 내에서는 AOP와 애노테이션을 활용하여 쉽게 분산 락을 적용할 수 있는 구조를 사용하고 있다. 간단하게만 코드를 살펴보고자 한다.
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface GlobalLock {
String prefix() default "";
}@Aspect
@Component
public class LockAspect {
@Autowired
private RedisLockService redisLockService;
@Around("@annotation(GlobalLock)")
public Object around(ProceedingJoinPoint joinPoint) throws Throwable {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
GlobalLock globalLock = method.getAnnotation(GlobalLock.class);
String lockKey = globalLock.prefix() + Arrays.toString(joinPoint.getArgs());
return redisLockService.executeWithLock(lockKey, joinPoint::proceed);
}
}글로벌 락 사용 예시
어떻게 사용할 수 있을까? 실제 애노테이션에 여러 value들을 첨가해서 사용한다면 여러 옵션들을 덧붙이는 방식으로 key를 생성해서 사용할 수 있을 것이다.
@Service
public class DiscountService {
@GlobalLock(prefix = "discountServiceLock")
public void applyDiscount(String userId, String discountCode) {
// 비즈니스 로직 구현
System.out.println("Applying discount for user: " + userId);
}
}이와 같은 방식으로 글로벌 락을 적용하면, 현재의 race condition에 대한 데이터 일관성 문제를 제어할 수 있다.
3. 낙관적 락 방식
또 다른 방식은 낙관적 락을 이용하는 것이다. 이 방식이 실제로 최종적으로 선택한 방식이기도 하다.
낙관적 락은 데이터 업데이트 시점에 버전 번호를 사용하여 데이터 충돌을 방지하는 방식이다. 이 방식을 사용하면, 데이터 조회 시 버전 번호를 함께 반환하고, upsert 시 동일한 버전 번호를 확인하여 일치하는 경우에만 업데이트를 수행한다.
낙관적 락 방식의 기본 개념은 다음과 같다.
- 데이터 조회 시 현재 버전 번호를 함께 가져온다.
- 데이터 업데이트 시 조회한 버전 번호와 현재 버전 번호가 일치하는지 확인한다.
- 일치하면 업데이트를 수행하고, 버전 번호를 증가시킨다. 일치하지 않으면 업데이트를 중단하고 오류를 반환한다.
카우치베이스에서 제공하는 CAS(Check-and-Set) 연산을 활용하면 낙관적 락을 쉽게 이용할 수 있다.
3. 해결: 낙관적 락을 이용한 해결(카우치베이스의 CAS 오퍼레이션)
최종적으로 낙관적 락을 선택했다. 분명 트랜잭션이나 글로벌 락으로도 가능했을 것이다. 그런데 왜 낙관적 락이 적절했을까?
이 문제에 적절하다고 판단했는데, 정답을 우선 밝히자면 제일 비용이 싸게 들면서도 원하는 것을 이룰 수 있었기 때문이었다.
낙관적 락은 단순 조회만 하는 경우에는 도움이 되지 않는다. 만약 여러 클라이언트가 동시에 동일한 데이터를 읽고, 해당 데이터가 다른 프로세스에 의해 동시에 변경되지 않기를 보장해야 하는 경우, 낙관적 락은 적절한 해결책이 아니다.
여러 사용자가 동시에 특정 데이터(예: 재고 수량)를 조회하고, 각 사용자가 조회한 데이터가 다른 사용자에 의해 변경되지 않기를 원한다고 가정해보자. 이 경우, 단순히 데이터를 조회하는 동안 다른 사용자가 해당 데이터를 수정하지 못하도록 해야 한다. 하지만 낙관적 락은 업데이트 시에만 충돌을 감지하기 때문에, 단순 조회 시에는 동시성을 보장할 수 없다.
하지만 현재 문제의 경우는 할인 서비스와 통합 정보 서비스가 동시에 동일한 사용자 데이터를 업데이트하는 상황에서 충돌이 발생하는 상황이다. 즉, 낙관적 락의 시나리오에 딱 들어맞는 상황이다. 또한, 동시성이 매번 발생하는 상황은 아니며, 충돌에 대해서 재시도를 통해 비교적 손쉽게 처리도 가능한 상황이다. 정리해보면 다음과 같다.
