Order MicroService -> Catalog MicroService
- orders service에 요청된 주문의 수량 정보를 catlogs service에 반영
- orders service에서 kafka topic으로 메시지 전송 (producer)
- catalogs service에서 kafka topic에 전송된 메시지 취득 (consumer)
db - order service -> message Queing Service (Kafka) <- consumer service - db
각각의 db를 메시지에 따라 update 하도록 한다.
먼저 dependency 추가
implementation 'org.springframework.kafka:spring-kafka'
Catalog Service에 다음과 같은 Kafka 설정 클래스를 작성한다.
@EnableKafka
@Configuration
public class KafkaConsumerConfig {
@Bean
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> properties = new HashMap<>();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.10.0.1:9092");
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "consumerGroupId");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return new DefaultKafkaConsumerFactory<>(properties);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory
= new ConcurrentKafkaListenerContainerFactory<>();
kafkaListenerContainerFactory.setConsumerFactory(consumerFactory());
return kafkaListenerContainerFactory;
}
}
@EnableKafka: 현재 클래스가 Kafka를 사용하는 것을 활성화하는 데 사용된다. Kafka의 설정 및 기능을 자동으로 활성화한다.
consumerFactory(): ConsumerFactory 빈을 생성하는 데 사용된다. 주요 정보를 받아오고 이를 Deserializing 한다. 이 코드에서는 주요 Kafka 속성을 설정하고 DefaultKafkaConsumerFactory를 생성하여 반환한다.
kafkaListenerContainerFactory(): ConcurrentKafkaListenerContainerFactory 빈을 생성하는 데 사용된다. 이 빈은 Kafka Listener의 컨테이너를 생성하고 관리한다. Kafka Listener는 Kafka로부터 메시지를 수신하고 처리하는 데 사용된다. ConcurrentKafkaListenerContainerFactory를 생성하고 consumerFactory() 메서드에서 생성한 ConsumerFactory를 설정한다.
ConcurrentKafkaListenerContainerFactory 는 변경 사항을 계속해서 Listening 하는 데 사용된다. 이벤트 발생시 캐치한다.
이렇게 등록한 Bean을 사용할 수 있는 Consumer 클래스를 작성한다.
@Service
@Slf4j
@RequiredArgsConstructor
public class KafkaConsumer {
private final CatalogRepository repository;
@KafkaListener(topics = "example-catalog-topic")
public void updateQty(String kafkaMessage) {
log.info("Kafka Message: ->" + kafkaMessage);
Map<Object, Object> map = new HashMap<>();
ObjectMapper mapper = new ObjectMapper();
try {
map = mapper.readValue(kafkaMessage, new TypeReference<Map<Object, Object>>() {});
} catch (JsonProcessingException ex) {
ex.printStackTrace();
}
CatalogEntity entity = repository.findByProductId((String)map.get("productId"));
if (entity != null) {
entity.setStock(entity.getStock() - (Integer)map.get("qty"));
repository.save(entity);
}
}
}
컨슈머가 토픽 변경 사항을 확인하고 변경 사항을 db에 반영하기 때문에 Service 레이어와 같다고 할 수 있다.
@KafkaListener 애노테이션을 통해 topic 업데이트 사항을 구독할 수 있게 된다. 즉 "example-catalog-topic"이 있고, 해당 토픽에 producer가 무언가를 올리면 이를 받아보게 된다. 데이터를 읽고 해당 데이터에 productId를 캐치하여 db에서 이를 찾고, 수량을 업데이트 하도록 한다.
다음을 Prdoucer에 해당하는 OrderService를 수정한다.
마찬가지로 dependency를 추가한 후 설정 클래스를 작성한다.
@EnableKafka
@Configuration
public class KafkaProducerConfig {
@Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> properties = new HashMap<>();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return new DefaultKafkaProducerFactory<>(properties);
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
Producer 클래스는 데이터를 Serializing 한다.
메시지를 보낼 Service 클래스를 작성한다.
@Service
@Slf4j
@RequiredArgsConstructor
public class KafkaProducer {
private final KafkaTemplate<String, String> kafkaTemplate;
public OrderDto send(String topic, OrderDto orderDto) {
ObjectMapper mapper = new ObjectMapper();
String jsonInString = "";
try {
jsonInString = mapper.writeValueAsString(orderDto);
} catch(JsonProcessingException ex) {
ex.printStackTrace();
}
kafkaTemplate.send(topic, jsonInString);
log.info("Kafka Producer sent data from the Order microservice: " + orderDto);
return orderDto;
}
}
send() 메서드는 전달이 될 topic과 해당 topic에 들어갈 데이터를 매개변수로 받는다.
json으로 변환하여 전송된다.
json 포맷에 들어가는 데이터는 스키마, payload 등의 값이 들어갈 수 있지만 현재는 단순하게 메시지 전달용이기 때문에 orderdto를 직렬화하여 보내는 방식으로 한다.
OrderController에서는 다음과 같이 수정한다.