- 효율성: 사실상 락이 아니므로, 성능 오버헤드가 적다.
- 단순성: 코드 복잡성이 크게 증가하지 않고, 충돌 발생시에 해결도 간단하다.
카우치베이스의 CAS 오퍼레이션
카우치베이스는 CAS(Compare-And-Swap) 오퍼레이션을 통해 낙관적 락을 지원한다. 해당 연산을 이용하면 실제로 저렴한 비용으로 동시성을 제어할 수 있다. 문서의 내용을 살펴보자.
기본 설명
카우치베이스의 공식 문서에 따르면, CAS는 현재 아이템의 상태를 나타내는 값이다. 아이템이 수정될 때마다 CAS 값도 변경된다. 이 값은 아이템에 접근할 때마다 문서의 메타데이터로 반환된다. CAS는 낙관적 락의 한 형태로, 업데이트 연산 시 서버에서 문서의 현재 CAS 값과 애플리케이션이 제공한 CAS 값을 비교하여 일치하는 경우에만 업데이트가 성공하도록 한다.

예를 들어, 두 개의 스레드가 동일한 문서를 동시에 수정하려고 할 때, CAS 값이 일치하지 않으면 수정이 실패한다. 즉, 낙관적 락과 동일한 메커니즘으로 작동한다.
성능 퍼포먼스 저하가 없다
카우치베이스 문서에 따르면, CAS 연산은 성능 저하 없이 동작한다. CAS 값은 서버에서 각 연산 시 항상 반환되며, CAS 비교는 간단한 정수 비교로 구현되어 추가적인 오버헤드가 없다.

이러한 이유로 현재 문제 상황에서 낙관적 락을 사용한 CAS 오퍼레이션이 가장 적절한 해결책이 아닐수가 없었다.
구현
코드 레벨에서의 구현을 살펴보자. 실제 코드에서는 카우치베이스 SDK와 스프링 데이터 JPA에 맞게 추상화된 레포지토리를 사용하고 있다.
먼저 서비스레이어이다. 서비스 레이어에서는 할인 요청을 처리하고, 데이터를 가공하여 저장소에 업서트합니다. 여기서 달라진 부분은 사실 크게 없고, 레포지토리에 구현한 updateCas 오퍼레이션을 호출하도록만 변경되었다.
@Service
public class DiscountService {
@Autowired
private DiscountRepository discountRepository;
public Optional<DiscountSnapshot> applyDiscount(DiscountApplyRequest request) {
Optional<History> optionalHistory = discountRepository.get(request.getHistoryId());
// ...
History history = optionalHistory.get();
// ... 조회한 데이터 가공 ...
// CAS를 이용한 upsert 요청
discountRepository.upsertWithCAS(history);
// ...
}
}할인 요청을 받아 관련 데이터를 가공한 후 discountRepository.upsertWithCAS 메서드를 통해 데이터를 저장한다.
리포지토리 레이어에서 실제 데이터베이스 연산을 수행하고, CAS 연산을 통해 동시성 제어를 구현하는 부분이다.
@Repository
public class DiscountRepository {
public MutationResult upsertWithCAS(DiscountDocument document, Duration expiry) throws CasMismatchException {
try {
long cas = getCollection().get(document.getId()).cas();
log.info("[SUCCESS] upsertWithCAS. replaced. id={}, cas={}", document.getId(), cas);
return getCollection().replace(document.getId(), document, replaceOptions().cas(cas).expiry(expiry));
} catch (DocumentNotFoundException e) {
log.info("[SUCCESS] upsertWithCAS. inserted. id={}", document.getId());
return getCollection().insert(document.getId(), document, InsertOptions.insertOptions().expiry(expiry));
}
}
}이 메서드는 데이터베이스에 저장할 때 CAS 값을 사용하여 기존 데이터가 변경되지 않았는지 확인한다. 변경되었다면 연산을 실패시키고, 다시 시도하거나 적절한 처리를 한다.
충돌 발생에 따라 카우치베이스에서 CasMisMatchException이 발생하면 그에 대한 제어로서 retry를 수행한다. retry는 facade 레이어에서 처리한다.
public class OperationFacade {
private static final int MAX_RETRY_COUNT = 5;
private static final int RETRY_DELAY_MS = 50;
protected <R, S> Optional<S> executeWithRetry(R request, Function<R, Optional<S>> function) throws CasMismatchException {
for (int i = 0; i < MAX_RETRY_COUNT; i++) {
try {
return function.apply(request);
} catch (CasMismatchException e) {
// ...
}
}
public Optional<DiscountSnapshot> apply(DiscountApplyRequest request) throws UserException {
return executeWithRetry(request, discountService::apply);
}왜 Facade 레이어에서 retry를 해야할까? 아키텍처 관점에서 보면 역할을 분리하여 복잡성을 줄이고 재사용성을 높이는 등의 목적도 있을 것이다. 그런데 중요한 점은 request를 있는 그대로 다시 서비스에 태울 수 있다는 점으로 로직을 처음부터 실행시킬 수 있기 때문이었다.
현재 구현에서의 Retry는 CAS 값을 가져오는 처음 시점부터 다시 진행되어야 한다. retry 구현시에 이 점을 놓치기 쉽다! CAS 연산은 특정 시점의 데이터 상태를 기반으로 이루어지기 때문에, 특정 부분만 retry를 하게 되면 논리적인 오류에 빠질 수 있다. 예를 들어, 다음과 같은 시나리오를 생각해보자.
- 처음 CAS 값 가져오기: 서비스에서 데이터의 CAS 값을 가져온다.
- 데이터 가공: 가져온 데이터를 가공하여 새로운 값을 만든다.
- CAS 기반 업데이트: 가공된 데이터를 CAS 값을 기반으로 업데이트하려 한다.
이 과정에서 CAS 연산이 실패하면, 처음 CAS 값을 가져오는 시점부터 다시 시작해야 한다. 그렇지 않으면, 이미 변경된 CAS 값을 기준으로 다시 업데이트를 시도하기 때문에, 동시성 문제가 발생할 수 있다.
만약 서비스나 레포지토리 레이어에서 retry를 구현하면 어떨까? 물론 가능하다. 하지만 다음과 같은 문제가 발생할 수 있다.
- 부분적인 retry: 로직의 중간 부분에서만 retry를 하게 되면, 처음 데이터의 CAS 값이 이미 변경된 상태에서 다시 시도하게 된다. 잘못된 구현이다!
- 복잡성 증가: 각 서비스나 레포지토리마다 별도로 retry 로직을 구현하면 코드가 복잡해지고, 중복 코드가 증가한다.
따라서 퍼사드 레이어에서 retry로직을 구현함으로써 서비스 로직을 처음부터 다시 실행하여 CAS 연산의 일관성도 유지하면서도 비교적 클린한 코드 수준도 유지할 수 있다.
어떻게 검증할까?
당연하겠지만 구현에 따른 테스트가 필요했다. 테스트는 실제 상황에서와 같이 동시적인 요청을 발생시켜 상황을 재현시키는 것이 필요했다.
스프링에서 동시성을 테스트하는 한 가지 방법으로 ExecutorService와 CountDownLatch를 사용할 수 있다. 아래는 동시성을 발생시키는 간단한 예시 코드이다.
for (int i = 0; i < numThreads; i++) {
executorService.execute(() -> {
try {
startLatch.await(); // 모든 스레드가 동시에 시작
performConcurrentOperation(); // 동시성 문제를 검증할 로직
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
doneLatch.countDown(); // 작업 완료 표시
}
});
}
startLatch.countDown(); // 모든 스레드가 동시에 작업 시작
doneLatch.await(); // 모든 스레드가 작업 완료할 때까지 대기위와 같은 방식으로 동시 요청을 재현할 수 있다.
다만, 본 테스트를 이슈가 직접적으로 발생하는 서비스에서 수행하면 좋았겠지만 본 서비스의 오너는 아니었기 때문에 내가 관여하기는 힘들었다.