즉, 기존에 저장만 하던 로직에 kafka를 통해 전달하는 과정을 추가한다.
@PostMapping("/{userId}/orders")
public ResponseEntity<ResponseOrder> createOrder(@PathVariable("userId") String userId,
@RequestBody RequestOrder orderDetails) {
log.info("Before add orders data");
ModelMapper mapper = new ModelMapper();
mapper.getConfiguration().setMatchingStrategy(MatchingStrategies.STRICT);
OrderDto orderDto = mapper.map(orderDetails, OrderDto.class);
orderDto.setUserId(userId);
OrderDto createdOrder = orderService.createOrder(orderDto);
ResponseOrder responseOrder = mapper.map(createdOrder, ResponseOrder.class);
kafkaProducer.send("example-catalog-topic", orderDto);
log.info("After added orders data");
return ResponseEntity.status(HttpStatus.CREATED).body(responseOrder);
}
Kafka Connect를 활용한 단일 데이터베이스 사용 -> 데이터 동기화 문제 해결
- OrderService에 요청된 주문 정보를 DB가 아니라 Kafka Topic으로 전송
- Kafka Topic에 설정된 Kafka Sink Connect를 사용해 단일 Db에 저장 -> 데이터 동기화
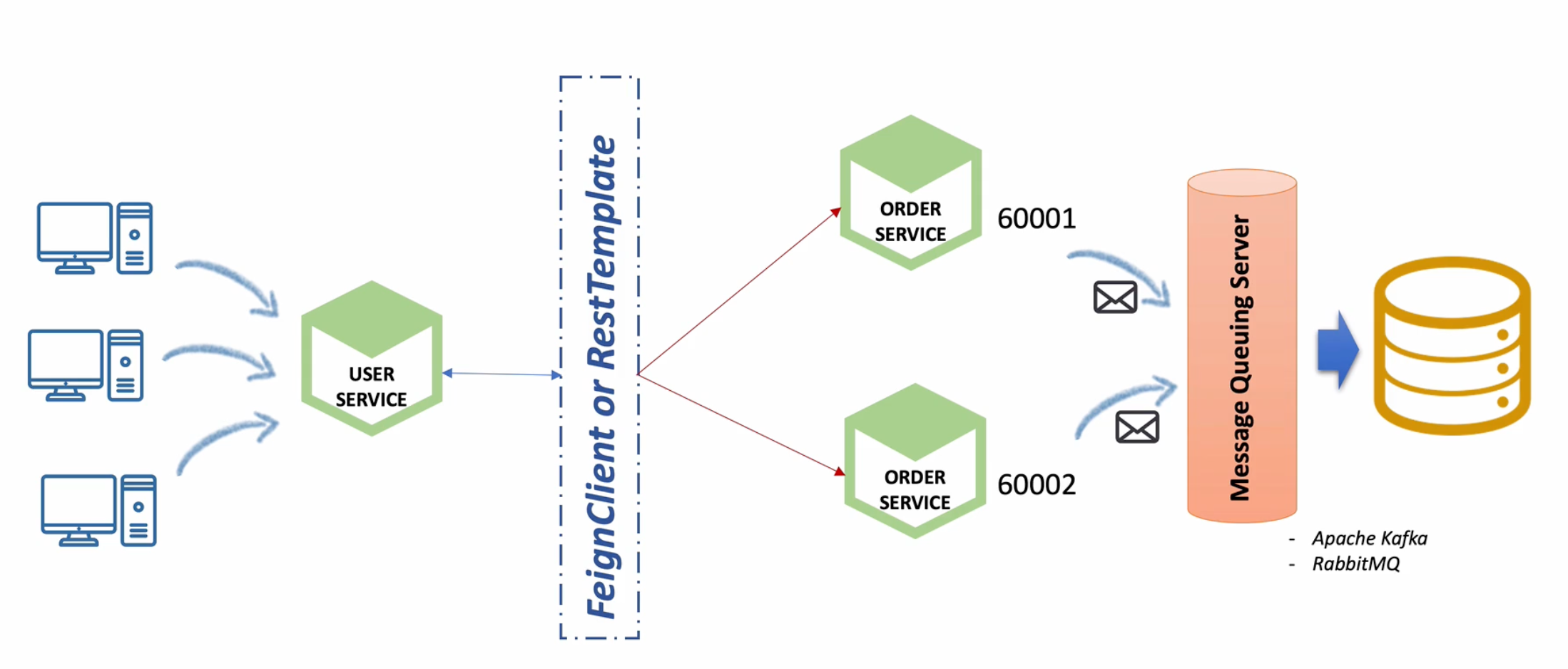
즉, 데이터베이스 입장에서는 최종적인 결과만 반영되어 있다.
먼저 외부 db를 준비한다.
mysql을 사용하였다.
implementation 'com.mysql:mysql-connector-j'datasource:
url: jdbc:mysql://localhost:3306/msapractice
username: xxxx
password: xxxx
driver-class-name: com.mysql.cj.jdbc.Driver
Producer의 컨트롤러를 다음과 같이 변경한다.