대신 처음 요청을 트리거 할 수 있는 포인트부터 테스트를 했다. 카프카 MessageQueue에 다수의 동시적인 메시지를 만들고, 할인 요청을 하는 부분에서부터 동시성을 재현하여, 종단간을 넘어가며 거의 100% 현실 시나리오에 가깝게 테스트를 했다.

Stage 환경에서 자체 테스트로 검증했고 재현이 안되는 것을 확인했다.
결론적으로 QA에서의 검증까지 마치고 운영까지 배포했다.
그렇게 문제가 해결될 줄 알았다. 그런데...
4. 또 다른 문제 - 이상 현상
프로덕션 환경에 새로운 코드를 배포한 후 초기에는 문제가 해결된 것처럼 보였다. 그러나 얼마 지나지 않아 이상한 문제가 다시 발생했다. 먼저 로그를 살펴보자.
<서버 인스턴스 1>
09:28:28.040 [ INFO] [XNIO-2 task-4] [Facade] - # apply : discountApplyRequest=(parkingHistoryId=ID-1, discountType=DISCOUNT1, value=100, ...)
09:28:28.041 [ INFO] [XNIO-2 task-4] [ServiceImpl] - ## (Before update) Discount snapshots=[]
09:28:28.041 [ INFO] [XNIO-2 task-4] [ServiceImpl] - ## New discount snapshot=(id=ID-1, value=100, ...)
09:28:28.041 [ INFO] [XNIO-2 task-4] [ServiceImpl] - ## (After update) Discount snapshots=[(id=ID-1, value=100, ...)]
09:28:28.041 [ INFO] [RepositoryImpl] - [SUCCESS] upsertWithCAS. replaced. id=ID-1, cas=1716251308008996864
09:28:28.042 [ INFO] [ResponseEntity] - resultCode : 0000, resultMessage : 성공<서버 인스턴스 2>
09:28:28.037 [ INFO] [XNIO-2 task-3] [Facade] - # apply : discountApplyRequest=(parkingHistoryId=ID-1, discountType=DISCOUNT2, value=10, ...)
09:28:28.041 [ INFO] [XNIO-2 task-3] [ServiceImpl] - ## (Before update) Discount snapshots=[]
09:28:28.043 [ INFO] [XNIO-2 task-3] [ServiceImpl] - ## New discount snapshot=(id=ID-2, value=10, ...)
09:28:28.043 [ INFO] [XNIO-2 task-3] [ServiceImpl] - ## (After update) Discount snapshots=[(id=ID-2, value=10, ...)]
09:28:28.045 [ INFO] [RepositoryImpl] - [SUCCESS] upsertWithCAS. replaced. id=ID-2, cas=1716251308042092544
09:28:28.046 [ INFO] [ResponseEntity] - resultCode : 0000, resultMessage : 성공발생한 문제 그리고 이상한 점
발생한 문제와 이상한 점은 다음과 같다.
- 서버 인스턴스 1과 2가 거의 동시에 동일한 할인 정보를 업데이트하려고 시도했다.
- 두 인스턴스 같은 객체를 조회한다. 이때 고유한 CAS 값을 부여받는다. 이는 로그 상의 Discount snapshots=
[]으로 확인된다. - 동시 요청에 대해서 하나가 먼저 업데이트가 되면 이후의 요청은 CAS mismatch로 인해서 예외가 발생해야 한다. 그러면 retry를 타게 될 것이고 업데이트 된 객체를 다시 불러와서 정상적으로 upsert가 될 것이다.
- 그런데 예외가 발생하지 않았다! 그대로 둘 다 업데이트가 되어버렸고, 또 다시 한 건에 대한 lost update가 발생했다!
이상한 점은 로그 상에 분명히 ## (Before update) Discount snapshots=[]로 공통이 객체를 조회하는 부분이 찍혔다는 점이다. 이점으로 미루어볼 때 CAS 값 조회시에 특별한 문제가 없다면 분명히 예외가 발생해야 맞다. 그리고 그렇게 발생해왔고, retry를 태워서 업데이트가 되어왔다. 그런데 왜 이번은 예외도 발생하지 않았느냐는 것이다!
왜?
사실 이 지점에서 팀원들과 이야기를 많이 나눴는데 원인 파악부터 해결방안까지 쉽지만은 않았던 것 같다. 스테이징 환경 대비 프로덕션 환경에서는 4개 인스턴스를 운영하기 때문에 더 험한 동시성 상황이 가능했다. 그렇더라도 그것이 이유가 될 수 있을까? 정말 극단적으로 생각해서, 우리가 카우치베이스 커뮤니티 버전을 사용해서 (유료버전이 아닌 무료버전) 카우치베이스에서 CAS 연산에 대한 보장을 못해주는 것이 아닐까 하는 의심도 스쳐갔다.
하지만 말이 안된다. 그동안 카우치베이스를 사용하면서 많이 데이긴 했어도 그래도 상장회사인데 그건 말이 안된다고 생각했다.
결국 어딘가 허점이 있지 않을까? 그건 우리 코드 상의 문제가 아닐까? 다시 처음부터 생각해보기로 했다.
진짜로, 왜?
사실 답은 간단했었고 어찌 보면 초반에 발견했었는데 좀 쉽게 지나쳐버렸던 부분이었다. 언제나 그렇듯 알고나면 참 쉽다. 🤯
어떤 상황이 벌어진 것일까?
문제의 핵심은 데이터를 조회한 시점과 실제 CAS 값 조회 시점의 차이 때문이다!
서비스 레이어와 리포지토리 레이어 간의 시간 차이와 데이터 조회 방식에서부터 기인한다. 차근차근 살펴보자.
다음과 같은 코드를 보면 서비스 레이어에서 데이터 조회와 리포지토리 레이어에서 CAS 값을 조회하는 시점이 다르다.
@Service
public class DiscountService {
@Autowired
private DiscountRepository discountRepository;
public Optional<DiscountSnapshot> applyDiscount(DiscountApplyRequest request) {
Optional<History> optionalHistory = discountRepository.get(request.getHistoryId());
// ...
History history = optionalHistory.get();
// ... 조회한 데이터 가공 ...
// CAS를 이용한 upsert 요청
discountRepository.upsertWithCAS(history);
// ...
}
}서비스 레이어에서 데이터 조회를 한 후, 데이터를 가공하여 리포지토리 레이어의 upsertWithCAS 메서드로 전달한다. 하지만 리포지토리 레이어에서 다시 데이터를 조회하여 CAS 값을 가져온다. 바로 이것이 문제다!
리포지토리 레이어에서 upsertWithCAS 메서드 구현을 다시 살펴보자.
@Repository
public class DiscountRepository {
public MutationResult upsertWithCAS(DiscountDocument document, Duration expiry) throws CasMismatchException {
try {
long cas = getCollection().get(document.getId()).cas(); // 최신의 CAS 값을 조회
log.info("[SUCCESS] upsertWithCAS. replaced. id={}, cas={}", document.getId(), cas);
return getCollection().replace(document.getId(), document, replaceOptions().cas(cas).expiry(expiry));
} // ...
}
}위의 코드에서 getCollection().get(document.getId()).cas()는 Couchbase 서버에 직접 요청을 보내 해당 문서의 최신 상태와 CAS 값을 가져오는 부분이다. 이는 데이터를 재조회하는 과정으로, Couchbase 서버와의 통신을 통해 최신 CAS 값을 가져온다.