@PostMapping("/{userId}/orders")
public ResponseEntity<ResponseOrder> createOrder(@PathVariable("userId") String userId,
@RequestBody RequestOrder orderDetails) {
ModelMapper mapper = new ModelMapper();
mapper.getConfiguration().setMatchingStrategy(MatchingStrategies.STRICT);
OrderDto orderDto = mapper.map(orderDetails, OrderDto.class);
orderDto.setUserId(userId);
/* jpa */
// OrderDto createdOrder = orderService.createOrder(orderDto);
// ResponseOrder responseOrder = mapper.map(createdOrder, ResponseOrder.class);
/* kafka */
orderDto.setOrderId(UUID.randomUUID().toString());
orderDto.setTotalPrice(orderDetails.getQty() * orderDetails.getUnitPrice());
ResponseOrder responseOrder = mapper.map(orderDto, ResponseOrder.class);
/* send this order to the kafka */
kafkaProducer.send("example-catalog-topic", orderDto);
orderProducer.send("orders", orderDto);
return ResponseEntity.status(HttpStatus.CREATED).body(responseOrder);
}
이때 변경되는 점은 Jpa를 통한 저장이 아니라 orderProducer를 만들어 Kafka로 전달해준다는 것이다.
KafkaProducer는 catalog와의 연동을 위한 producer이고 orderProducer는 주문 정보를 kafka topic에다 전달하기 위함이다.
topic에 쌓이는 주문 정보는 sink connector에 의해 분류되며 jdbc 커넥터를 통해 db에 저장된다.
따라서 별도의 포맷 작성이 필요하다.
@Data
@AllArgsConstructor
public class Field {
private String type;
private boolean optional;
private String field;
}
@Data
@Builder
public class Schema {
private String type;
private List<Field> fields;
private boolean optional;
private String name;
}
@Data
@Builder
public class Payload {
private String order_id;
private String user_id;
private String product_id;
private int qty;
private int unit_price;
private int total_price;
}
@Data
@AllArgsConstructor
public class KafkaOrderDto implements Serializable {
private Schema schema;
private Payload payload;
}
즉, Java Object 를 json 형식으로 변경해주어야 한다.
field > schema + payload > kafkaOrderDto
이후 OrderProducer 클래스를 작성한다.
@Service
@Slf4j
public class OrderProducer {
private KafkaTemplate<String, String> kafkaTemplate;
List<Field> fields = Arrays.asList(new Field("string", true, "order_id"),
new Field("string", true, "user_id"),
new Field("string", true, "product_id"),
new Field("int32", true, "qty"),
new Field("int32", true, "unit_price"),
new Field("int32", true, "total_price"));
Schema schema = Schema.builder()
.type("struct")
.fields(fields)
.optional(false)
.name("orders")
.build();
@Autowired
public OrderProducer(KafkaTemplate<String, String> kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
public OrderDto send(String topic, OrderDto orderDto) {
Payload payload = Payload.builder()
.order_id(orderDto.getOrderId())
.user_id(orderDto.getUserId())
.product_id(orderDto.getProductId())
.qty(orderDto.getQty())
.unit_price(orderDto.getUnitPrice())
.total_price(orderDto.getTotalPrice())
.build();
KafkaOrderDto kafkaOrderDto = new KafkaOrderDto(schema, payload);
ObjectMapper mapper = new ObjectMapper();
String jsonInString = "";
try {
jsonInString = mapper.writeValueAsString(kafkaOrderDto);
} catch(JsonProcessingException ex) {
ex.printStackTrace();
}
kafkaTemplate.send(topic, jsonInString);
log.info("Order Producer sent data from the Order microservice: " + kafkaOrderDto);
return orderDto;
}
}
이렇게 하여 지정된 topic에 추가한 뒤에 작업은 업데이트 된 변경사항을 감지하여 db에 저장해주어야 한다.
이를 위해 kafka sink connector를 이용한다.
/8083/connectors 주소에 post요청으로 다음과 같은 connector를 등록한다.
{
"name": "my-order-sink-connect",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"tasks.max": "1",
"topics": "orders",
"connection.url": "jdbc:mysql://localhost:3306/msapractice",
"connection.user": "xxxx",
"connection.password": "xxxx",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter",
"auto.create": "true",
"auto.evolve": "true"
}
}
'Programming > Java, Spring' 카테고리의 다른 글
| 자바의 Functional Interface와 andThen 메서드 이해하기 (0) | 2023.06.02 |
|---|---|
| 자바와 함수형 프로그래밍 (0) | 2023.06.02 |
| [Spring Cloud] 마이크로서비스 간의 통신 RestTemplate, FeignClient, Error decoder, 동기화 문제 (0) | 2023.06.02 |
| [Spring cloud] 비대칭키로 암호화하기 (0) | 2023.06.01 |
| [Spring Cloud] config에서 대칭키 암호화 설정하기 (1) | 2023.06.01 |