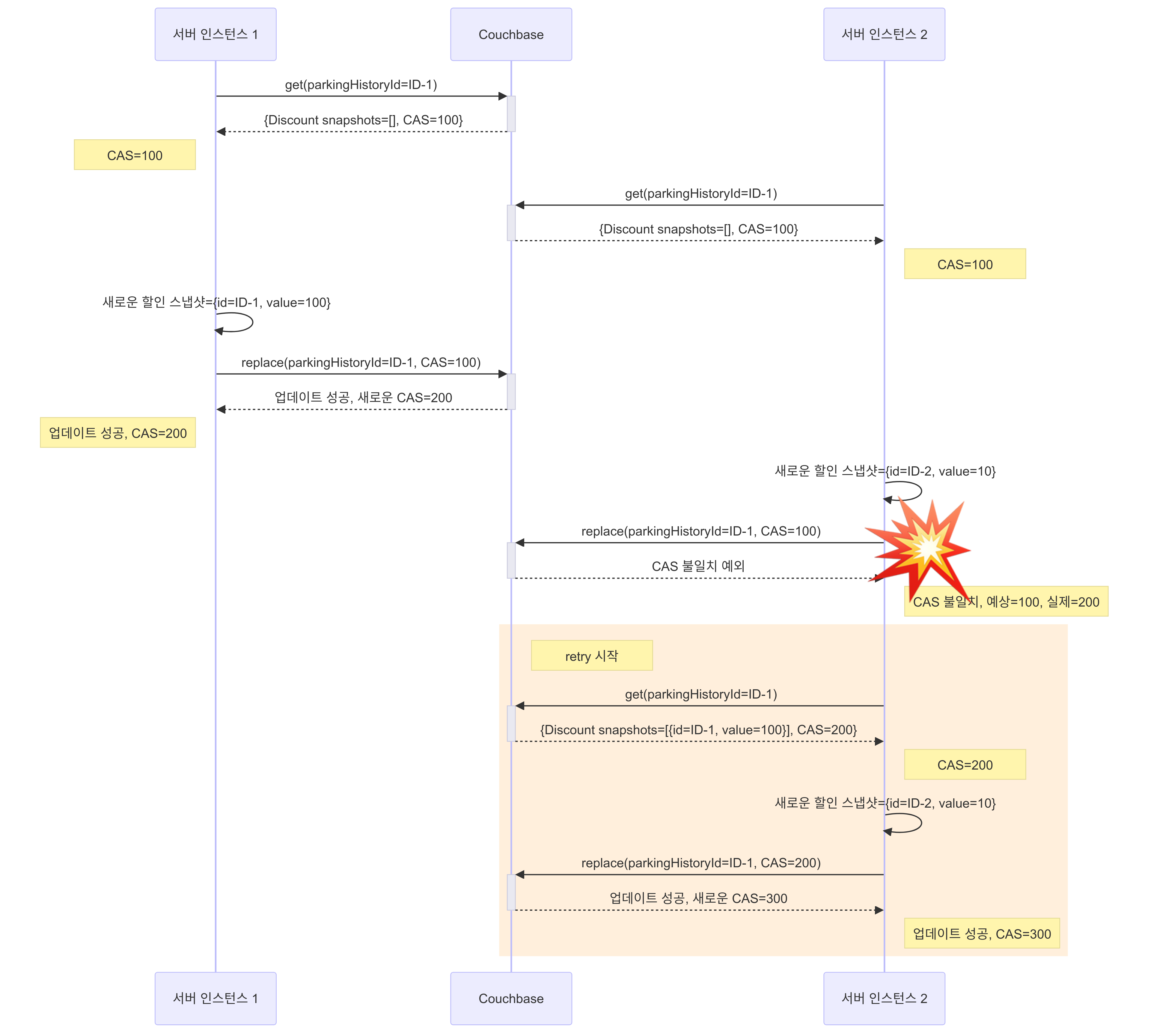
이러한 방식은 특정 시점에 서버 인스턴스 1과 서버 인스턴스 2가 동일한 문서의 CAS 값을 조회했으나, 시간이 흐른 후에 리포지토리 레이어에서 문서를 다시 조회할 때 최신 CAS 값이 변경된 상황에서 발생한다.
리포지토리 레이어에서 getCollection().get(document.getId()).cas()를 호출하여 CAS 값을 가져오고, 이를 사용해 업데이트를 수행한다. 이 과정에서 첫 번째 요청의 업데이트가 완료된 후, 두 번째 요청이 새로운 CAS 값을 가져와 업데이트를 성공되어 버리는 것이다.
즉, 서비스 레이어에서 데이터를 조회한 시점과 리포지토리 레이어에서 CAS 값을 조회한 시점이 다르다는 것이다. 서비스 레이어에서 데이터를 조회한 후, 가공하는 동안 다른 인스턴스에서 동일한 데이터를 업데이트할 수 있다. 그런 다음 리포지토리 레이어에서 CAS 값을 다시 조회하면서 업데이트 타이밍이 달라지게 된다.
타임라인으로 살펴보자.
타임라인

09:28:28.037: 서버 인스턴스 2 - 할인 관리 서비스-> 할인 적용 요청 (ID-1,DISCOUNT2,value=10)09:28:28.040: 서버 인스턴스 1 - 할인 관리 서비스-> 할인 적용 요청 (ID-1,DISCOUNT1,value=100)09:28:28.041: 서버 인스턴스 1 - 데이터 조회,Discount snapshots=[], CAS 값 10009:28:28.041: 서버 인스턴스 2 - 데이터 조회,Discount snapshots=[], CAS 값 10009:28:28.041: 서버 인스턴스 1 - 데이터 가공,New discount snapshot=(id=ID-1, value=200)09:28:28.041: 서버 인스턴스 1 - 가공된 데이터를 CAS 값100으로 업데이트 시도09:28:28.041: 서버 인스턴스 1 - 업데이트 성공, CAS 값이200로 변경됨09:28:28.043: 서버 인스턴스 2 - 데이터 가공,New discount snapshot=(id=ID-2, value=20)09:28:28.045: 서버 인스턴스 2 - 리포지토리 레이어의upsertWithCAS메서드를 호출09:28:28.046: 서버 인스턴스 2 - 리포지토리 레이어에서getCollection().get(document.getId()).cas()를 호출하여 최신 CAS 값200을 가져옴09:28:28.046: 서버 인스턴스 2 - CAS 값200으로 업데이트 시도09:28:28.046: 서버 인스턴스 2 - CAS mismatch 예외가 발생하지 않고, 업데이트가 성공함. CAS 값은300으로 변경됨
위 타임라인을 보면 서버 인스턴스 1과 서버 인스턴스 2가 동시 요청을 처리할 때, 데이터 조회 시점과 실제 CAS 값을 가져오는 로직이 달라서 로깅에서는 Discount snapshots=[]가 찍혀 동일한 CAS 값을 사용하는 것처럼 착시 현상이 발생했다. 하지만 최신의 CAS 값으로 업데이트되면서 덮어씌워지게 되어 CAS mismatch 예외가 발생하지 않고 lost update가 발생했다.
결국은 휴먼 에러
결론은 결국 '휴먼 에러'라는 것이다. 기술적으로 복잡한 문제로 보였던 원인은 사실 우리가 코드 작성 시 간과했던 부분에서 비롯되었다. 핵심은 데이터 조회 시점과 CAS 값 조회 시점의 불일치였다. 다음과 같이 요약해볼 수 있었다.
- 동시성 제어 미흡:
- 서비스 레이어에서 데이터를 조회한 후, 가공하는 동안 다른 인스턴스에서 동일한 데이터를 업데이트할 수 있다는 점을 고려하지 않았다. 이는 동시성 제어의 기본적인 원칙을 간과한 것이다.
- 코드 리뷰 및 테스트 부족:
- 사실 초기 단계에서 충분히 발견되고 해결될 수 있었다. 역시나 부족한 코드 리뷰와 더 엄밀한 테스트의 부재가 아쉬울 따름이다.
고치는 건 쉽다! 원인을 알았으니 ... 🤧
기존 코드는 서비스 레이어에서 데이터를 가공한 후 리포지토리 레이어에서 최신 CAS 값을 조회하여 업데이트하는 방식으로 동시성 문제가 발생했다.
변경된 코드는 서비스 레이어에서 데이터와 CAS 값을 함께 조회하여 가공한 후, 해당 CAS 값을 사용해 리포지토리 레이어에서 업데이트하도록 수정했다.
즉, 데이터를 가공하기 전에 CAS 값을 조회하고, 조회한 CAS 값을 사용하여 업데이트한다.
@Service
public class DiscountService {
@Autowired
private DiscountRepository discountRepository;
public Optional<DiscountSnapshot> applyDiscount(DiscountApplyRequest request) {
Optional<History> optionalHistoryWithCas = discountRepository.getWithCas(request.getHistoryId());
// ...
History history = optionalHistoryWithCas.get();
// ... 조회한 데이터 가공 ...
// CAS를 이용한 upsert 요청
discountRepository.upsertWithCAS(history);
// ...
}
}@Repository
public class DiscountRepository {
public MutationResult upsertWithCAS(DocumentWithCas<DiscountDocument> documentWithCas, Duration expiry) throws CasMismatchException {
try {
return getCollection().replace(documentWithCas.getDocument().getId(), documentWithCas.getDocument(), replaceOptions().cas(documentWithCas.getCas()).expiry(expiry));
} catch (DocumentNotFoundException e) {
// ...
}
}
}다음 시퀀스 다이어그램에서처럼 이제 정상적으로 예외가 발생하고, 그에 따른 retry 로직이 발동된다!
5. 요약 정리
- CAS 연산이란?
보통 CAS(Compare And Swap) 연산은 컴퓨터 CPU 명령어 수준에서 제공되는 기능에 기반하며, 다양한 프로그래밍 언어에서 하드웨어 수준의 구현으로 제공하는 원자적 연산의 의미로 사용된다. 예를 들어, Java는 java.util.concurrent 패키지에서 AtomicInteger, AtomicReference 등의 클래스를 통해 CAS 연산을 제공한다. 의미 자체는 데이터베이스나 메모리의 특정 위치의 값을 예상한 값과 비교하고 일치하면 새로운 값으로 변경하는 방식이다. 메커니즘 자체가 낙관적 락과 긴밀하므로 낙관적 락 방식으로 활용될 수 있다. 카우치베이스에서 CAS 연산은 특정 문서의 상태를 나타내는 고유한 CAS 값을 통해 데이터의 최신 상태를 추적하고, 이를 기반으로 동시성 문제를 해결한다. 본 프로젝트에서는 CAS 연산을 통해 낙관적 락을 구현하여, 데이터 충돌 시 충돌을 감지하고 재시도하는 방식으로 동시성 문제를 해결하였다.
- CAS mismatch 예외란?
CAS mismatch 예외는 예상한 CAS 값과 실제 CAS 값이 일치하지 않을 때 발생하는 예외이다! 이는 다른 인스턴스에서 데이터가 이미 변경되었음을 의미한다. 해당 예외가 발생하면 데이터 충돌이 발생하는 것으로 동시성을 제어할 수 있다. 본문의 3번째 섹션인 '해결: 낙관적 락을 이용한 해결(카우치베이스의 CAS 오퍼레이션)'에서 동시성이 발생할 때, 데이터의 동시 접근으로 즉 충돌이 발생할 때 해당 예외가 발생하길 기대했었으나 발생하지 않는 것이 문제가 되었다.
- 왜 동시성 문제가 발생했나?
동시성 문제는 여러 인스턴스가 동시에 동일한 데이터를 수정하려 할 때 발생한. 이 경우에는 첫 번째로 MSA 환경과 멀티 서버 인스턴스 운영으로 여러 서비스간의 상호 작용 중에 중복 요청이 발생하였다. 이에 더불어, 이를 제어하기 위한 노력으로 구현한 낙관적 락 메커니즘에서 잘못된 구현으로 데이터 조회와 CAS 값 조회 시점의 차이 때문에 해결이 쉽지 않았다.
- 프로덕션 환경에서만 문제가 발생한 이유는 무엇인가?
테스트 환경에서도 발생했었다. 하지만 프로덕션 환경에서는 더 많은 인스턴스가 운영되면서 동시성 문제가 더 자주 발생할 가능성이 높다. 테스트 환경과의 차이를 좁힐 필요가 있다.
- 어떻게 휴먼 에러를 줄일 수 있을까?
이번에 배울 수 있던 점은 코드 리뷰와 실전과 동일한 환경으로 조성된 엄밀한 테스트의 필요성이었다.